







前言
相较于GCN早期基于频域的若干方法,这篇论文虽然内容较少,方法存在一定的局限性,但是可以说是基于空域GCN的开山之作,它提供了一个很清晰的对非欧式空间进行卷积的思路。但是正如作者在Limitation中提到的,卷积过程中需要考虑所有结点的扩散信息限制了模型在大规模图上的计算能力。所以后续的研究很多都是在邻域进行采样的,以缩小计算量。后续的GraphSAGE可以说是此种方法的升级版
要点
- DCNNs的特点如下:
1.在同构条件下对于图数据类型隐藏特征表示的不变形
2.提升预测性能
3.将学习行为以张量的形式进行体现并作用于GPU上有效实现 - DCNNs通过扫描图结构输入中每个结点的扩散过程来构建一个隐藏特征表示
- DCNNs的优点如下:
1.高准确率
2.灵活可变性,可以表示多种图类型数据例如节点特征,边特征,几乎不用预处理所得到的纯粹结构信息。也就可以应用到多种分类任务(基于结点,边,整个图)
3.由于可以以张量形式表示并作用于GPU,因此有速度上的优势 - 同时此种方法没有限制条件,可以有权或无权,有向或无向。同时可以预测结点,边甚至图
算法
变量声明
定义的变量有
- T T T个图 G 1 G_1 G1~ G T G_T GT
- 每个图 G t = ( V t , E t ) G_t=(V_t,E_t) Gt=(Vt,Et)由 t t t个边和 t t t个顶点组成
- 可以组成 N t ∗ F N_t*F Nt∗F大小的由每个顶点特征值组成的特征矩阵 X t X_t Xt。其中 N t N_t Nt代表 G t G_t Gt图中的顶点个数, F F F代表每个顶点的特征值组成的向量
- 边的信息由 N t ∗ N t N_t*N_t Nt∗Nt大小的邻接矩阵 A t A_t At表示。基于此可以计算出度归一化矩阵 P t P_t Pt,包含了结点 i i i到 j j j的概率
要点
这种设置代表了几种典型的机器学习任务:
- 如果仅有一个图:
a.标签Y代表了结点和边,这样做减少了半监督分类的问题
b.如果输入的图中没有边的信息,进一步降低到了监督分类问题 - 如果不止一个图,同时标签代表的是整个图,这样就代表了监督图分类问题
- DCNN的核心部分是学习一个从节点及其特征到从该节点开始的扩散过程的结果的映射
- DCNN参数根据搜索深度而不是其在网格中的位置进行绑定
- 对于两个同构的输入图,他们的传播卷积激活后的值应该是相同的
- 传播卷积没有池化操作
- DCNN 将 graph g g g 作为输入,然后输出 一个 hard prediction for Y Y Y 或者 一个条件分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)。每一个感兴趣的 entity(结点,边后者整张图) 被转换为一个 传播-卷积表示。也就是转换成一个 H ∗ F H*F H∗F的矩阵(由 H H H阶内的特征向量组成)同时经过了 H ∗ F H*F H∗F的权重向量 W c W _c Wc和非线性可微激活函数f的作用而生成
- 对于节点分类任务,对于图
t
t
t的传播卷积表示
Z
t
Z_t
Zt就是一个
N
t
∗
H
∗
F
N_t*H*F
Nt∗H∗F的张量
对于图或边的分类任务 Z t Z_t Zt就是一个H*F或者 N t ∗ H ∗ F N_t*H*F Nt∗H∗F的张量
具体流程
1.结点分类

P
t
∗
P_t^*
Pt∗是
N
t
∗
H
∗
N
t
N_t*H*N_t
Nt∗H∗Nt维的结点的扩散概率张量,它描述了结点不同Hop之后到达其他结点的概率(根据论文的实现代码,这个张量由邻接矩阵A计算,返回的是3d numpy array [A0, A1, …, A**k])。邻居结点的特征根据这个张量描述的概率向中心结点集中。它被定义为:
 其中,
i
i
i表示结点,
j
j
j表示hop,
k
k
k表示特征,
t
t
t表示第几个图。由此。扩散卷积的操作定义为:
其中,
i
i
i表示结点,
j
j
j表示hop,
k
k
k表示特征,
t
t
t表示第几个图。由此。扩散卷积的操作定义为: 或者换一种更顺眼的写法,注意其中的○乘法表示元素级别的乘积,不是矩阵的乘法
或者换一种更顺眼的写法,注意其中的○乘法表示元素级别的乘积,不是矩阵的乘法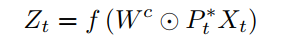
此时矩阵的维度分别是
P
t
∗
P^*_t
Pt∗是
N
t
∗
H
∗
N
t
N_t*H*N_t
Nt∗H∗Nt维,
X
t
X_t
Xt是
N
t
∗
F
N_t*F
Nt∗F维(注意其中的○乘法表示元素级别的乘积,不是矩阵的乘法)则结果
Z
t
Z_t
Zt的维度就是
N
t
∗
H
∗
F
N_t*H*F
Nt∗H∗F
中心结点
i
i
i采集了
j
j
j跳之内所有结点的特征信息,汇总并加权,根据Figure1(a),
Z
t
Z_t
Zt维度为
N
t
∗
H
∗
F
N_t*H*F
Nt∗H∗F的张量。经过下一个dense layer(也就是进行卷积之后)得到
N
t
∗
1
N_t*1
Nt∗1的向量
Y
t
Y_t
Yt。分别使用argmax和softmax分别得到预测结合以及概率分布:

图分类
为了让
Z
t
Z_t
Zt变成
H
∗
F
H*F
H∗F的张量,在这里
1
N
t
1_{N_t}
1Nt(
N
t
∗
1
N_t*1
Nt∗1维)被乘到最前且此时矩阵的维度分别是
P
t
∗
P^*_t
Pt∗是
N
t
∗
H
∗
N
t
N_t*H*N_t
Nt∗H∗Nt维,
X
t
X_t
Xt是
N
t
∗
F
N_t*F
Nt∗F维,正如Figure1(b)显示的那样。
注意最后的 “/Nt”的操作,影响了图分类的效果。

在训练的时候采用随机小批梯度下降,并设置了early stop,learning rate为0.05,激活函数采用tanh。
实验
结点分类的实验的数据集来。在结点分类的任务中对比传统算法

同时,也探究了Hop应该设置为多少才能达到最优,从图中可以看出hop=2收敛,和Kipf的方法不谋而合。
 图分类的数据集来自。从实验结果来看效果差的一批。这些结果表明,虽然扩散过程是节点的有效表示(节点分类),但它们在汇总整个图时表现得很糟糕(由于简单的平均聚合操作)。通过找到一种比简单的平均值更有效的方法来聚合节点操作,可以改进这些结果。
图分类的数据集来自。从实验结果来看效果差的一批。这些结果表明,虽然扩散过程是节点的有效表示(节点分类),但它们在汇总整个图时表现得很糟糕(由于简单的平均聚合操作)。通过找到一种比简单的平均值更有效的方法来聚合节点操作,可以改进这些结果。


优缺点
优点:
- 节点分类准确率很高
- 灵活性
- 快速
缺点:
- 内存占用大:DCNN建立在密集的张量计算上,需要存储大量的张量,需要的空间复杂度。
- 长距离信息传播不足:模型对于局部的信息获取较好,但是远距离的信息传播不足。















 3206
3206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









