









最简单的线性回归例子:
Paddle实现最简单的线性回归的例子如下:
# 乘坐出租车的时候,会有一个10元的起步价,只要上车就需要收取。出租车每行驶1公里,需要再支付每公里2元的行驶费用。
# 当一个乘客坐完出租车之后,车上的计价器需要算出来该乘客需要支付的乘车费用。
def calculate_fee(distance_travelled):
return 10 + 2 * distance_travelled
for x in [1.0, 3.0, 5.0, 9.0, 10.0, 20.0]:
pass
# print(calculate_fee(x))
# 现在知道乘客每次乘坐出租车的公里数,也知道乘客每次下车的时候支付给出租车司机的总费用。
# 但是并不知道乘车的起步价,以及每公里行驶费用是多少。
# total_fee = w * distance_travelled + b
# 在机器学习任务中,像distance_travelled这样的输入值,一般被称为x(或者特征feature),
# 像total_fee这样的输出值,一般被称为y(或者标签label)。
import paddle
print("paddle " + paddle.__version__)
# paddle.to_tensor把示例数据转换为paddle的Tensor数据
x_data = paddle.to_tensor([[1.], [3.0], [5.0], [9.0], [10.0], [20.0]])
y_data = paddle.to_tensor([[12.], [16.0], [20.0], [28.0], [30.0], [50.0]])
print("x_data : {}".format(x_data))
print("y_data: {}".format(y_data))
# 用飞桨定义模型的计算
# 从数据当中学习公式当中的w和b。这样在未来,给定x时就可以估算出来y值(估算出来的y记为y_predict)y_predict = w * x + b
# 用飞桨的线性变换层:paddle.nn.Linear来实现这个计算过程,这个公式里的变量x, y, w, b, y_predict4
# 根据经验,已经事先知道了distance_travelled和total_fee之间是线性的关系
linear = paddle.nn.Linear(in_features=1, out_features=1)
# 机器(计算机)在一开始的时候会随便猜w和b,可以看到,这时候的w是一个随机值,b是0.0,这是飞桨的初始化策略,也是这个领域常用的初始化策略。
w_before_opt = linear.weight.numpy().item()
b_before_opt = linear.bias.numpy().item()
print("w before optimize: {}".format(w_before_opt))
print("b before optimize: {}".format(b_before_opt))
# 告诉飞桨怎么样学习
# 得到的y_predict,跟实际的y值一定是有差距的。机器会根据这个差距来调整w和b,随着逐步调整,w和b会越来越正确,y_predict跟y之间的差距也会越来越小,从而最终能得到好用的w和b。这个过程就是机器学习的过程。
# 衡量差距的函数(一个公式)就是损失函数,用来调整参数的方法就是优化算法
# 用最简单的均方误差(mean square error)作为损失函数(paddle.nn.MSELoss);
# 和最常见的优化算法SGD(stocastic gradient descent)作为优化算法
# (传给paddle.optimizer.SGD的参数learning_rate,可以理解为控制每次调整的步子大小的参数)。
mse_loss = paddle.nn.MSELoss()
sgd_optimizer = paddle.optimizer.SGD(learning_rate=0.001, parameters = linear.parameters())
# 运行优化算法
# 衡量y和y_predict的差距的loss)在不断的降低
total_epoch = 5000
for i in range(total_epoch):
y_predict = linear(x_data)
loss = mse_loss(y_predict, y_data)
loss.backward()
sgd_optimizer.step()
sgd_optimizer.clear_grad()
if i % 1000 == 0:
print("epoch {} loss {}".format(i, loss.numpy()))
print("finished training, loss {}".format(loss.numpy()))
# 机器学习出来的参数
# 经过了这样的对参数w和b的调整(学习),再通过下面的程序,来看看现在的参数变成了多少
w_after_opt = linear.weight.numpy().item()
b_after_opt = linear.bias.numpy().item()
print("w after optimize: {}".format(w_after_opt))
print("b after optimize: {}".format(b_after_opt))
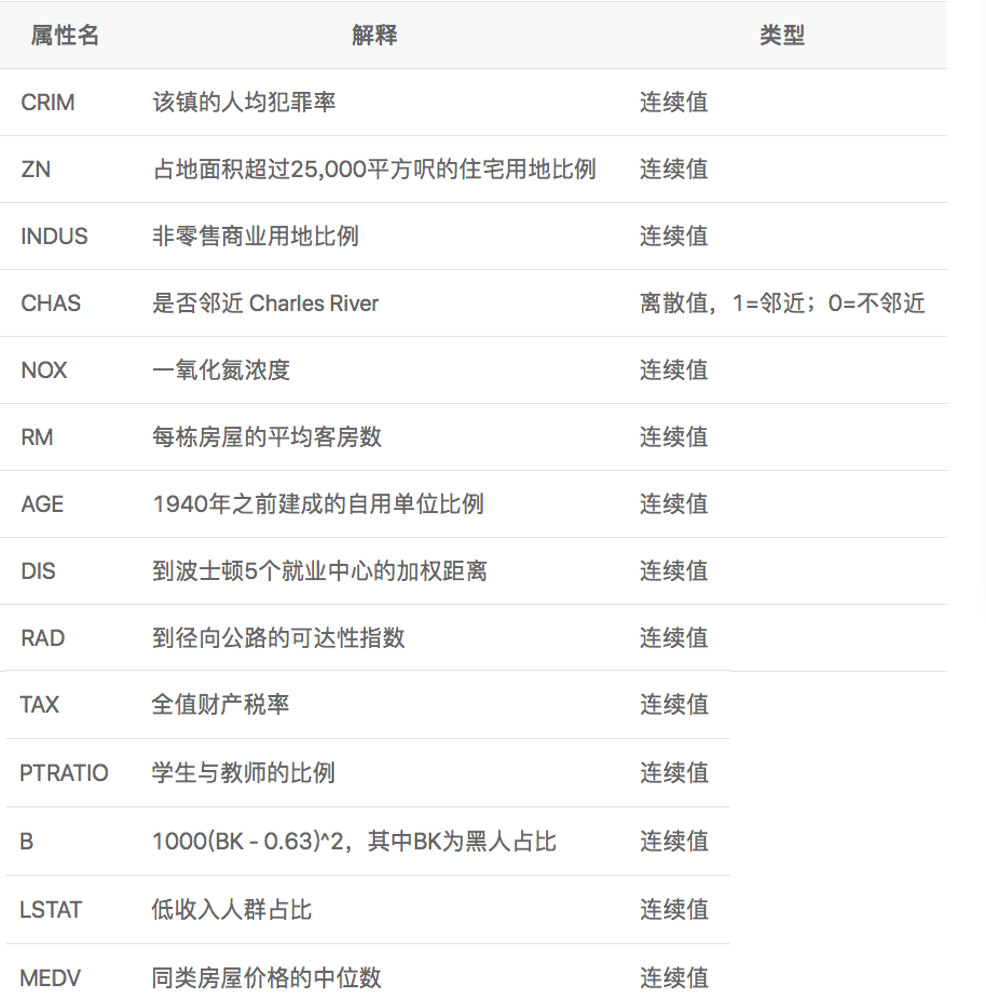
波士顿房价预测(线性回归):
下面是使用paddle实现波士顿房价预测(使用线性回归模型)的实现例子:
其中数据集(housing.data):
# paddle/fluid:飞桨的主库,目前大部分的实用函数均在paddle.fluid包内。
import paddle.fluid as fluid
# dygraph:动态图的类库
import paddle.fluid.dygraph as dygraph
# Linear:神经网络的全连接层函数,即包含所有输入权重相加和激活函数的基本神经元结构。在房价预测任务中,使用只有一层的神经网络(全连接层)来实现线性回归模型。
from paddle.fluid.dygraph import Linear
import numpy as np
def load_data():
# 从文件导入数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算train数据集的最大值,最小值,平均值
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 记录数据的归一化参数,在预测时对数据做归一化
global max_values
global min_values
global avg_values
max_values = maximums
min_values = minimums
avg_values = avgs
# 对数据进行归一化处理
for i in range(feature_num):
# print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
# ratio = 0.8
# offset = int(data.shape[0] * ratio)
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
class Regressor(fluid.dygraph.Layer):
# 定义init函数:在类的初始化函数中声明每一层网络的实现函数。在房价预测模型中,只需要定义一层全连接层FC。
# name_scope变量用于调试模型时追踪多个模型的变量,在此忽略即可,飞桨1.7及之后版本不强制用户设置name_scope。
def __init__(self, name_scope):
super().__init__(name_scope)
name_scope = self.full_name()
# 定义一层全连接层,输出维度是1,激活函数为None,即不使用激活函数
self.fc = Linear(input_dim=13, output_dim=1, act=None) # act=None不使用任何激活函数
# 网络的前向计算函数
# 定义forward函数:构建神经网络结构,实现前向计算过程,并返回预测结果,在本任务中返回的是房价预测结果。
def forward(self, inputs):
x = self.fc(inputs)
return x
# 定义飞桨动态图的工作环境
with fluid.dygraph.guard():
# 声明定义好的线性回归模型
model = Regressor("Regressor")
# 开启模型训练模式
model.train()
# 加载数据
training_data, test_data = load_data()
# 定义优化算法,这里使用随机梯度下降-SGD
# 学习率设置为0.01
opt = fluid.optimizer.SGD(learning_rate=0.01, parameter_list=model.parameters())
with dygraph.guard(fluid.CUDAPlace(0)): # fluid.CPUPlace使用CPU计算
EPOCH_NUM = 10 # 设置外层循环次数
BATCH_SIZE = 10 # 设置batch大小
# 定义外层循环,外层循环: 定义遍历数据集的次数,通过参数EPOCH_NUM设置。
for epoch_id in range(EPOCH_NUM):
# 在每轮迭代开始之前,将训练数据的顺序随机的打乱
np.random.shuffle(training_data)
# 将训练数据进行拆分,每个batch包含10条数据
mini_batches = [training_data[k:k + BATCH_SIZE] for k in range(0, len(training_data), BATCH_SIZE)]
# 定义内层循环,内层循环: 负责整个数据集的一次遍历,采用分批次方式(batch)。一般设置为2^n或10^n
# 假设数据集样本数量为1000,一个批次有10个样本,则遍历一次数据集的批次数量是1000/10=100,即内层循环需要执行100次。
# batch的取值会影响模型训练效果。batch过大,会增大内存消耗和计算时间,且效果并不会明显提升;batch过小,每个batch的样本数据将没有统计意义。由于房价预测模型的训练数据集较小,我们将batch为设置10。
for iter_id, mini_batch in enumerate(mini_batches):
x = np.array(mini_batch[:, :-1]).astype('float32') # 获得当前批次训练数据
y = np.array(mini_batch[:, -1:]).astype('float32') # 获得当前批次训练标签(真实房价)
# 将numpy数据转为飞桨动态图variable形式
house_features = dygraph.to_variable(x)
prices = dygraph.to_variable(y)
# 前向计算
predicts = model(house_features)
# 计算损失
loss = fluid.layers.square_error_cost(predicts, label=prices)
avg_loss = fluid.layers.mean(loss)
if iter_id % 20 == 0:
print("epoch: {}, iter: {}, loss is: {}".format(epoch_id, iter_id, avg_loss.numpy()))
# 反向传播
avg_loss.backward()
# 最小化loss,更新参数
opt.minimize(avg_loss)
# 清除梯度
model.clear_gradients()
# 保存模型
fluid.save_dygraph(model.state_dict(), 'LR_model')
# 定义飞桨动态图工作环境,将模型当前的参数数据model.state_dict()保存到文件中(通过参数指定保存的文件名 LR_model),以备预测或校验的程序调用
with fluid.dygraph.guard():
# 保存模型参数,文件名为LR_model
fluid.save_dygraph(model.state_dict(), 'LR_model')
print("模型保存成功,模型参数保存在LR_model中")
def load_one_example(data_dir):
f = open(data_dir, 'r')
datas = f.readlines()
# 选择倒数第10条数据用于测试
tmp = datas[-15]
tmp = tmp.strip().split()
one_data = [float(v) for v in tmp]
# 对数据进行归一化处理
for i in range(len(one_data)-1):
one_data[i] = (one_data[i] - avg_values[i]) / (max_values[i] - min_values[i])
data = np.reshape(np.array(one_data[:-1]), [1, -1]).astype(np.float32)
label = one_data[-1]
return data, label
with dygraph.guard():
# 参数为保存模型参数的文件地址
model_dict, _ = fluid.load_dygraph('LR_model')
model.load_dict(model_dict)
model.eval()
# 参数为数据集的文件地址
test_data, label = load_one_example('./work/housing.data')
# 将数据转为动态图的variable格式
test_data = dygraph.to_variable(test_data)
results = model(test_data)
# 对结果做反归一化处理
results = results * (max_values[-1] - min_values[-1]) + avg_values[-1]
print("Inference result is {}, the corresponding label is {}".format(results.numpy(), label))















 1401
1401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









