







这节课讲述了另一种和概率有关的分类器,老师也改变了讲课方式,直接摆上例子,然我们通过例子将课件上的内容串联起来,减少了纯粹的理论公式推导,不得不说,老师的教学水平属实是高,也让我认识到了自己很多不足之处。
本文参考:
条件概率公式
后面会经常碰到的条件概率公式,老师也是放下狠话,这点背景知识都不知道的话,可以考虑退课了,压力直接就来了。
-
P ( A ∣ B ) = P ( B ∣ A ) ∗ P ( A ) / P ( B ) P(A | B)= P(B | A)*P(A) / P(B) P(A∣B)=P(B∣A)∗P(A)/P(B)
这就是常规贝叶斯公式,在后面计算题的时候第一步经常用到,能够将因果互换 -
P ( A , B ∣ C ) = P ( A ∣ B , C ) ∗ P ( B ∣ C ) P(A,B|C)=P(A|B,C)*P(B|C) P(A,B∣C)=P(A∣B,C)∗P(B∣C),类似地
P ( A , B , C ∣ D ) = P ( A ∣ B , C , D ) ∗ P ( B , C ∣ D ) P(A,B,C|D)=P(A|B,C,D)*P(B,C|D) P(A,B,C∣D)=P(A∣B,C,D)∗P(B,C∣D)
这个公式我之前倒没怎么用到过,但是在后面计算的时候,常常会将某些变量移到|后面去,让|前面只留下相互独立的变量,这样子就可以用下面的乘法公式拆开来 -
在变量相互独立的情况下,乘法公式 P ( A , B , C ) = P ( A ) ∗ P ( B ) ∗ P ( C ) P(A,B,C)=P(A)*P(B)*P(C ) P(A,B,C)=P(A)∗P(B)∗P(C)
-
在变量相互独立的情况下,乘法公式 P ( A , B ∣ C ) = P ( A ∣ C ) ∗ P ( B ∣ C ) P(A,B|C)=P(A|C)*P(B|C) P(A,B∣C)=P(A∣C)∗P(B∣C)
朴素贝叶斯分类器
老师通过一个例子引出朴素贝叶斯分类的计算方法,

例子中,我们要判断某个人在30+, undergraduate, lawyer的情况下是否有loan default 的情况,用y=1来表示有loan default,否则y=-1。因此需要对称地计算两个概率,分别为
P
r
[
y
=
1
∣
30
+
,
u
n
d
e
r
g
r
a
d
u
a
t
e
,
l
a
w
y
e
r
]
Pr[y=1|30+,undergraduate,lawyer]
Pr[y=1∣30+,undergraduate,lawyer]以及
P
r
[
y
=
−
1
∣
30
+
,
u
n
d
e
r
g
r
a
d
u
a
t
e
,
l
a
w
y
e
r
]
Pr[y=-1|30+,undergraduate,lawyer]
Pr[y=−1∣30+,undergraduate,lawyer],结果为算出来Pr较大的那种情况。
因为是对称的,因此把目光聚焦在 P r [ y = 1 ∣ 30 + , u n d e r g r a d u a t e , l a w y e r ] Pr[y=1|30+,undergraduate,lawyer] Pr[y=1∣30+,undergraduate,lawyer]上,通过贝叶斯公式化简,最后在计算 P r [ 30 + , u n d e r g r a d u a t e , l a w y e r | y = 1 ] Pr[30+,undergraduate,lawyer|y=1] Pr[30+,undergraduate,lawyer|y=1]的时候,因为训练集S中没有同时满足特征空间age上30+、特征空间education上undergraduate、特征空间occupation上lawyer、y=1的情况,很容易统计到0,因此用个很小的数字 γ \gamma γ(0.00001/3)表示。但这显然是不利于构建分类器的,最后算出来的概率都是0.
因此朴素贝叶斯作出的假设就是,假设所有特征之间相互独立,英文为conditional independence assumption,放在公式上就是 P r [ 30 + , u n d e r g r a d u a t e , l a w y e r | y = 1 ] = P r [ 30 + | y = 1 ] ∗ P r [ u n d e r g r a d u a t e | y = 1 ] ∗ P r [ l a w e r | y = 1 ] Pr[30+,undergraduate,lawyer|y=1]=Pr[30+|y=1]*Pr[undergraduate|y=1]*Pr[lawer|y=1] Pr[30+,undergraduate,lawyer|y=1]=Pr[30+|y=1]∗Pr[undergraduate|y=1]∗Pr[lawer|y=1]。这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。但是它的好处是算法逻辑简单,易于实现,在属性相关性较小时,朴素贝叶斯性能最为良好;同时扫描的空间较小,比如 P r [ 30 + , u n d e r g r a d u a t e , l a w y e r | y = 1 ] Pr[30+,undergraduate,lawyer|y=1] Pr[30+,undergraduate,lawyer|y=1]需要统计age、education、occupation三个特征的联合概率分布个数为{20+,30+,40+,50+} * {high school、undergrad、master} * {self-employed、lawyer、prgrammer}=36,到后面特征较大,特征空间较大的时候几乎是没法做的。
不同假设下的贝叶斯分类
上面提出朴素贝叶斯分类器其实就是做出了一步强假设,假设所有特征之间相互独立,教授为了进一步阐明假设(conditional independence assumption)在贝叶斯分类中的重要意义,又放了一个较弱的假设Assumption:given y and occupation,age and education are mutually independent. 也即age和education是相互独立的,那么我们在列公式
P
r
[
30
+
,
u
n
d
e
r
g
r
a
d
u
a
t
e
,
l
a
w
y
e
r
|
y
=
1
]
Pr[30+,undergraduate,lawyer|y=1]
Pr[30+,undergraduate,lawyer|y=1]的时候,就要尽量把独立的因素放在前面,好让乘法公式将它们分开,用到了前面的条件概率公式:
P
(
A
,
B
∣
C
)
=
P
(
A
∣
B
,
C
)
∗
P
(
B
∣
C
)
P(A,B|C)=P(A|B,C)*P(B|C)
P(A,B∣C)=P(A∣B,C)∗P(B∣C)
P r [ 30 + , u n d e r g r a d u a t e , l a w y e r | y = 1 ] = P r [ 30 + , u n d e r g r a d u a t e | y = 1 , l a w y e r ] ∗ P r [ l a w y e r ∣ y = 1 ] = P r [ 30 + | y = 1 , l a w y e r ] ∗ P r [ u n d e r g r a d u a t e | y = 1 , l a w y e r ] ∗ P r [ l a w y e r ∣ y = 1 ] \begin{aligned} & \quad Pr[30+,undergraduate,lawyer|y=1] \\ & = Pr[30+,undergraduate|y=1,lawyer] * Pr[lawyer| y=1] \\ & = Pr[30+|y=1,lawyer] * Pr[undergraduate|y=1,lawyer] * Pr[lawyer| y=1] \end{aligned} Pr[30+,undergraduate,lawyer|y=1]=Pr[30+,undergraduate|y=1,lawyer]∗Pr[lawyer∣y=1]=Pr[30+|y=1,lawyer]∗Pr[undergraduate|y=1,lawyer]∗Pr[lawyer∣y=1]
贝叶斯分类器候选集
和前面的课程CMSC5724-关于分类问题、决策树问题以及一个关于误差的泛化理论中用Hunt’s Algorithm在候选决策树中找出最佳决策树一样,贝叶斯分类器也同样会用Bayes Method找出最合适的贝叶斯分类器,这里同样存在一个贝叶斯分类器候选集。在候选集存在的前提下,我们也可以用之前的泛化理论Generalization Theorem来约束我们要找的分类器的泛化误差。
相比于当时决策树估算时直接给出了可能有的参数parameter个数,这里的贝叶斯分类器需要我们根据属性预估参数个数,这是个跨越。


简单来说,就是要根据我们已有的特征attribute的特征空间dom大小,算出分类器表示了多少种条件概率。拿到候选集中泛化地讲,就是一个分类器对于不同特征有多少种条件概率的表示形式。如下面的例子中,当给定y和occupation,算出相互独立的因素education、age的条件概率,y=1时occupation不同有3种,age和education相互独立不同有7种,再算上y=-1,也就是7*(3+3)=42种表达形式,也就是42个parameter,如果每个parameter用一个浮点数8bytes表示,最终的候选集总数就是2的幂次。
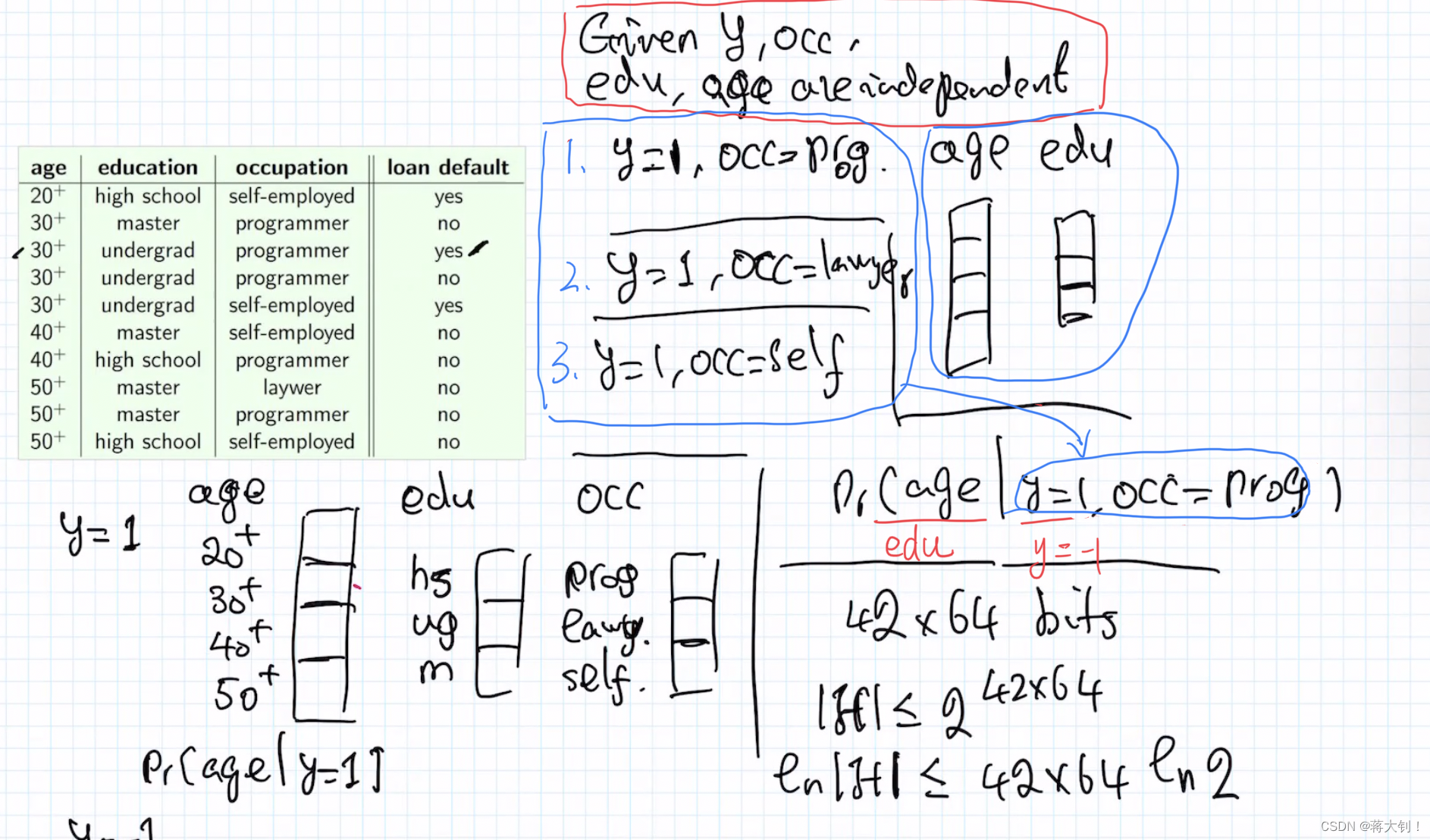
相关题目

解答:

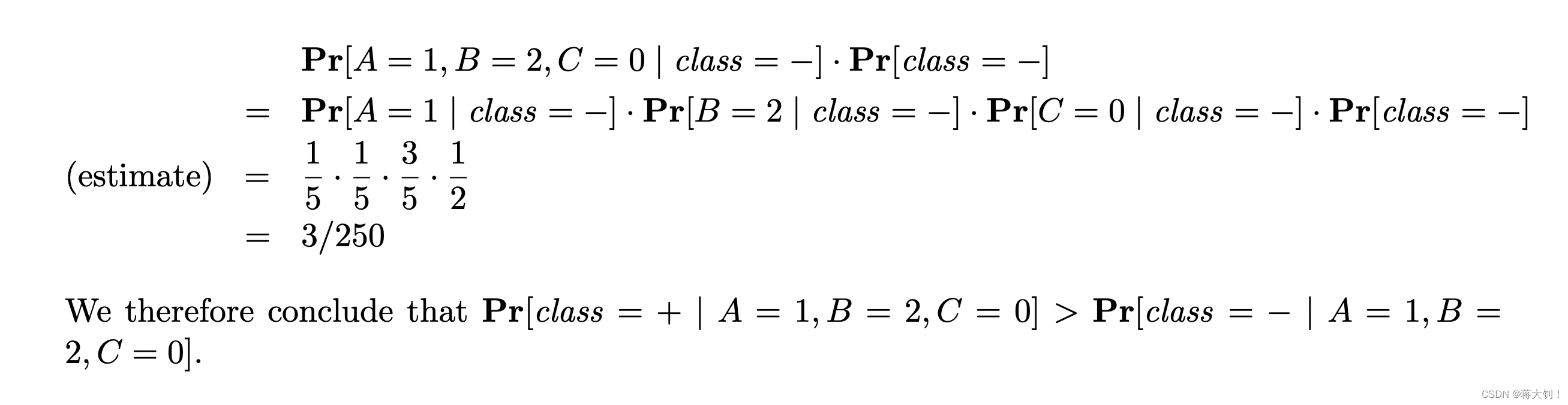


















 4336
4336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











