







python爬虫——爬取搜狗影视热门电视剧
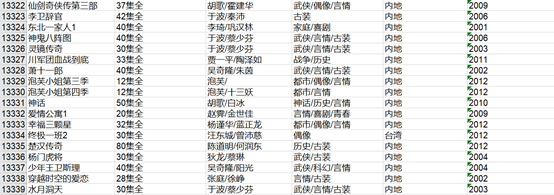
1.结果图





2.这次爬取的网址请点击传送门
搜狗影视热门电视剧
3.先构建请求头,请求头直接复制过来
4.接下来先请求这条url,通过format方法实现对url的拼接,以达到翻页的效果,通过查看接口内容,发现是js格式,热门电视剧的信息存储在’class’:'add-list-1’中



5.将数据存储为文件(json/xls)

1.worksheet.write(0,i,title[i])中
—0表示行
—i表示列
—title[i]表示写入的内容
6.完整代码
import requests
import bs4
import json
import xlwt
allData=[]
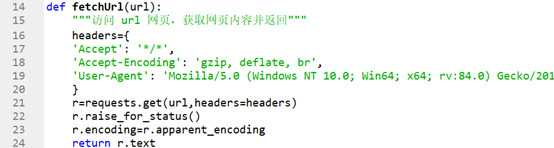
def fetchUrl(url):
"""访问 url 网页,获取网页内容并返回"""
headers={
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0',
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 7545
7545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









