







【论文阅读笔记】(2021 ICCV)Video Pose Distillation for Few-Shot, Fine-Grained Sports Action Recognition
写在前面(中文版自己总结)
之前的 AR(Action Recognition) 有两种做法:
(1)end-to-end:就是普通的 AR,输入 RGB frames,输出动作的类别。
(2)pose based:基于骨架点做的 AR
其中,end-to-end 学习到的 representation 容易 bias 到 some visual patterns,eg:basketball,rather than the action itself;
pose based 的问题就是他需要有个前提:pose label should be accurate 这就要求 pose estimation algorithm 非常 robust,或者 requires expensive human annotation work
这篇文章的做法就是利用 end-to-end 的思想,希望输入是 RGB frames,输出是动作类别。
但巧妙的是,它用一个 student encoder + decoder 去 match teacher(a pose estimator pretrained on a generic dataset)的 output feature,让 student encoder 去 focus 在一些利于进行 pose estimation 的 action representation,从而约束网络尽量少 bias 到 action-irrelated visual patterns 上。
此外,当 teacher 的 confidence 不高的时候,还可以利用一些 visual patterns 进行 AR。
但是。。。弱弱问一句,文章里提到的 weakly-supervised 是不是有点不合适?
Contributions
-
A weakly-supervised method, VPD, to adapt pose features to new video domains, which significantly improves performance on downstream tasks like action recognition, retrieval, and detection in scenarios where 2D pose estimation is unreliable.
-
State-of-the-art accuracy in few-shot, fine-grained action understanding tasks using VPD features, for a variety of sports. On action recognition, VPD features perform well with as few as 8 examples per class and remain competitive or state-of-the-art even as the training data is increased.
-
A new dataset (figure skating) and extensions to three datasets of real-world sports video, to include tracking of the performers, in order to facilitate future research on fine-grained sports action understanding.
引言
现有的姿势估计器往往只使用简单动作的视频数据进行训练,其中缺乏细粒度运动的标签标注。因此,直接将这类估计器应用在具有挑战性的体育视频时,模型会在遇到复杂模糊、遮挡和较快节奏的情况时,预测失败,而且往往出现在那些对行为决策至关重要的几帧中,这会严重影响后续行为识别的结果。下图展示了一些预测失败的例子。

基于上述分析,本文提出的VPD方法设计主要遵循以下三点:
-
VPD仍然与端到端的监督学习方法一样,可以充分挖掘原始视频中的视觉模式(包括但不限于运动员的姿势),并在姿态估计失败时继续工作。
-
在模型的蒸馏学习阶段,只有当教师网络作出较高置信度的姿态预测时,模型才进行蒸馏约束,这样做可以避免过度拟合与运动员动作无关的视觉模式。
-
弱监督的训练设定允许我们对模型加入额外的约束。例如不仅要求学生网络预测实时的运动姿态,还需要预测出当前姿态的运动梯度,这有助于学生网络对一些运动的时序规则进行建模,捕获其随着时间推移而形成的视觉相似性特征。
方法
我们的策略是将现有的、现成的姿势检测器–老师–的不准确的姿势估计,在通用的姿势数据集上进行训练,提炼成一个–学生–网络,专门为特定的目标运动领域的视频生成鲁棒的姿势描述符。学生把围绕运动员裁剪的RGB像素和光流作为输入。它产生一个描述符,我们从该描述符中回归到教师发出的运动员姿势。我们在一个大型的、未经剪裁的、没有标签的目标领域视频语料库上运行这个提炼过程,使用稀疏的高置信度的教师输出作为学生的弱监督。由于教师已经被训练过,VPD不需要在目标视频领域进行新的姿势注释。同样,也不需要下游的特定应用标签(例如用于识别的动作标签)来学习姿势特征。

教师网络
(1) 首先使用一个现成的姿势估计器[45],从第t帧的RGB像素xt中估计2D关节位置。我们将其称为2D-VPD,因为教师生成了2D关节位置。
(2) 我们的第二个教师变体将二维关节位置进一步处理为视图不变的姿势描述符,以pt的形式发出。我们的实现使用VIPE⋆来生成这个描述符。VIPE⋆是对Pr-VIPE[44]概念的重新实现,它被扩展为在额外的合成三维姿势数据[32, 38, 63]上进行训练以获得更好的泛化。我们将这一变化称为VI-VPD,因为教师生成了一个视图不变的姿态表示。
学生特征提取器
我们设计了一个学生特征提取器,对运动员的当前姿势pt和姿势变化率∆pt := pt - pt-1的信息进行编码。该学生是一个神经网络F,它消耗一个彩色视频帧xt∈R3hw,围绕着运动员进行裁剪,以及它的光流jt∈R2hw,来自前一帧。h和w是裁剪的空间尺寸,t表示帧索引。
学生产生一个描述符F(xt,jt)∈Rd,其维度与教师的输出相同。我们将F实现为一个标准的ResNet-34[18],有5个输入通道,我们将输入作物的尺寸调整为128×128。
在蒸馏过程中,F发出的特征通过一个辅助解码器D,该解码器预测当前姿势pt和时间导数Δpt。利用视频的时间性,∆pt提供了一个额外的监督信号,迫使我们的描述器除了捕捉当前姿势外还捕捉运动。D被实现为一个全连接的网络,我们使用以下目标来训练组合学生路径D◦F。
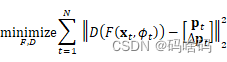
由于在推理过程中只需要F来产生描述符,我们在训练结束时丢弃D。
数据选择。我们从教师的弱监督集合中排除姿势置信度低的帧(具体而言,平均估计联合得分)。默认情况下,阈值为0.5,尽管网球比赛中使用了0.7。
实验结果
本文在四个具有代表性的细粒度体育视频数据集上进行了实验,分别是Firue skating、Tennis、Floor exercise和Diving48。四个数据集中都包含一定数量的快速运动和模糊运动(例如翻转或俯冲)的视频帧,但是这些帧对于识别当前运动行为的类别往往起到关键作用,因此有效的估计和捕获这些帧的时序信息对于下游任务至关重要。
作者首先进行了最关键的细粒度行为识别实验,实验选择了三个baseline:
-
直接使用教师网络对测试数据提取特征,随后使用相同的下游行为识别模型和数据增强手段。
-
使用基于骨架(Skeleton-based)的行为识别方法。
-
使用传统的端到端的行为识别方法。
为了模拟现实场景中标注数据较少,但未标记和目标域数据较多的情形,作者设计了few-shot的实验环境,实验效果如下图所示:
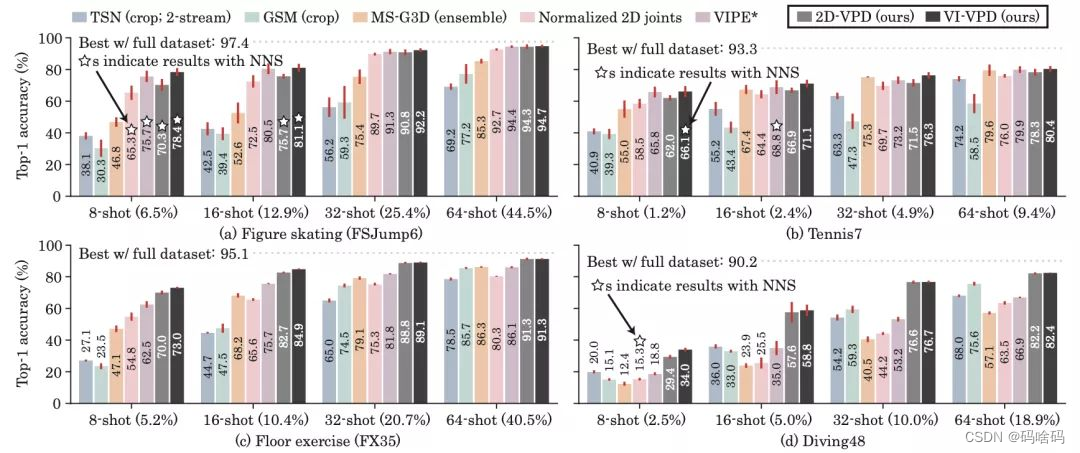
其中2D-VPD和VI-VPD分别对应上文提到的两种教师姿态估计网络的变体,从中也可以看到,在FSJump6和Tennis7数据集上,本文方法已经可以超过其对应的教师网络。随着支持样本数量 k 的增加,本文方法展现出了相比传统方法更好的性能。
为了进一步探索蒸馏学习对该任务的改进来源,作者设计了三种形式的消融实验:
-
分析蒸馏方法的输入。
-
仅使用视频的关键运动片段进行蒸馏。
-
在完全无标注的大规模视频上进行蒸馏。
下表展示了实验结果:

表(a)在FX35和Diving48数据集上的结果表明,VPD的蒸馏效果在仅有RGB作为输入时已经非常明显,当加入光流时,可以进一步提升小样本数据的识别性能。但是仅使用关键运动片段进行蒸馏的效果却很差,结果如表(b)所示,可能是因为缺乏了丰富的运动上下文信息,这也侧面印证了使用更多的视频蒸馏可以有效提高特征的质量。
总结
本文提出的VPD方法以一种明确的蒸馏形式从现有姿态估计网络中获取知识,提高了学生网络在标签受限和运动模糊等场景中的姿态估计能力,VPD学习得到的特征也可以有效提高目标视频域中细粒度行为理解任务的性能。虽然VPD提取的特征可以在数据受限场景中提高模型的精度,但是其在小样本和半监督任务上的性能仍有很大的提升空间。















 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









