







文章目录
学习链接:https://www.bilibili.com/video/BV1js411g7Fw/?vd_source=8aea3f90602702c9d3488ccfc5071f9c
HTTP协议
- HTTP (Hytper Text Transfer Protocol,全称为 “超文本传输协议”) 是一种应用非常广泛的 应用层协议。
- HTTP 是一种纯文本协议。传输的数据 = 控制信息 + 携带的负荷信息(html、css、js),控制信息是纯文本的,但是它携带的数据信息没有限制。
简化来说:
- weService = HTTP协议+ XML
- Rest = HTTP协议+JSON
- 各种API也是使用 HTTP协议 + JSON/XML来实现的
一、原理
1.形象理解HTTP协议
什么是协议?
计算机的协议和现实中的协议是一样的,一式双份/多份,双方/多方都遵从的一个规范,这个规范就可以称之为协议
HTTP协议即,按一定规则,向服务器要数据,或发送数据,而服务器按一定规则,回应数据
2.HTTP协议的工作流程
- 客户机与服务器建立连接。点击某个超链接,HTTP 工作开始。
- 客户机发送一个请求给服务器。
- 服务器接收到请求后,给予相应的相应信息。
- 客户端接收服务器返回的信息,通过浏览器显示在用户的屏幕上,客户机与服务器断开连接。
3.HTTP请求信息和相应信息的格式
请求:
问:浏览器能发送HTTP协议,那么HTTP协议一定要浏览器发送吗
答:不是,HTTP既然是一种协议,那么只需要满足这种协议,任何工具都可以
1.请求行
例如请求bilibili
GET https://www.bilibili.com/ HTTP/1.1
| 请求方法 | 请求路径 | 请求协议(版本号) |
|---|---|---|
| GET | https://www.bilibili.com/ | HTTP/1.1 |
- 请求方法
HTTP1.0定义了三种请求方法:GET,POST和HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS,PUT,DELETE,TRACE和CONNECT方法
| 方法 | 说明 |
|---|---|
| GET | 向特定的资源发出请求 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中 |
| HEAD | 向服务器索取GET请求相一致的响应,只不过响应体将不会被返回。(取响应头) |
| PUT | 向指定资源位置上传其最新内容 |
| DELETE | 请求服务器删除Request-URL所标识的资源 |
| OPTIONS | 返回服务器针对特定资源所支持的HTTP请求方法,也可以利用向web服务器发送‘*’的请求来测试服务器的功能性 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断(追踪路径) |
| CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器 |
GET 是最常用的 HTTP 方法,常用于获取服务器上的某个资源。
GET 请求的特点:
1.首行里面的第一个部分就是 GET
2.URL 里面的 query string 可以为空,也可以不为空 %E8%9B%8B%E7%B3%95
3.GET 请求的 header 有若干个键值对结构
4.GET 请求的 body 一般是空的
POST 方法也是一种常见的方法,多用于提交用户输入的数据给服务器(如登录页面)。
POST 请求的特点:
1.首行第一个部分就是 POST
2.URL 里面的 query string 一般是空的
3.POST 请求的 header 里面有若干个键值对
4.POST 请求的 body 一般不为空(body 的具体数据格式,由 header 中的 Content-Type 来描述; body 的具体数据长度,由header 中的 Content-Length 来描述
GET和POST的区别:
1.POST 和GET本质都是一样的。
2.POST和GET都是HTTP请求的基本方法。
3.区别主要有以下几个:
3-1 GET请求在浏览器刷新或者回退的时候是无害的。POST的话数据会被重新提交。
3-2 GET可以被书签收藏,POST不行
3-3 GET可以存在缓存中。POST不行
3-4 GET 会将数据存在浏览器的历史中,POST不会
3-5 GET 编码格式只能用ASCII码,POST没有限制
3-6 GET 数据类型urlencode,POST是URLENCODE,form-data
3-7 可见性 参数在URL用户可以看见,POST的参数在REQUSET BODY中不会被用户看见
3-8 安全性 GET相对不安全 POST相对安全些
3-9 长度 参数一般限制2048(和WEB服务器相关),参数无限制。
4.GET 和POST在请求的时候
4-1 GET 是将数据中的hearder 和 data 一起发送给服务端,返回200code
4-2 POST 是先将hearder发给服务器返回100continue,再发送data给到服务器,返回200
4-3 GET 就发送了一个TCP数据包给服务器而POST发送了两次TCP数据包给服务器
4-4 GET和POST是已经有定义好的说明的,最好不要混用。
5. GET和POST本质上是一样的,GET可以加Request Body ,POST也可以在URL中添加参数。实现是可以的。
- 请求路径
URL (Uniform Resource Locator 统一资源定位符),互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL的具体格式:
https://www.bilibili.com/video/BV1js411g7Fw/?vd_source=8aea3f90602702c9d3488ccfc5071f9c
1.资源在哪台主机上——域名 (domain) 或者ip来体现一主机 (host)
2.和主机上的哪个进程去获取资源——端口 (port)(端口常被忽略,使用默认:http:80,https:443)
3.具体定位到是该进程管理的哪个资源——资源路径/路径 (path)
4.URL设计之初,不仅仅为HTTP协议使用。所以需要标识出本次资源对应的协议(protocol/ schema)
5.针对本次请求,除了资源本身之外的特殊要求。(查询字符串query string、文档片段fragment) - 所用协议
所使用的HTTP协议的版本
2.请求头信息
请求头(header)的整体格式是键值对结构,每个键值对占一行,键和值之间使用 冒号+空格 进行分割
| key | value |
|---|---|
| Host | 表示服务器主机的地址和端口 |
| Content-Length | 表示 body 的数据长度,长度单位是字节 |
| Content-Type | 表示 body 的数据格式 |
| User-Agent | 表示浏览器或者操作系统的属性 |
| Referer | 表示这个页面是从哪个页面跳转过来的 |
| Cookie | 是浏览器提供的一种让程序员在本地存储数据的能力 |
| 等… |
请求头Content-Type类型:
application/x-www-form-urlencoded:这是 form 表单提交的数据格式,此时 body 的格式就类似于 query string(是键值对的结构,键值对之间使用 & 分割,键与值之间使用 = 分割multipart/form-data:这是 form 表单提交的数据格式(需要在 from 标签上加上enctyped="multipart/form-data"),通常用于 HTML 提交图片或者文件application/json:此时 body 数据为 json 格式,json 格式就是源自 js 的对象的格式。用一个 { } 括住,里面有多个键值对,键值对之间使用逗号分割,键和值之间使用冒号分割
注意:请求头信息结束后,有一个空行,用来标志头信息的结束以及主体信息的开始,即使没有主体信息,也需要有空行
3.请求主体信息
请求的信息,可以为空
响应
1.响应行
HTTP/1.1 200 OK
| 版本号 | 状态码 | 状态码解释 |
|---|---|---|
| HTTP/1.1 | 200 | OK |
状态码:
| 常见状态码 | 状态码解释 | 说明 |
|---|---|---|
| 200 | OK | 这是一个最常见的状态码, 表示访问成功。抓包抓到的大部分结果都是 200 |
| 404 | Not Found | 没有找到资源。URL 标识的资源不存在, 那么就会出现 404 |
| 403 | Forbidden | 表示访问被拒绝。有的页面通常需要用户具有一定的权限才能访问(登陆后才能访问).。如果用户没有登陆直接访问, 就容易见到 403 |
| 405 | Method Not Allowed | 我们学习了 HTTP 中所支持的方法, 有 GET, POST, PUT, DELETE 等。但是对方的服务器不一定都支持所有的方法(或者不允许用户使用一些其他的方法). |
| 500 | Internal Server Error | 服务器出现内部错误. 一般是服务器的代码执行过程中遇到了一些特殊情况(服务器异常崩溃)会产生这个状态码 |
| 504 | Gateway Timeout | 当服务器负载比较大的时候, 服务器处理单条请求的时候消耗的时间就会很长, 就可能会导致出现超时的情况 |
| 302 | Move temporarily | 临时重定向。在登陆页面中经常会见到 302. 用于实现登陆成功后自动跳转到主页 |
| 301 | Moved Permanently | 永久重定向。当浏览器收到这种响应时, 后续的请求都会被自动改成新的地址。301 也是通过 Location 字段来表示要重定向到的新地址 |
状态码总结:
| 状态码 | 类别 | 原因短语 |
|---|---|---|
| 1XX | Informational (信息性状态码) | 接受的请求正在处理 |
| 2XX | Success (成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection (重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error (客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error (服务器错误状态码) | 服务器处理请求出错 |
2.响应头信息
响应报头的基本格式和请求报头的格式基本一致。
响应报头的 Content-Type 参数:
text/html:表示数据格式是 HTMLtext/css:表示数据格式是 CSSapplication/javascript:表示数据各式是 JavaScriptapplication/json:表示数据格式是 JSON
3.响应体
服务器返回给客户端的文本信息
二、进阶
1.Cookie
来源:https://www.cnblogs.com/bq-med/p/8603664.html
Cookie总是保存在客户端中,按在客户端中的存储位置,可分为内存Cookie和硬盘Cookie。内存Cookie由浏览器维护,保存在内存中,浏览器关闭后就消失了,其存在时间是短暂的。硬盘Cookie保存在硬盘里,有一个过期时间,除非用户手工清理或到了过期时间,硬盘Cookie不会被删除,其存在时间是长期的。所以,按存在时间,可分为非持久Cookie和持久Cookie。
HTTP请求+cookie的交互流程:
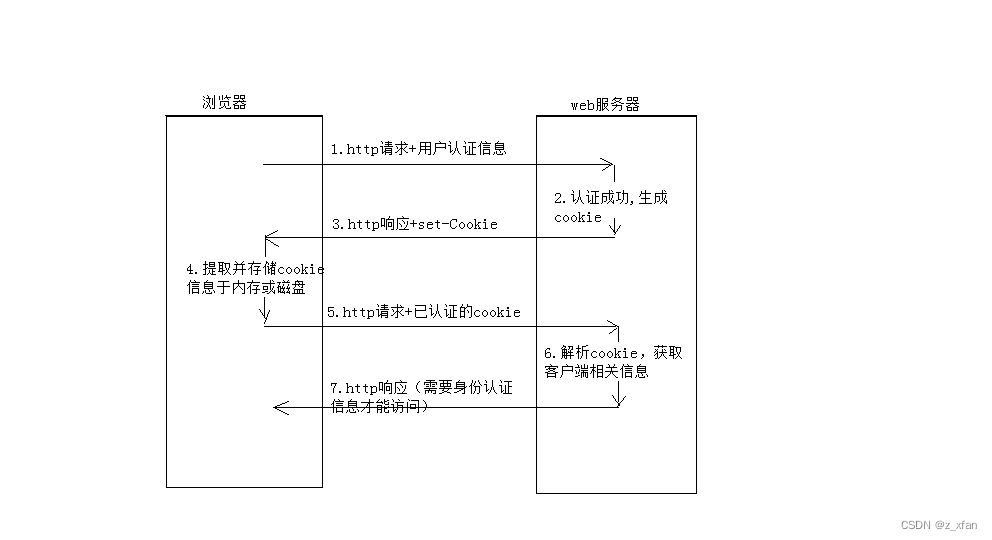
如果步骤5携带的是过期的cookie或者是错误的cookie,那么将认证失败,返回至要求身份认证页面。
HTTP协议作为无状态协议,对于HTTP协议而言,无状态同样指每次request请求之前是相互独立的,当前请求并不会记录它的上一次请求信息。那么问题来了,既然无状态,那完成一套完整的业务逻辑,发送多次请求的情况数不胜数,使用http如何将上下文请求进行关联呢?机智的人类通过优化,找到了一种简单的方式记录http协议的请求信息
优化后的HTTP请求: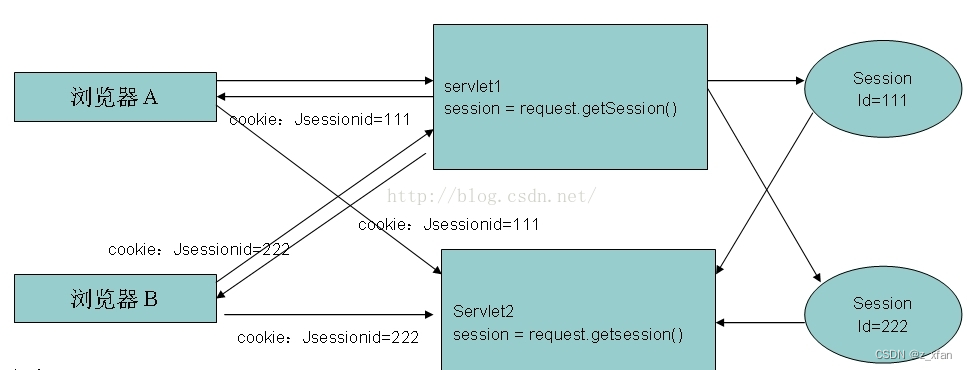
- 浏览器发送request请求到服务器,服务器除了返回请求的response之外,还给请求分配一个唯一标识ID,协同response一并返回给浏览器。
- 同时服务器在本地创建一个MAP结构,专门以key-value(请求ID-会话内容)形式将每个request进行存储
- 此时浏览器的request已经被赋予了一个ID,第二次访问时,服务器先从request中查找该ID,根据ID查找维护会话的content内容,该内容中记录了上一次request的信息状态。
- 根据查找出的request信息生成基于这些信息的response内容,再次返回给浏览器。如果有需要会再次更新会话内容,为下一次请求提供准备。
所以根据这个会话ID,以建立多次请求-响应模式的关联数据传递。说到这里可能已经唤起了大家许多共鸣。这就是cookie和session对无状态的http协议的强大作用。服务端生成这个全局的唯一标识,传递给客户端用于唯一标记这次请求,也就是cookie;而服务器创建的那个map结构就是session。所以,cookies由服务端生成,用于标记客户端的唯一标识,无特定含义,在每次网络请求中,都会被传送。session服务端自己维护的一个map数据结构,记录key-content上下文内容状态。
cookie的属性:
一般cookie所具有的属性,包括:
| 属性 | 解释 |
|---|---|
Domain | 域,表示当前cookie所属于哪个域或子域下面。对于服务器返回的Set-Cookie中,如果没有指定Domain的值,那么其Domain的值是默认为当前所提交的http的请求所对应的主域名的。比如访问 http://www.example.com,返回一个cookie,没有指名domain值,那么其为值为默认的www.example.com。 |
Path | 表示cookie的所属路径。 |
Expire time/Max-age | 表示了cookie的有效期。expire的值,是一个时间,过了这个时间,该cookie就失效了。或者是用max-age指定当前cookie是在多长时间之后而失效。如果服务器返回的一个cookie,没有指定其expire time,那么表明此cookie有效期只是当前的session,即是session cookie,当前session会话结束后,就过期了。对应的,当关闭(浏览器中)该页面的时候,此cookie就应该被浏览器所删除了。 |
secure | 表示该cookie只能用https传输。一般用于包含认证信息的cookie,要求传输此cookie的时候,必须用https传输。 |
httponly | 表示此cookie必须用于http或https传输。这意味着,浏览器脚本,比如javascript中,是不允许访问操作此cookie的。 |
服务器发送cookie给客户端
从服务器端,发送cookie给客户端,是对应的Set-Cookie。包括了对应的cookie的名称,值,以及各个属性。
从客户端把cookie发送到服务器
从客户端发送cookie给服务器的时候,是不发送cookie的各个属性的,而只是发送对应的名称和值。
关于修改,设置cookie
除了服务器发送给客户端(浏览器)的时候,通过Set-Cookie,创建或更新对应的cookie之外,还可以通过浏览器内置的一些脚本,比如javascript,去设置对应的cookie,对应实现是操作js中的document.cookie。
Cookie的缺陷
- cookie会被附加在每个HTTP请求中,所以无形中增加了流量。
- 由于在HTTP请求中的cookie是明文传递的,所以安全性成问题。(除非用HTTPS)
- Cookie的大小限制在4KB左右。对于复杂的存储需求来说是不够用的。
2.防盗链
HTTP请求防盗链:只允许某些域名请求来源才可以访问。
比如A网站有一张图片或音频等资源被B网站直接通过img等标签属性引入使用,这样就是B网站盗用了A网站的资源。那么对于A
网站来说,流量怎么被消耗的都不知道。
解决思路:
判断http请求头Referer域中的请求来源的值,如果和当前访问的域名(或者被允许的一些域名)不一致的情况下,说明该图片可能被其他服务器盗用。
注意:上句话中括弧中:被允许的一些域名,这个是基于黑白名单而言的,拦截请求,判断请求头的Referer是否包含黑名单的域名,包含则拦截请求,不包含就放行。
参考资料:
https://blog.csdn.net/qq_39806107/article/details/101521031
https://blog.csdn.net/mobile18611667978/article/details/80853473
了解更多:8种网站防盗链手段
三、优化
1.HTTP缓存
http缓存(能够帮助服务器提高并发性能,使很多资源不需要重复请求直接从浏览器中拿缓存数据)
数据库缓存、服务器端缓存(代理服务器缓存、CDN 缓存)、浏览器缓存。
浏览器缓存:
- 强缓存(不用发请求到服务器 ,就拿到缓存文件的请求)
强缓存是 利用http的返回头中的Expires或者Cache-Control两个字段来控制的,用来表示资源的缓存时间。
Expires(绝对时间)Cache-Control(相对时间)两个来解决服务器和浏览器时间补同步的问题 - 协商缓存(发送请求到服务器,判断浏览器本地缓存是否失效,没失效,则服务器不会返回资源信息,继续从缓存加载资源)
若未命中强缓存,则浏览器会将请求发送至服务器。服务器根据http头信息中的Last-Modify或 E-tag 来判断是否命中协商缓存。如果命中,则http返回码为304,浏览器从缓存中加载资源。
Last-Modify 它有个精度问题 到秒
E-tag 没有精度问题 只要文件改变 E-tag值就会改变
过程
浏览器第一次加载资源,服务器返回 200,浏览器从服务器下载资源文件,并缓存资源文件与 response header,以供下次加载时对比使用;
下一次加载资源时,由于强制缓存优先级较高,先比较当前时间与上一次返回 200 时的时间差,如果没有超过 cache-control 设置的 max-age,则没有过期,并命中强缓存,直接从本地读取资源。如果浏览器不支持 HTTP1.1,则使用 expires 头判断是否过期;
如果资源已过期,则表明强制缓存没有被命中,则开始协商缓存,向服务器发送带有 If-None-Match 和 If-Modified-Since 的请求;
服务器收到请求后,优先根据 Etag 的值判断被请求的文件有没有做修改,Etag 值一致则没有修改,命中协商缓存,返回 304;如果不一致则有改动,直接返回新的资源文件带上新的 Etag 值并返回 200;
如果服务器收到的请求没有 Etag 值,则将 If-Modified-Since 和被请求文件的最后修改时间做比对,一致则命中协商缓存,返回 304;不一致则返回新的 last-modified 和文件并返回 200
问:浏览器强缓存,协商缓存
(1)强缓存
使用强缓存策略时,如果缓存资源有效,则直接使用缓存资源,不必再向服务器发起请求。
强缓存策略可以通过两种方式来设置,分别是 http 头信息中的 Expires 属性和 Cache-Control 属性。
(2)协商缓存
如果命中强制缓存,我们无需发起新的请求,直接使用缓存内容,如果没有命中强制缓存,如果设置了协商缓存,这个时候协商缓存就会发挥作用了。
命中协商缓存的条件有两个:
max-age=xxx 过期了
值为no-store
使用协商缓存策略时,会先向服务器发送一个请求,如果资源没有发生修改,则返回一个 304 状态,让浏览器使用本地的缓存副本。如果资源发生了修改,则返回修改后的资源
2.HTTP内容压缩
为了提高网页在网络上的传输速度,服务器对主体信息进行压缩
如常见的gzip,deflate压缩,compress压缩以及google chrome的sdch压缩。
因此,响应头中的content-length的值和我们下载下来的内容字节不一样,会相对较小。
客户端在接收到内容后进行解压,再进行渲染。
服务器如何知道我们浏览器压缩方式
客户端允许发送一个Accept-Encoding头信息,与服务器协商
3.分块传输/持久链接/反向ajax
反向 ajax 又叫 comet server push 服务器推技术
原理: 一般而言,HTTP 协议的特点是,连接之后断开连接(服务器响应 Content-Length,收到了指定 Length 长度的内容时,也就断开了)。在 HTTP 1.1 协议中,允许不写 Content-Length,比如要发送的内容长度确实不知道,此时需要一个特殊的 Content-Type:chunked,叫做分块传输,只有当服务器最后发送 0 ,在表明服务器和客户端的此次连接彻底结束。















 4635
4635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









