







参考博客-zhiguo98
个人体会:Inception块需要卷积核与池化层保证same.多个分支才能拼接成同样大小的块,区别是各个分支的通道数不同,最后由反向传递自己选择哪一个分支作为中间层.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=True)
# 构建Inception模型
class MyInception(nn.Module):
def __init__(self, in_channels):
super(MyInception, self).__init__()
# 以下所有卷积核以及池化层都是same操作
# 第一个分支 (1,28,28)
self.branch1 = nn.Conv2d(
in_channels=in_channels,
out_channels=16,
kernel_size=1
)
# 第二个分支
self.branch2 = nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=16,
kernel_size=1
),
nn.Conv2d(
in_channels=16,
out_channels=24,
kernel_size=5,
padding=2
)
)
# 第三个分支
self.branch3 = nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=16,
kernel_size=1
),
nn.Conv2d(
in_channels=16,
out_channels=24,
kernel_size=3,
padding=1
),
nn.Conv2d(
in_channels=24,
out_channels=24,
kernel_size=3,
padding=1
)
)
# 第四部分
# self.branch4 = nn.Conv2d(in_channels, 24, kernel_size=1)
self.branch4 = nn.Sequential(
nn.AvgPool2d(
kernel_size=3,
stride=1,
padding=1
),
nn.Conv2d(
in_channels=in_channels,
out_channels=24,
kernel_size=1
)
)
def forward(self, x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3 = self.branch3(x)
# same池化
# branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
b4 = self.branch4(x)
output = [b1, b2, b3, b4]
return torch.cat(output, dim=1)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.incep1 = MyInception(in_channels=10)
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep2 = MyInception(in_channels=20)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(1408, 10)
def forward(self, x):
batch_size = x.size(0)
x = self.mp(F.relu(self.conv1(x))) # (1,28,28)->(10,24,24)->(10,12,12)
x = self.incep1(x) # (10,12,12)->(88,12,12)
x = self.mp(F.relu(self.conv2(x))) # (88,12,12) -> (20,8,8) -> (20,4,4)
x = self.incep2(x) # (20,4,4) -> (88,4,4)
x = x.view(batch_size, -1) # (batch_size,84*4*4)
x = self.fc(x)
return x
model = Net().to('cuda' if torch.cuda.is_available() else 'cpu')
# 损失函数
loss_func = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.5)
costs = []
# 训练网络
def train(epoch):
batch_loss = 0
for step, (data) in enumerate(train_loader):
inputs, labels = data
if torch.cuda.is_available():
inputs = inputs.cuda()
labels = labels.cuda()
optimizer.zero_grad()
output = model(inputs)
loss = loss_func(output, labels)
loss.backward()
optimizer.step()
costs.append(loss)
batch_loss += loss.item()
if step % 300 == 299:
print(f'epoch:{epoch},step:{step + 1},mini_loss:{batch_loss / 300:.3f}')
batch_loss = 0
# 测试网络
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, labels = data
if torch.cuda.is_available():
inputs = inputs.cuda()
labels = labels.cuda()
output = model(inputs)
_, predicted = torch.max(output, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum()
print(f'测试集上的准确率为:{correct / total * 100:.3f}%')
if __name__ == '__main__':
for epoch in range(3):
train(epoch)
test()
# 绘制图片:此时的costs里面的数据是tensor类型,如果是gpu上跑的就是cuda,需要将他转换成array
print(costs)
if torch.cuda.is_available():
costs = [cost.cpu().detach().numpy() for cost in costs]
else:
costs = [cost.numpy() for cost in costs]
print(costs)
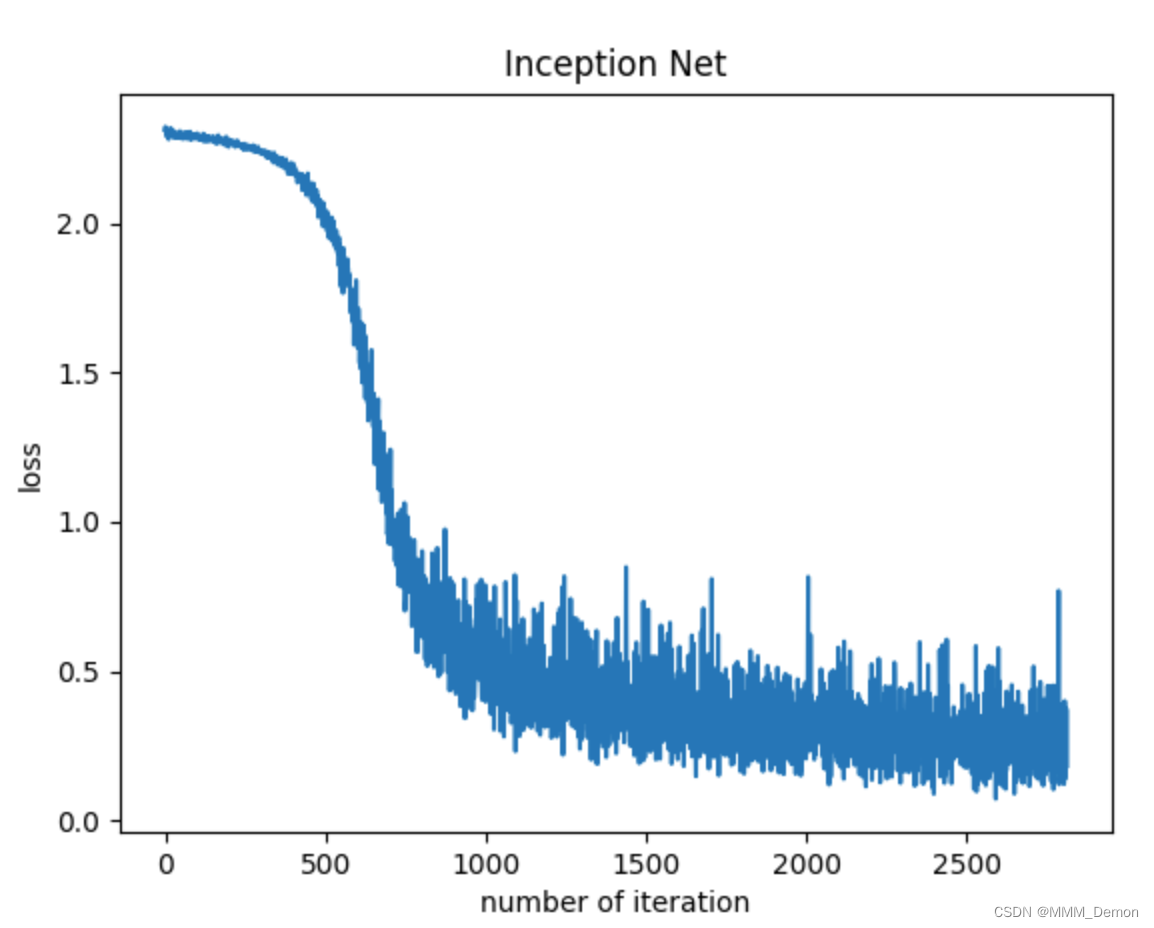
plt.plot(costs)
plt.xlabel('number of iteration')
plt.ylabel('loss')
plt.title('Inception Net')
plt.show()
图片:














 3242
3242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









