







一、Mathpix Markdown 和标准 Markdown 的语法区别规则
Mathpix Markdown 是一种扩展了标准 Markdown 的语法,主要用于科学和技术文档的编写,特别是在需要插入数学公式、化学方程式和复杂表格时。以下是 Mathpix Markdown 和标准 Markdown 的一些主要语法区别:
标准 Markdown 语法
- 标题:使用
#符号来创建标题,支持从#到######六级标题。 - 段落和换行:段落之间通过空行分隔,段落内部的强制换行需要在行末尾插入两个空格。
- 列表:无序列表使用
-、+或*作为标记,有序列表使用数字加点(如1.)。 - 表格:标准 Markdown 不支持表格,需要使用 HTML 代码来实现。
- 代码块:使用反引号(`)来创建行内代码,使用三个反引号来创建区块代码。
- 链接和图片:链接使用
[链接文本](URL)格式,图片使用格式。
Mathpix Markdown 语法
- 数学公式:支持 LaTeX 语法来插入数学公式。内联公式使用
$...$或\(...\),块级公式使用$$...$$、\[...\]、\begin{equation}...\end{equation}等。 - 表格:支持 LaTeX 的
tabular语法来创建复杂的表格。 - 化学方程式:支持使用 SMILES 标记来表示化学方程式。
- 公式编号与引用:可以使用 LaTeX 的公式编号和引用功能,如
\label{}和\ref{}。 - 其他扩展:支持更多的 LaTeX 环境和格式化选项,如定理环境、证明环境等。
Mathpix Markdown 保留了标准 Markdown 的基本语法,并在此基础上增加了对科学文档编写的支持,使其在处理复杂的数学和科学内容时更加高效和方便。
将这种Mathpix Markdown格式转化为
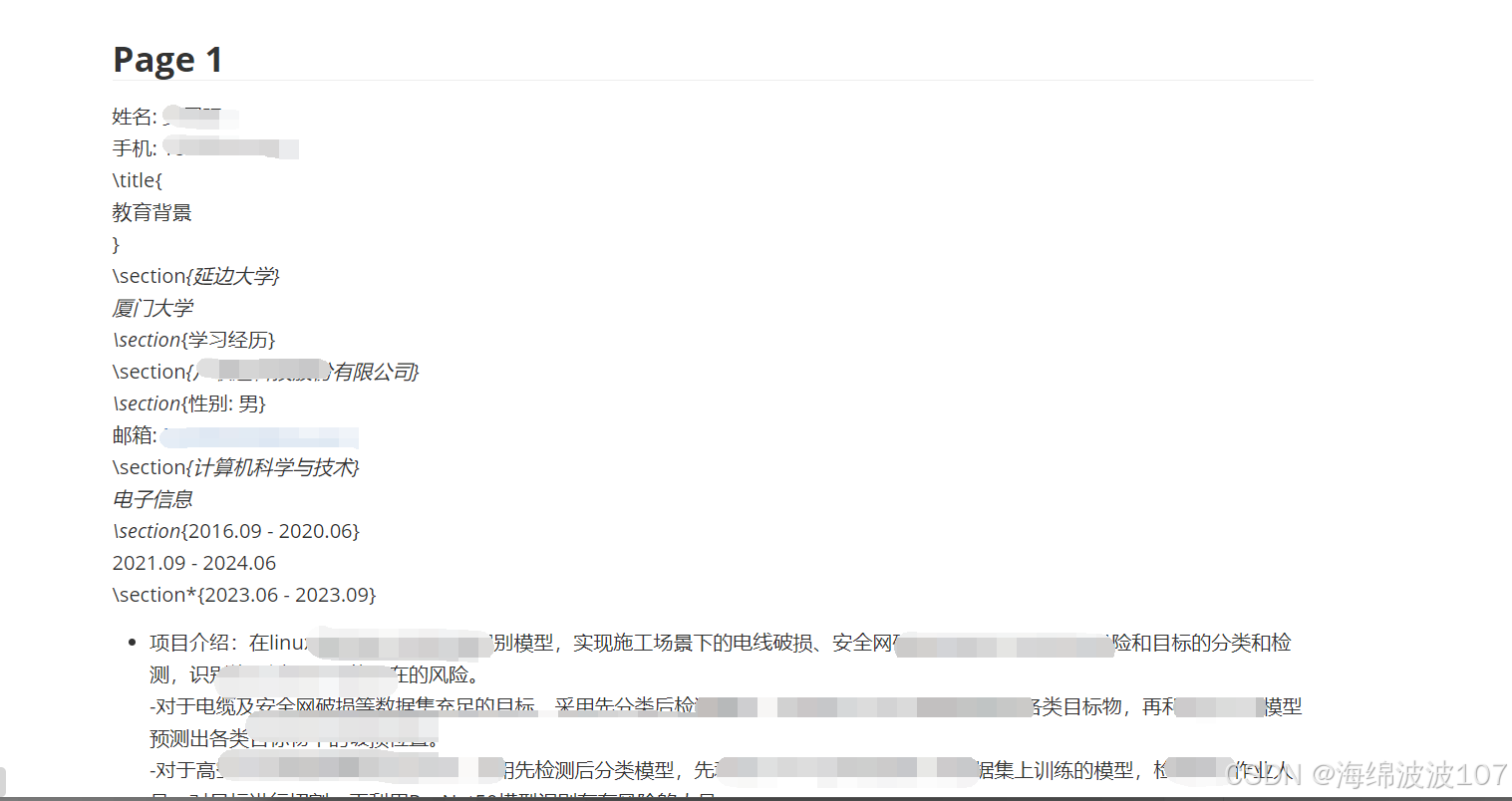
标准的markdown格式
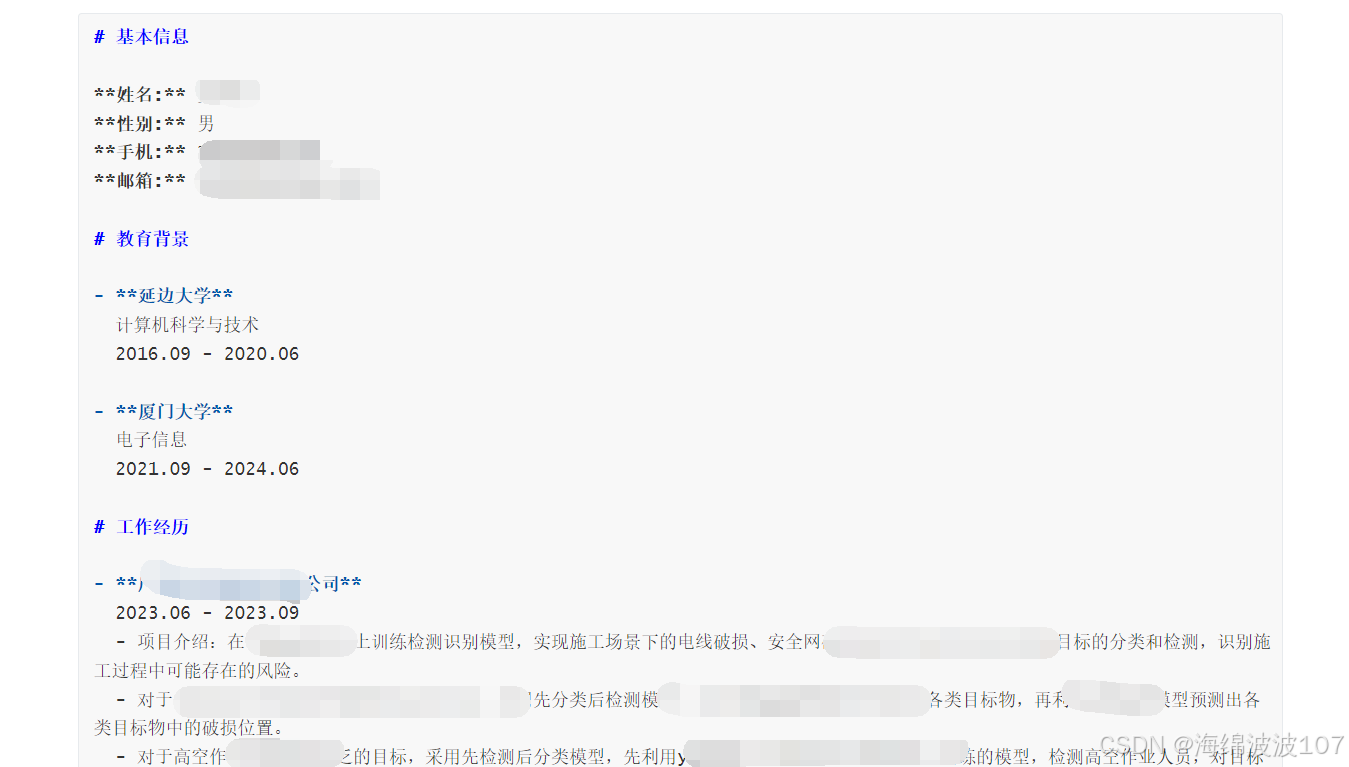

二、LLM转换
大模型出现后,很有用的功能就是文本转换,不需要再像之前一样写一堆正则表达式之类的规则进行提取,可以更加智能化,且能进行补充,这是正则表达式都做不到的事情。
使用LLM最重要的是提示词,尽可能多地添加注意事项(提取、补充规则),规定返回格式。而且指定输入的变量
"""
我现在需要你帮我把mathpix Markdown格式文件处理成正常的markdown文件。你
只需要返回文件内容,不需要返回任何其他内容。注意:1.务必保证信息完整,内容与原文
一致。2. 取消page页,保证内容连续 3.结合语义检查有些标题是否需要删除,比如错把
一句话作为标题的情况。4.结合语义检查是否有遗漏的标题,常见标题比如:基本信息/教
育背景/工作经历/科研经历/成果/奖励/个人技能。
mathpix Markdown的区别是:{MATHPIX_RULES}。
需要转化的文件内容是:
{mathpix_content}
"""
三、批量处理
确保打印台有时间的显示。这样子就能评估工程化所需的时间。
源代码
import os
import time
from langchain_community.chat_models import ChatOllama, ChatOpenAI
OPENAI_API_KEY='sk-xxx'
# 初始化 LLM 模型
## 使用openai
llm = ChatOpenAI(model='gpt-4o', temperature=0.1, api_key=OPENAI_API_KEY)
# Mathpix Markdown 和标准 Markdown 的语法区别规则
MATHPIX_RULES = """Mathpix Markdown addresses these limitations by adding support for the following standard Latex syntax elements which are already familiar to the scientific community:
- inline math via \\( <latex math> \\)
- block math via \\[ <latex math> \\] or $$ <math> $$
- tables via \\begin{tabular} ... \\end{tabular}
- figures and figure captions via \\begin{figure} \\caption{...} ... \\end{figure}
- lists: unordered lists via \\begin{itemize} ... \\end{itemize} and ordered lists via \\begin{enumerate} ... \\end{enumerate}
- numbered and unnumbered equation environments \\begin{elem} ... \\end{elem} and \\begin{elem*} ... \\end{elem*} where elem=equation|align|split|gather
- equation, table, and figure references via \\label, \\ref, \\eqref, \\tag
- text formatting options \\title{...}, \\author{...}, \\begin{abstract}...\\end{abstract}, \\section{Section Title}, \\subsection{Section Title}, \\subsubsection{Section Title}, \\textit{italicized text}, \\textbf{bold text}, \\url{link}
- chemistry equation via <smiles>OC(=O)c1cc(Cl)cs1</smiles> or"""
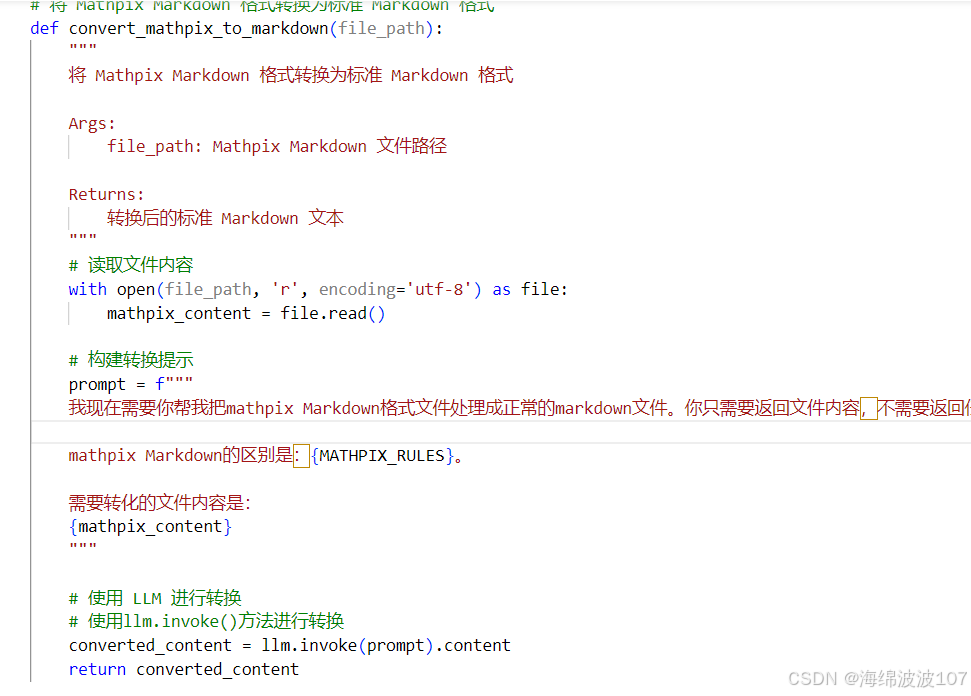
# 将 Mathpix Markdown 格式转换为标准 Markdown 格式
def convert_mathpix_to_markdown(file_path):
"""
将 Mathpix Markdown 格式转换为标准 Markdown 格式
Args:
file_path: Mathpix Markdown 文件路径
Returns:
转换后的标准 Markdown 文本
"""
# 读取文件内容
with open(file_path, 'r', encoding='utf-8') as file:
mathpix_content = file.read()
# 构建转换提示
prompt = f"""
我现在需要你帮我把mathpix Markdown格式文件处理成正常的markdown文件。你只需要返回文件内容,不需要返回任何其他内容。注意:1.务必保证信息完整,内容与原文一致。2. 取消page页,保证内容连续 3.结合语义检查有些标题是否需要删除,比如错把一句话作为标题的情况。4.结合语义检查是否有遗漏的标题,常见标题比如:基本信息/教育背景/工作经历/科研经历/成果/奖励/个人技能。
mathpix Markdown的区别是:{MATHPIX_RULES}。
需要转化的文件内容是:
{mathpix_content}
"""
# 使用 LLM 进行转换
# 使用llm.invoke()方法进行转换
converted_content = llm.invoke(prompt).content
return converted_content
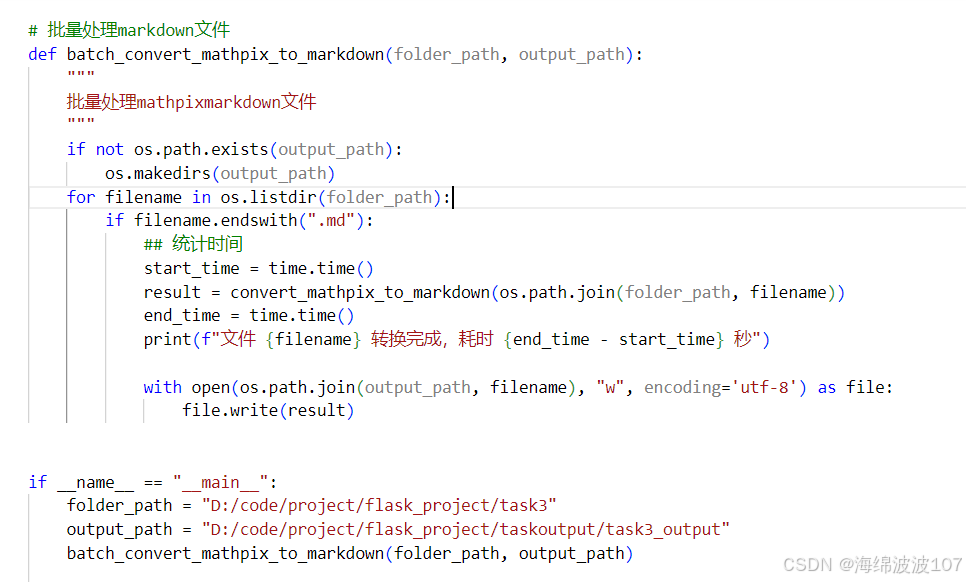
# 批量处理markdown文件
def batch_convert_mathpix_to_markdown(folder_path, output_path):
"""
批量处理mathpixmarkdown文件
"""
if not os.path.exists(output_path):
os.makedirs(output_path)
for filename in os.listdir(folder_path):
if filename.endswith(".md"):
## 统计时间
start_time = time.time()
result = convert_mathpix_to_markdown(os.path.join(folder_path, filename))
end_time = time.time()
print(f"文件 {filename} 转换完成,耗时 {end_time - start_time} 秒")
with open(os.path.join(output_path, filename), "w", encoding='utf-8') as file:
file.write(result)
if __name__ == "__main__":
folder_path = "D:/code/project/flask_project/task3"
output_path = "D:/code/project/flask_project/taskoutput/task3_output"
batch_convert_mathpix_to_markdown(folder_path, output_path)
# 测试单个文件
# start_time = time.time()
# content = convert_mathpix_to_markdown("d:/code/rag_hr/gotocr_result/result7/李飞工作简历.md")
# end_time = time.time()
# print(f"耗时 {end_time - start_time} 秒")
# with open(os.path.join(folder_path, "output.md"), 'w', encoding='utf-8') as file:
# file.write(content)


















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











