







6. 神经网络
6.1 人工神经网络的实现
人工神经网络的构成
- 人工神经元和连接:神经网络由人工神经元组成,这些神经元之间通过连接相互传递信息。人工神经元是对人脑神经元的简化模拟,它们可以处理和传递信息。
信息传递机制
-
权重和影响强度:每个连接都有一个权重,这个权重代表了相应神经元对输出结果影响的强度。权重的大小决定了信号在网络中的传递强度。
-
前馈过程(Feed Forward):信息在网络中从输入层通过隐藏层(如果有)最后传递到输出层的过程称为前馈。在这个阶段,输入数据通过加权求和(加上偏置项)后,通过一个非线性激活函数来产生输出。
权重优化过程
-
反向传播(Backpropagation):这是一种权重优化过程,用于训练神经网络。在每次训练迭代中,反向传播会通过网络的各层反向传递,根据权重对网络误差的贡献来调整权重。
- 计算误差:首先,计算网络预测输出和实际目标值之间的误差。
- 误差反向传播:然后,这个误差会反向传播到网络中,根据误差对每个权重的影响程度来调整权重。
- 权重更新:权重根据预定的学习率和误差梯度来更新,目的是减少网络的总体误差。
使用训练好的网络进行预测
- 新输入和预测:一旦神经网络通过训练数据学习到了相应的模式,我们就可以将新的输入数据(测试集)放入网络中,网络会根据训练过程中创建的函数来预测输出。
训练过程的总结
- 初始化:随机初始化网络权重。
- 前馈传播:将输入数据传递到网络中,计算输出。
- 计算误差:使用损失函数计算预测输出和真实值之间的误差。
- 反向传播:利用误差对权重进行更新,以减少预测误差。
- 迭代优化:重复上述步骤,直到网络在训练数据上达到满意的性能。
通过这种方式,神经网络能够学习到数据之间的关系,并能够对新的、未见过的数据做出准确的预测。这种能力使得神经网络在各种领域,如图像识别、自然语言处理、游戏玩法等领域得到广泛应用。
6.2 模拟布尔函数
这段内容讨论了数学中的布尔函数(Boolean Function),以及它们在计算机科学和逻辑学中的应用。以下是对这段内容的详细解释:
布尔函数的定义
- 布尔函数:在数学中,布尔函数是一种特殊类型的函数,其输入(参数)和输出(结果)仅来自一个包含两个元素的集合。这个集合通常表示为 {true, false}、{0, 1} 或 {-1, 1},分别对应逻辑真、逻辑假以及二进制值。
布尔函数的其他名称
- 开关函数(Switching Function):在计算机科学文献中,布尔函数有时被称为开关函数,特别是在讨论逻辑电路和数字电路时。
- 真值函数(Truth Function)或逻辑函数(Logical Function):在逻辑学中,布尔函数也被称为真值函数或逻辑函数,因为它们与逻辑表达式的真值表有关。
常见的布尔函数
- AND:逻辑与,当所有输入都为真时,输出为真。
- OR:逻辑或,当至少有一个输入为真时,输出为真。
- XOR:逻辑异或,当输入中恰好有一个为真时,输出为真(偶数个假输入和奇数个真输入时输出不同)。
- NAND:逻辑与非,与AND门相反,只有当所有输入都为假时,输出为真。
- NOR:逻辑或非,与OR门相反,只有当所有输入都为假时,输出为真。
- XNOR:逻辑同或,与XOR门相反,当输入中所有位都相同时,输出为真(即两个输入都为假或都为真时输出为真)。
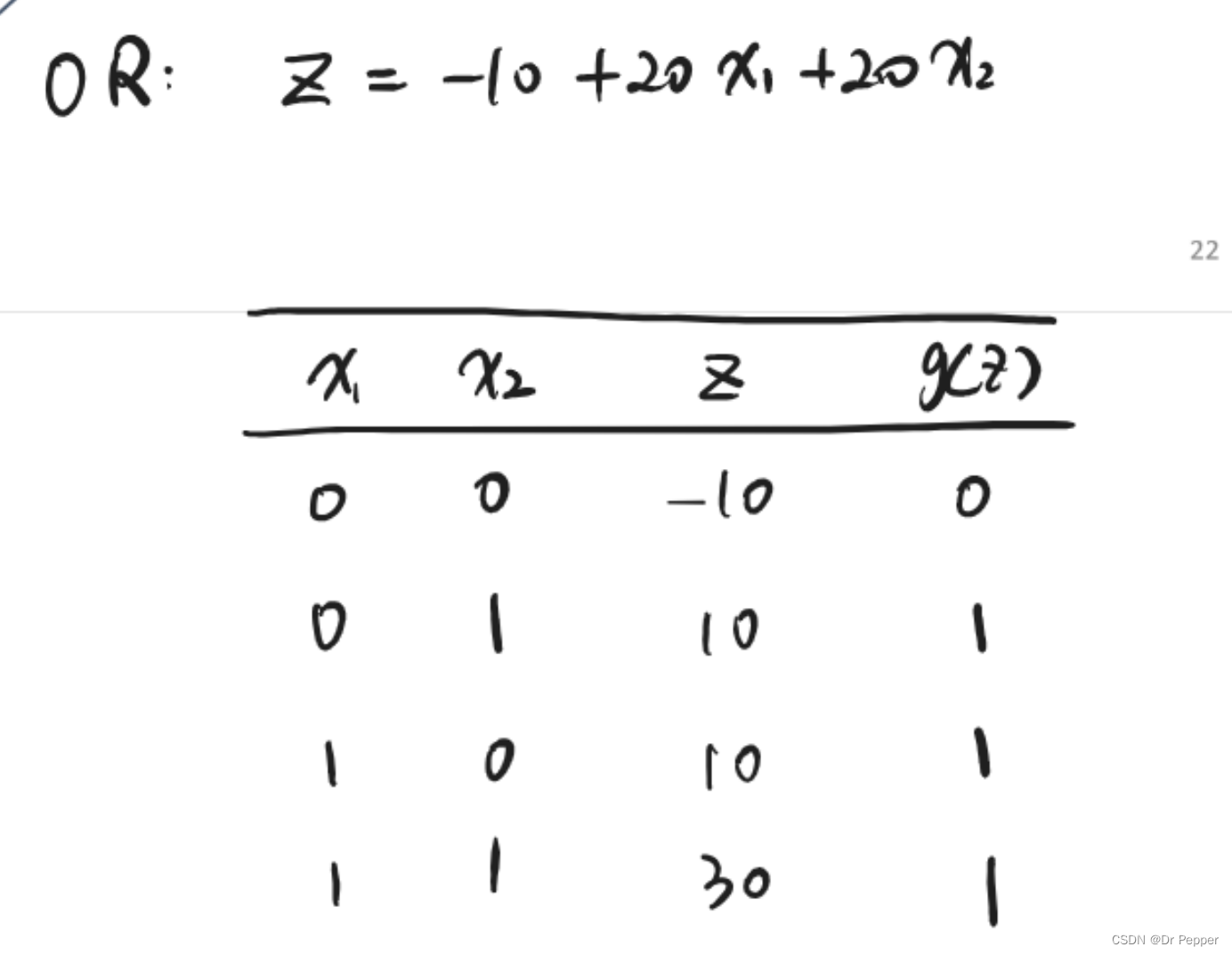
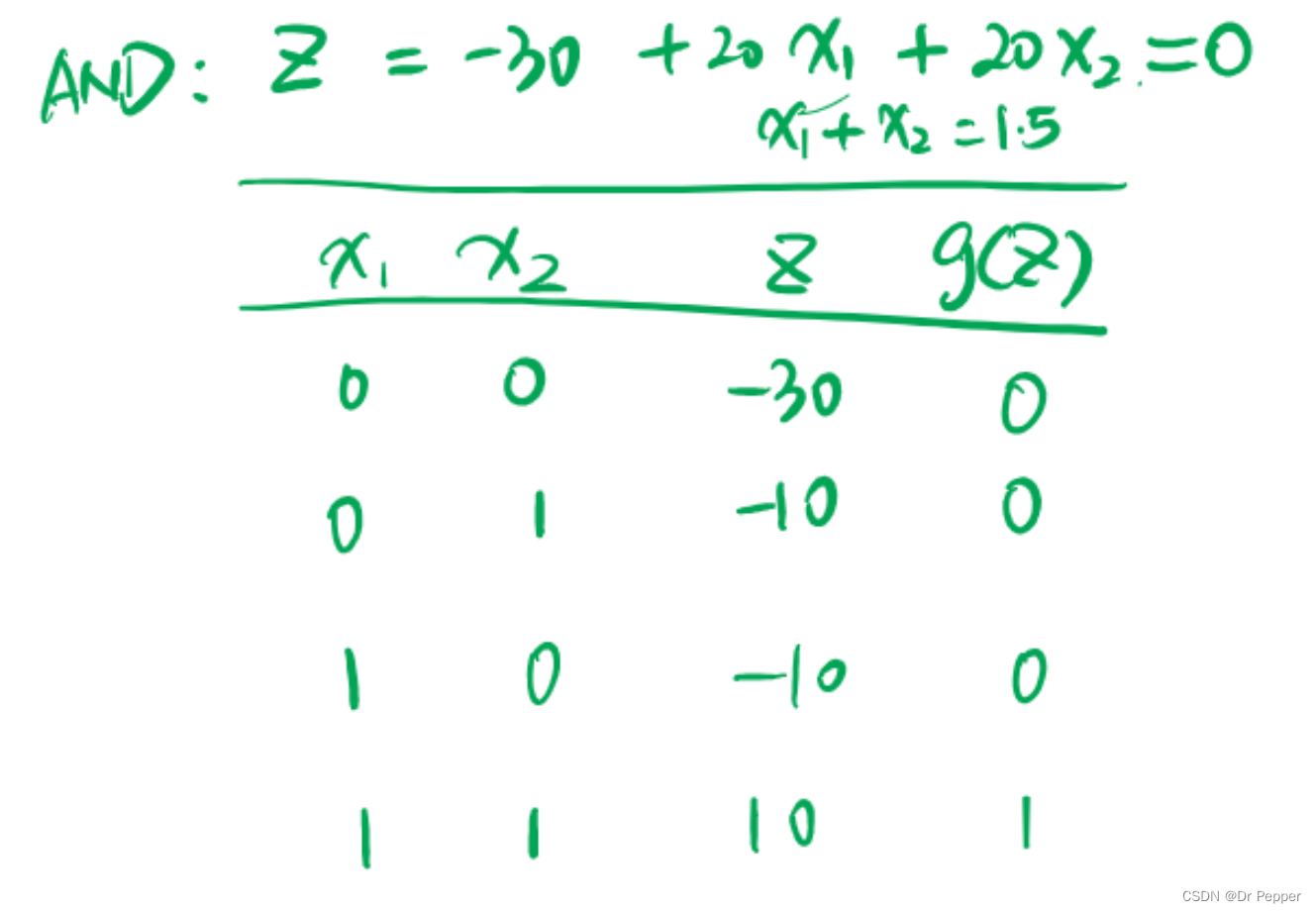
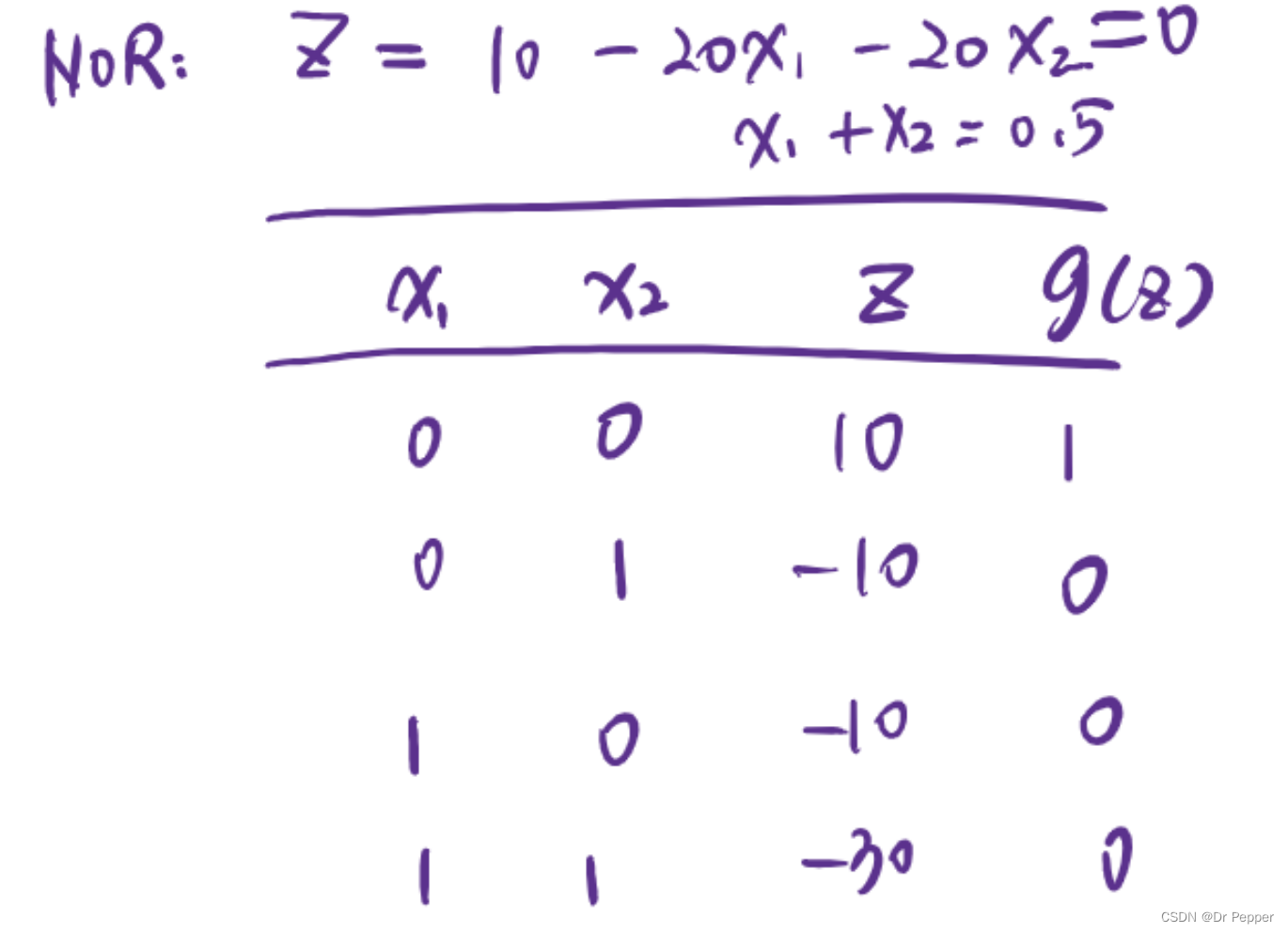
N输入的AND和OR门
- N输入AND门:一个有N个输入的AND门在所有N个输入都为真(TRUE)时,输出为真(TRUE)。如果任何一个输入为假(FALSE),输出即为假(FALSE)。
- N输入OR门:一个有N个输入的OR门在至少有一个输入为真(TRUE)时,输出为真(TRUE)。只有当所有N个输入都为假(FALSE)时,输出才为假(FALSE)。
布尔函数在设计逻辑电路、评估逻辑表达式、构建计算机算法以及处理数据和信息的许多其他领域中都非常重要。它们是数字逻辑和计算理论的基础。
7.建立神经网络
7.1 sequential模型
Sequential模型的特点:
-
层的线性堆叠:Sequential模型适用于一个简单的层的堆叠,每一层都恰好有一个输入张量和一个输出张量。
-
tf.keras.model的封装:
keras.Sequential将线性堆叠的层组合成一个tf.keras.Model对象,这是一个更高级别的抽象,代表整个模型。 -
网络架构的构建:通过
keras.Sequential定义网络的架构,用户可以一层接一层地添加神经网络层。 -
训练和推理功能:
keras.Sequential不仅提供了模型的构建方式,还提供了模型的训练(training)和推理(inference)功能。
Sequential模型的构建步骤:
-
初始化Sequential模型:
from tensorflow.keras.models import Sequential model = Sequential() -
添加层:使用
.add()方法向模型添加神经网络层。每一层都建立在前一层之上。model.add(Dense(12, input_shape=(8,), activation='relu')) # 第一层,包含8个输入特征和12个神经元 model.add(Dense(8, activation='relu')) # 第二层,之前的层输出将成为这一层的输入 model.add(Dense(1, activation='sigmoid')) # 输出层 -
编译模型:在训练模型之前,需要编译模型并指定损失函数、优化器和评估指标。
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) -
训练模型:使用
.fit()方法训练模型,传入训练数据和标签。model.fit(x_train, y_train, epochs=150, batch_size=10) -
评估模型:使用
.evaluate()方法在测试集上评估模型性能。loss, accuracy = model.evaluate(x_test, y_test) -
使用模型进行预测:使用
.predict()方法进行推理和预测。predictions = model.predict(x_new)
Sequential模型的适用场景:
- 当模型的架构是简单的层叠结构时,Sequential模型非常方便。
- 对于初学者来说,Sequential模型提供了一种简单直观的方式来构建和理解神经网络。
Sequential模型的局限性:
- 如果模型需要更复杂的结构,如多输入、多输出或共享层(同一输入连接到多个层),Sequential模型可能不够灵活。
- 对于更复杂的模型架构,可能需要使用
tf.keras.Model或函数式API(Functional API)来构建模型。
Sequential模型是Keras中快速构建和原型设计深度学习模型的强大工具,特别适合初学者和简单的神经网络结构。随着对深度学习理解的深入,用户可能会探索更高级的模型构建方法。
8. clustering
| 特性 | K-Means聚类 | DBSCAN聚类 |
|---|---|---|
| 聚类方法 | 分区聚类(Partition-based Clustering) | 密度聚类(Density-based Clustering) |
| 聚类形状 | 球形或类球形(Creates sphere-like shaped groups) | 任意形状(Creates arbitrary shaped groups) |
| 聚类算法示例 | K-Means聚类、K-Median聚类等 | DBSCAN聚类 |
| 核心样本识别 | 不直接识别核心样本 | 有助于识别核心样本和离群点(Helpful to identify core samples and outliers) |
| 应用场景 | 高效且广泛使用,适用于球形或类球形数据集 | 适用于任意形状的数据集,包括噪声和离群点 |
| 对噪声的敏感度 | 对噪声敏感 | 对噪声不敏感,能够识别离群点 |
| 聚类数量 | 预先指定聚类数量 | 聚类数量不固定,由数据密度决定 |
| 聚类中心 | 有明确的聚类中心 | 没有明确的聚类中心,通过密度连接点来形成聚类 |
| 计算复杂度 | 相对较低,适合大规模数据集 | 相对较高,尤其是当数据集很大或密度不均匀时 |
| 聚类稳定性 | 较高 | 可能较低,取决于参数设置和数据的局部密度 |
| 参数选择 | 主要参数是聚类数量K | 主要参数是邻域半径ε和最小点数MinPts |
8.1 K-Means
K-Means聚类算法是一种流行的聚类方法,它通过迭代过程将数据点分配到K个聚类中,每个聚类由一个质心(Centroid)代表。以下是K-Means算法的步骤解释:
-
随机初始化K个聚类质心:算法开始时,随机选择K个数据点作为初始的聚类质心,这些质心在数学上表示为向量 ( \mu_1, \mu_2, …, \mu_K \in \mathbb{R}^m ),其中m是数据的维度。
-
迭代过程:K-Means算法的核心是一个重复的过程,直到收敛(即质心的位置不再有显著变化)。
-
为每个数据点分配到最近的质心:对于数据集中的每个点 ( x_i )(i从1到N,N是数据点的总数),算法计算它到每个质心 ( \mu_k ) 的距离,并将其分配给最近的质心。距离通常是通过计算点和质心之间的欧几里得距离(即平方距离)来计算的,公式为 ( \min_k (x_i - \mu_k)^2 )。
-
更新质心:一旦所有数据点都被分配到最近的质心,算法将进入下一步,更新每个聚类的质心。新的质心是分配给该聚类的所有数据点的均值,即 ( \mu_k ) 更新为该聚类中所有点 ( x_i ) 的均值。
-
重复迭代:步骤3和4重复进行,直到质心的位置不再有显著变化,或者达到预设的迭代次数,这时算法收敛。
K-Means算法的优点在于它简单、快速,适合处理大型数据集。然而,它也有一些局限性:
- 需要预先指定K值,即聚类的数量。
- 对初始质心敏感,不同的初始质心可能导致不同的聚类结果。
- 对噪声和离群点敏感。
- 可能只能找到局部最优解,而不是全局最优解。
K-Means算法适用于球形或类球形的数据聚类,但对于任意形状的聚类,可能需要使用其他算法,如DBSCAN。
8.2 DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,它能够识别任意形状的聚类,并且可以识别并处理噪声点和离群点。下面是对您提供的内容的解释:
-
DBSCAN:即密度基空间聚类,用于带噪声的应用程序。
-
基于密度的对象工作:DBSCAN算法的核心思想是,如果一个区域内的点的密度足够高,那么这个区域就可以被认为是一个聚类。
-
R (邻域半径):这是一个参数,定义了在数据空间中考虑的邻域的范围。如果一个点的R范围内包含了足够多的点,那么这个区域就可以被认为是一个“密集”的区域。
-
密集区域的定义:在DBSCAN中,如果一个点的R邻域内包含的点数达到了一定的阈值(即M),那么这个点就被认为是处于一个密集区域。
-
M (最小邻居数):这是另一个参数,定义了在R邻域内需要有多少个点才能认为该邻域是密集的。换句话说,M是定义一个聚类所需的最小数据点数。
A cluster is formed by grouping the connected corepoints and all their borders together通过将连接的核心点及其所有边界组合在一起形成集群.
DBSCAN算法通过这两个参数来识别核心点(如果在R范围内有至少M个点,则该点是核心点),边界点(在核心点的R邻域内,但是自己的R邻域内没有M个点),以及噪声点(不在任何核心点的R邻域内,且数量少于M的点)。核心点和边界点共同组成聚类,而噪声点则被认为是离群点或不属于任何聚类。

DBSCAN的优点在于它不需要预先指定聚类的数量,并且可以有效地识别并处理噪声。然而,选择合适的R和M参数对于算法的性能至关重要。如果R过大或M过小,可能会导致过多的噪声点被错误地识别为聚类的一部分;如果R过小或M过大,可能会导致数据集中的许多小聚类被忽略。















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









