







1、网页URL: http://www.shicimingju.com/book/sanguoyanyi.html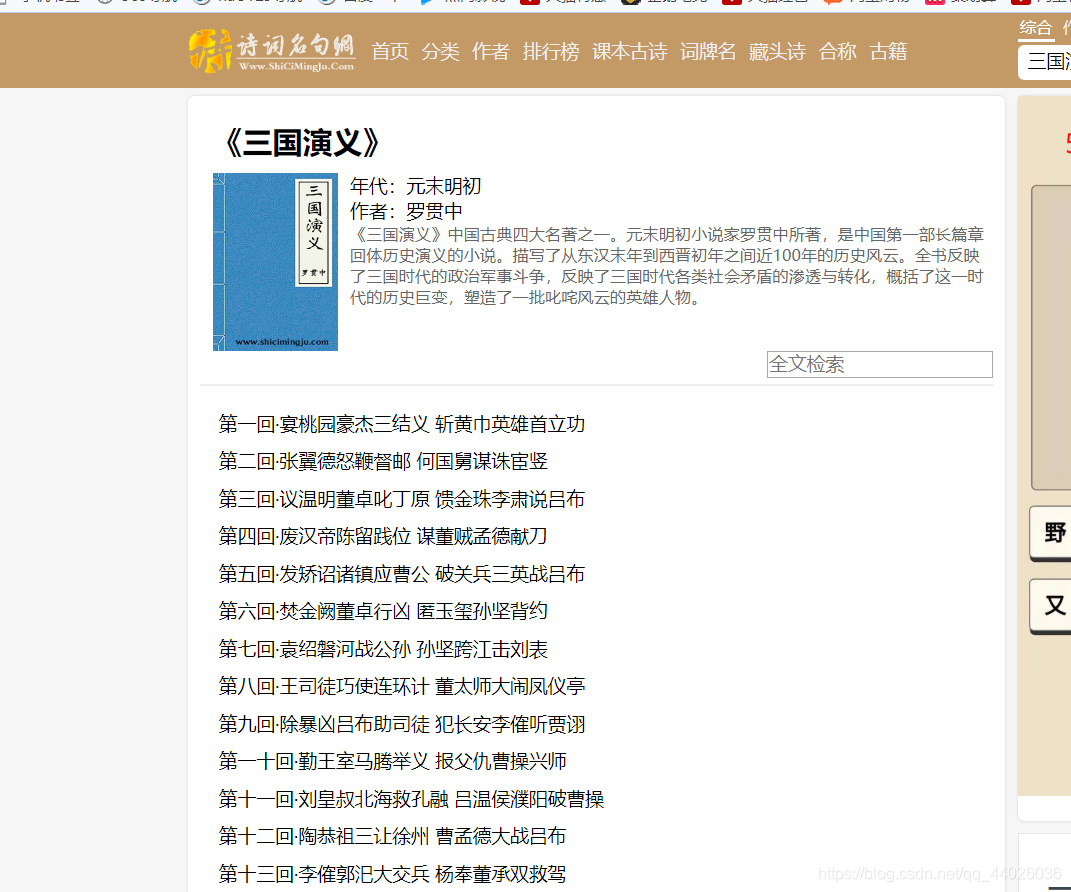
1.1 注意安装环境
pip install bs4
pip install lxml(解析器)
1.2 数据解析原理:
1.2.1 标签定位
1.2.2 提取标签、标签属性中存储的数据值
1.3 bs4数据解析的原理:(bs4只能用于python)
1.3.1实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中
1.3.2通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取。
2、在首页中解析出章节的标题和详情页的url
用F12抓包工具
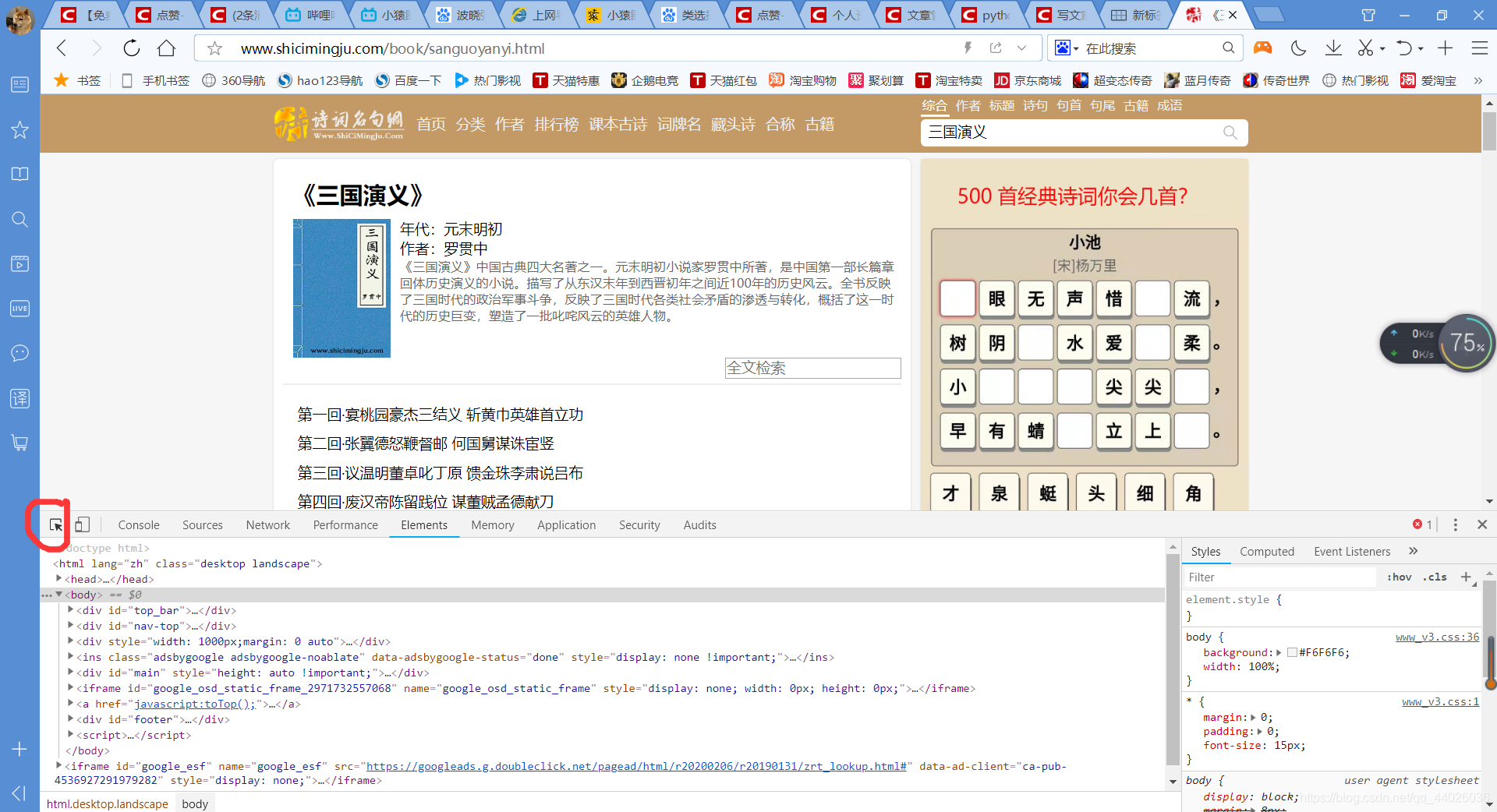
快捷键[Ctrl+Shift+C],选择章节标题部分,会自动在Elements的源码中显示在何处,如图:
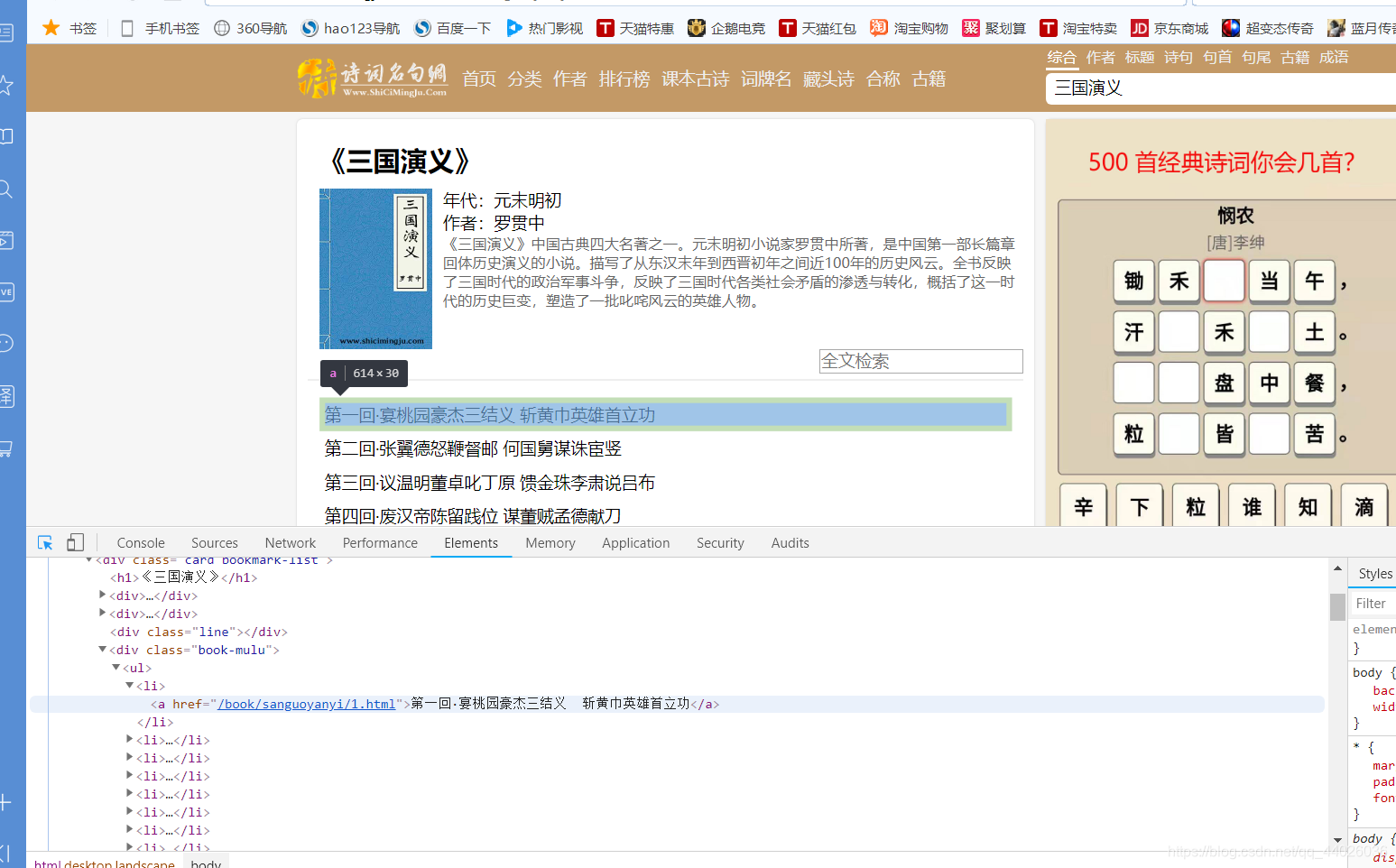
是在div标签下的class =book-mulu 的 ul 子标签的各个 li 子标签的 a 标签中
a标签中有章节标题和章节内容的超链接
解析出章节标题和超链接
结果如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















01-10
 2349
2349
2349
10-24
890
890
11-23
1269
1269
03-02
4351
4351
04-05
2911
2911
09-11
1169
1169
12-26
9935
9935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









