







这里写目录标题
引言
深度学习中很多数据需要打标签,例如我现在就需要得到图像的二值掩码图像,比如下边,我想要得到一张掩码去标识图片上的缺陷区域,自已标是很困难的且费时费力

什么是半自动标注
·半自动标注·就是通过将SAM集成到label-studio中,然后在给数据打标的时候还是人工进行操作,但是只需要在图像上点一下就会自动识别并且打好标注了。其实其他文章,如基于 SAM 的半自动标注新方法,手把手教会你!,这里已经讲解相对是比较详细了,但是还是存在一些坑,这里再总结一下,其中下文很多东西都来自基于 SAM 的半自动标注新方法,手把手教会你!,
conda环境创建与启动
首先创建一个python3.9的环境,其他python版本肯定是可以的,但是很可能跟下文的配置出现兼容问题,这种很坑
conda create -n rtmdet-sam python=3.9 -y
conda最好配置下清华源然后再创建环境,同样下文会用到pip的环境,可以在下载的时候配置临时清华源或者永久的清华源,以下给出了他们的配置,需要自取
#conda删除之前的镜像源,恢复默认状态
conda config --remove-key channels
#conda添加镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
#显示检索路径
conda config --set show_channel_urls yes
#显示镜像通道
conda config --show channels
# pip临时使用清华源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
# pip永久配置清华源
pip install pip -U
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
环境启动
conda activate rtmdet-sam
playground下载
playground是运行的环境,需要在playground的label-anything目录下进行运行label-studio,首先到github下载,我是直接到仓库下载然后下载zip文件的,使用git拉取也行
https://github.com/open-mmlab/playground
点击zip下载
然后解压出来就行
pytorch下载(Linux服务端和Win10客户端)
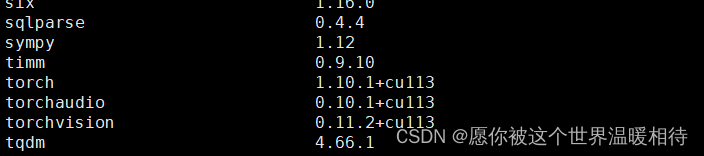
首先在的版本信息如下,我用的是GPU的
torch===1.10.1+cu113
torchvision===0.11.2+cu113
torchaudio===0.10.1+cu113
如果是cpu的,直接通过以下下载,如果pip配置了清华源,那下载还是很快的。但是使用cpu进行推理是要慢一点的
pip3 install torch torchvision torchaudio
如果用的是gpu,可以继续看这里,我直接在国内的镜像源中通过whl文件安装pytorch,地址如下
https://download.pytorch.org/whl/torch_stable.html
这里有个小技巧,就是直接搜索cu113就可以找到了,然后去找对应上边的版本,如果你是windows的话,要选带win的那个文件下载,linux的话要选带类inux的,如下边的cp39表示用的是python3.9,就是我们的版本,amd64就是显卡信息了,看个人电脑配置了,如果不知道就选amd64的,一般都是这个

下载完毕以后,就可以直接通过pip进行安装了,如下,这里注意的是,应该先安装torch的whl,然后再试torchaudio和torchvision
# 首先切换到你放whl文件的目录
cd /path/pkg
# 然后通过pip进行安装,后边这么长一串,其实打torch-,然后按键盘上的tab键就会自动补全了
pip install torch-1.10.0+cu113-cp39-cp39-linux_x86_64.whl
安装完毕后通过pip list看一下,就是这样了
我是使用的局域网的服务器以及本地的win10进行实现的,所以上述配置需要在远程服务器以及本地的win10都弄一遍,如果是同一个设备就不需要
SAM安装和预训练权重添加
既然用到SAM,那肯定是需要源代码了,我这里同样是自己下载的,通过git也可以,地址如下,这里注意的是,你只需要在你的服务端,就是你运行模型的机器上下载并安装,我这里就是用的远程的linux服务器的,所以下载到远程的服务器中
https://github.com/facebookresearch/segment-anything
同样点击zip下载,然后下载即可
解压出来

然后通过pip安装
# 切换到SAM解压的目录,这里的地址打开应该长得像上图一样
cd /home/chen/label_studio/pkg/segment-anything-main
# 直接通过以下命令安装
pip install -e .
安装完毕以后就可以下载预训练的权重,就是别人训练好的模型,上边安装的仅仅是源代码,没有预训练的权重也是没用的,预训练的权重有三个,如下,我是直接下载的,下边三个地址,表示不同权重,直接粘贴到浏览器就会下载了。其中里边带的vit_b、vit_l、vit_h就代表不同的模型了
https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth
https://dl.fbaipublicfiles.com/segment_anything/sam_vit_l_0b3195.pth
https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
我就下了一个示例,如下

SAM相关库安装
pip install opencv-python pycocotools matplotlib onnxruntime onnx
问题1
上述SAM相关库安装是来自前文提到的文章的,但是还差一个库,就是timm,直接安装即可
pip install timm
安装 Label-Studio 和 label-studio-ml-backend
这里呢Label-Studio 就是客户端,就是你实际看到,用来打标的,label-studio-ml-backend就是服务端,。大概流程就是服务器通过label-studio-ml-backend启动后端服务,后端服务就加载模型,当用户在客户端操作的时候,就会向服务端发一张你操作的图像,然后服务端就会通过SAM对你操作的图像进行分割,然后返回给你,你就可以看到标注好的图像了。
首先呢,你只需要在服务端安装label-studio-ml-backend,我这里就是linux服务器了,然后只需要在客户端安装Label-Studio ,我这里就是我自己的win10,安装命令如下
pip install label-studio==1.7.3
pip install label-studio-ml==1.0.9
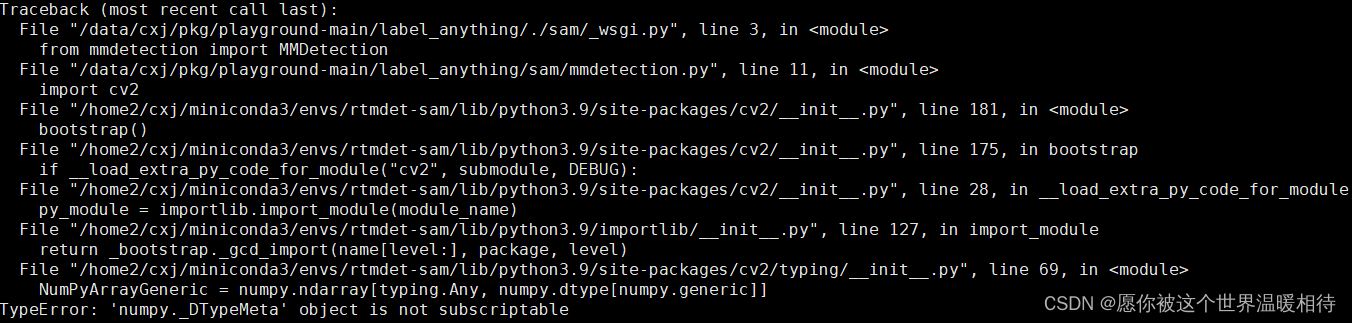
问题2:TypeError: ‘numpy._DTypeMeta’ object is not subscriptable
这里会有个问题,如果就是你客户端和服务端都在同一个机器,后续可能会存在numpy的兼容问题,就是上述安装的opencv-python的需要的numpy版本和你labeo-studio的冲突了,这里只需要更新一下numpy就行了
# 先卸载
pip uninstall numpy
# 再通过conda安装,这里最好用conda安装
conda install numpy
服务端配置和启动
上述基本就差不多了,然后就先需要启动服务端,服务端启动需要先切换到playground的label-anything目录,当然可以做映射这些环境配置,这里就不整了,然后通过以下命令启动
# 切换到你自己的
cd path/to/playground/label_anything
linux配置和启动
然后linux服务端就使用以下命令进行启动,参数可以才考下标配置
label-studio-ml start sam --port 8003 --with sam_config=vit_b sam_checkpoint_file=./sam_vit_b_01ec64.pth out_mask=True out_poly=True device=cuda:3
参数说明
- –port 8003:就是设置端口,
随便设,不冲突就行了 - sam_config=vit_b,就是你用的哪个模型,跟权重要对应
- sam_checkpoint_file=./sam_vit_b_01ec64.pth,这里权重中
vit_b要跟上边配置的模型一一对应,这里填的是你权重的路径,我是省事直接放到同目录下了,也可以放其他地方,地址对就行 - out_mask=True,表示输出的是掩码,
这里设置成True,那么在你打标的时候,后端就会给你返回掩码,什么是掩码呢?如下图,就是对整个模区域都给你标出来了,然后操作的时候,就是可以整体拖动的,这就是我想要的
- out_poly=True,这个就是多边形的注释,如下图如果设置为True就会同时得到多边形标注,打过标的应该都知道这种,就是一堆的点,可以任意拖拽上边的点,所有点组合成闭合的形状,拖到你想要的形状,而掩码就是只能整体拖动的

- out_bbox=True,这里就是会返回一个举行的框,里边就是标识的物体了
- device=cuda:3,这里就表示使用
cuda了,后边就是用哪个卡了,如果是cpu就改成device=cpu
注意:上边的out_xxx这些,你设置了什么,在一次预测就会返回设置了的,例如你同时设置了out_mask=True和out_poly=True,那么就会一次性得到两种标注,这个就看你个人需求了
windows配置和启动
如果你是windows环境,就可以用以下,上边配置环境变量,就一行行弄到提示符就行了
cd path/to/playground/label_anything
# 首先配置环境变量
$env:sam_config = "vit_b"
$env:sam_checkpoint_file = ".\sam_vit_b_01ec64.pth"
$env:out_mask = "True"
$env:out_bbox = "True"
$env:device = "cuda:0"
# 配置
label-studio-ml start sam --port 8003 --with sam_config=$env:sam_config sam_checkpoint_file=$env:sam_checkpoint_file out_mask=$env:out_mask out_bbox=$env:out_bbox device=$env:device
启动成功后就是下边这样,启动成功就可以看到地址的

客户端启动
客户端启动的时候还是需要切换到playground下的label_anything目录,注意:如果客户端和服务端在同一台机器,那只需要重新再开一个命令行界面就行了
# 切换到playground环境中
cd path/to/playground/label_anything
# 启动
label-studio start
vit-h模型后端配置
如果使用vit-h进行预测,这里可以根据刚才的命名可以看到,就需要进行超时重建连接,因为像vit-h这种模型预测时间长,服务端如果太久没回应,客户端就会报错 那么linux客户端就需要设置
export ML_TIMEOUT_SETUP=40
windows客户端则
# 配置环境变量
$env:ML_TIMEOUT_SETUP = "40"
# 设置
set ML_TIMEOUT_SETUP=ML_TIMEOUT_SETUP
客户端启动后就会在默认浏览器中自动打开一个界面,然后就注册一下,然后登录就行了
账户注册报错500
如果是严格按照上述版本,那在版本上时不会出现问题的(目前),如果存在问题就是防火墙的问题
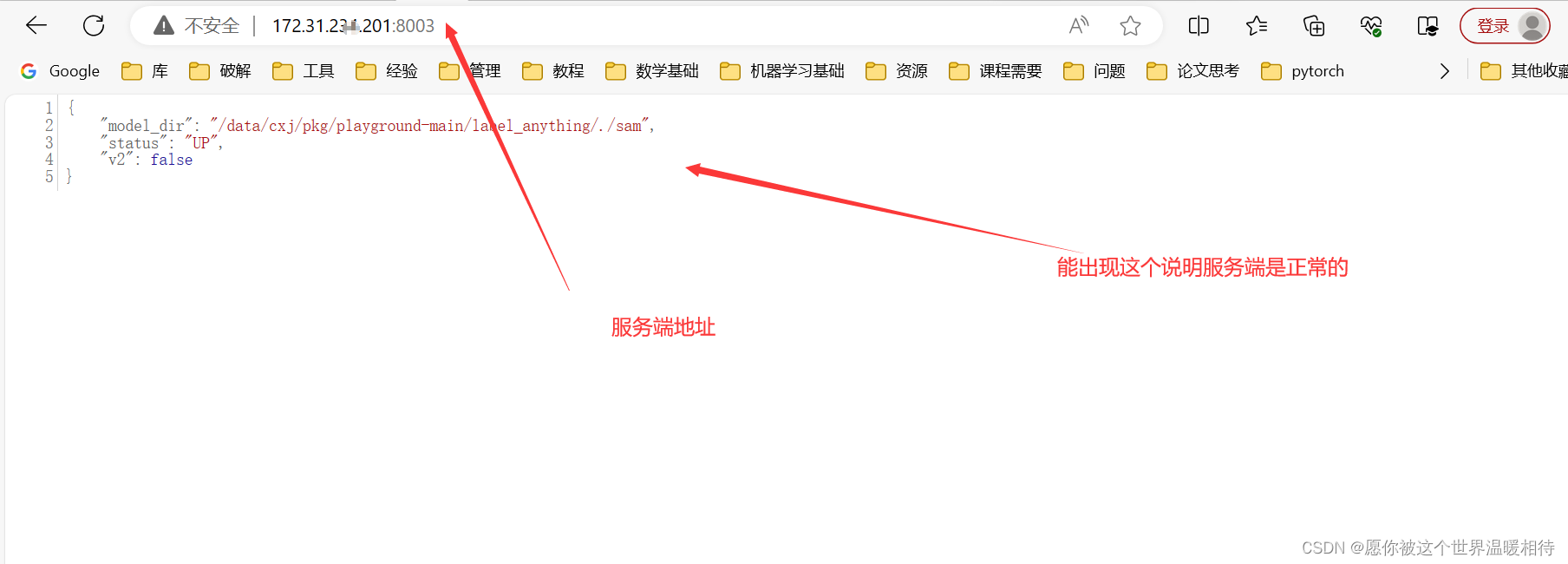
尝试输入刚才启动的后端的地址到浏览器中,如果出现以下界面说明是正常的,如果是一直在转,说明没连通,尝试关闭服务端防火墙看下能不能连通,一般都是防火墙的策略问题
创建项目和使用
创建账户后,首次会让你创建项目,其实就是创建你标注的任务
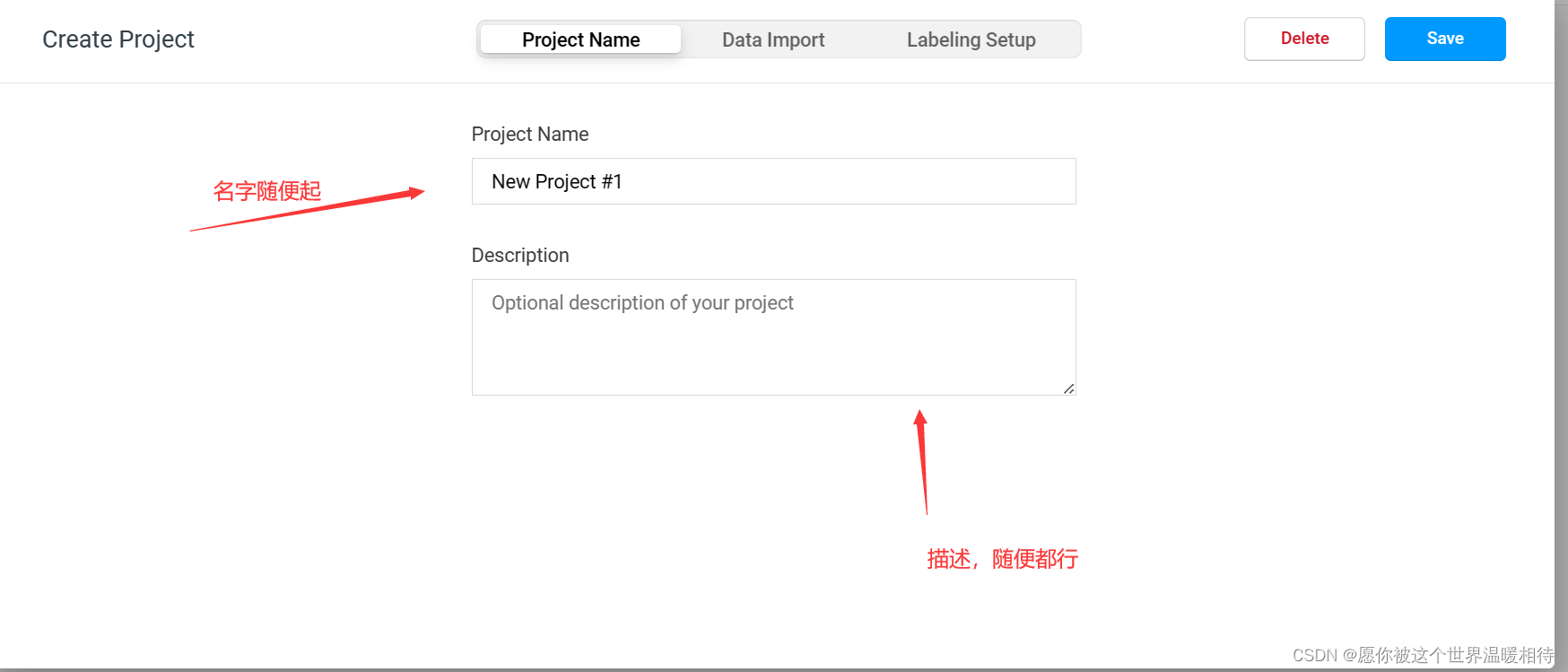
项目名称和描述
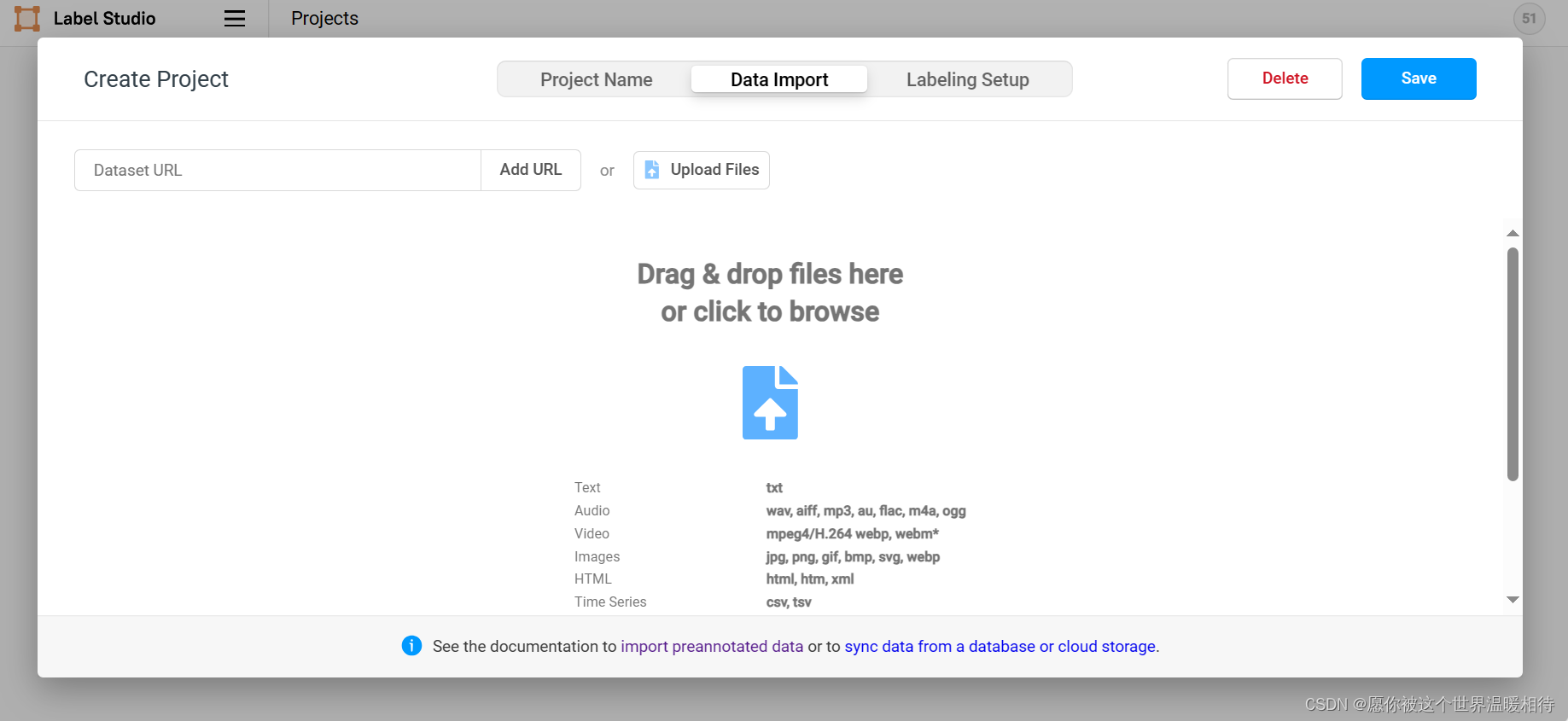
加载数据
点一下上传的图标或者是点upload就会跳转到本地
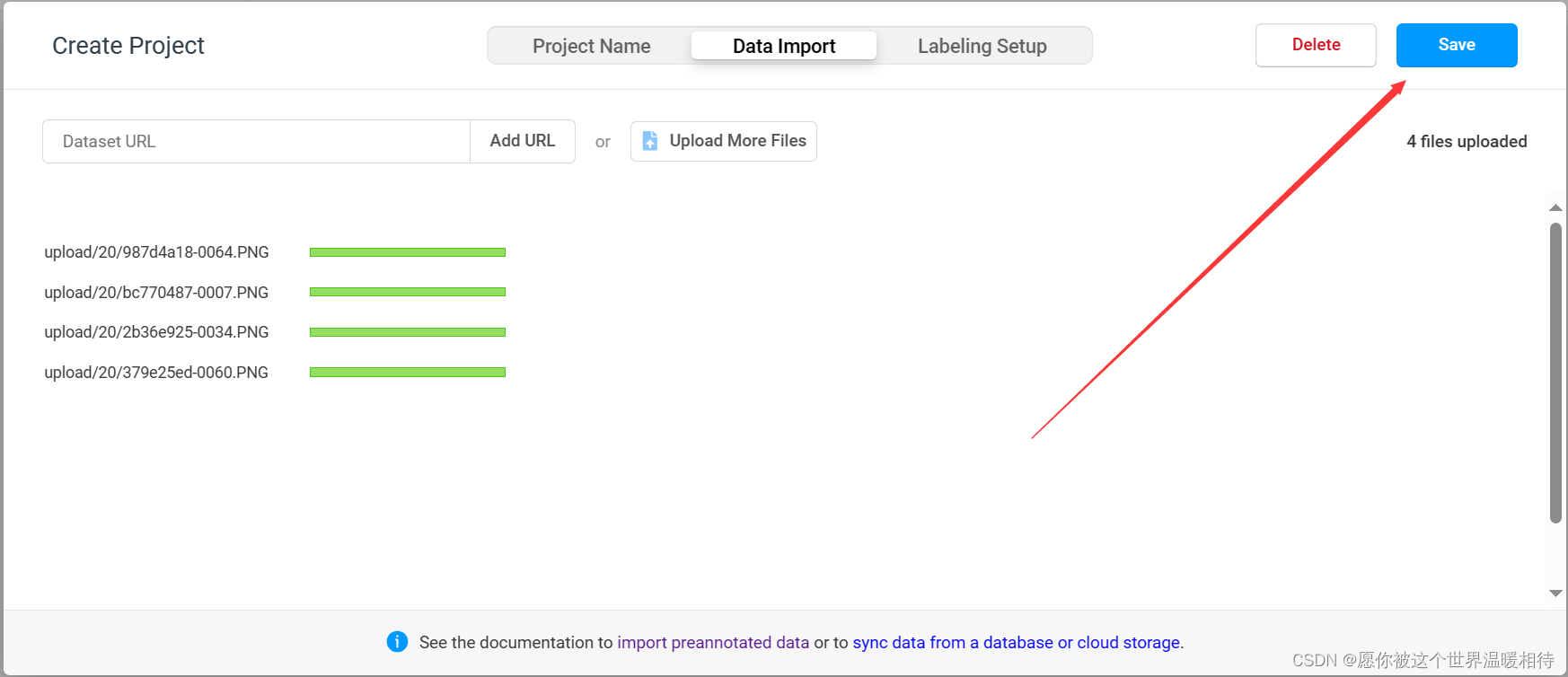
多选你想要标注的图像,然后确定

然后就可以保存了,至于隔壁的labelung setup,这里可以自行配置,这是什么,看完下文知道了
可以看到图像列表了
设置
点setting
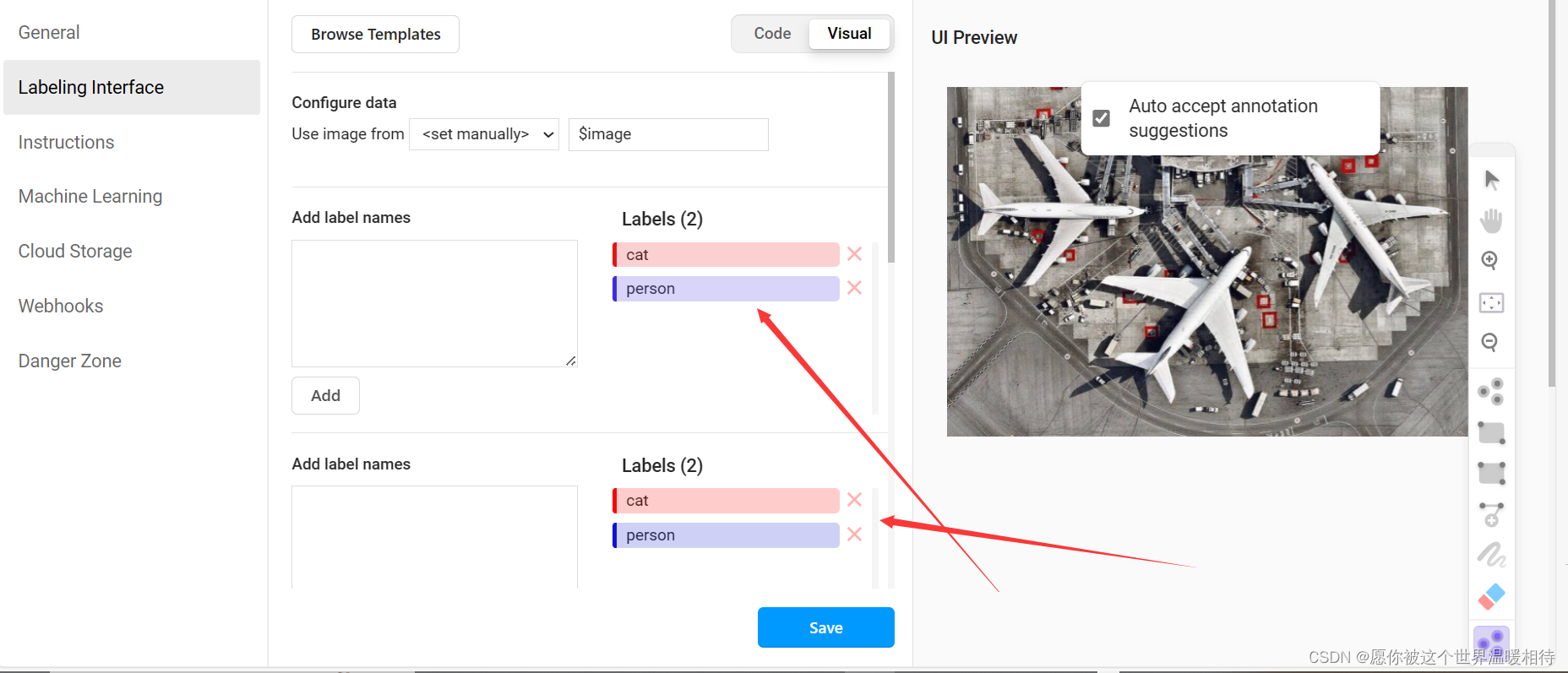
首先是进行标签配置,点击labeling interface,右边就是可以看到使用xml进行配置的区域了
这里给出官方的示例配置,包含4种标标注方式,分别是点标注方式,就是在目标上点一个点,矩形标注方式,就是拖拉鼠标出现矩形进行标注,然后是多边形标注方式,就是可以打多个点,然后绕成一个闭合多边形进行标注,最后就是掩码标注了
<View>
<Image name="image" value="$image" zoom="true"/>
<KeyPointLabels name="KeyPointLabels" toName="image">
<Label value="cat" smart="true" background="#e51515" showInline="true"/>
<Label value="person" smart="true" background="#412cdd" showInline="true"/>
</KeyPointLabels>
<RectangleLabels name="RectangleLabels" toName="image">
<Label value="cat" background="#FF0000"/>
<Label value="person" background="#0d14d3"/>
</RectangleLabels>
<PolygonLabels name="PolygonLabels" toName="image">
<Label value="cat" background="#FF0000"/>
<Label value="person" background="#0d14d3"/>
</PolygonLabels>
<BrushLabels name="BrushLabels" toName="image">
<Label value="cat" background="#FF0000"/>
<Label value="person" background="#0d14d3"/>
</BrushLabels>
</View>
黏贴上去就是这样
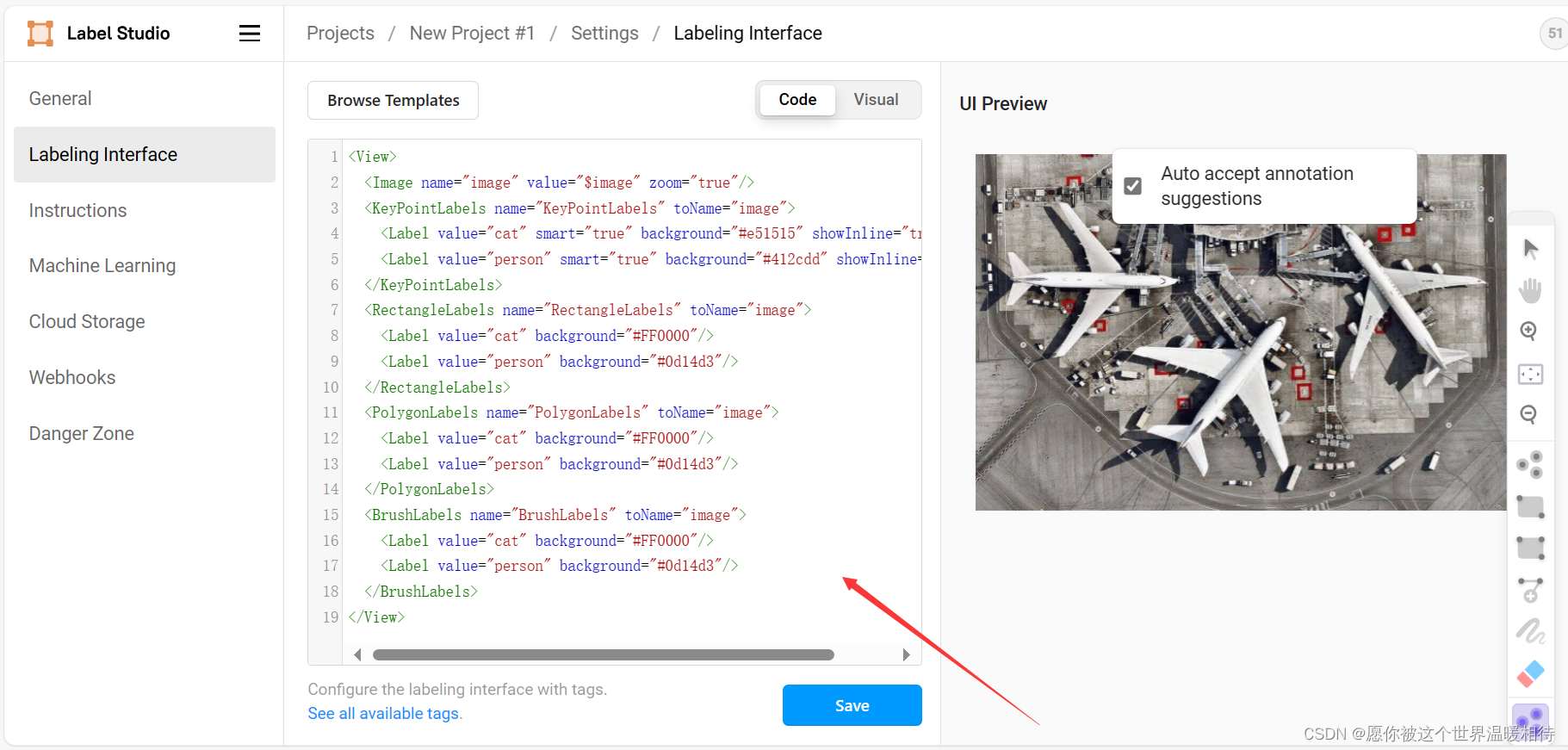
然后在code隔壁有个visual按钮,就是进行可视化的,这就是刚才设置的标签的可视化了,这里可以根据你自己数据想要什么标签去设置,这个跟后边的导出有关了
注意事项
刚才配置仅仅是一个完整例子,这里注意的是KeyPointLabels 是必须的,如果不配置将会报错,这是因为SAM的原因。然后其他的标注方式是根据你启动后端的时候,配置了什么就必须添加什么,例如启动后端时设置了out_poly=true,那你这里就必须放上多边形的标注标签配置其他也一样
然后搞定后记得保存

然后会跳出去
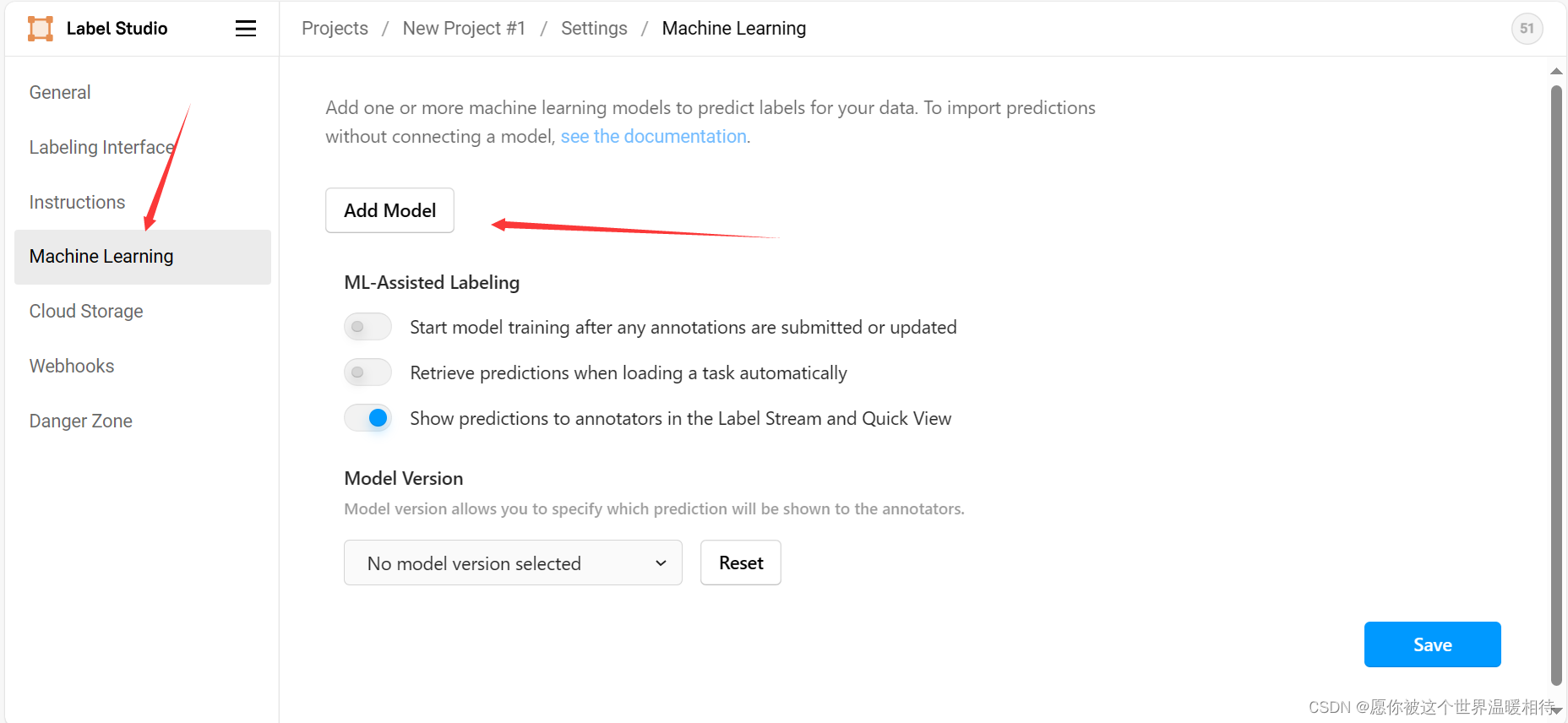
添加SAM模型
这一步就是关联预训练模型了。继续点击setting,机会回到设置中,然后点击Machin learning,然后点击Add Model
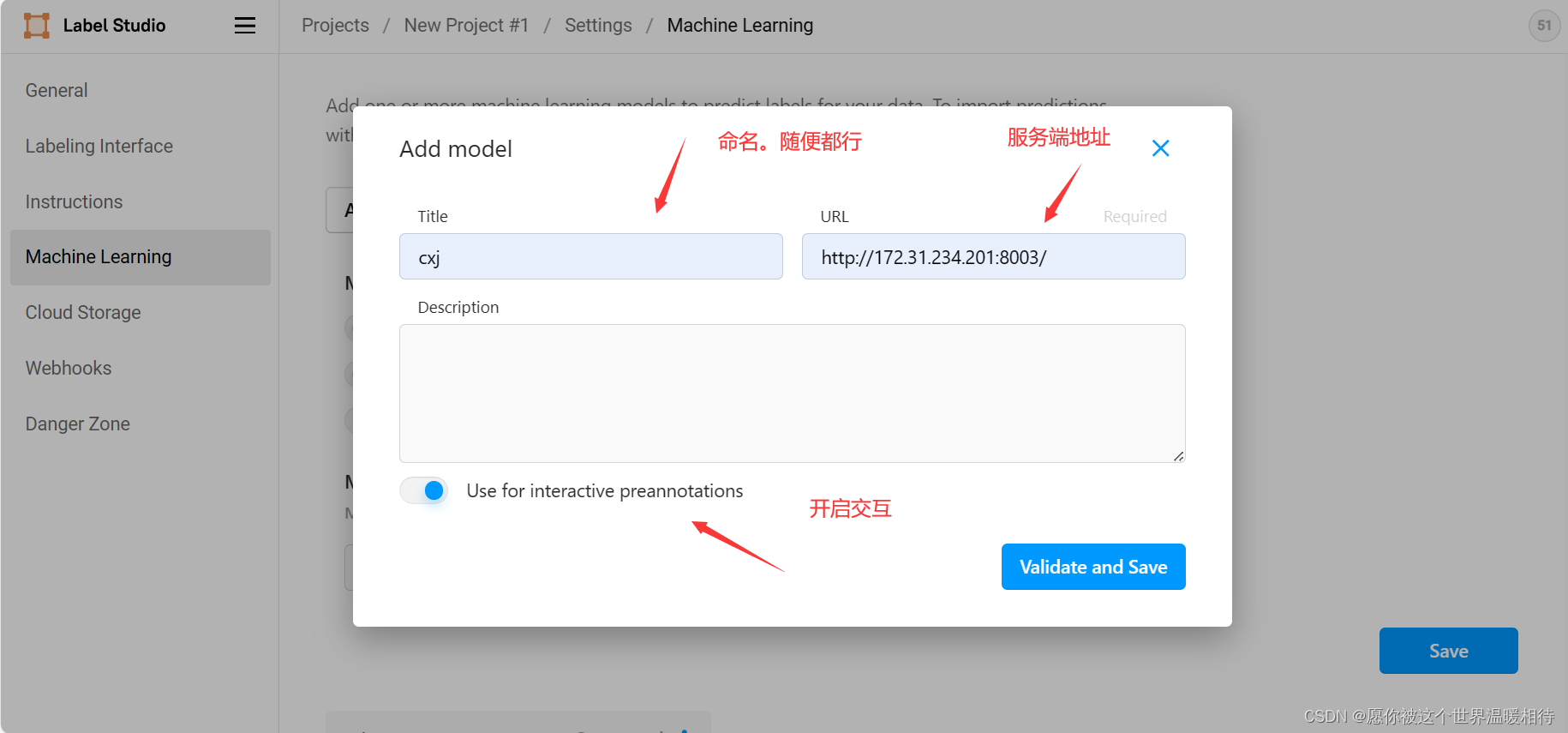
然后再里边进行填入信息,并开启交互
出现问题
下边的valiade and save,可能会出现问题,在这个界面下方会显示一段英文
Successfully connected to http://172.31.234.201:8003/ but it doesn't look like a valid ML backend. Reason: 500 Server Error: INTERNAL SERVER ERROR for url: http://172.31.234.201:8003/setup. Check the ML backend server console logs to check the status. There might be something wrong with your model or it might be incompatible with the current labeling configuration.
意思是连上了,但是出问题了,后边说可能是版本问题,这个就不要被迷惑了

解决这个问题,需要查看你的服务端,
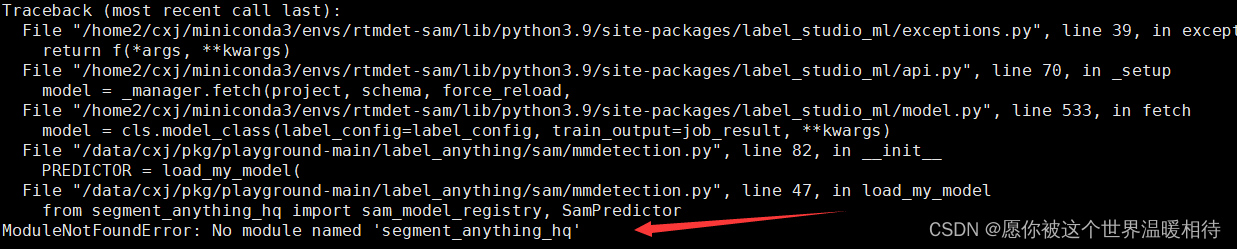 我这里可以看到,说找不到包了,那就安装吧
我这里可以看到,说找不到包了,那就安装吧
pip install segment_anything_hq
上述中,出现这个错误,都是服务端出现问题了,去看下就行了
成功就是下边那样了
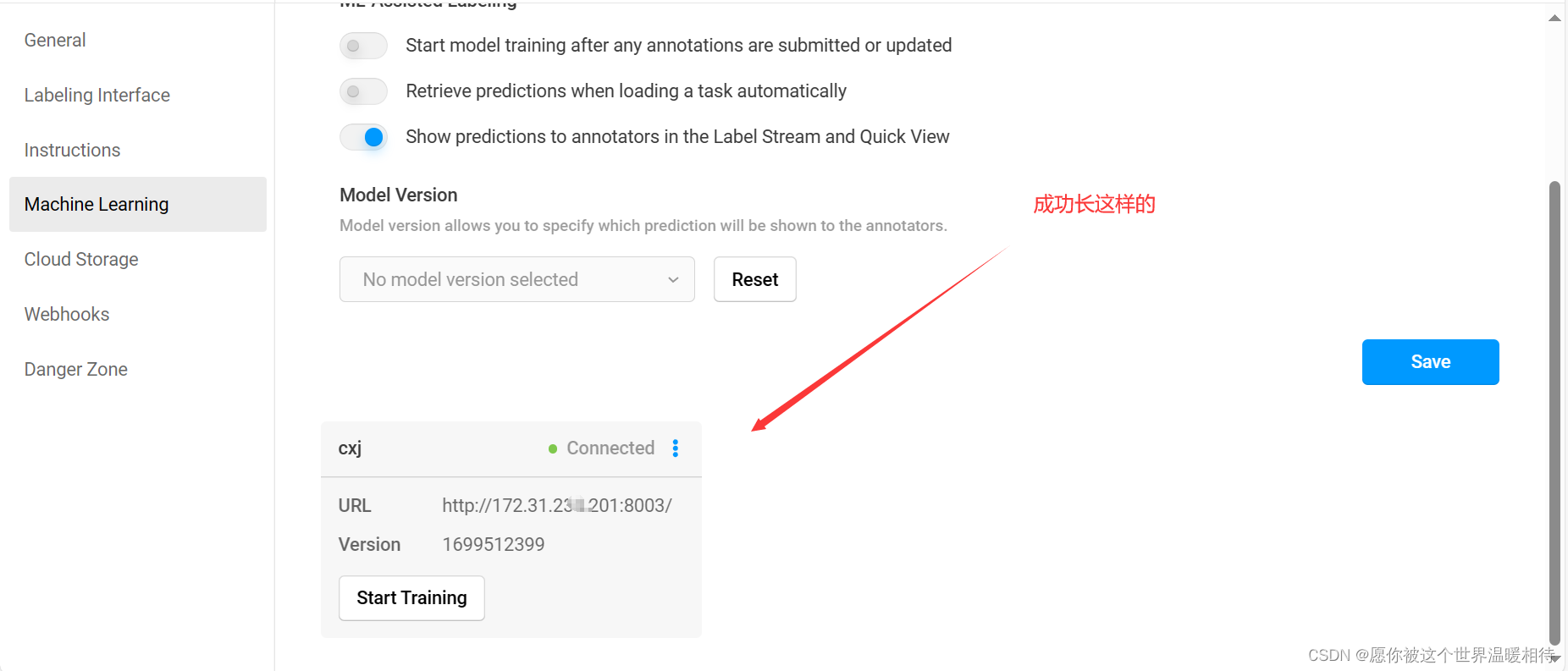
简单标注实例
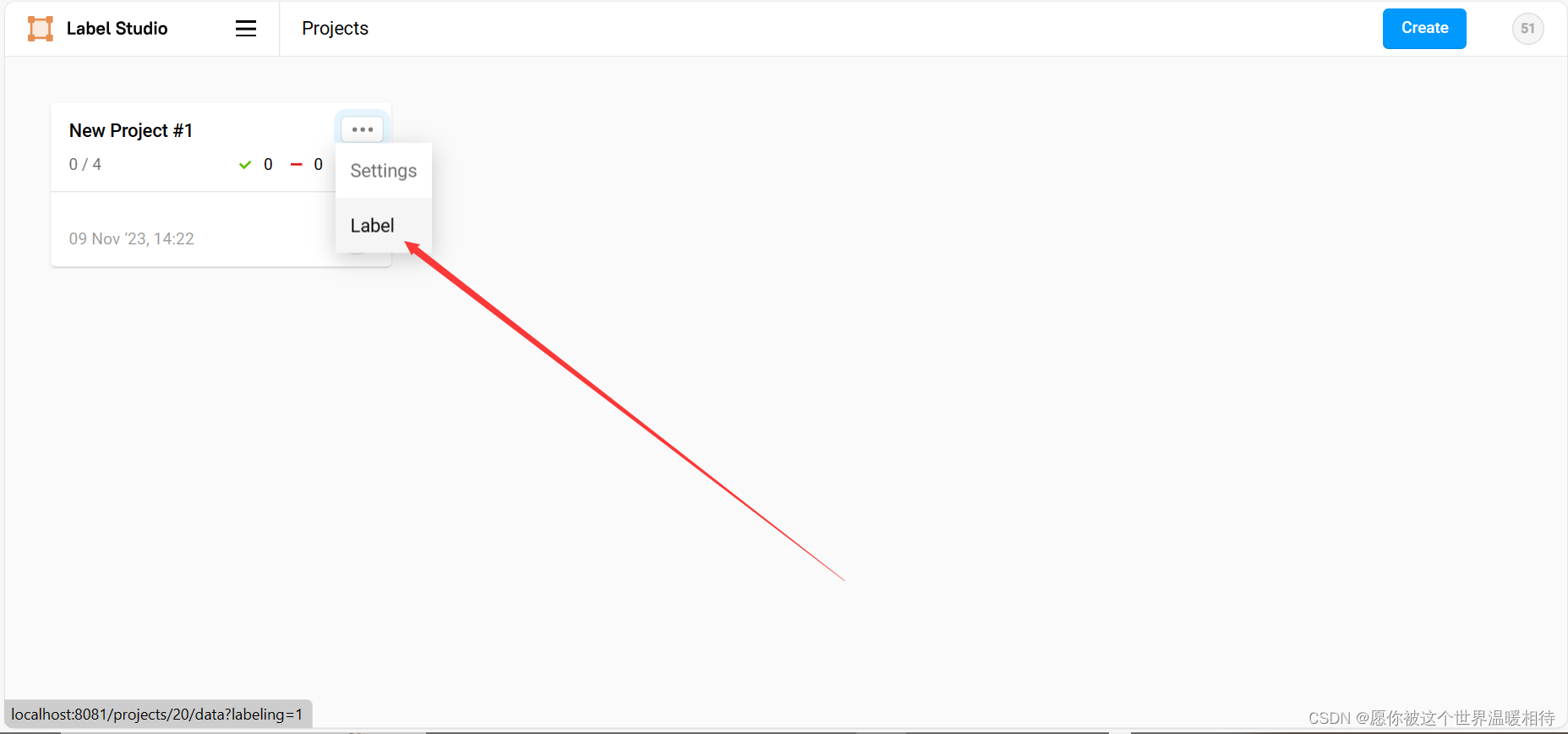
然后就可以打标了,打标有两个入口,一个是直接在项目外边点击label就可以了,或者点击项目,然后点击label All Tasks
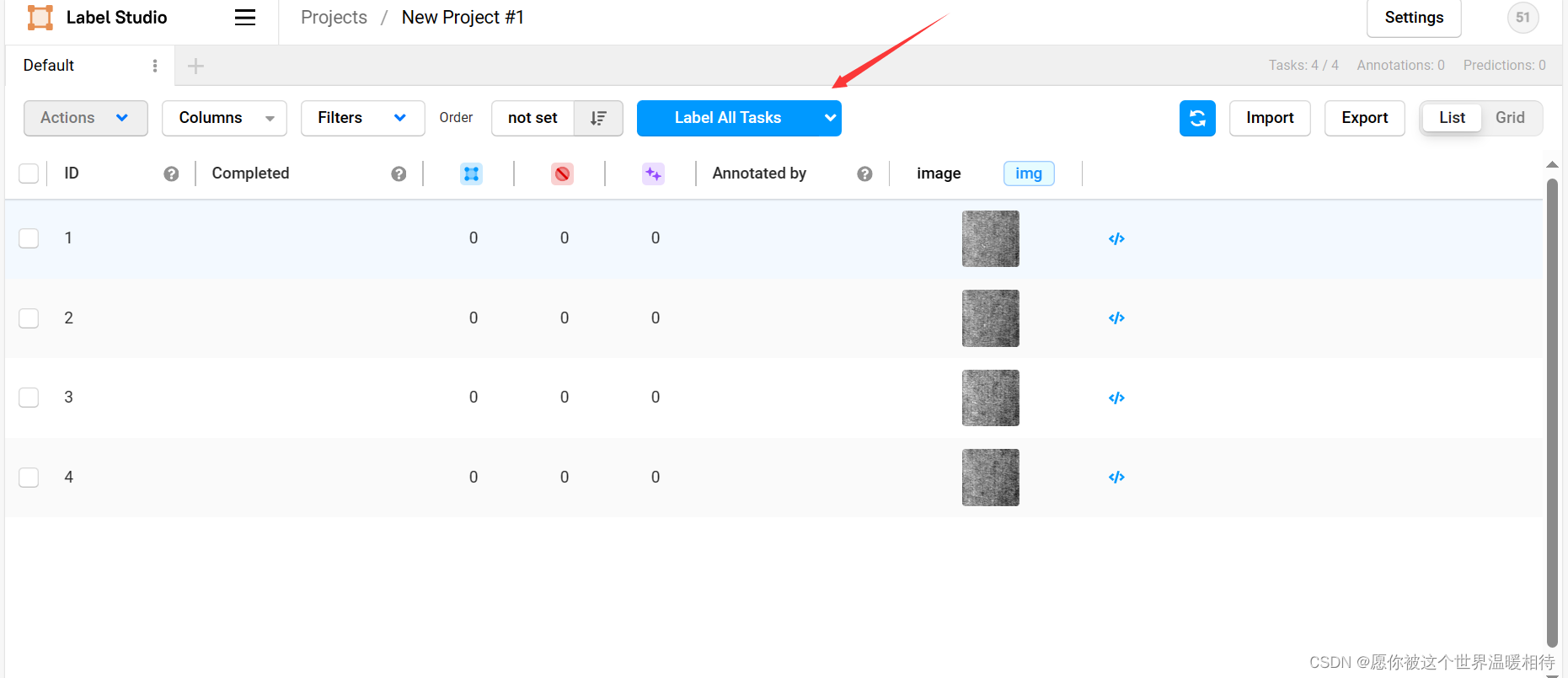
可以看到加载的图像以及右边的工具栏,工具栏中把鼠标放过去就可以看到是什么类型的标注了,事实上就是上边的4种
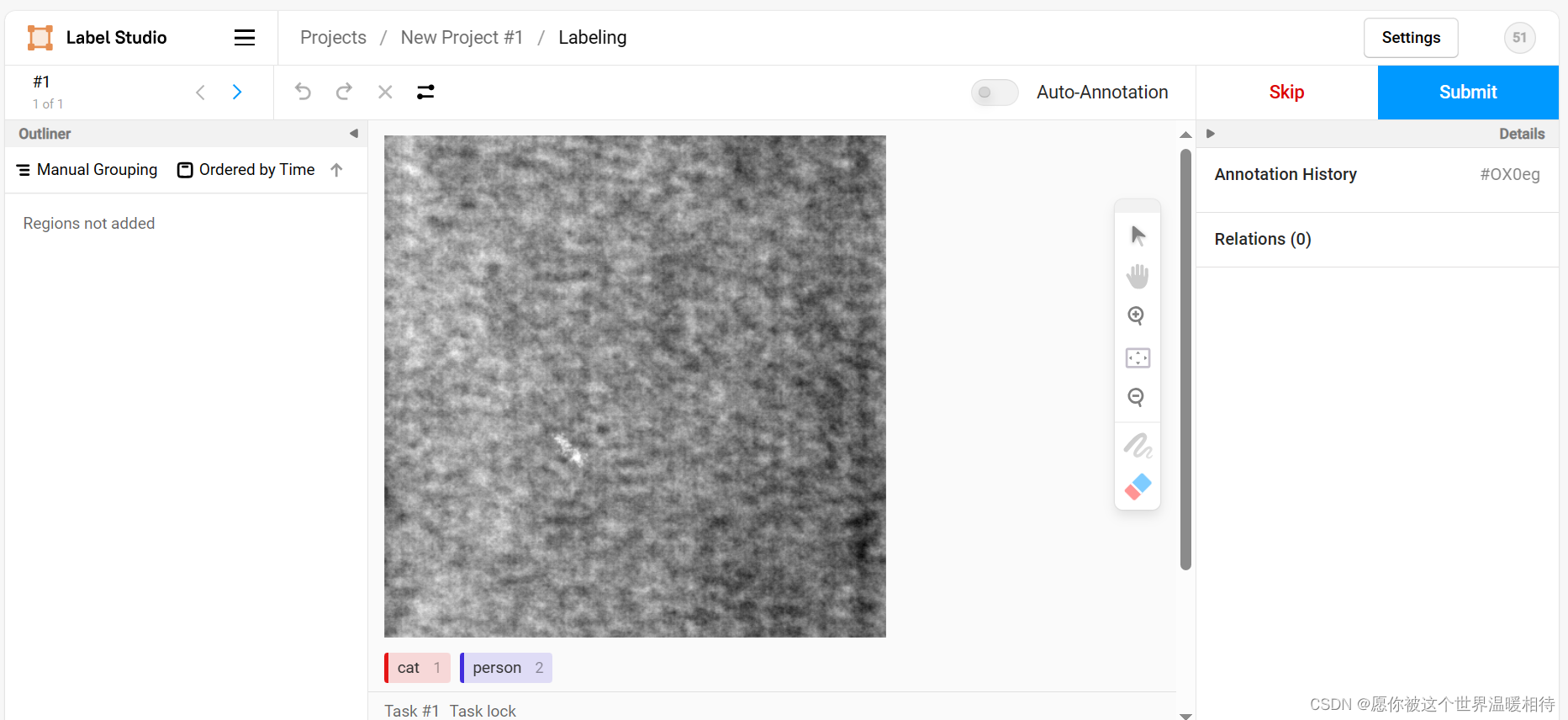
底部是4种标签,每一行表示不同的标注方式,他们排序方式就是上边通过xml的方式

点击不同行的标签就可以直接选择对应的标注方式,比如刚才第一个是关键点的标注方式,并且我想要cat这个标签,那就可以点击第一行的cat
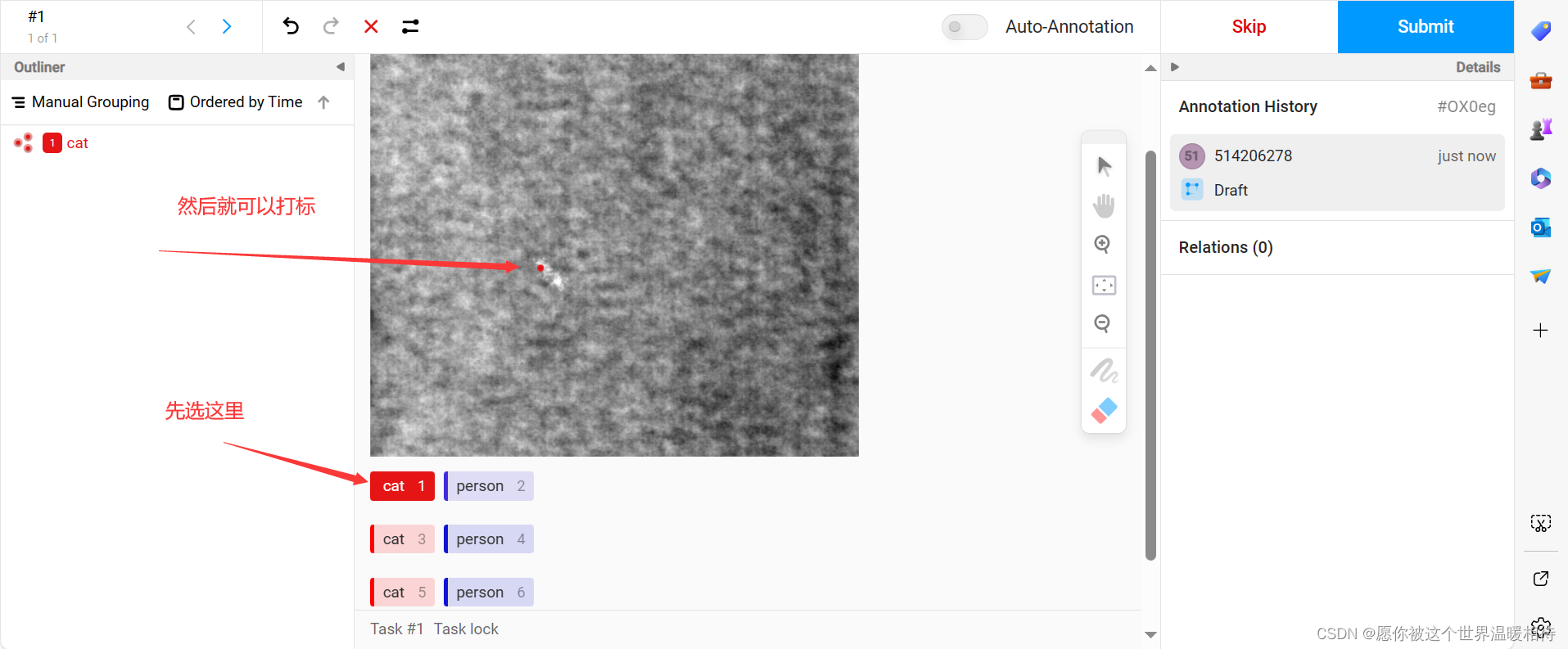
左侧就显示我们打的标签,然后右侧栏可以对标签进行一些简单控制,如下图描述的
半自动标注
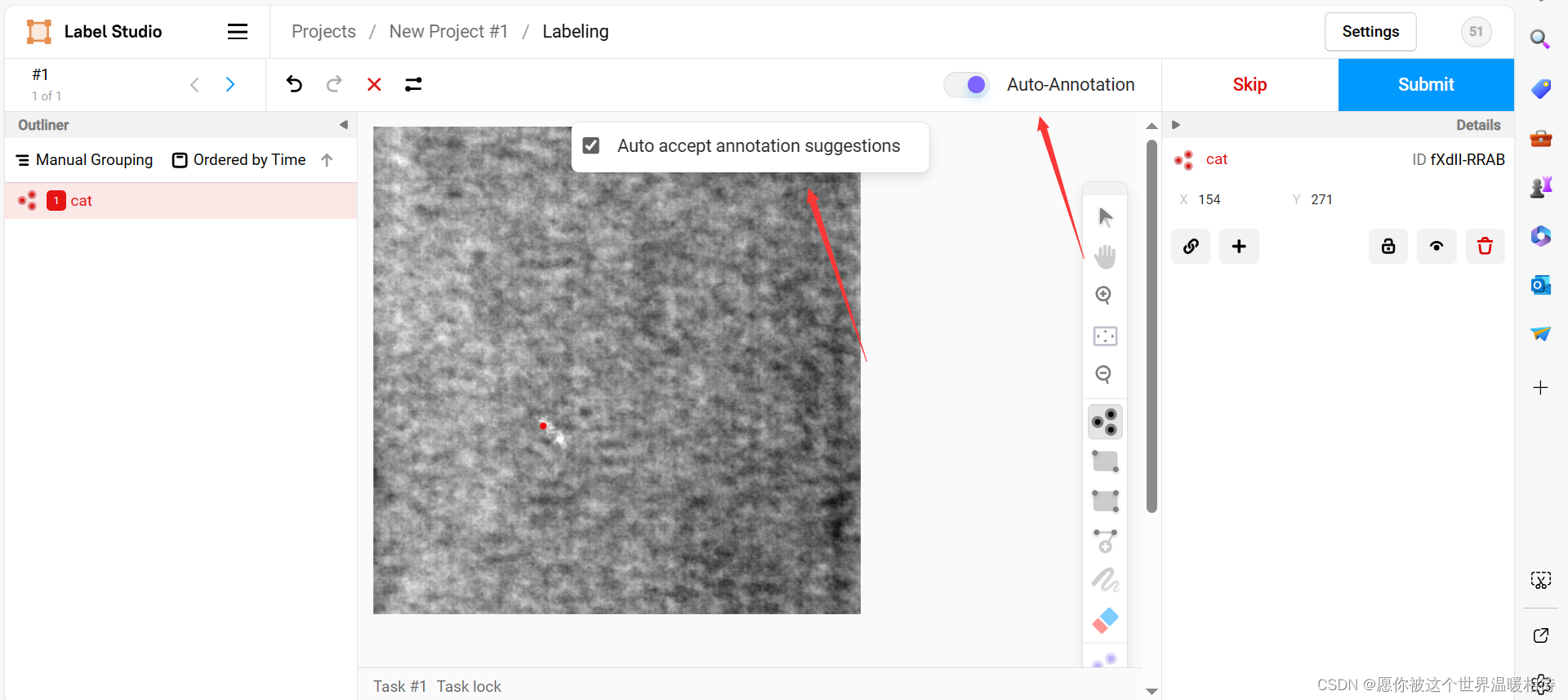
上述是简单的使用案例,但是我们需要时自动标注的,首先打开Auyo-Annotation,同时勾选Auto accept annotation suggestion
9a36791dc0787f151.png)
问题:self.value报错
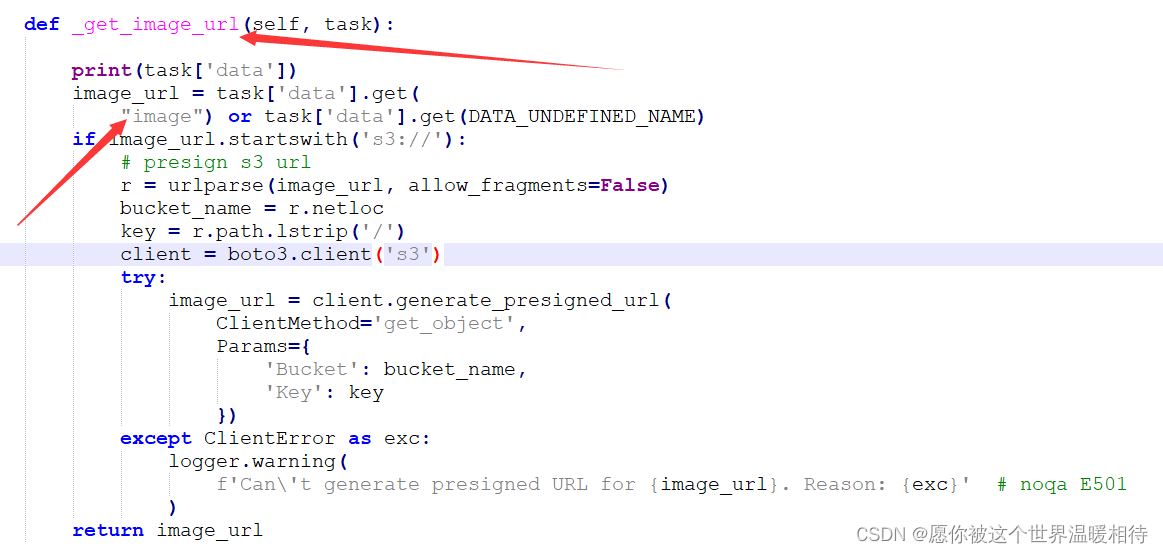
可能会遇到该问题,这里忘记具体问题了,即SAM在预测图像的时候,后端报错self.value不合法,这是源代码中mmdetection.py存在的问题,该文件路径是playground-main\label_anything\sam,具体路径取决于你的playground。这是在SAM在获取图像的时候的错,打开mmdetection.py,如下
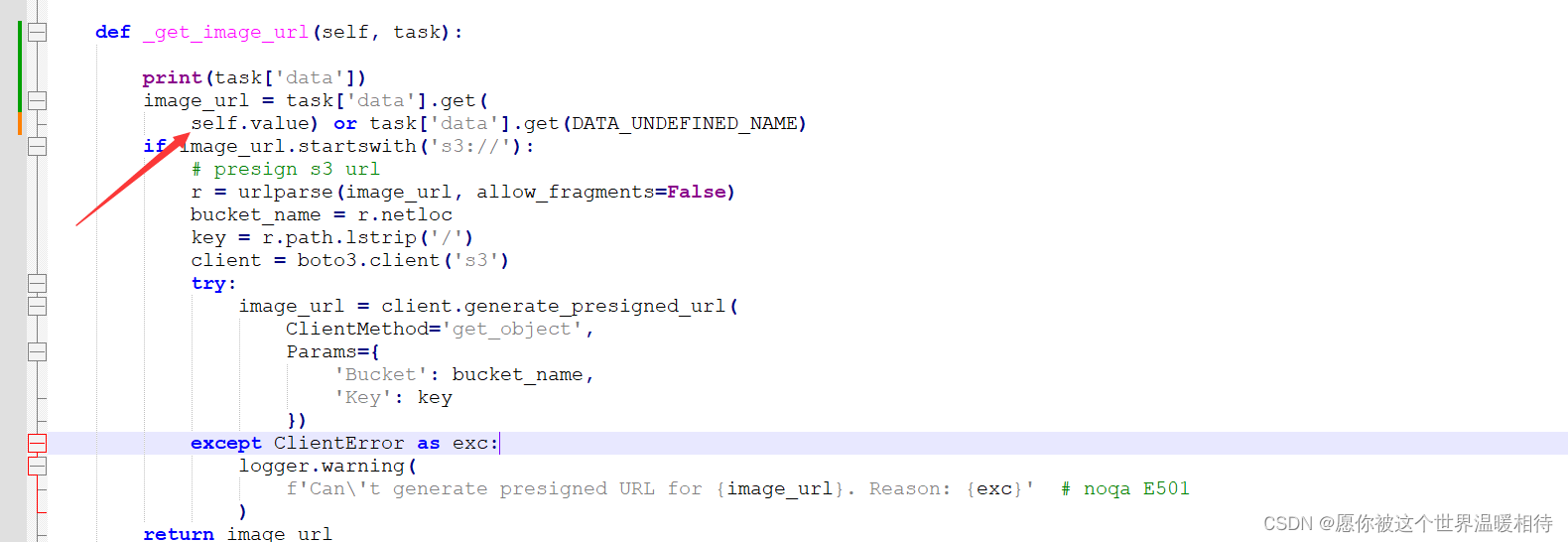
里边的键值改成"image"就行了,这可以通过打印task['data']看到,其实task['data']是一个键值对,其中键值"image"存储图像的地址
注意事项1
右边紫色的是smart工具,必须开启,也就是亮起来,并且必须跟你标签选的是一样,比如我现在是选的第一行的关键点相关的标签,右边的smart工具就必须是关键点的,如下边亮起来的三个点就是关键点配置的,
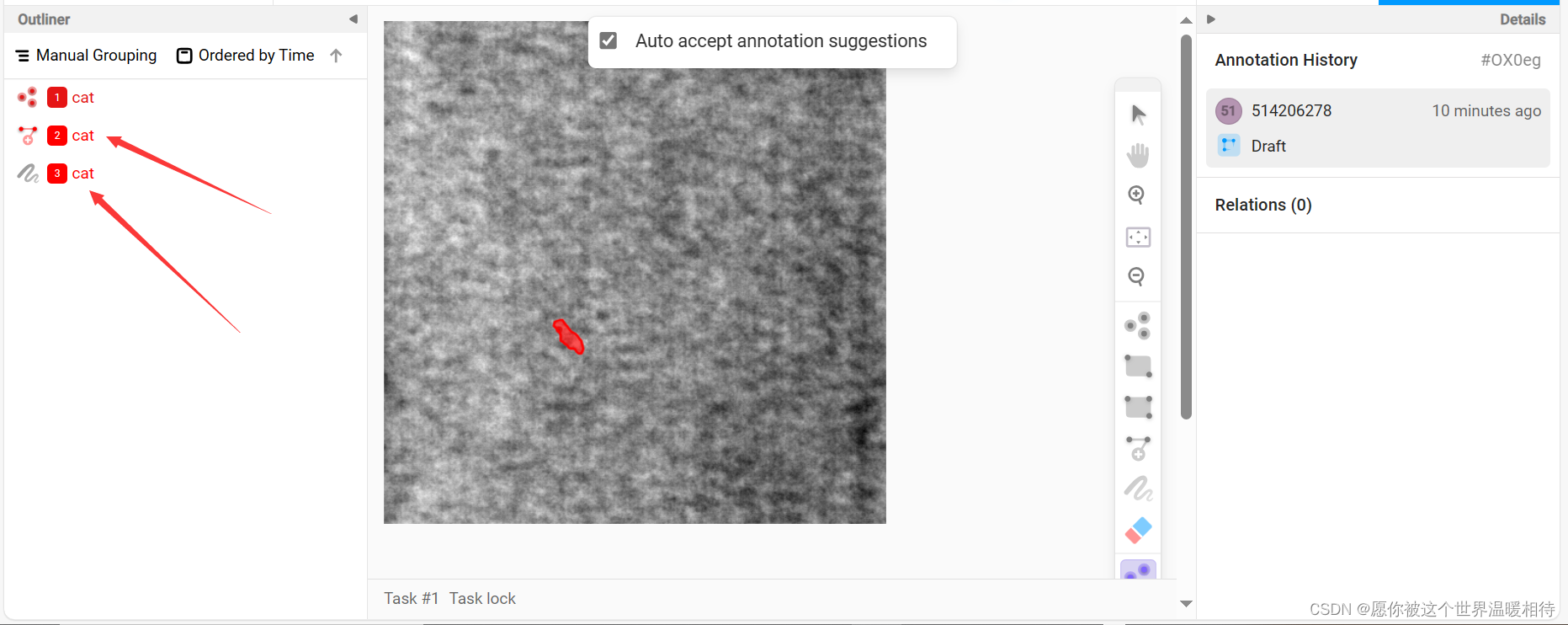
这个时候,只需要在目标区域点一下然后稍等一下就可以了,等多久就看你服务器的推理速度了,还有传输的速度了,如下图,可以看到,他自动就给我标了,并且多了两个标签,为啥是两个呢,因为我只配置了out_mask=true和out_poly=true,所以它就会得到两个
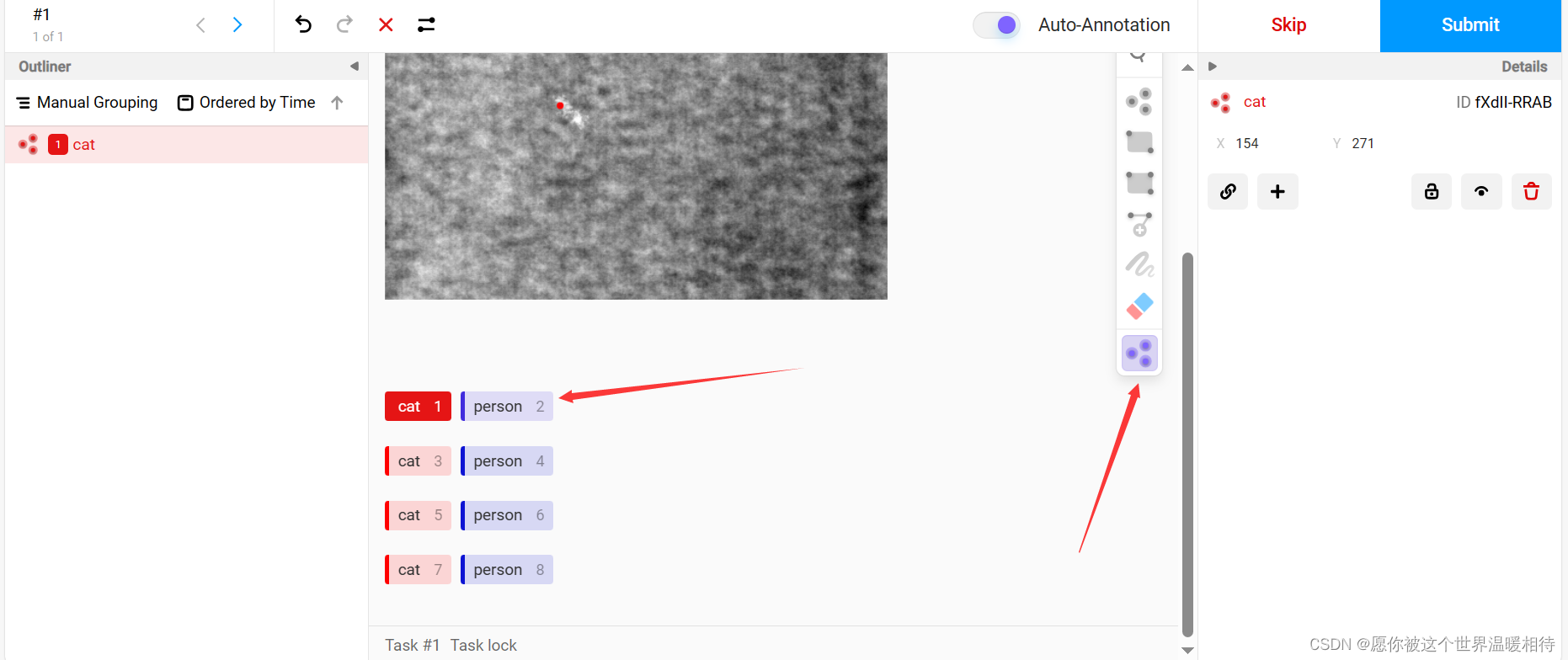
这是直接通过关键点进行标注的,smart工具还有其他的,如矩形检测,同理矩形检测必须是矩形标注的,只能选择矩形标注标签
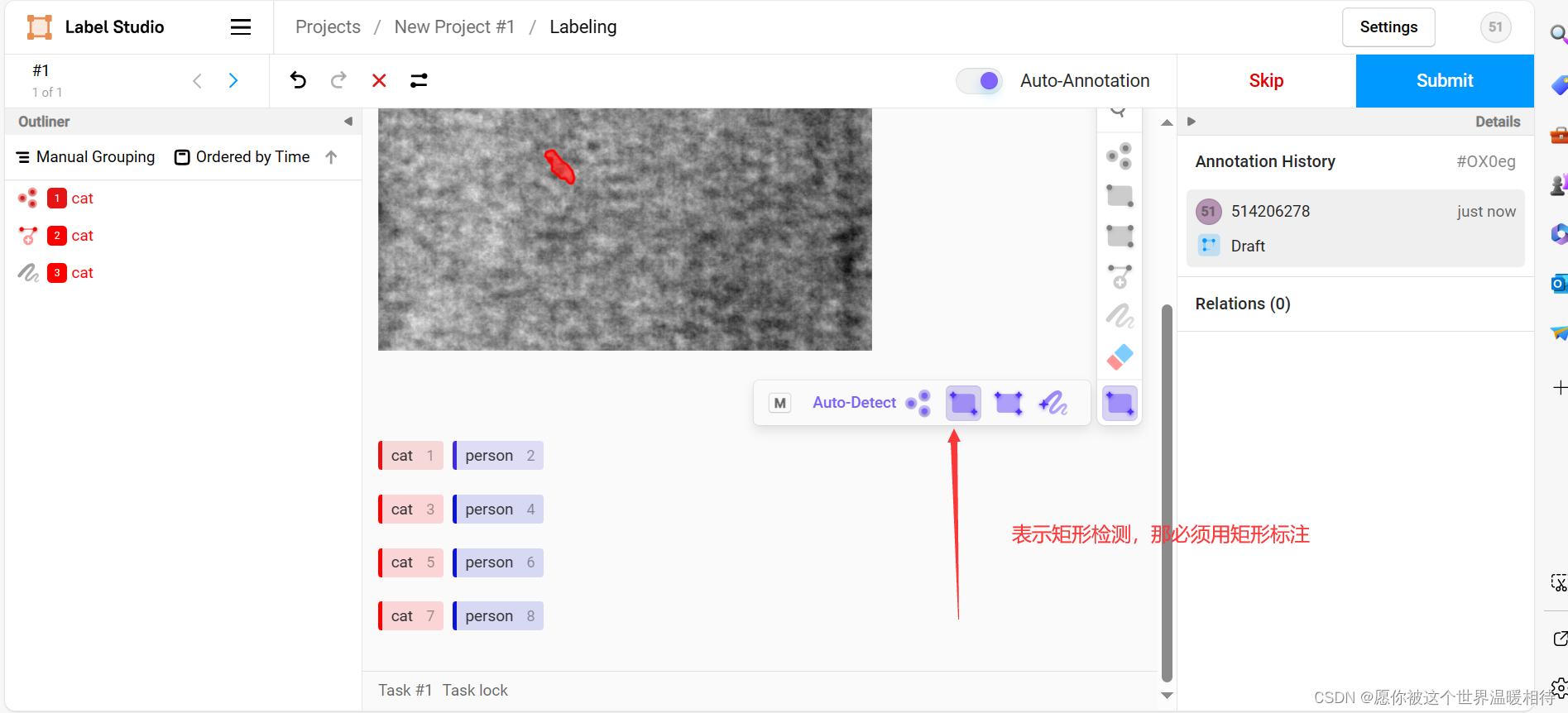
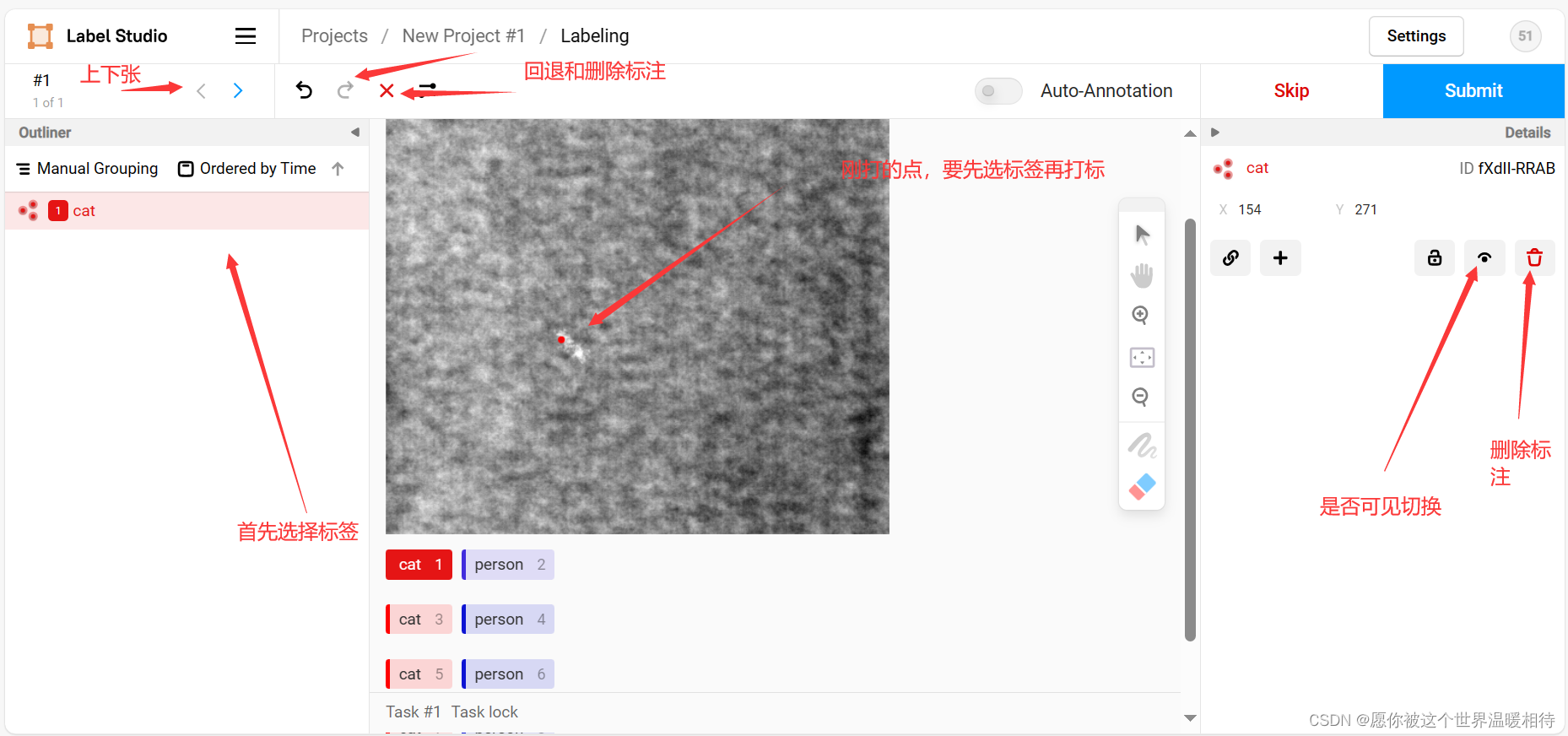
打出来的标没问题就可以点右上角的Sbumit进行提交,有问题就可以用点击左边那些标注,这里就是左栏里边那些标注去更改一下
注意事项2
记得点击右上角的Sbumit进行提交,不然等下导出就没有你现在标的标注了
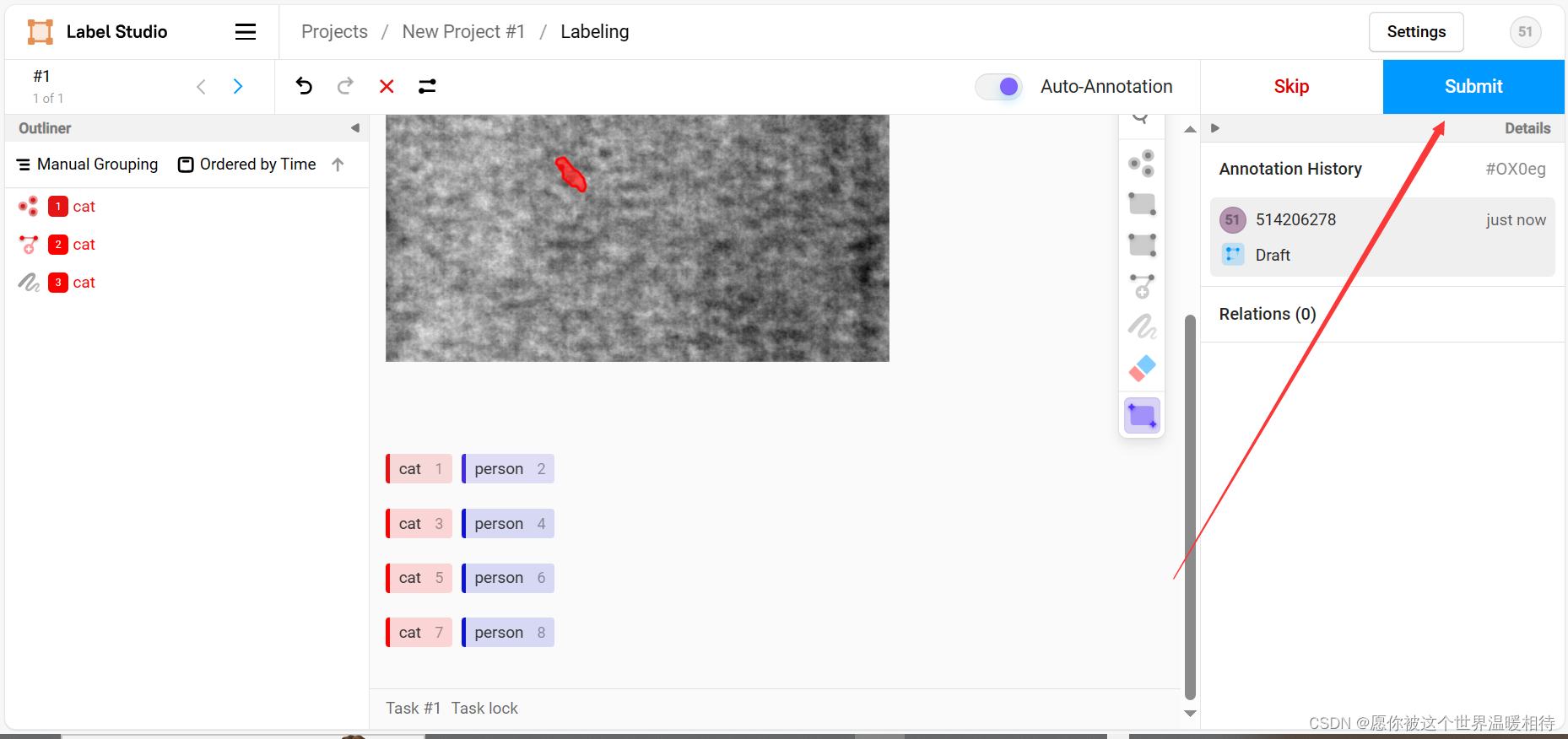
全部标注完是这样的
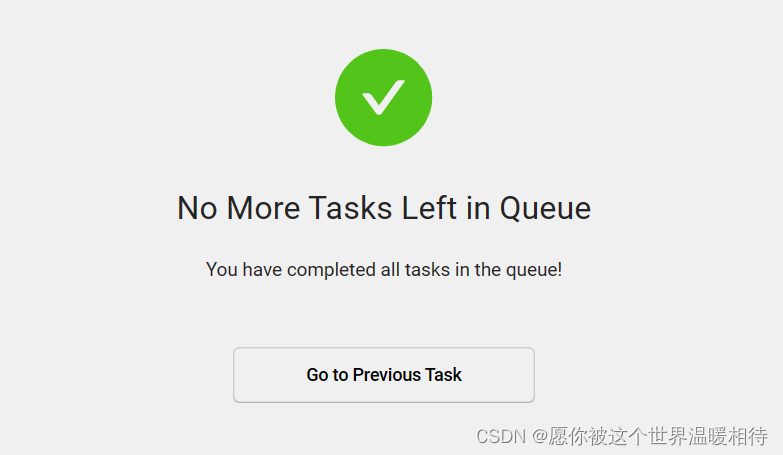
导出结果
回到项目,然后点击Export就可以导出来
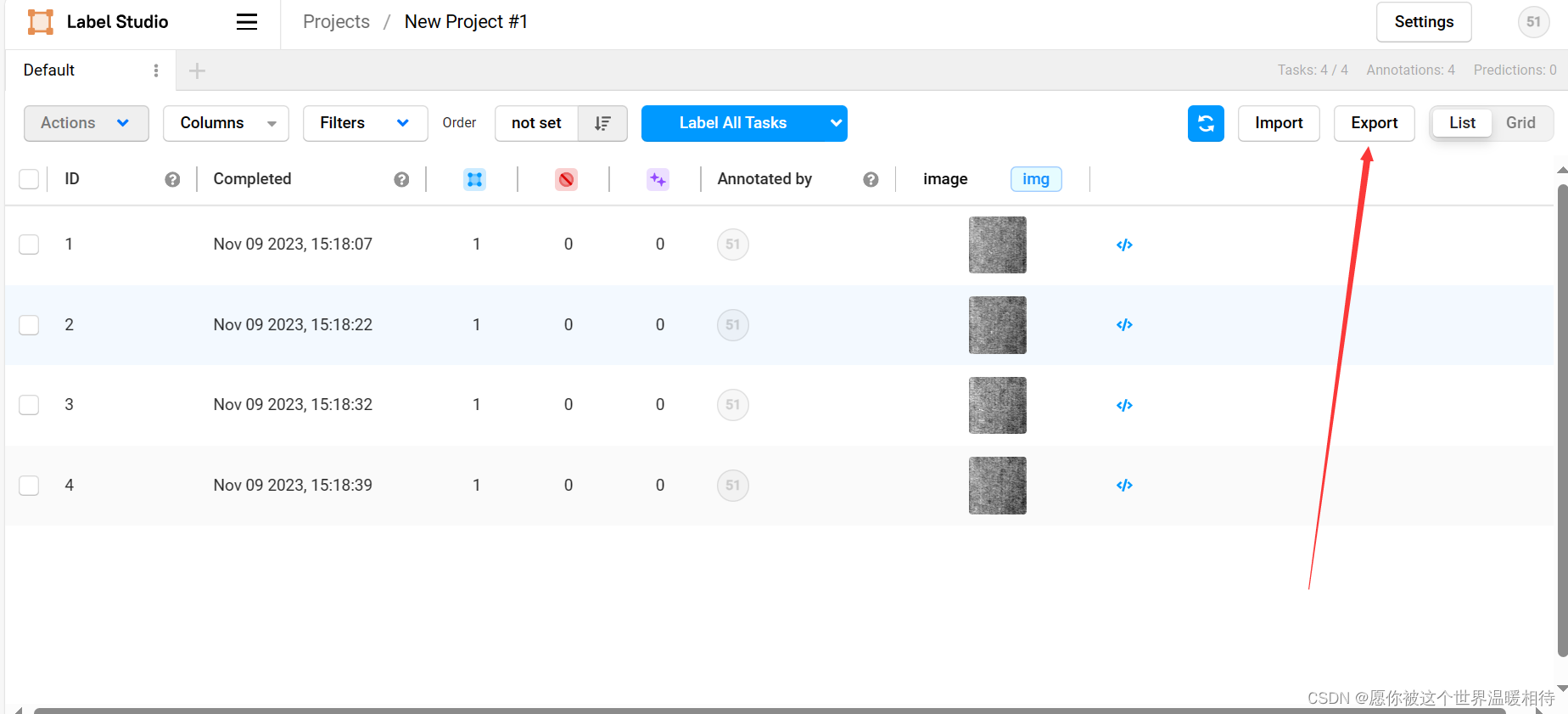
如下是导出二值掩码
下载压缩包

然后就是长这样,具体导出什么就看个人需求了


















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









