







项目简介
简介
本文学习了一个个人信贷违约预测模型代码,方法并不是复杂,但适合新手进行学习。对于Anaconda环境配置这里不再赘述。
原文和代码
原文来自:
手把手教你:个人信贷违约预测模型
原代码来自原代码和数据:
我修改了少量代码,代码都会在下方展出,具体的数据集和原先代码可以点击原博主放的链接。
模型具体代码解析
解析数据集
在原文的代码中,除了ipynb包还有csv格式的数据集。第一步,就是导入数据集:
import pandas as pd
load_data=pd.read_csv("LoanStats3a.csv",skiprows=1,low_memory=False)
load_data.head() #检查数据前五行
显示:
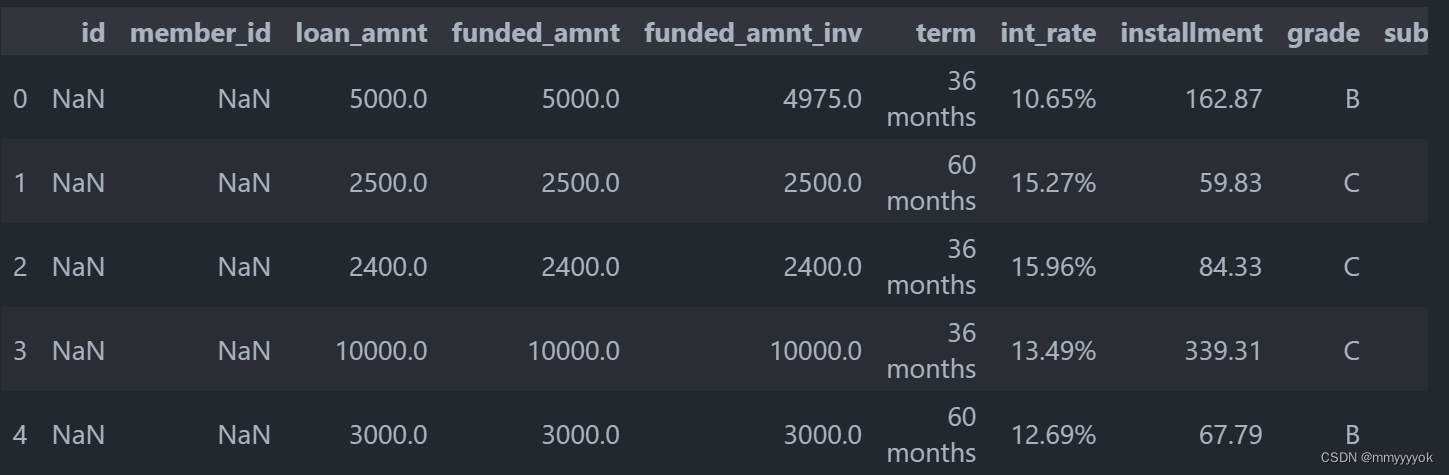
5 rows × 122 columns
load_data=load_data.dropna(axis=1,how='all')
load_data.head()
load_data.dropna(axis=1, how=‘all’):
这行代码尝试删除 load_data 这个 DataFrame 中所有值都是 NaN 的列。axis=1 表示操作在列上执行。how=‘all’ 表示只有当列的所有值都是 NaN 时,该列才会被删除。
特征选择和特征清洗
数据清洗主要做数据类型的转换,以及处理缺失数据。
原文代码:
# 选择所需的列
load_data_clean=load_data[['loan_amnt','funded_amnt','term','int_rate',
'installment','emp_length','dti',
'annual_inc','total_pymnt',
'total_pymnt_inv',
'total_rec_int','loan_status']]
del load_data # 删除原始的load_data以节省内存
#注意输入的变量必须是量化的值,不能是字符串
#采用针对矩阵的元素的函数实现
import re #正则表达式的包
# 从字符串中提取数字
def extract_number(string):
num=re.findall('\d+',str(string))
if len(num)>0:
return int(num[0])
else:
return 0;
load_data_clean.emp_length=load_data_clean.emp_length.apply(extract_number)
load_data_clean.head()
请注意,使用apply方法将extract_number函数应用于load_data_clean DataFrame中的emp_length列。然而,emp_length列可能包含像’10+ years’或’2 years’这样的字符串,其中包含了非数字字符。直接使用extract_number函数可能无法正确提取年数,因为该函数当前只是查找字符串中的第一个连续数字序列并将其转换为整数。
为了正确地从emp_length列中提取年数,可以修改extract_number函数来适应这种字符串格式。下面是一个修改后的函数示例,该函数可以处理包含’years’或’+'的字符串,并尝试提取年数:
import pandas as pd
import re
# 假设load_data已经被加载并且包含所需的数据
# 选择所需的列
load_data_clean = load_data[['loan_amnt', 'funded_amnt', 'term', 'int_rate',
'installment', 'emp_length', 'dti',
'annual_inc', 'total_pymnt',
'total_pymnt_inv',
'total_rec_int', 'loan_status']]
del load_data
# 定义一个函数来从'emp_length'中提取年数
def extract_years_from_emp_length(string):
if pd.isnull(string) or pd.isna(string) or not isinstance(string, str):
return 0 # 返回0或NaN,取决于你想要的处理方式
match = re.search(r'(\d+)', string)
if match:
return int(match.group(1))
else:
return 0 # 或者你可以选择返回NaN或其他默认值
# 应用函数到'emp_length'列
load_data_clean['emp_length'] = load_data_clean['emp_length'].apply(extract_years_from_emp_length)
# 对于'int_rate'列,如果需要,可以类似地提取数字部分并转换为小数
def extract_decimal_from_int_rate(string):
if pd.isnull(string) or pd.isna(string) or not isinstance(string, str):
return None # 或者返回0.0,取决于你的需求
match = re.search(r'(\d+\.\d+)', string) # 假设int_rate总是有小数点后的数字
if match:
return float(match.group(1)) / 100 # 转换为小数并除以100(如果需要)
else:
return None # 或者返回0.0或其他默认值
# 如果需要,应用函数到'int_rate'列
# load_data_clean['int_rate'] = load_data_clean['int_rate'].apply(extract_decimal_from_int_rate)
# 显示前几行以验证清理后的数据
load_data_clean.head()
数据清理后的结果:
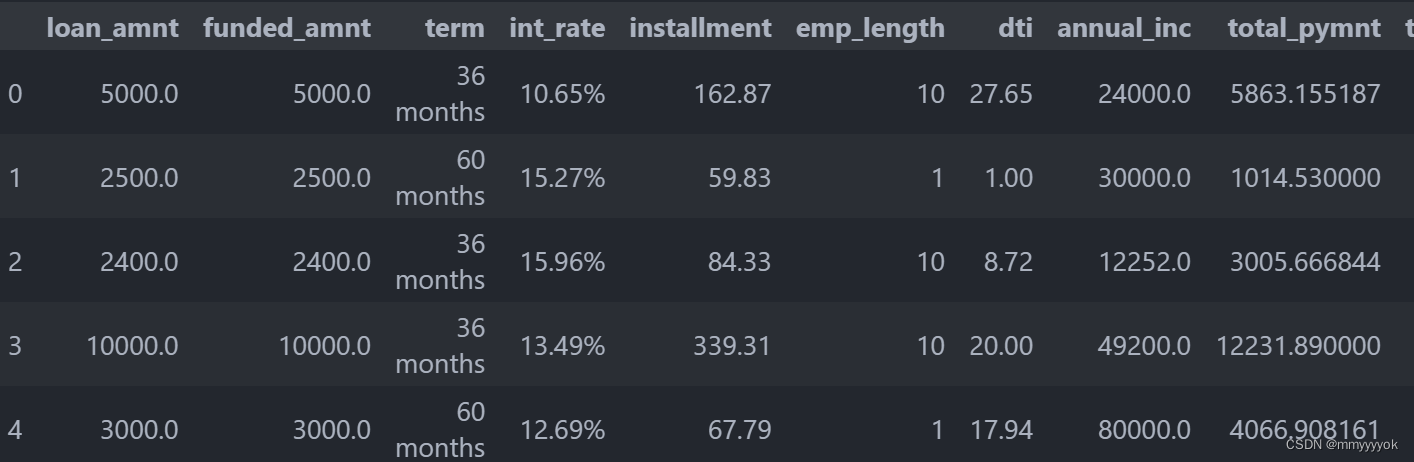
提取数字,剔除掉百分号等字符:
load_data_clean.term=load_data_clean.term.apply(extract_number)
#使用之前定义的 extract_number 函数来从 term 列中提取数字,
# 并将其应用于 load_data_clean DataFrame 的 term 列
load_data_clean.head()
检查结果:
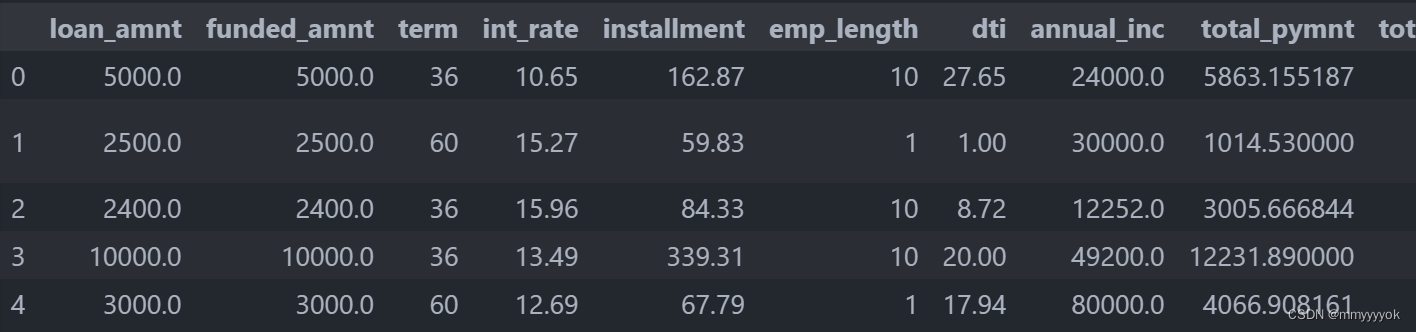
不难发现,百分号,“months”等字符都没有了。
清理int_rate列:
load_data_clean.int_rate=load_data_clean.int_rate.apply(\
lambda x: float(str(x).replace('%','')))
#清理 load_data_clean DataFrame 中的 int_rate 列,该列包含表示年利率的字符串,如 "15.0%"。
# 使用了一个 lambda 函数来移除百分号 %,并将剩余的字符串转换为浮点数。
load_data_clean.describe()
# 保存预处理数据
load_data_clean.to_csv("data_train.csv",encoding='utf-8-sig',index=False)
数据可视化
导入相关库,进行数据可视化。
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#用于在Jupyter Notebook中内联显示matplotlib图形,只能在jupyter notebook中使用
load_data_clean = load_data=pd.read_csv("data_train.csv",encoding='utf-8-sig') #数据存储赋值
load_data_clean.head()
检查一下:
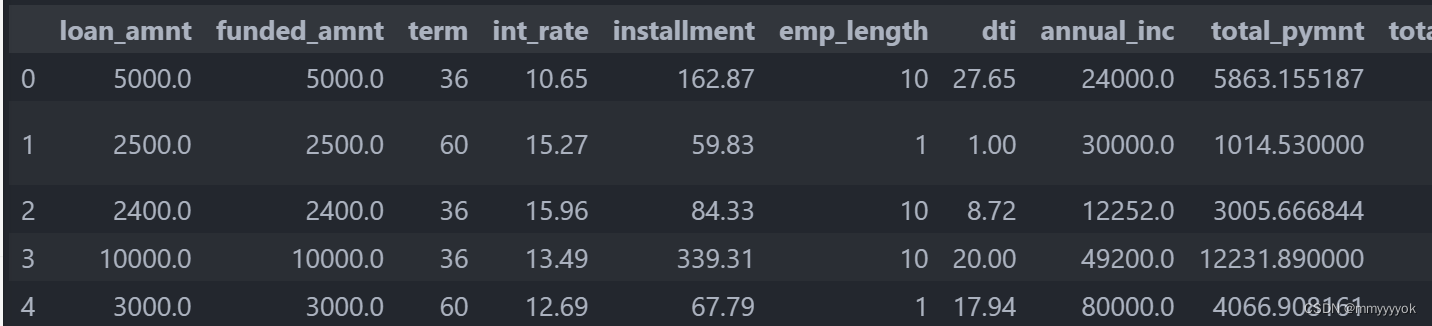
load_data_clean.plot(figsize=(15,6))
#用于绘制数据框中的列,为数值型数据设计

原博文代码给的是简单的条形图,这里将其修改为了箱线图,筛选了loan_amnt 列在 25% 到 75% 范围内的数据。
#异常数据排除
#这是一个条形图
#sns.boxplot(x=load_data_clean.loan_amnt)
#只取25%--75%的数据
import pandas as pd
import seaborn as sns
# 分析列loan_amnt
#箱线图
# 计算四分位数
Q1 = load_data_clean['loan_amnt'].quantile(0.25)
Q3 = load_data_clean['loan_amnt'].quantile(0.75)
# 筛选 25% 到 75% 之间的数据
filtered_data = load_data_clean[(load_data_clean['loan_amnt'] >= Q1) & (load_data_clean['loan_amnt'] <= Q3)]
# 现在 filtered_data 包含了 loan_amnt 列在 25% 到 75% 范围内的数据
sns.boxplot(x=filtered_data['loan_amnt'])
原博客代码这里的可视化结果:
sns.boxplot(x=load_data_clean.loan_amnt)

修改后的可视化结果:

绘制其他一些图表:
load_data_clean.annual_inc.plot()
#绘制年收入图表

load_data_clean.int_rate.plot()

展示loan_amnt(贷款量)和 installment(分期付款的量)之间的关系:
#使用 matplotlib 的 scatter 函数来绘制一个散点图,
#展示 loan_amnt(贷款量)和 installment(分期付款的量)之间的关系
plt.figure(figsize=(15,6))
plt.scatter(load_data_clean.loan_amnt,load_data_clean.installment,c='b',alpha=0.5)
plt.xlabel('loan_amnt')
plt.ylabel('installment')
Text(0, 0.5, ‘installment’)

接着对一个load_data_clean中的loan_status列进行清洗和转换,并随后对清洗后的列进行统计和可视化。
(1)定义correct_label函数:
该函数接受一个字符串string作为输入。
如果string中包含’not’字符串或者string为空(经过str(string)转换后),则返回字符串’reject’。否则,将string中的空格’ ‘替换为下划线’_',并返回修改后的字符串。
(2)应用correct_label函数到loan_status列:
使用Pandas的apply方法将correct_label函数应用到load_data_clean DataFrame的loan_status列中的每一个元素上。这将清洗和转换loan_status列中的每一个值。
(3)统计和可视化loan_status列的值:
使用Pandas的value_counts方法来统计loan_status列中各个值的出现次数。
使用Matplotlib的plot方法绘制一个条形图,其中kind='bar’指定了条形图的类型colormap='Dark2’设置了颜色映射。
(4)找出包含空值的行:
使用pd.isnull(load_data_clean).any(axis=1)来检查load_data_clean DataFrame中的每一行是否包含任何空值(NaN)。结果是一个布尔序列,指示哪些行包含空值。
def correct_label(string):
if 'not' in str(string) or not str(string):
return 'reject'
else:
return str(string).replace(' ','_')
load_data_clean.loan_status=load_data_clean.loan_status.apply(correct_label)
#使用 value_counts 方法统计了更新后的 loan_status 列中各个值的出现次数
load_data_clean.loan_status.value_counts().plot(kind='bar',colormap='Dark2')
load_data_clean[pd.isnull(load_data_clean).any(axis=1)]
展示结果:
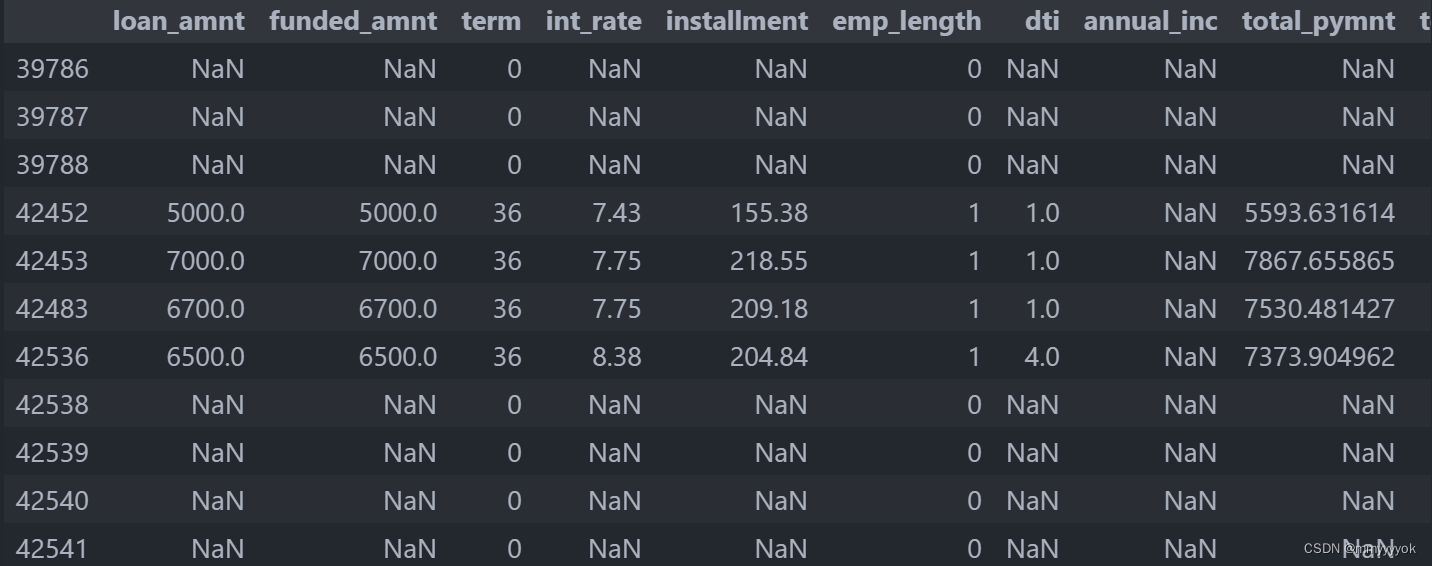

移除包含任何空值(NaN)的行:
#如果某一行至少有一个 True 值(即至少有一个空值),那么该行的结果就是 True;否则为 False
#load_data_clean=load_data_clean[pd.isnull(load_data_clean).any(axis=1)!=True]
#以下是简化写法
load_data_clean = load_data_clean.dropna(how='any')
#或者:load_data_clean = load_data_clean[~pd.isnull(load_data_clean).any(axis=1)]
风险预测模型建模
完成上述数据处理后我们构建不同的模型进行训练并预测。原博客给出高斯朴素贝叶斯模型、随机森林还有逻辑回归模型进行了不同的建模预测,本文仅给出高斯朴素贝叶斯模型和逻辑回归模型。先导入模型训练需要的库和一些预处理:
from sklearn.naive_bayes import GaussianNB #基本的机器学习模型 流行的库 代表朴素贝叶斯分类器的一个版本
from sklearn.model_selection import train_test_split #用于将数据集随机划分为训练集和测试集
from sklearn.metrics import roc_curve,roc_auc_score,classification_report,accuracy_score,precision_score #评估AOC、RUC曲线,显示评估指标,分类准确度、精度
from collections import Counter #计数数据集中的标签或特征
# 剔除reject
#统计 loan_status 列中每个状态的出现次数,如返回{'approved': 100, 'reject': 50, 'pending': 25}这样的字典
Counter(load_data_clean.loan_status)
#过滤掉 loan_status 列中值为 'reject' 的所有行,过滤后重新赋值给load_data_clean
load_data_clean = load_data_clean.loc[load_data_clean['loan_status']!='reject']
#load_data_clean DataFrame 将只包含那些 loan_status 不是 'reject' 的行
定义目标变量Y:
Y=load_data_clean.loan_status
Y.head()
#dtype: object 表明这个 Series 包含的是字符串类型的数据(在pandas 中,字符串类型通常被标记为 object)。
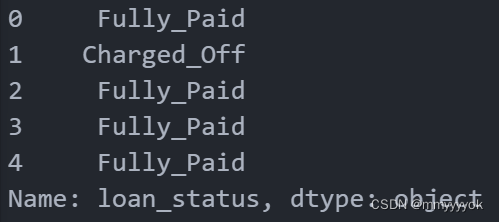
Counter(Y) #统计这个 Series 中每个唯一值(即贷款状态)的出现次数
结果:

X=load_data_clean.drop('loan_status',axis=1) # 特征
#删除了名为 'loan_status' 的列,axis=1 指定了您希望在列(而不是行)上进行操作
X.head()
结果:
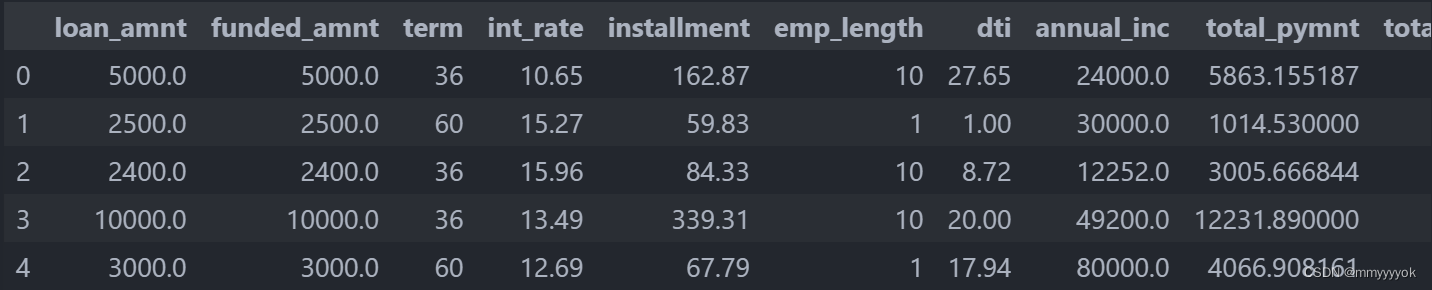
将特征(X)和目标变量(Y)分割成训练子集和测试子集:
#训练子集上训练模型,并在测试子集上评估模型的性能
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.3,random_state=0) #30%的数据来测试模型是否准确
#random_state=0 参数确保了在每次运行代码时,数据分割的方式都是相同的(即可复现性)
采用高斯朴素贝叶斯模型
高斯朴素贝叶斯模型(Gaussian Naive Bayes)是一种基于贝叶斯定理和特征条件独立假设的分类方法,它假设每个非类别属性(即特征)都服从高斯(正态)分布。
使用scikit-learn库中的GaussianNB类来创建和训练一个高斯朴素贝叶斯模型:
#fit 方法会根据 X_train 中的特征和 Y_train 中的标签来训练 gnb_model。
# 训练完成后,gnb_model 将能够使用学习到的参数来预测新数据点的类别。在这个例子中,是预测贷款的状态。
gnb_model=GaussianNB()
gnb_model.fit(X_train,Y_train)
from sklearn.metrics import accuracy_score, classification_report
# 训练集
# 模型预测可以给出概率的结果
train_probs = gnb_model.predict_proba(X_train)
# 返回概率最高的结果
train_predict = gnb_model.predict(X_train)
# 测试集
# 模型预测可以给出概率的结果
test_probs = gnb_model.predict_proba(X_test)
# 返回概率最高的结果
test_predict = gnb_model.predict(X_test)
# 把预测的结果和真实的结果比较
# 在训练集上评估模型
print('-----------------训练集上评估结果:-----------------------')
print('Training accuracy_score:', accuracy_score(Y_train, train_predict))
print('\nTraining Classification report:\n', classification_report(Y_train, train_predict))
# 在测试集上评估模型
print('-----------------测试集上评估结果:-----------------------')
print('Test accuracy_score:', accuracy_score(Y_test, test_predict))
print('\nTest Classification report:\n', classification_report(Y_test, test_predict))
# 通常,我们在训练集上评估模型是为了诊断模型是否过拟合或欠拟合,并在独立的测试集上评估模型是为了估计其在新数据上的性能。
原代码把训练集上的评估结果描述为“测试集上得分”,这可能会导致混淆。这里进行了小修改。
这时候会有训练集上评估结果和测试集上评估结果。
展示ROC曲线:
# 类别编码函数
from sklearn.preprocessing import LabelEncoder
le_credit_level = LabelEncoder().fit(Y)
# 类别编码
gnb_train_y = le_credit_level.transform(Y_train)
gnb_train_pre = le_credit_level.transform(train_predict)
gnb_test_y = le_credit_level.transform(Y_test)
gnb_test_pre = le_credit_level.transform(test_predict)
plt.rcParams['figure.figsize']=6,4
# # 训练集
# fpr,tpr,threshold=roc_curve(gnb_train_y,gnb_train_pre)
# plt.plot(fpr,tpr,color='green',label='GaussianNB_train')
# 测试集
fpr_opt,tpr_opt,threshold_opt=roc_curve(gnb_test_y,gnb_test_pre)
plt.plot(fpr_opt,tpr_opt,color='darkorange',label='GaussianNB_test')
plt.plot([0,1],[0,1],color='black')
plt.title('ROC Curve')
plt.legend()

采用逻辑回归模型
使用了LogisticRegression类来构建一个逻辑回归模型:
from sklearn.linear_model import LogisticRegression
#构建模型参数
LGR = LogisticRegression(penalty='l2', multi_class='multinomial',solver="newton-cg",n_jobs=12)
#训练模型
#使用训练数据X_train和对应的标签Y_train来训练逻辑回归模型
LGR.fit(X_train, Y_train)
这里创建了一个LogisticRegression类的实例LGR,并指定了一些参数:
(1)penalty=‘l2’:指定使用L2正则化(也称为岭回归)。
(2)multi_class=‘multinomial’:当处理多类问题时,指定使用多项式损失,适用于标签是离散的并且有序的情况(比如,星级评分)。对于无序的多类问题,通常使用’ovr’(one-vs-rest)或’multinomial’(当且仅当solver为’lbfgs’, ‘newton-cg’, ‘sag’, 'saga’或’elastic_net’时)。
(3)solver=“newton-cg”:指定优化算法。'newton-cg’是一种基于牛顿法的优化算法,适用于L2惩罚项的多类逻辑回归。
(4)n_jobs=12:指定用于并行计算的CPU核心数。注意,不是所有的solver都支持并行处理,'newton-cg’在某些情况下可能不支持。
train_probs=LGR.predict_proba(X_train)
train_predict=LGR.predict(X_train)
test_probs=LGR.predict_proba(X_test)
test_predict=LGR.predict(X_test)
#做出预测
print('-----------------训练集上评估结果:-----------------------')
print('Test accuracy_score:',accuracy_score(Y_train,train_predict))
print('\nTest Classification report:\n',classification_report(Y_train,train_predict))
print('-----------------测试集上评估结果:-----------------------')
print('Test accuracy_score:',accuracy_score(Y_test,test_predict))
print('\nTest Classification report:\n',classification_report(Y_test,test_predict))
更多代码还有各模型的ROC曲线笔记请看原博客:【代码分享】手把手教你:个人信贷违约预测模型















 7999
7999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









