






 本文介绍了如何使用深度学习中的卷积神经网络(CNN)对MNIST手写数字数据集进行识别,包括数据加载、预处理、模型构建、编译和训练过程,以及可视化训练结果。
本文介绍了如何使用深度学习中的卷积神经网络(CNN)对MNIST手写数字数据集进行识别,包括数据加载、预处理、模型构建、编译和训练过程,以及可视化训练结果。
无聊,不想学习,玩一玩,下面为原文章
🍦 参考文章地址:深度学习100例-卷积神经网络(CNN)实现mnist手写数字识别 | 第1天_深度学习基于cnn的案例_K同学啊的博客-CSDN博客
默认前期工作无问题。
1.minist数据集
MNIST手写数字数据集来源于是美国国家标准与技术研究所,是著名的公开数据集之一。数据集中的数字图片是由250个不同职业的人纯手写绘制,数据集获取的网址为:http://yann.lecun.com/exdb/mnist/(下载后需解压)。
我们一般会采用(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()这行代码直接调用,这样就比较简单。
代码:
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签 (train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
MNIST手写数字数据集中包含了70000张图片,其中60000张为训练数据,10000为测试数据(已经划分好,keras中自带,比较方便),70000张图片均是28*28。

如果我们把每一张图片中的像素转换为向量,则得到长度为28*28=784的向量。因此我们可以把训练集看成是一个[60000,784]的张量,第一个维度表示图片的索引,第二个维度表示每张图片中的像素点。而图片里的每个像素点的值介于0-1之间(一般来说像素点的值为0-255,所以要进行简单的归一化)。
1.5 设置gpu(按需设置)
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
2.归一化
在此之前已经导入数据集。
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。) train_images, test_images = train_images / 255.0, test_images / 255.0 # 查看数据维数信息 print(train_images.shape, test_images.shape, train_labels.shape, test_labels.shape)
3.数据可视化的图(让你看看数据集里面有什么东东)
# 将数据集前50个图片数据可视化显示
# 进行图像大小为20宽、10长的绘图(单位为英寸inch)
plt.figure(figsize=(20, 10))
# 遍历MNIST数据集下标数值0~49
for i in range(50):
# 将整个figure分成5行10列,绘制第i+1个子图。
plt.subplot(5,10,i+1)
# 设置不显示x轴刻度
plt.xticks([])
# 设置不显示y轴刻度
plt.yticks([])
# 设置不显示子图网格线
plt.grid(False)
# 图像展示,cmap为颜色图谱,"plt.cm.binary"为matplotlib.cm中的色表
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 设置x轴标签显示为图片对应的数字
plt.xlabel(train_labels[i])
# 显示图片
plt.show()
显示的图片就是上面数据集部分的那张。
因为需要进CNN,需要调整张量维度,如下:
train_images = train_images.reshape((60000, 28, 28, 1)) test_images = test_images.reshape((10000, 28, 28, 1)) print(train_images.shape, test_images.shape, train_labels.shape, test_labels.shape)
4.CNN模型的搭建
接下来就是最重要的CNN 的搭建了,这里用sequential的方式。(借用原文章网络结构图)
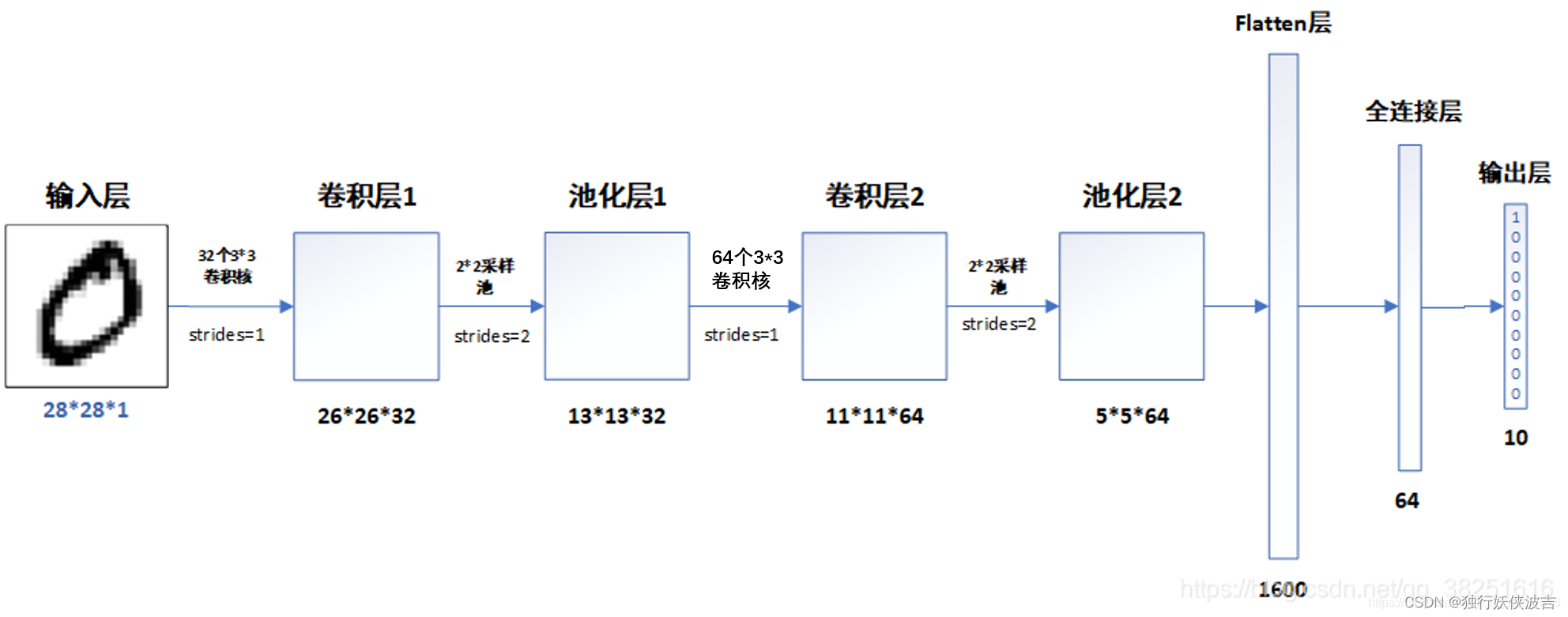
model = models.Sequential([
# 设置二维卷积层1,设置32个3*3卷积核(比较好),input_shape参数将图层的输入形状设置为(28, 28, 1)
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
# 这样后,w=(w1-kernel+1)/s, 26*26*32(32通道数)
# 最大池化层1,2*2采样(降参数的作用,对网络准确性似乎没什么好处,但能大大加快速度)
layers.MaxPooling2D((2, 2)),
# 设置二维卷积层2,设置64个3*3卷积核
layers.Conv2D(64, (3, 3), activation='relu'),
# 池化层2,2*2采样
layers.MaxPooling2D((2, 2)),
# 变成5*5*64(11到5)
layers.Flatten(), # Flatten层(展开),它将输入数据中的每个元素按照其在多维数组中的位置展平到一个一维数组中,连接卷积层与全连接层
layers.Dense(64, activation='relu'), # 全连接层,特征进一步提取,64为输出空间的维数,activation参数将激活函数设置为ReLu函数
layers.Dense(10) # 输出层,输出预期结果,10为输出空间的维数
])
# 打印网络结构
model.summary()
打印的结构如下:
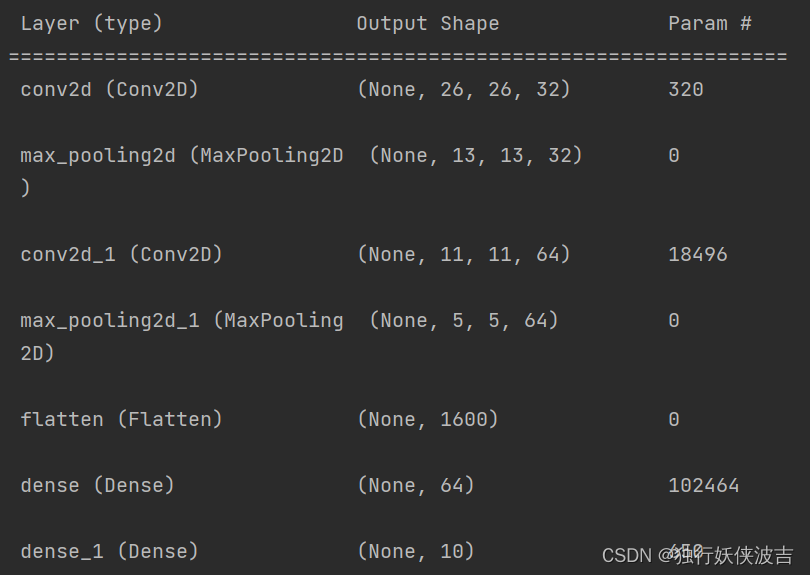
没什么问题,下面进行模型的编译和训练。
5.模型的编译和训练
代码如下:
# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
model.compile(
# 设置优化器为Adam优化器
optimizer='adam',
# 设置损失函数为交叉熵损失函数(tf.keras.losses.SparseCategoricalCrossentropy())
# from_logits为True时,会将y_pred转化为概率(用softmax),否则不进行转换,通常情况下用True结果更稳定
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# 设置性能指标列表,将在模型训练时监控列表中的指标
metrics=['accuracy'])
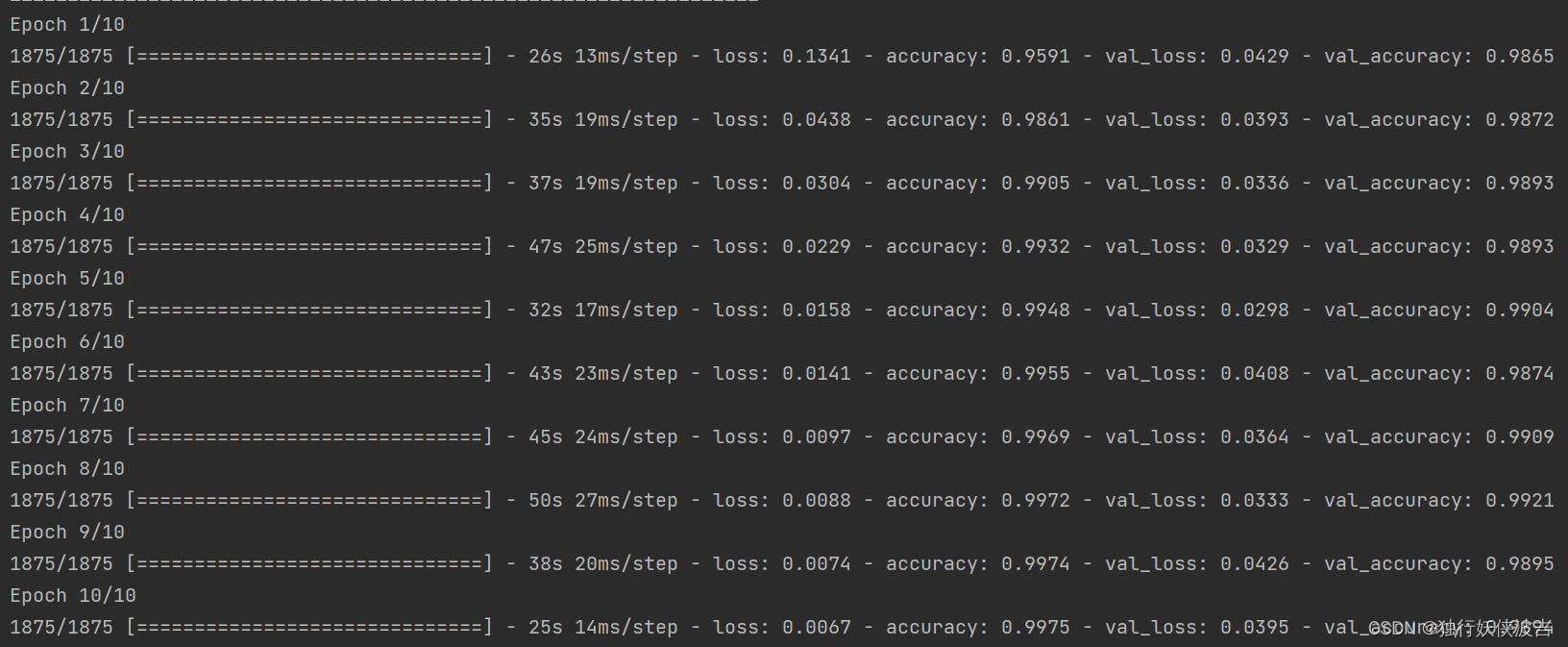
history = model.fit(
# 输入训练集图片
train_images,
# 输入训练集标签
train_labels,
# 设置10个epoch,每一个epoch都将会把所有的数据输入模型完成一次训练。
epochs=10,
# 设置验证集
validation_data=(test_images, test_labels))
6.进行预测
plt.imshow(test_images[2]) pre = model.predict(test_images) # 对所有测试图片进行预测 plt.show() print(pre[2])

acc太高就不绘制曲线了。。
好啦好啦,那么就到此为止了,再学就不礼貌了。总体的代码如下:
import tensorflow as tf
from keras import datasets, layers, models
import matplotlib.pyplot as plt
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。)
train_images, test_images = train_images / 255.0, test_images / 255.0
# 查看数据维数信息
print(train_images.shape, test_images.shape, train_labels.shape, test_labels.shape)
# 将数据集前50个图片数据可视化显示
# 进行图像大小为20宽、10长的绘图(单位为英寸inch)
plt.figure(figsize=(20, 10))
# 遍历MNIST数据集下标数值0~49
for i in range(50):
# 将整个figure分成5行10列,绘制第i+1个子图。
plt.subplot(5,10,i+1)
# 设置不显示x轴刻度
plt.xticks([])
# 设置不显示y轴刻度
plt.yticks([])
# 设置不显示子图网格线
plt.grid(False)
# 图像展示,cmap为颜色图谱,"plt.cm.binary"为matplotlib.cm中的色表
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 设置x轴标签显示为图片对应的数字
plt.xlabel(train_labels[i])
# 显示图片
plt.show()
# 调整数据到我们需要的格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
print(train_images.shape, test_images.shape, train_labels.shape, test_labels.shape)
# 创建并设置卷积神经网络
# 卷积层:通过卷积操作对输入图像进行降维和特征抽取
# 池化层:是一种非线性形式的下采样。主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的鲁棒性。
# 全连接层:在经过几个卷积和池化层之后,神经网络中的高级推理通过全连接层来完成。
model = models.Sequential([
# 设置二维卷积层1,设置32个3*3卷积核(比较好),input_shape参数将图层的输入形状设置为(28, 28, 1)
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
# 这样后,w=(w1-kernel+1)/s, 26*26*32(32通道数)
# 最大池化层1,2*2采样(降参数的作用,对网络准确性似乎没什么好处,但能大大加快速度)
layers.MaxPooling2D((2, 2)),
# 设置二维卷积层2,设置64个3*3卷积核
layers.Conv2D(64, (3, 3), activation='relu'),
# 池化层2,2*2采样
layers.MaxPooling2D((2, 2)),
# 变成5*5*64
layers.Flatten(), # Flatten层(展开),它将输入数据中的每个元素按照其在多维数组中的位置展平到一个一维数组中,连接卷积层与全连接层
layers.Dense(64, activation='relu'), # 全连接层,特征进一步提取,64为输出空间的维数,activation参数将激活函数设置为ReLu函数
layers.Dense(10) # 输出层,输出预期结果,10为输出空间的维数
])
# 打印网络结构
model.summary()
# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
model.compile(
# 设置优化器为Adam优化器
optimizer='adam',
# 设置损失函数为交叉熵损失函数(tf.keras.losses.SparseCategoricalCrossentropy())
# from_logits为True时,会将y_pred转化为概率(用softmax),否则不进行转换,通常情况下用True结果更稳定
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# 设置性能指标列表,将在模型训练时监控列表中的指标
metrics=['accuracy'])
history = model.fit(
# 输入训练集图片
train_images,
# 输入训练集标签
train_labels,
# 设置10个epoch,每一个epoch都将会把所有的数据输入模型完成一次训练。
epochs=10,
# 设置验证集
validation_data=(test_images, test_labels))
plt.imshow(test_images[2])
pre = model.predict(test_images) # 对所有测试图片进行预测
plt.show()
print(pre[2])
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









