








目录
一、相关背景和研究目标
2012年,Alexnet网络是由Geoffrey和他的学生Alex在2012年的ILSVRC竞赛上提出,Alexnet属于经典的卷积神经网络的衍生,本次主要目的为利用pytorch框架复现Alexnet网络实现对minist数据集的手写数字进行识别。
二、Alexnet网络主要结构
AlexNet网络结构相对简单,它的隐含层共有8层,其中前五层为卷积层,后三层为全连接层,Alexnet网络结构在当时有好几个创新点,其中包括使用多GPU训练,该方案在当时确实具有极大的优势,但是,在如今的时代,单GPU就已经可以完成该项目了,其结果简图如下。

Alexnet的最大的优点在于使用了ReLU非线性激活函数,其表达式为
尽管从表达式中看到函数的两个部分都是线性的,但该函数事实上本身不满足叠加性。
(激活函数:对于一大堆数据集,它本身是非线性的,无论使用多少线性变换叠加成的神经网络,都是线性的,激活函数将线性转化为非线性的激活过程)
Alexnet的另一个优点在于使用了8层卷积神经网络,前5层是卷积层,剩下的3层是全连接层
2.1 卷积层
卷积的计算公式为,其中P为padding,代表padding的像素数,s即是步长,W为W*W的输入图片大小,F为卷积核或池化核的大小。
此处要进行多次计算以得到输入输出层的图片大小,但事实上从应用角度可以直接调用库函数,此处只举一层的例子
C1(第一层):卷积–>ReLU–>池化
卷积:输入1×224×224 (单通道,长×宽),96个1×11×11×1的卷积核,扩充边缘padding = 2,步长stride = 4,因此其FeatureMap大小为(224-11+0×2+4 )/4+1= 55,即48×55×55;输入输出层次由函数定义,唯一需要注意的是有两层没有最大池化操作这点在代码中有所体现
激活函数:ReLU;
池化:池化核大小3 × 3,不扩充边缘padding = 0,步长stride = 2,因此其FeatureMap输出大小为(55-3)/2+1=27, 即C1输出为48×27×27
2.2全连接层
全连接层各层节点全相连,将特征分布到样本标记空间,从而起到分类作用。
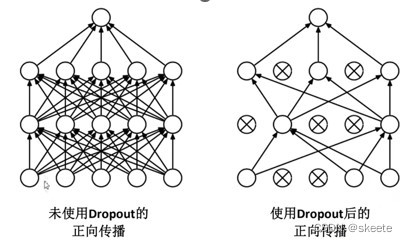
全连接层有一个重要的操作,dropout函数,它以0.5的概率去除了前向通道中的神经节点,从而防止了过拟合。
2.3 pytorch代码实现
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=10, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential( #对于深层次的网络采用sequential进行打包使得其更加整洁
nn.Conv2d(1, 48, kernel_size=11, stride=4, padding=2),#卷积层
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(48, 128, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(128, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(#全连接层
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):#前向
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):#初始化权重,据说这种方法在需要套用别人的训练结果时有用
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)三、训练模型
import os
import sys
#import json
#from PIL import Image
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets, utils
#import matplotlib.pyplot as plt
#import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
loss_list = [] # 定义几个空列表方便可视化
acc_list = []
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")#这里始终切不到GPU1(存疑)
print("using {} device.".format(device))
# 训练集预处理
train_transform = transforms.Compose([torchvision.transforms.Resize(244),
# transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor()
#torchvision.transforms.Normalize((0.5,), (0.5,))
])
#测试集预处理
test_transform = transforms.Compose([transforms.Resize(244),
transforms.ToTensor(),
#transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# img=Image.open("F:/data_set/minst/train/0_0.png")
# img1=train_transform(img)
#加载数据集
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path,data_set之前
image_path = os.path.join(data_root, "data_set", "minst") # minst set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = torchvision.datasets.MNIST(root='F:/data_set/minst/train', train=True,
download=True, transform=train_transform)#torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
# torchvision.transforms.Normalize(
# (0.1307,),(0.3081,)
# )
# ]))#后一个参数表示预处理,这里的TRUE可以直接从网上下载数据集
train_num = len(train_dataset) # 记录训练集的总数
batch_size = 100
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
test_dataset = torchvision.datasets.MNIST(root='F:/data_set/minst/train',
train=False, download=True,
transform=test_transform)
test_num = len(test_dataset)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=100, shuffle=False,
num_workers=nw)
net = AlexNet(num_classes=10, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
# pata = list(net.parameters())
optimizer = optim.Adam(net.parameters(), lr=0.0002)
epochs = 10
save_path = './AlexNet.pth'
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
running_loss += loss.item()
loss_list.append(loss.item()) # 存每次的loss值,每迭代一次就会产生一次loss值
with open("./train_loss.txt", 'w') as train_loss:#在该目录下打开一个文件存一下数据
train_loss.write(str(loss_list))
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# test,说是测试集实际上更应该是验证集
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
test_bar = tqdm(test_loader, file=sys.stdout)
for test_data in test_bar:
test_images, test_labels = test_data
outputs = net(test_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, test_labels.to(device)).sum().item()
test_accurate = acc / test_num
acc_list.append(test_accurate)
with open("./train_acc.txt", 'w') as train_acc:
train_acc.write(str(acc_list))#这里存入了acc
if test_accurate > best_acc:
best_acc = test_accurate
torch.save(net, save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, test_accurate))
print('Finished Training')
if __name__ == '__main__':
main()
四、绘制loss曲线
4.1 代码实现
import numpy as np
import matplotlib.pyplot as plt
# 读取存储为txt文件的数据
def data_read(dir_path):
with open(dir_path, "r") as f:
raw_data = f.read()#读取原始数据,这里读出来是带, 的字符串
data = raw_data[1:-1].split(", ")#切片后划分变到列表
return np.asfarray(data, float)#返回该列表的数组
# 不同长度数据,统一为一个标准,倍乘x轴,没啥意义
# def multiple_equal(x, y):
# x_len = len(x)
# y_len = len(y)
# times = x_len/y_len
# y_times = [i * times for i in y]
# return y_times
if __name__ == "__main__":
train_loss_path = r"F:\AIPY\CNNm\train_loss.txt"
train_acc_path = r"F:\AIPY\CNNm\train_acc.txt"
y_train_loss = data_read(train_loss_path)
y_train_acc = data_read(train_acc_path)
x_train_loss = range(len(y_train_loss))
x_train_acc = range(len(y_train_acc))
# 去除顶部和右边框框,不去除也无所谓
#ax = plt.axes()
#ax.spines['top'].set_visible(False)
#ax.spines['right'].set_visible(False)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.xlabel('iteration')#迭代次数
plt.ylabel('loss')
plt.plot(x_train_loss, y_train_loss, linewidth=1, linestyle="solid", label="train loss")
plt.title('loss curve')
plt.subplot(1, 2, 2)
plt.xlabel('epoch')
plt.ylabel('acc')
plt.plot(x_train_acc, y_train_acc, color='red', linestyle="solid", label="train accuracy")
plt.legend()
plt.title('Accuracy curve')
plt.show()4.2 运行结果

五、P-R曲线与ROC曲线
5.1 代码实现
import os
import sys
import prettytable
import json
from PIL import Image
import torch
import torch.nn as nn
import torchvision
from contourpy.util import data
from torch.nn import functional as F
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
from sklearn.metrics import precision_recall_curve, roc_curve
def main():
device = torch.device("cpu")#开CPU
print("using {} device.".format(device))
# 测试集预处理
batch_size=100
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # 开工作区
test_transform = transforms.Compose([transforms.Resize(244),
transforms.ToTensor(),
])
test_dataset = torchvision.datasets.MNIST(root='F:/data_set/minst/train',
train=False, download=True,
transform=test_transform)
test_num = len(test_dataset)#图片总数
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=100, shuffle=False,
num_workers=nw)
#加载模型
model=torch.load('AlexNet.pth')
model.eval()
model.to(device)
pred_list = torch.tensor([])#建tensor
with torch.no_grad():
test_bar = tqdm(test_loader, file=sys.stdout)
for X, y in test_bar:
pred = model(X)
pred_list =torch.cat([pred_list, pred])#将每一次测试得到的张量拼合起来
test_iter1 = torch.utils.data.DataLoader(test_dataset, batch_size=10000, shuffle=False,
num_workers=2)#迭代数据保存标签和图片
features, labels = next(iter(test_iter1))#调用迭代器,可迭代对象有it方法还可调用next就是迭代器
print(labels.shape)
#test_loader1=torch.utils.data.DataLoader(test_dataset,
# batch_size=10000, shuffle=False,
# num_workers=nw)
#features, labels = next(iter(test_loader1))
#print(labels.shape)#记录一下本身的标签
#可视化P与R值,这里是在计算整个过程中的值
train_result = np.zeros((10, 10), dtype=int)#10*10零张量
for i in range(test_num):
train_result[labels[i]][np.argmax(pred_list[i])] += 1#取出最大可能为对应的预测值,每出现一次就加一
result_table = prettytable.PrettyTable()
result_table.field_names = ['Type', 'Accuracy(精确率)', 'Recall(召回率)', 'F1_Score']
class_names = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine']
for i in range(10):#计算从0到9各个类别的PR
accuracy = train_result[i][i] / train_result.sum(axis=0)[i]#准确值,axis=0表示列求和,TP/tp+fn,0和把其他的也识别成了0
recall = train_result[i][i] / train_result.sum(axis=1)[i]#召回率0和把0识别错了的
result_table.add_row([class_names[i], np.round(accuracy, 3), np.round(recall, 3),
np.round(accuracy * recall * 2 / (accuracy + recall), 3)])#加入相关数据到这个表格,np.round对数组进行四舍五入
print(result_table)
#归一化操作便于处理
pred_probilities = F.softmax(pred_list, dim=1)#用softmax函数将最后一层的输出转化为(0,1)间的概率
#绘制PR曲线与ROC曲线
for i in range(1):#调用十次,每次输出一个类
temp_true = []#用于预测结果存放,正确放1
temp_probilities = []
temp = 0
for j in range(len(labels)):
if i == labels[j]:
temp = 1
else:
temp = 0
temp_true.append(temp)#一旦预测准确就加入1,#真实标签
temp_probilities.append(pred_probilities[j][i])#预测概率
precision, recall, threshholds = precision_recall_curve(temp_true, temp_probilities)
fpr, tpr, thresholds = roc_curve(temp_true, temp_probilities)#FPR=TP/(TP+FN),TPR=FP/(FP+TN)
#开始绘图
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)#创建子图,一行二列第一个,一行二列第二个
plt.xlabel('Precision')
plt.ylabel('Recall')
plt.title(f'Precision & Recall Curve (class:{i}) ')#加f表示格式化字符串
plt.plot(precision, recall, 'yellow')
plt.subplot(1, 2, 2)
plt.xlabel('Fpr')
plt.ylabel('Tpr')
plt.title(f'Roc Curve (class:{i})')
plt.plot(fpr, tpr, 'cyan')
plt.show()
if __name__ == '__main__':
main()5.2 运行结果

六、对单张图片进行预测
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import AlexNet
import matplotlib.pyplot as plt
classes = ('0', '1', '2', '3', '4', '5', '6', '7', '8', '9')#创建类便于输出结果
predict_transform=transforms.Compose([transforms.ToTensor(),
transforms.Resize(244),
#transforms.Normalize((0.5,),(0.5,))
])
net=AlexNet()
net.load_state_dict(torch.load('AlexNet.pth')) #加载以训练的模型load_state_dict这里是字典型号,我之前的训练存的是整个模型,注意分辨
image=Image.open('9.png')
image_gray=image.convert('L')#灰度图模式
image_gray=predict_transform(image_gray)
image_gray=torch.unsqueeze(image_gray,dim=0)
plt.imshow(image)
#plt.figure('number')
plt.axis('off')
plt.show()
with torch.no_grad():
outputs = net(image_gray)
predict_y = torch.max(outputs, dim=1)[1] #输出标签
print(classes[predict_y])参考链接
https://www.bilibili.com/video/BV1W7411T7qc/














 9187
9187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









