






 该博客介绍了使用Python和Selenium爬取股票历史数据的方法。先从指定网站爬取股票代码,再循环模拟下载数据过程,爬取网易财经的个股历史数据。同时解决了Chrome弹窗问题,实现隐藏浏览器爬取。
该博客介绍了使用Python和Selenium爬取股票历史数据的方法。先从指定网站爬取股票代码,再循环模拟下载数据过程,爬取网易财经的个股历史数据。同时解决了Chrome弹窗问题,实现隐藏浏览器爬取。
股票的历史数据爬取
爬取网易财经的个股历史数据
爬取链接:http://quotes.money.163.com/trade/lsjysj_000001.html?
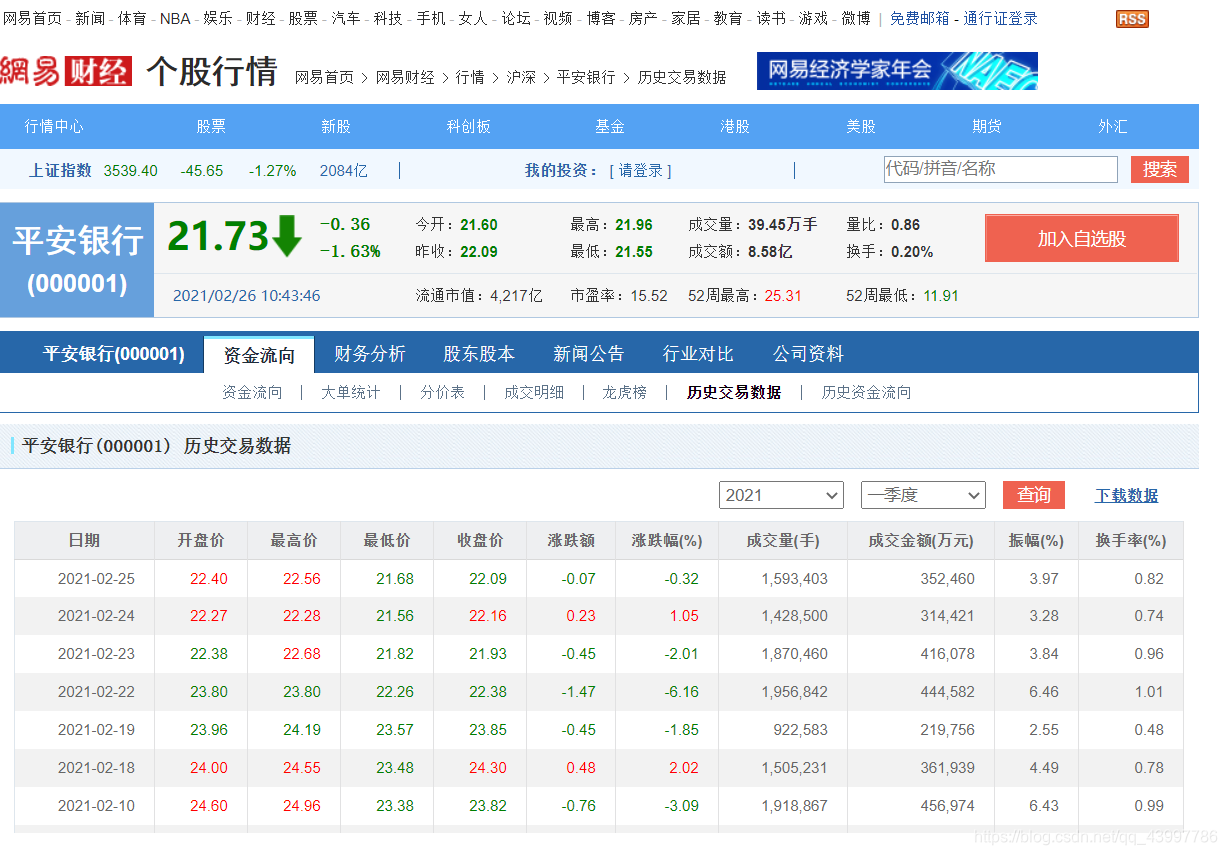
先爬取股票的对应的代码
爬取股票代码的网站
https://www.banban.cn/gupiao/list_sh.html
代码
import requests,pymysql,re,datetime
import pandas as pd
from bs4 import BeautifulSoup
from sqlalchemy import create_engine
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from time import sleep
#1.创建Chrome浏览器对象,这会在电脑上在打开一个浏览器窗口
headers={
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36'
}
def DownStockCode():
print('开始获取上证、深证股票代码')
count = 0
stockcodeList=[]
urlList = ['https://www.banban.cn/gupiao/list_sh.html','https://www.banban.cn/gupiao/list_sz.html']
for url in urlList:
res = requests.get(url=url,headers=headers)
bs_res = BeautifulSoup(res.text,'html.parser')
stocklist=bs_res.find('div',id='ctrlfscont').find_all('li')
for stock in stocklist:
stockhref=stock.find('a')['href']
list_stockhref=stockhref.strip().split('/')
stock_code=list_stockhref[2]
stockcodeList.append(stock_code)
count += 1
print('当前已获取{}只股票代码'.format(count),end='\r')
print('已获取所有上证、深证股票代码:{}个'.format(count))
return stockcodeList

然后循环模拟下载数据的过程
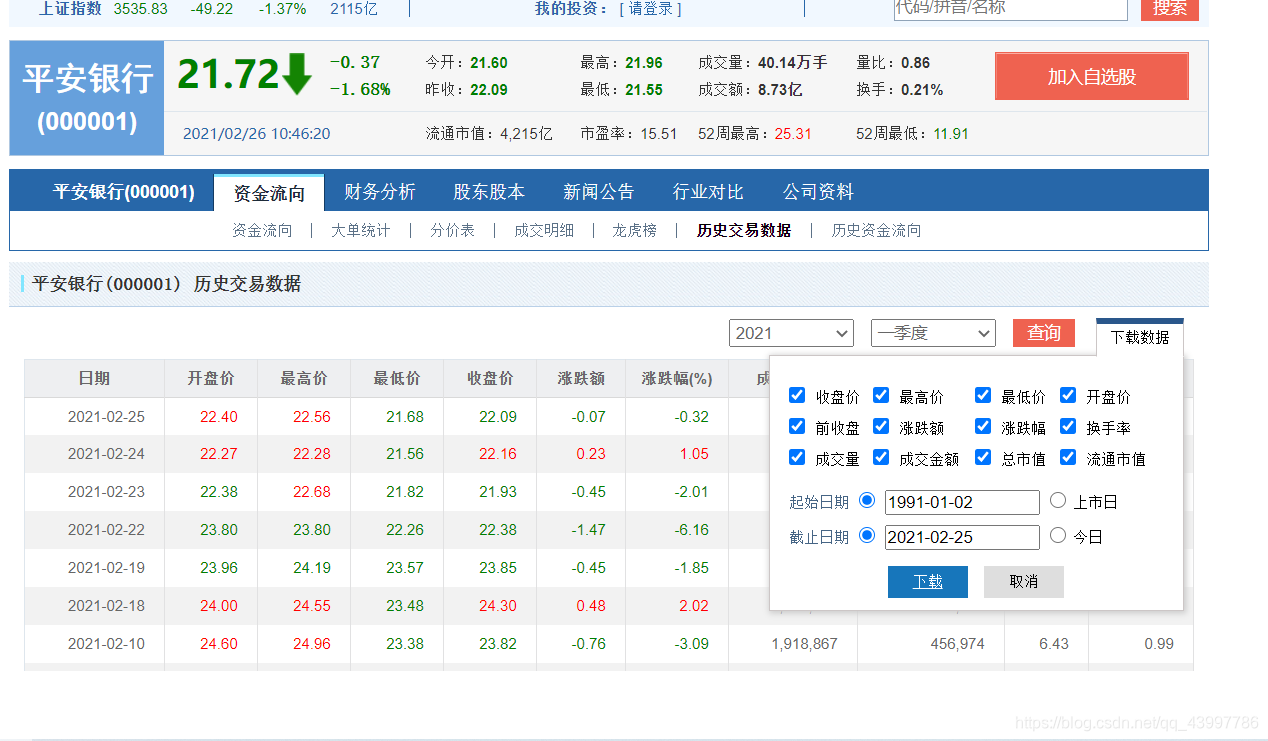
全部代码(运用到selenium)
之前没有解决的问题是chrome会弹窗出来,隐藏浏览器
#隐藏浏览器
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
#隐藏浏览器
新代码
import requests,pymysql,re,datetime
import pandas as pd
from bs4 import BeautifulSoup
from sqlalchemy import create_engine
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from time import sleep
from selenium.webdriver.chrome.options import Options
from PIL import Image,ImageEnhance
#1.创建Chrome浏览器对象,这会在电脑上在打开一个浏览器窗口
headers={
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36'
}
def DownStockCode():
print('开始获取上证、深证股票代码')
count = 0
stockcodeList=[]
urlList = ['https://www.banban.cn/gupiao/list_sh.html','https://www.banban.cn/gupiao/list_sz.html']
for url in urlList:
res = requests.get(url=url,headers=headers)
bs_res = BeautifulSoup(res.text,'html.parser')
stocklist=bs_res.find('div',id='ctrlfscont').find_all('li')
for stock in stocklist:
stockhref=stock.find('a')['href']
list_stockhref=stockhref.strip().split('/')
stock_code=list_stockhref[2]
stockcodeList.append(stock_code)
count += 1
print('当前已获取{}只股票代码'.format(count),end='\r')
print('已获取所有上证、深证股票代码:{}个'.format(count))
return stockcodeList
all_code = DownStockCode()
#隐藏浏览器
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
#隐藏浏览器
browser = webdriver.Chrome(chrome_options=chrome_options)#声明浏览器
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
chrome_options.add_argument('user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36')
#chrome_options.add_argument("--headless")
#browser = webdriver.Chrome(options=chrome_options)
for i in all_code:
#2.通过浏览器向服务器发送URL请求
try:
browser = webdriver.Chrome(options=chrome_options)
browser.get("http://quotes.money.163.com/trade/lsjysj_"+i+".html?")
sleep(5)
#3.刷新浏览器
#定位按钮并点击
#4.设置浏览器的大小
browser.set_window_size(1400,800)
browser.find_element_by_xpath('//*[@id="downloadData"]').click()
browser.find_element_by_xpath('/html/body/div[2]/div[5]/div[2]/form/div[3]/a[1]').click()
sleep(2)
browser.quit()
except:
continue

















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









