







diffusion-convolutional neural networks
发表于NIPS 2016。
abstract
本文提出了针对于图结构数据的模型:diffusion-convolutional neural networks(DCNN)。本文展示了如何通过图结构数据学习到基于传播的数据并被有效用于节点分类。DCNN有很多优秀的特质:图结构的潜在表征在同构的情况下是不变的,计算过程可以被视为可以在多项式时间下完成的向量操作,并能够被有效扩展到GPU之上。通过实验证明,DCNNs在关系节点分类任务上超越了概率关系模型以及图上的核方法。
1.introduction
处理结构数据很具有挑战性。一方面,如果能够有效表达以及挖掘数据结构那么能够提升预测性能,另一方面,找到这样的表征可能很困难,会给预测增加很大的复杂度。
本次工作的目标是设计一个灵活的模型来处理结构数据,它在保持了计算简洁性的同时提升了模型的预测性能。为了达成这些目标,我们通过引入“diffusion-convolution”操作来将CNN扩展到普通的图结构数据上。“diffusion-convolution”在图结构的输入里的每个节点上进行一个diffusion操作来建立潜在表征。
本文的模型的灵感来自于压缩了图传播的表征能够比图本身提供一个更好的预测偏好。图传播(graph diffusion)可以被视为是一个矩阵乘方序列,为包含了内容信息的实体提供直接的机制来可以在多项式时间内被计算以及可以很好地被应用到GPU上。
作为一个模型类,DCNNs具有以下这些优点:
1.准确度:对于图分类任务和节点分类任务超越了其他的迭代模型。
2.灵活性:DCNNs为图数据提供了灵活的表征来编码节点特征、边特征以及单纯的结构信息(在只有很少的预处理的情况下)。DCNNs可以应用于各种图上的分类任务:包括节点分类任务以及全图分类任务。
3.速度:DCNN的预测可以被视为是多项式时间的向量操作序列,可以使用标准库来完成在GPU上的高效率的计算。
2.model
首先做一些问题的符号定义:
T个图的集合
G
=
{
G
t
∣
t
∈
1
,
.
.
.
T
}
G=\{G_t|t\in 1,...T\}
G={Gt∣t∈1,...T}。每个图
G
t
=
(
V
t
,
E
t
)
。
G_t=(V_t,E_t)。
Gt=(Vt,Et)。顶点集合被特征矩阵
X
t
X_t
Xt刻画,维度为
N
t
×
F
N_t \times F
Nt×F,
N
t
N_t
Nt代表了节点的总数,邻接矩阵
A
t
A_t
At,维度为
N
t
×
N
t
N_t \times N_t
Nt×Nt,根据邻接矩阵我们能够计算出一个转移矩阵
P
t
P_t
Pt,它定义出了在图上的节点
i
i
i跳跃到节点
j
j
j的概率(有多大可能两个节点之间发生转移,那肯定是路径越多转移可能性越大)。
G
t
G_t
Gt可能为有向图/无向图,有权图/无权图。节点或者是图具有labels
Y
Y
Y。
我们本次的任务是预测 Y Y Y,就是说,去预测图中每个节点或者是图本身的标签。在具体情况下,就是我们已知一些有标签的实体,去预测剩下没有标签的实体。如果 T = 1 T=1 T=1,标签 Y Y Y是关于图上的节点的话,问题就可以被刻画为半监督分类。如果 T > 1 T>1 T>1,每个图都有标签 Y Y Y的话,这就代表了有监督的图分类任务。
DCNNs可以解决以上提到的所有任务,可以选择返回 Y Y Y的hard 预测,或者conditional distribution P ( Y ∣ X ) \mathbb{P}(Y|X) P(Y∣X)。节点或者是图的实体被转化为一个传播卷积表征(diffusion-convolutional representation),本质上是一个 H × F H \times F H×F的实值矩阵,通过在F个特征上的H-hop的图传播形成。这种图传播的过程通过一个 H × F H \times F H×F的实值权重矩阵 W c W^c Wc以及非线性可积函数 f f f作为激活函数计算得到。所以对于节点分类任务,图 t t t的传播卷积表征 Z t Z_t Zt,会是一个 N t × H × F N_t \times H \times F Nt×H×F的向量(因为共有 N t N_t Nt个节点)。而对于图分类任务来说 Z t Z_t Zt会是一个 H × F H \times F H×F的矩阵。
模型基于传播核的思想,这种思想可以被视为是度量一个图上的两个节点之前的连通性的方式(通过考虑两个节点之间的所有路径),具有更短路径考虑的权重应该更大。传播核为节点分类任务提供了一个很有效的基础。
术语“diffusion-convolution”旨在唤起特征学习、参数绑定和不变性是卷积神经网络的特征。 DCNN 的核心操作是从节点及其特征到到从节点开始的传播结果的映射。与标准的CNN不同,DCNN的参数与传播搜索深度绑定而非是与矩阵中的位置固定。传播卷积表征根据节点的index不变而非根据位置,这就意味着两个同构图的表征将是一致的。和CNN不同,DCNN没有pooling操作。
2.1 node classification
考虑一个节点分类任务,需要预测图中每个节点的标签 Y Y Y,令 P t ∗ P_t^* Pt∗为一个 N t × H × N t N_t \times H \times N_t Nt×H×Nt的向量,包含 P t P_t Pt的乘方序列,定义如下:
节点 i i i,hop j j j,图 t t t,特征 k k k。
传播卷积表征定义如下:
使用向量表示如下:
这个模型只需要 O ( H × F ) O(H \times F) O(H×F)的参数,使得潜在传播卷积表征的大小与输入的大小无关。
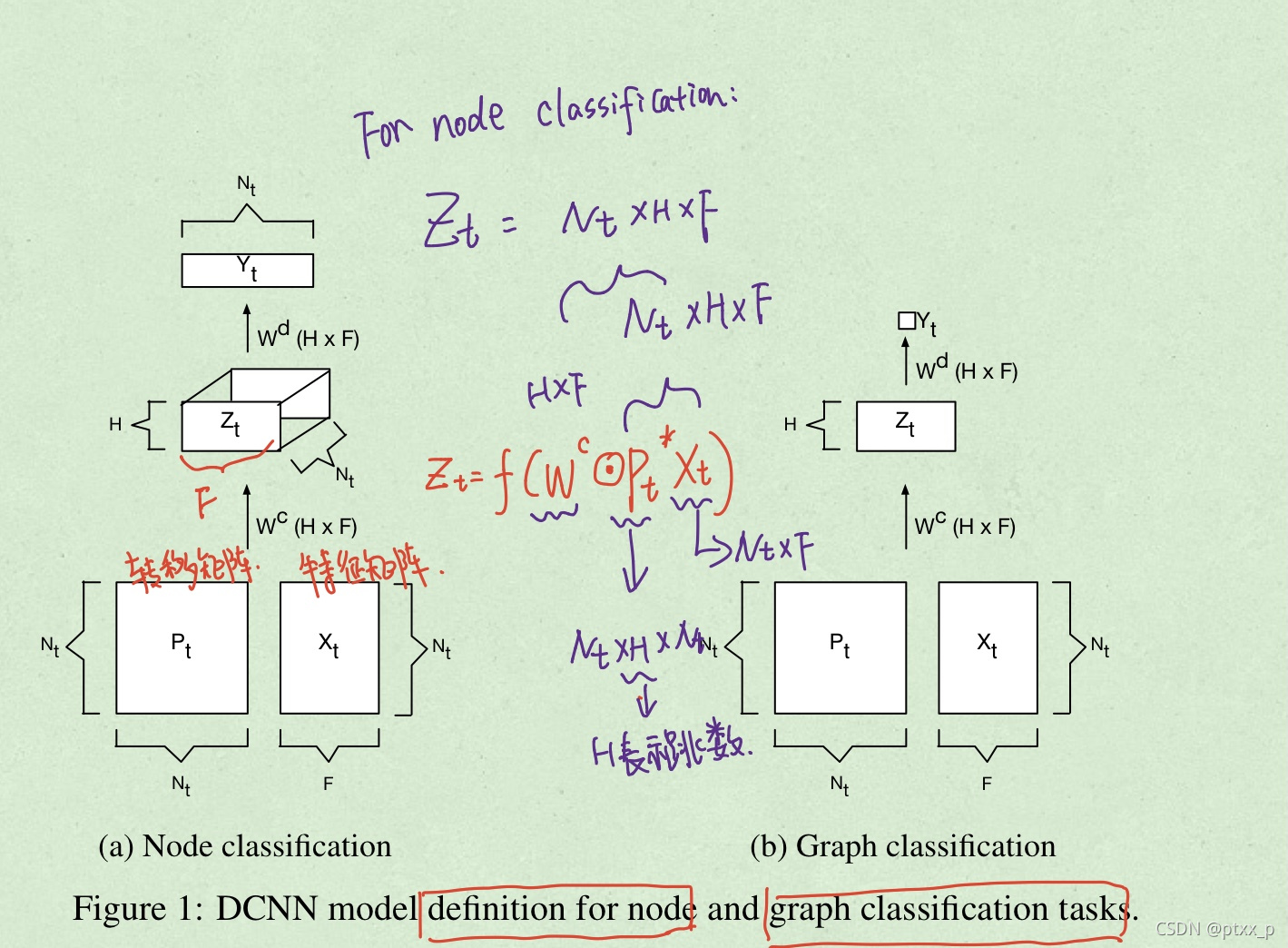
模型通过一个dense层来完成从 Z Z Z到 Y Y Y的转换,hard prediction结果 Y ^ \hat{Y} Y^,可以通过最大值激活得到,条件概率分布 P ( X ∣ Y ) \mathbb{P}(X|Y) P(X∣Y)则可以通过softmax函数激活得到:
2.2 graph classification
图分类任务通过在节点间使用mean激活得到:
其中 1 N t 1_{N_t} 1Nt代表了ones向量,大小为 N t × 1 N_t \times 1 Nt×1。相当于对节点表征在经过权重矩阵表换之前求一个全图的平均。
2.3 purely structural DCNNs
DCNNs可以被应用到没有特征的输入图上,通过将每个节点连接到一个值为1的偏执特征上。更加丰富的结构可以通过添加附加节点特征(如pagerank或者聚类系数)来编码,尽管这样确实引入了手工工程和预处理。
2.4 learning
DCNNs可以基于bp损失的随机小批量梯度下降来学习。在每个epoch中,节点indices随机被划分到不同的batch之中。我们同样设计了早停机制,如果每轮的验证损失的validation error比上几轮的要大的时候就停止训练。
3.experiments
在本部分中,探索了DCNN在节点分类和图分类任务上的表现。
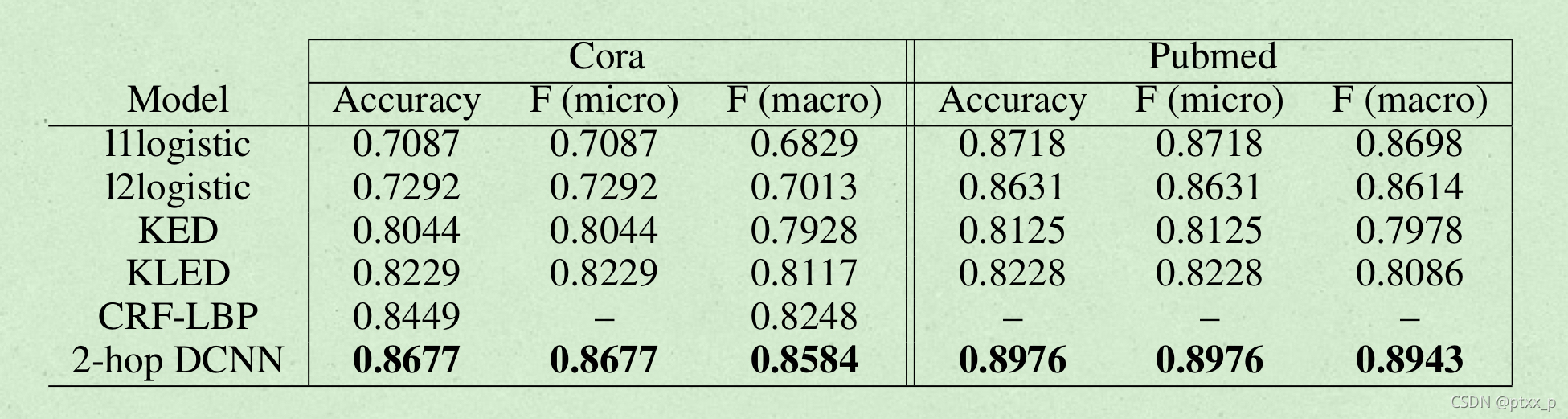
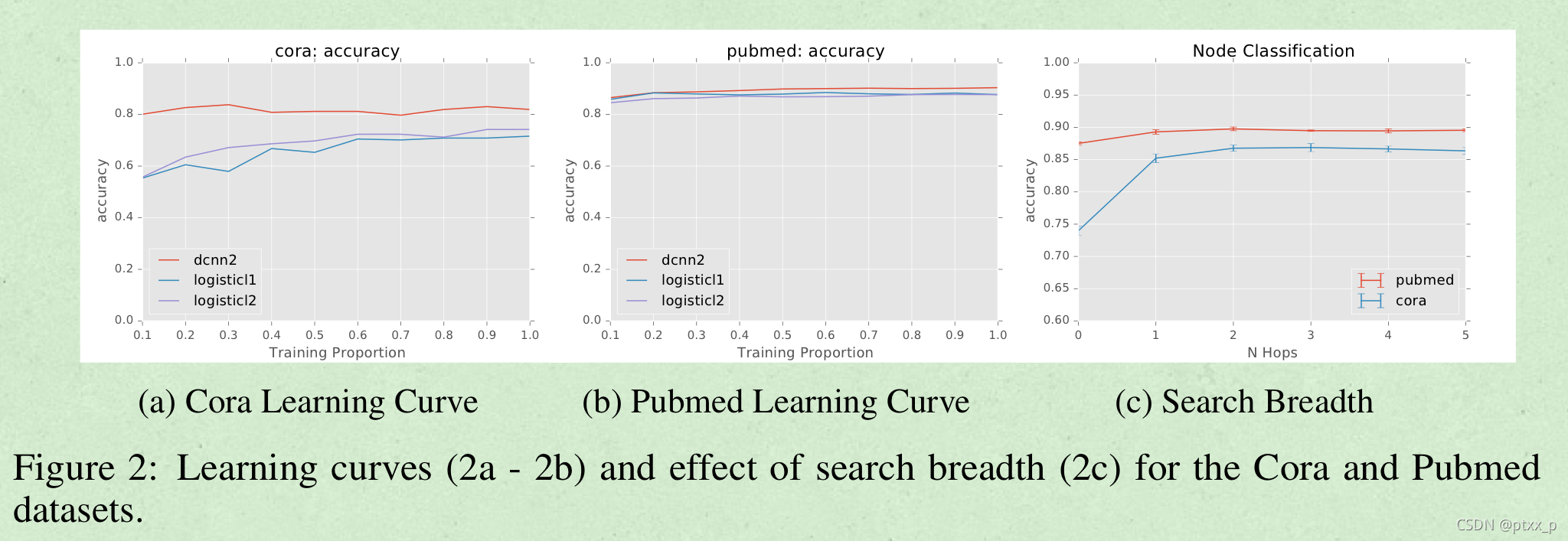
节点分类任务:
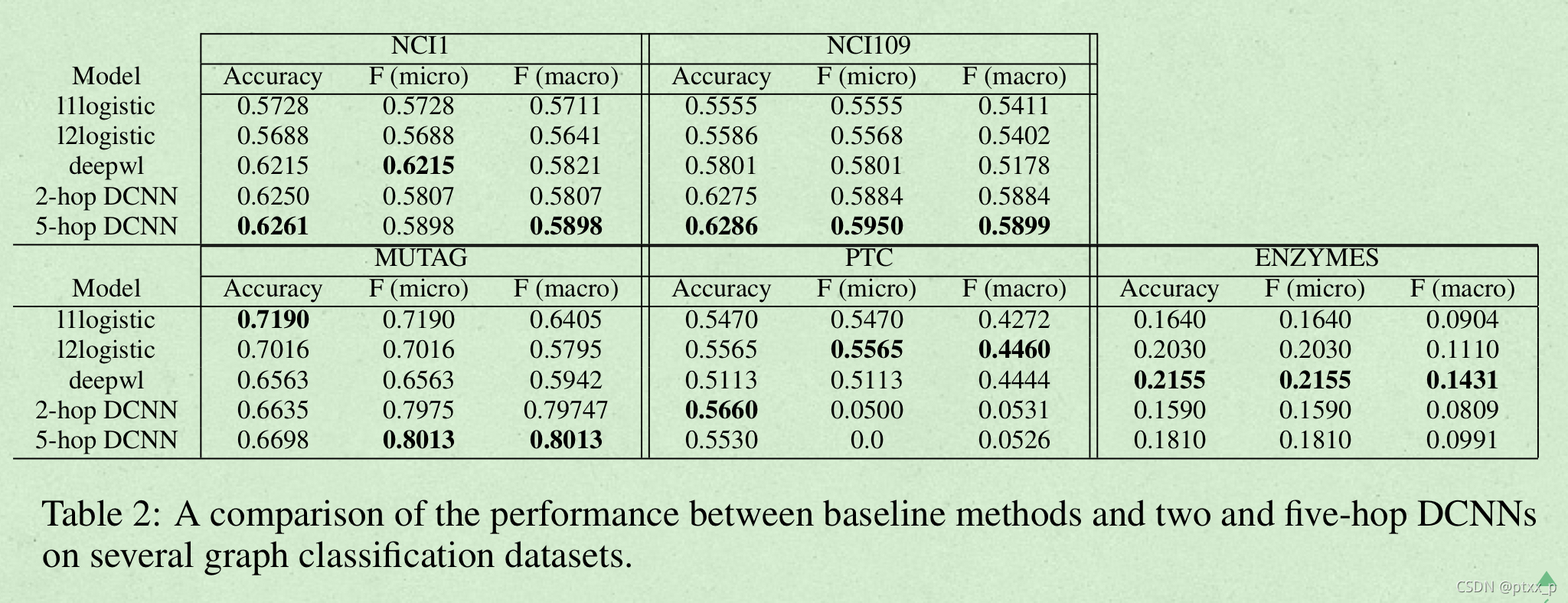
图分类任务:
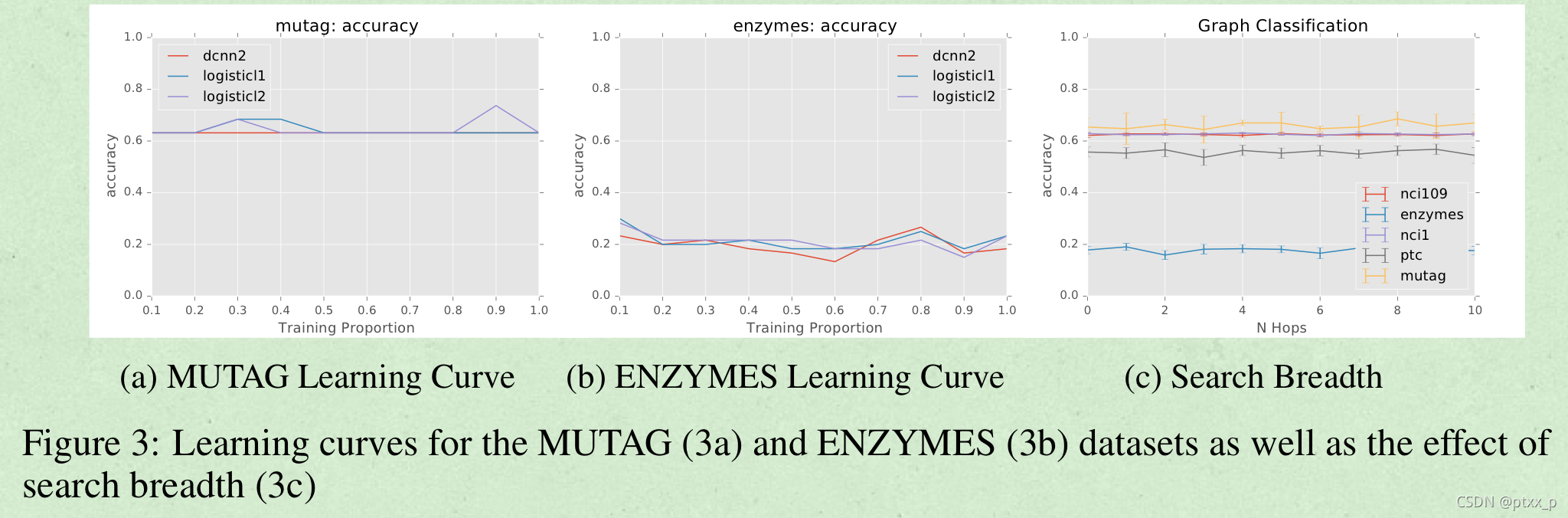
传播过程对于图节点的学习很有效,但是在全图表征上表现较差。需要找到一个比简单的求均值的更好的方法来聚合节点信息成为全图表征。
4.limitations
可扩展性:由于存储 P ∗ P^* P∗向量需要 O ( N t 2 H ) O(N_t^2H) O(Nt2H)的空间大小,所以在大图上可能导致内存溢出的风险。
局部性:可能无法编码单个节点之间有用的远程空间依赖关系或者其他非局部图行为(因为传播过程是基于邻居捕获的)。
5.related work
在本部分中我们将概括一些方法of半监督学习,图分类,边分类,以及讨论它们和DCNNs的关系。
其他基于图的神经网络模型: 其他的一些研究关注如何将CNNs从网格数据扩展到图数据之上。
概率关系模型: DCNN与概率关系模型具有很大的关联性,但是DCNN是确定性的,这预防了学习过程中的指数爆炸。且概率关系模型的计算量更大。
核方法: 核方法可以被概括为通过核技巧来作为预测基础。DCNN与图上的指数传播核关联。指数传播核是矩阵的乘方序列。但是它和传播卷积表征有所不同。首先:传播卷积表征的权重通过反向传播学习得到,而核表征的权重不通过数据学习得到,其次,传播卷积表征通过节点特征和图结构学习得到,而核表征只通过图结构得到,最后表征的纬度不同。
6.conclusion and future work
通过学习图传播表征,DCNN在节点分类任务上超过了概率关系模型和核方法。未来将继续研究全图表征的学习,以及将模型变得更具有扩展性。
ps:作者在附录部分证明了,如果两个图是同构的话,那么他们的传播卷积表征结果将是一致的。

















 3409
3409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









