







import torch.nn
#原来单卡运行的GPU代码只需要进行少量改掉即可
#现在我有两块GPU,序号是0,1,然后导入以下代码
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"
device_ids = [0, 1]
#原来定义的model传入nn.DataParallel
model = nn.DataParallel(model,device_ids).cuda()
#之后model原来的参数就会全都转移到model.module这个模块下
"""
model.G.train()#原来单卡就可以进行的操作
model.module.G.train()#现在要改为这个代码,其他参数也是同理
"""
其他地方不用改动。
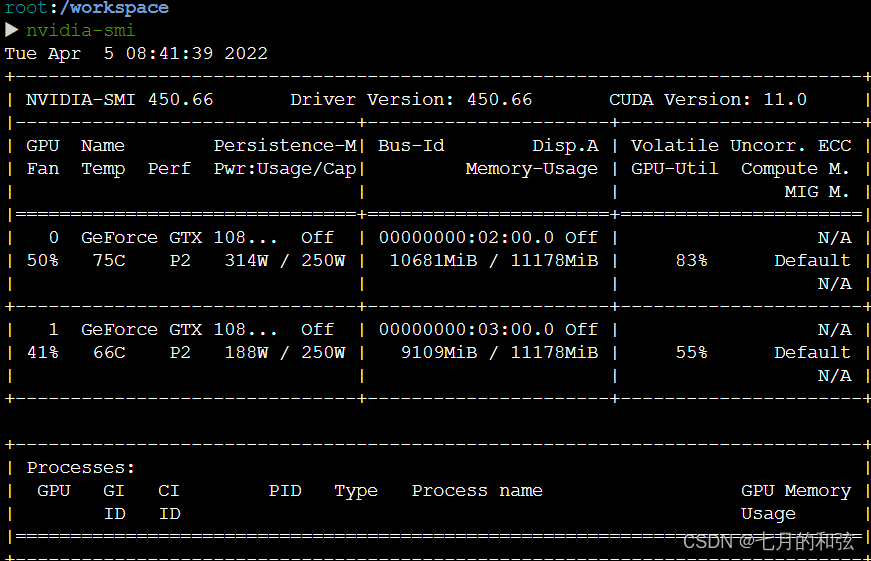
运行代码之后,可以看到2个GPU都被使用了。
原来我得batchsize只能给8,跑一个epoch要90分钟以上
现在batchsize能给到14,跑一个epoch在60分钟左右。
但这是DP(DataParallel)模式,听说DDP模式下进行多卡训练,会更快。后边研究研究














 5589
5589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









