







很久没有接触MySQL,最近在力扣上刷刷题目,整理整理知识点。
MySQL表的连接知识点回顾
为什么要使用连接?因为想要获取多个表中的数据。
在MySQL中,表连接(JOIN)是一种将两个或多个表中的行组合起来,基于这些表之间的某些相关列之间的关系的方法。这允许你从多个表中检索数据,而无需使用多个查询。
以下是MySQL中几种常见的表连接类型:
笛卡尔积连接
在MySQL中,当两个表进行连接但没有指定连接条件时,会发生笛卡尔积连接(JOIN)。这意味着第一个表中的每一行都会与第二个表中的每一行组合,生成一个结果集,其行数等于两个表行数的乘积。
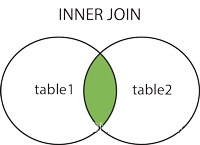
内连接
INNER JOIN(内连接)
只返回两个表中满足连接条件的行。
SELECT A.*, B.*
FROM table1 A
INNER JOIN table2 B ON A.key = B.key;
左连接
LEFT JOIN(左连接)或 LEFT OUTER JOIN
**从左表返回所有的行,即使右表中没有匹配的行。**如果右表中没有匹配的行,则结果集中右表的部分将包含NULL。
SELECT A.*, B.*
FROM table1 A
LEFT JOIN table2 B ON A.key = B.key;
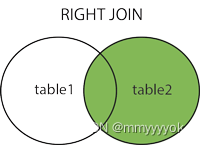
右连接
RIGHT JOIN(右连接)或 RIGHT OUTER JOIN
与LEFT JOIN相反,从右表返回所有的行,即使左表中没有匹配的行。
SELECT A.*, B.*
FROM table1 A
RIGHT JOIN table2 B ON A.key = B.key;
注意:在实际应用中,RIGHT JOIN不如LEFT JOIN常用,因为可以通过交换表的位置和使用LEFT JOIN来达到相同的效果。
有时使用类别名,如:
SELECT o.order_id, c.customer_name
FROM orders AS o
INNER JOIN customers AS c ON o.customer_id = c.customer_id;
以上 SQL 语句使用表别名 o 和 c 作为 orders 和 customers 表的别名。
自连接
针对相同的表进行连接,可以理解为同一张表复制成两份甚至多份。
尤其适合:
(1)在同一张表内进行比较
(2)找出列的组合(查找共用同一车站的所有公交路线)
(3)查找部分内容重复的记录
https://www.cnblogs.com/HuZihu/p/12244796.html
Leetcode中MySQL练习题
上升的温度

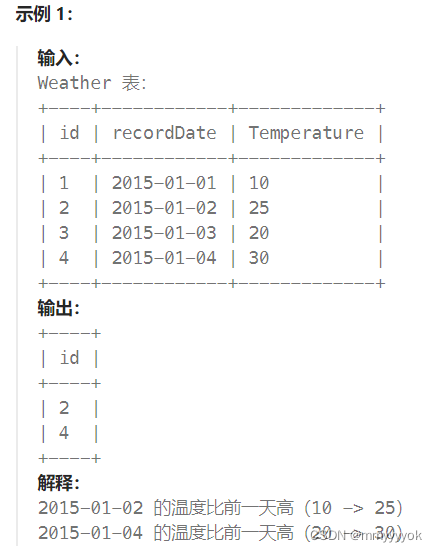
解题思路:看似题中只给出了一张表格,但是涉及到了比较(昨天和今天的温度),可以将这份表再copy一份,然后利用日期函数找到了昨天的日期:
select a.id from Weather as a,Weather as b
where datediff(a.recordDate,b.recordDate) = 1 and a.Temperature >b.Temperature; #
-- DATEDIFF(a.RecordDate, b.RecordDate)=1,表示a是今天b是昨天
知识点:内连接,日期函数datediff计算两个日期间的差值
通常datediff这样使用:
DATEDIFF(interval, start_date, end_date)
每台机器的运行时间平均
表: Activity

该表展示了一家工厂网站的用户活动。
(machine_id, process_id, activity_type) 是当前表的主键(具有唯一值的列的组合)。
machine_id 是一台机器的ID号。
process_id 是运行在各机器上的进程ID号。
activity_type 是枚举类型 (‘start’, ‘end’)。
timestamp 是浮点类型,代表当前时间(以秒为单位)。
‘start’ 代表该进程在这台机器上的开始运行时间戳 , ‘end’ 代表该进程在这台机器上的终止运行时间戳。
同一台机器,同一个进程都有一对开始时间戳和结束时间戳,而且开始时间戳永远在结束时间戳前面。
现在有一个工厂网站由几台机器运行,每台机器上运行着相同数量的进程 。编写解决方案,计算每台机器各自完成一个进程任务的平均耗时。
完成一个进程任务的时间指进程的’end’ 时间戳减去 ‘start’ 时间戳。平均耗时通过计算每台机器上所有进程任务的总耗费时间除以机器上的总进程数量获得。
结果表必须包含machine_id(机器ID) 和对应的 average time(平均耗时) 别名 processing_time,且四舍五入保留3位小数。
以 任意顺序 返回表。
具体参考例子如下。
示例 1:
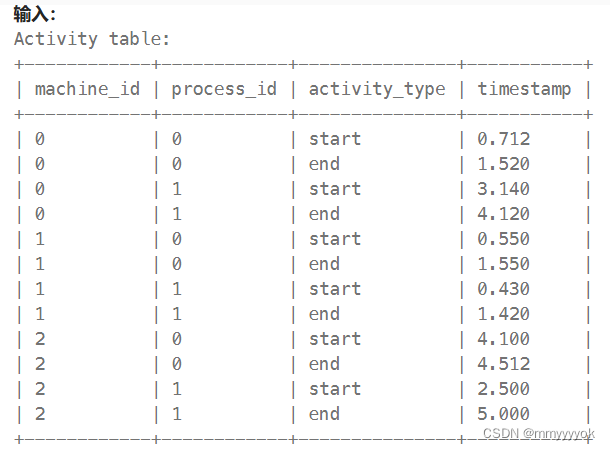

解释:
一共有3台机器,每台机器运行着两个进程.
机器 0 的平均耗时: ((1.520 - 0.712) + (4.120 - 3.140)) / 2 = 0.894
机器 1 的平均耗时: ((1.550 - 0.550) + (1.420 - 0.430)) / 2 = 0.995
机器 2 的平均耗时: ((4.512 - 4.100) + (5.000 - 2.500)) / 2 = 1.456
解题思路:同一张表上既要用结束时间又要用开始时间,还要对这些时间分别进行计算。不妨将这张表进行自连接,定义a1和a2。提取a2里是所有activity_type是end的部分以及a1里是所有activity_type是start的部分。只要用a2表中的时间减去a1表中的时间(也就是完成一个进程任务的时间),再将这个结果直接取平均,就是平均耗时。
select a1.machine_id,
round(avg(a2.timestamp -a1.timestamp ),3) as processing_time
from Activity as a1 join Activity as a2 on
a1.machine_id=a2.machine_id and
a1.process_id=a2.process_id and
a1.activity_type ='start' and
a2.activity_type ='end'
group by machine_id;
注意点:
(1)这里avg(a2.timestamp -a1.timestamp)是比较巧妙的,并不需要将每个机器的每个进程耗时一一算出再加起来除以进程数。
(2)round()保留小数点位数
(3)and a2.activity_type =‘end’ 也可以改成 where…但是耗时更多
学生们参加各科成绩的次数(多表连接查询)
学生表: Students

在 SQL 中,主键为 student_id(学生ID)。
该表内的每一行都记录有学校一名学生的信息。
科目表: Subjects

在 SQL 中,主键为 subject_name(科目名称)。
每一行记录学校的一门科目名称。
考试表: Examinations

这个表可能包含重复数据(换句话说,在 SQL 中,这个表没有主键)。
学生表里的一个学生修读科目表里的每一门科目。
这张考试表的每一行记录就表示学生表里的某个学生参加了一次科目表里某门科目的测试。
查询出每个学生参加每一门科目测试的次数,结果按 student_id 和 subject_name 排序。
查询结构格式如下所示。
示例 1:
输入:
Students table:
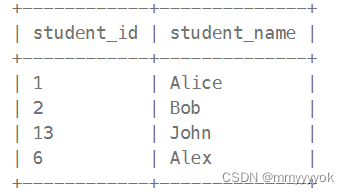
Subjects table:

Examinations table:
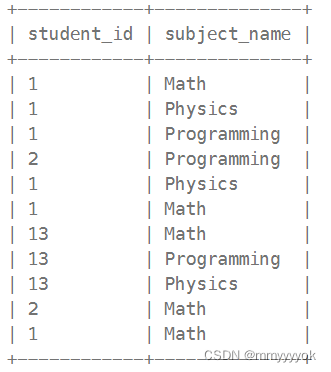
输出:
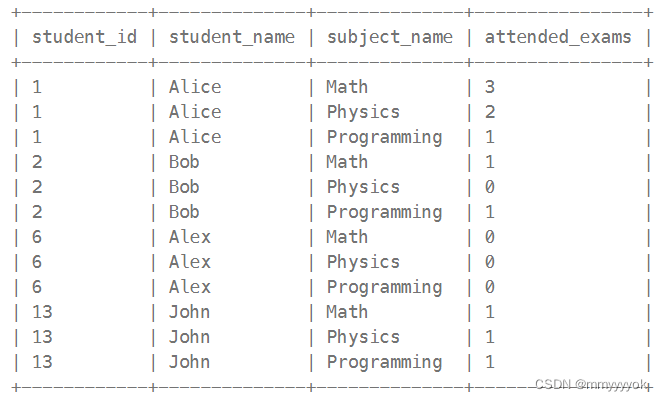
解释:
结果表需包含所有学生和所有科目(即便测试次数为0):
Alice 参加了 3 次数学测试, 2 次物理测试,以及 1 次编程测试;
Bob 参加了 1 次数学测试, 1 次编程测试,没有参加物理测试;
Alex 啥测试都没参加;
John 参加了数学、物理、编程测试各 1 次。
解题思路:
(1)Student表和Subjects表进行笛卡尔积连接(Student JOIN Subjects)
(2)在第一点的基础上拼接Examinations中的每个学生参加每门科目的数量
(3)根据案例可以看出,学生名单必须完整,在Examinations表中不存在则为0。所以使用左连接LEFT JOIN进行连接(Student JOIN Subjects LEFT JOIN Examinations)
(4)注意排序不是按Examinations表进行排序的,因为存在NULL,下图就是第四个字段就是Examinations的student_id。
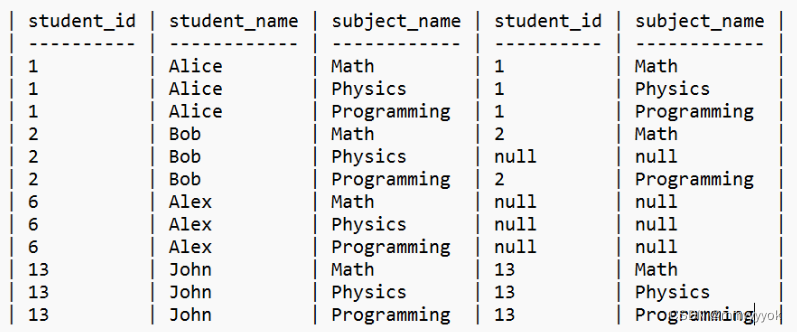
https://leetcode.cn/problems/students-and-examinations/solutions/2323062/xin-shou-jie-ti-fen-xi-ti-mu-yi-bu-yi-bu-xx8g/
运行代码:
select s.student_id,s.student_name,su.subject_name,
count(e.subject_name) as attended_exams
from Students as s
join Subjects as su
left join Examinations as e
on e.student_id=s.student_id
and e.subject_name=su.subject_name
group by s.student_id,su.subject_name
order by s.student_id,su.subject_name
知识点:
(1)分组查询group by,按照学生的学号和课程号再去在e表中进行计数
(2)笛卡尔积连接通常用于生成所有可能的组合,但应谨慎使用,以避免生成不必要的大量数据。左连接则更常用于确保返回左表中的所有记录,即使右表中没有匹配的记录。在需要保留左表所有记录的情况下,左连接是更好的选择。
学生们参加各科成绩的次数(多表连接查询)

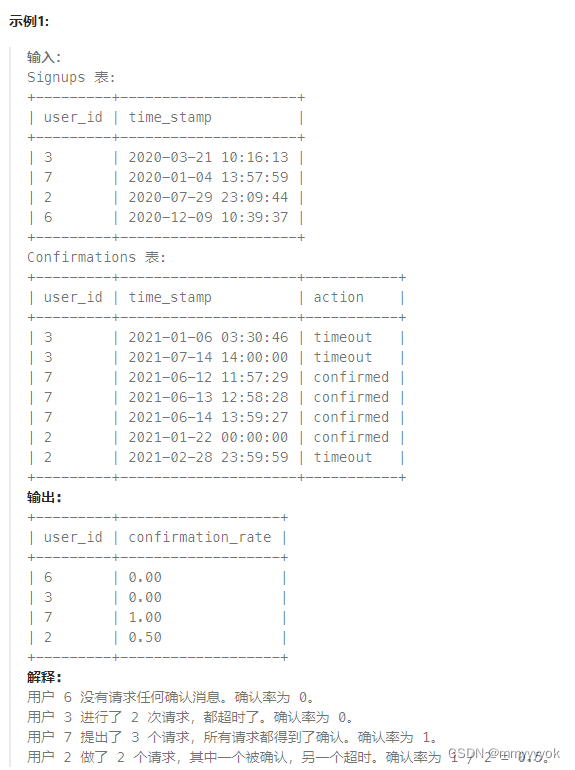
解题思路:
(1)确认率是confirmed消息的数量除以请求的确认消息的总数。
(2)没有请求任何确认消息的用户的确认率为0。左连接之后,用round进行四舍五入,然后在sum函数嵌套一个if函数 ,
如果类型为confirmed,那么就进行+1,否则什么也不做,然后除以group by之后的总action,就能得到确认率,但是这种方法算不了action为null的user,所以在if里面改一下,count(action)改为count(user_id),这样为null的也能算进去。
(3)确认率四舍五入到小数点后两位
select a.user_id,
round(sum(if (b.action='confirmed',1.00,0.00)) / count(a.user_id), 2) as confirmation_rate
from Signups a left join Confirmations b on a.user_id = b. user_id
group by a.user_id















 363
363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









