







文章目录
这章主要讲述了一些我一直没弄懂的分类器评价指标,以及我之前觉得会,但是其实什么都不会的人脸检测知识,虽然这些人工智能的知识在现在看来已经有点落伍了,但总体学下来还是有收获的。
分类器评价指标
老师举的例子非常具有参考意义,总体学下来是能弄清楚概念的:
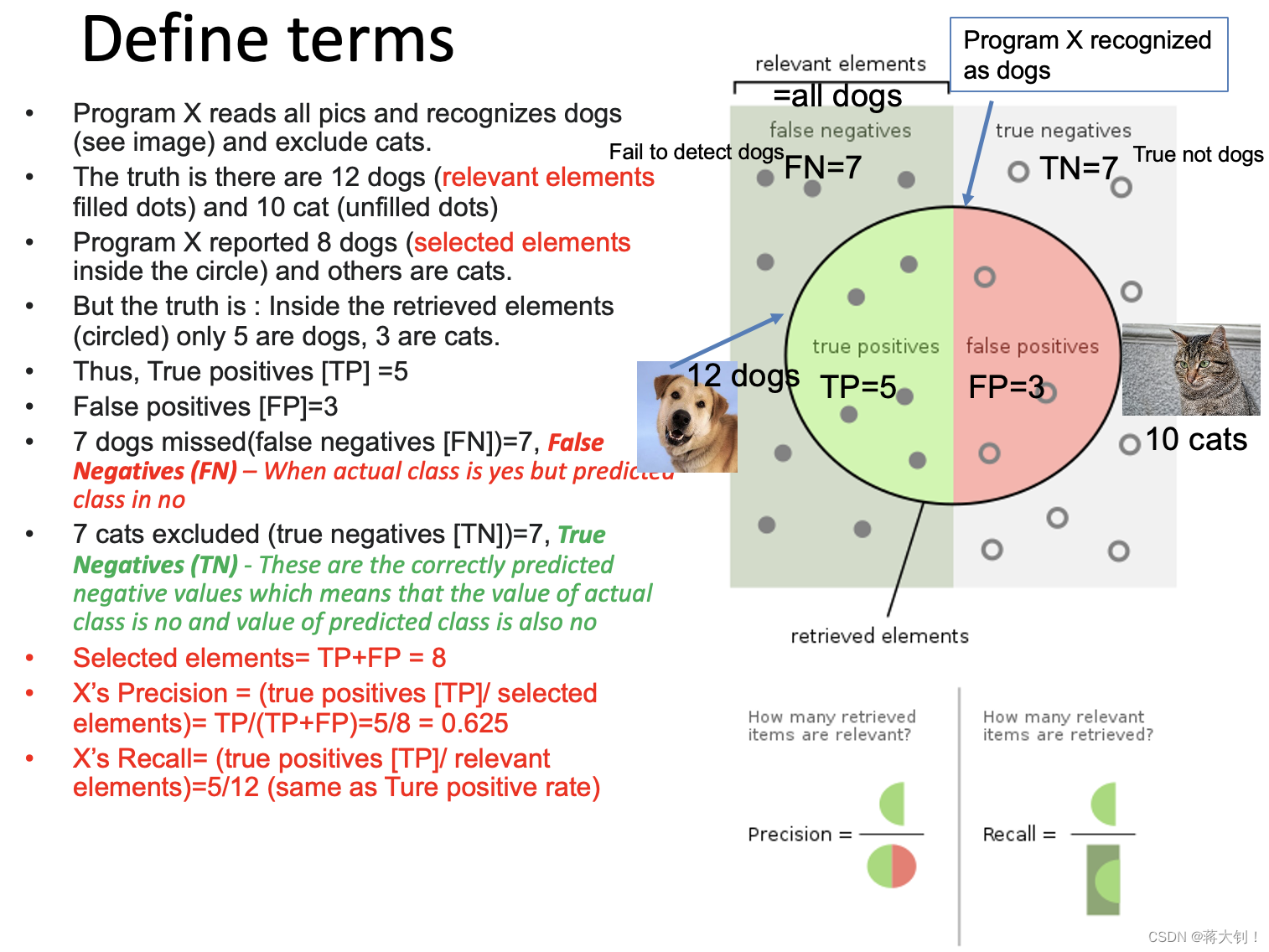

我自己的理解如下:
分类器X目的是检测dog,因此将圆圈中的判断为dog,所以都是positive的,其中左半部分确实是dog,X判断正确了其为true,右半部分显然cat,X判断错误了其为false。至于没被认为dog的部分,都是negative,其中左半部分应该都被认为dog,但是X没把他们囊括进圈子里来,因此是false,右半部分本来就是cat,X没把他们囊括进来,所以是对的true。
因此前半部分是Acutual,用来评价system分类对不对,后半部分是predicted,是system当时的分类结果,两者一结合,可以看出来system是否正确预测出了结果。
上面那个例子中:
TP=5
FP=3
FN=7
TN=7
Accurary=(TP+TN)/(TP+TN+FP+FN) //all True
=(5+7)/(5+3+7+7)=0.545 //被正确分类的dog和cat占全体的比例,也就是分类器做出的和没做出的选择里面有多少对的
Precision=(TP)/(TP+FP) //all Positive
=5/(5+3)=0.625 //分类器做出postive判断的里面,确实为dog的比例,也就是分类器在positive猜测里面有多少对的
Recall= (TP)/(TP+FN) //all should be true
=5/(5+7)=0.4166 //分类器判断正确的dog,占全局的真实dog的比例,也就是分类器在所有找出来或者没找出来的dog里面正确发掘出了多少个dog
F1 score= 2*(0.4166*0.625)/(0.4166+0.625)=0.49995
Intuitive理解:Positive是本次判断任务的判断目标。Precision聚焦于这次动作中判断成positive的样本,看里面究竟多少是TP的;而Recall则是把目光放向整个数据集,TP样本在全局中该类别样本的比例。
人脸识别的评价指标
在接下来的人脸识别技术中,经常出现的两个名词为Detection rate和False Positive rate.
(Correct) Detection rate: Total number of faces that are correctly detected 除以/ total number of faces that actually exit in the picture,should be high >95%,就是上面的Recall.
False positive rate: The detector output is positive, but it is false(there is actually no face), should be low <10^6,这个就是上面的Precision的反面,相当于看错误分类的比例。

The Viola and Jones Method
接下来主要讲的是The Viola and Jones Method里面的一些人脸检测技术,都是最经典的算法, 也需要进行一定量的计算。
Integral image for feature extraction 数字图像特征提取
Integral image
采用Rectangle Filters作为图像的特征提取方式,也就是:
f
=
∑
(
p
i
x
e
l
s
w
h
i
t
e
)
−
∑
(
p
i
x
e
l
s
s
h
a
d
e
d
)
f = \sum(pixels_{white})-\sum(pixels_{shaded})
f=∑(pixelswhite)−∑(pixelsshaded)
当
f
>
t
h
r
e
s
h
o
l
d
f>threshold
f>threshold则认为该区域是脸。

为了能够快速计算出上面两部分的矩形面积,引入了一种类似前缀和的计算公式,其中在坐标(x,y)的integral image的定义为坐标(x,y)左上方围成的像素和。
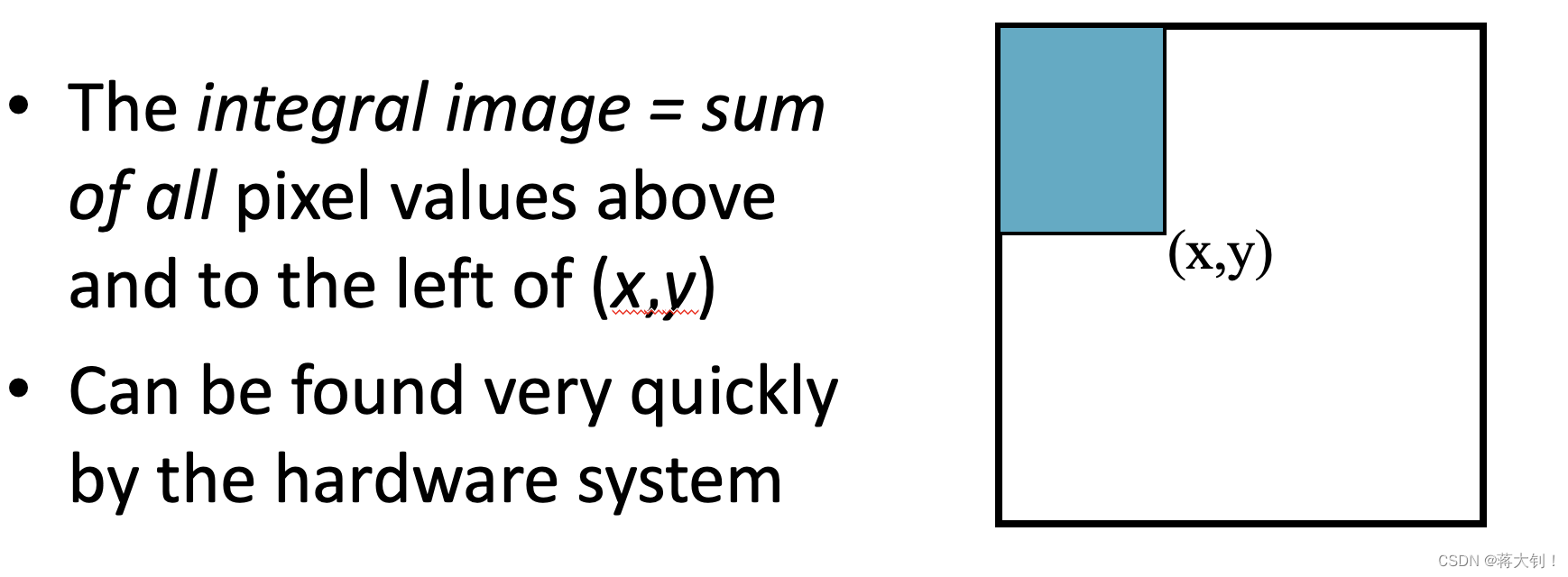
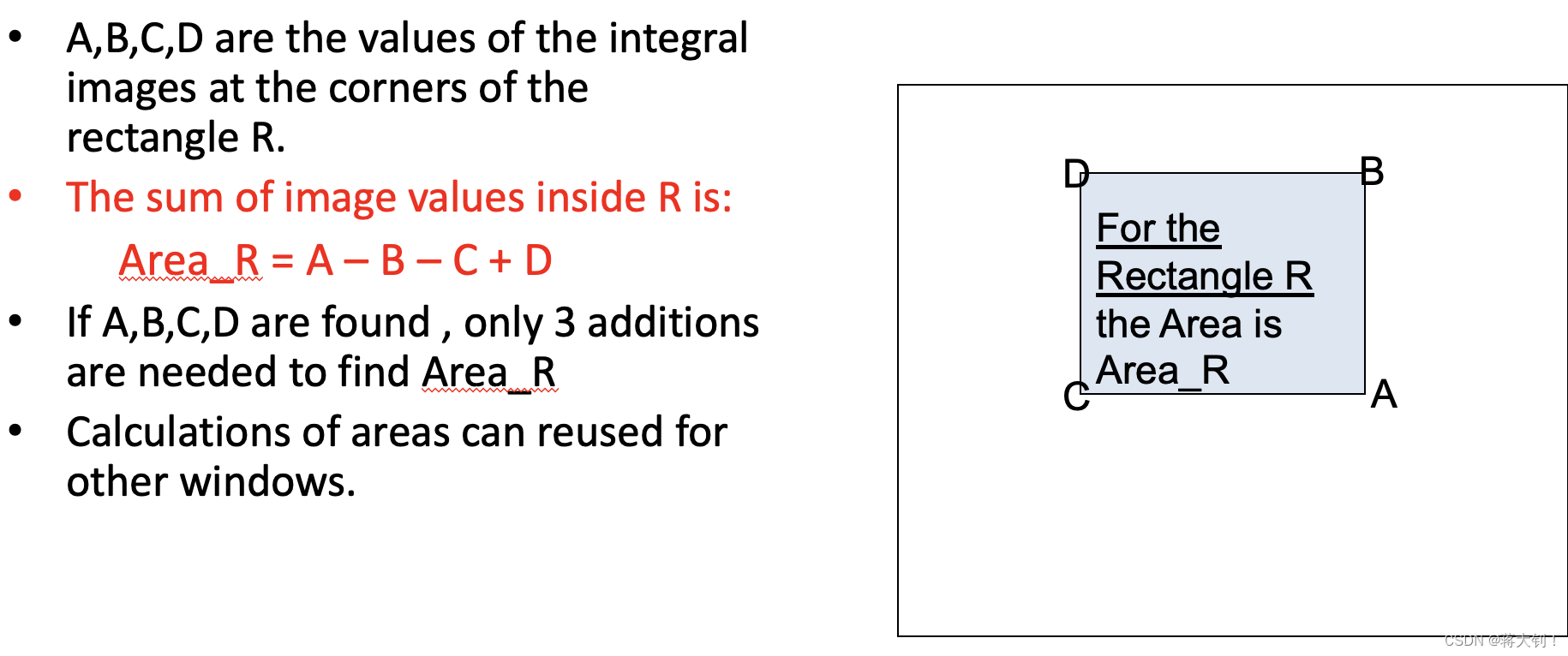
然后就可以重复利用上面预先处理的integral image来计算任意矩形的面积:
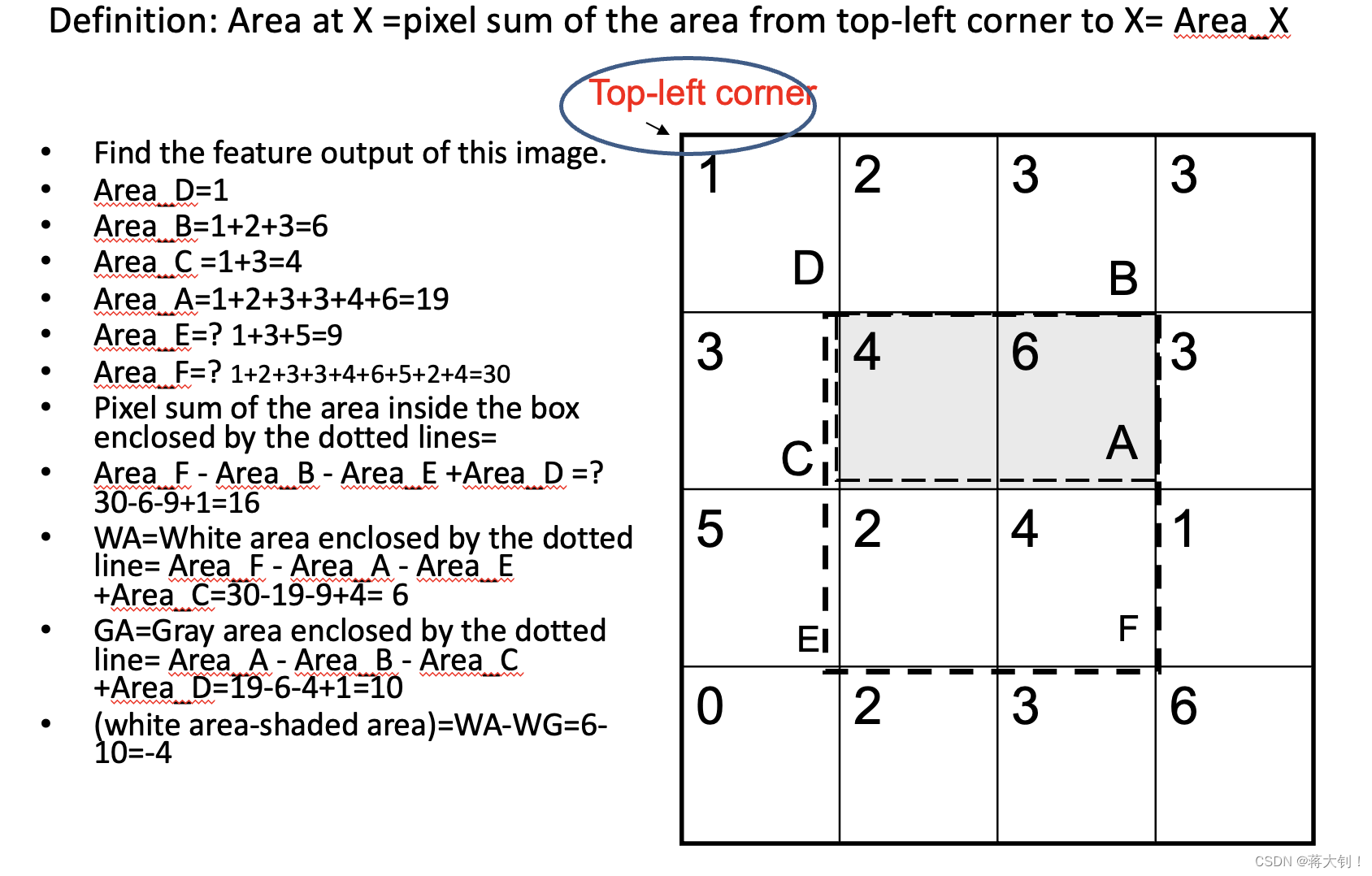
相关题目如下:
Rectangular features
上面讨论的特征是最基本的模式basic rectangular feature(如下面的Type2),左边的5种feature只是一种Basic feature,即它们其实指定了一种模式Pattern,但是每种模式中的方块可能会有不同的大小size,产生各种衍生模式的feature。

在指定大小的一个窗口中,我们怎么计算出所有不同的基本模式能够提取出来的所有特征(不同位置不同区域大小的块)呢?可以简单理解为要计算每种基本模式在该窗口中取不同的size能够得到的衍生模式,再把所有衍生模式能够找到所有特征加起来。
R
e
s
u
l
t
=
∑
i
=
1
i
=
s
i
z
e
(
P
a
t
t
e
r
n
b
a
s
i
c
)
(
P
a
t
t
e
r
n
i
∗
∑
j
=
1
j
=
s
i
z
e
b
l
o
c
k
N
u
m
b
e
r
j
)
Result=\sum_{i=1}^{i=size(Pattern_{basic})} (Pattern_i*\sum_{j=1}^{j=size_{block}}Number_j)
Result=i=1∑i=size(Patternbasic)(Patterni∗j=1∑j=sizeblockNumberj)
N
u
m
b
e
r
j
=
N
u
m
b
e
r
j
w
i
d
t
h
∗
N
u
m
b
e
r
j
h
e
i
g
h
t
Number_j= Number_j^{width}*Number_j^{height}
Numberj=Numberjwidth∗Numberjheight
下面就是三种基本模式(Type1,Type3,Type5)各自算出来的特征数量,整体思路为两层循环,第一层循环的意义是一个方格能够取到的宽度width,循环从1到 w i n d o w W i d t h / ( H o r i z o n t a l 格 子 数 量 ) windowWidth/(Horizontal格子数量) windowWidth/(Horizontal格子数量),第二层循环的意义是一个方格能够取到的高度height,循环从1到 w i n d o w H e i g h t / ( V e r t i c a l 格 子 数 量 ) windowHeight/(Vertical格子数量) windowHeight/(Vertical格子数量),两层循环内部就是在这种Basic feature的指定Size下计算总特征数,最后将所有结果都累加到temp上。
在24*24的窗口中,采用上面5个基本特征,计算其所有的衍生特征,总数量为162336.
下面单纯计算每种基本模式可以产生的特征数量,
Type1:

Type3:

Type5:

一个具体的计算例子如下:

Adaboost for Face Detection
上面是单个窗口,固定基本特征空间,在一个特征的不同Size下进行的计算,已经产生了很多特征,当我们真将它们用作人脸识别检测,如下所示,还需要截取不同位置的所有窗口,每个位置还需要在原来不同大小特征的基础上,考虑缩放zoom factor,这将会产生巨大的特征量。

解决地方法就是Adaboost(前面一章有讲过),先验地挑选出几个最佳的特征(经过很长时间地训练)作为弱分类器,将若干弱分类器组合成为强分类器,这能够有效提升detection rate,但是false positive rate还是过高。

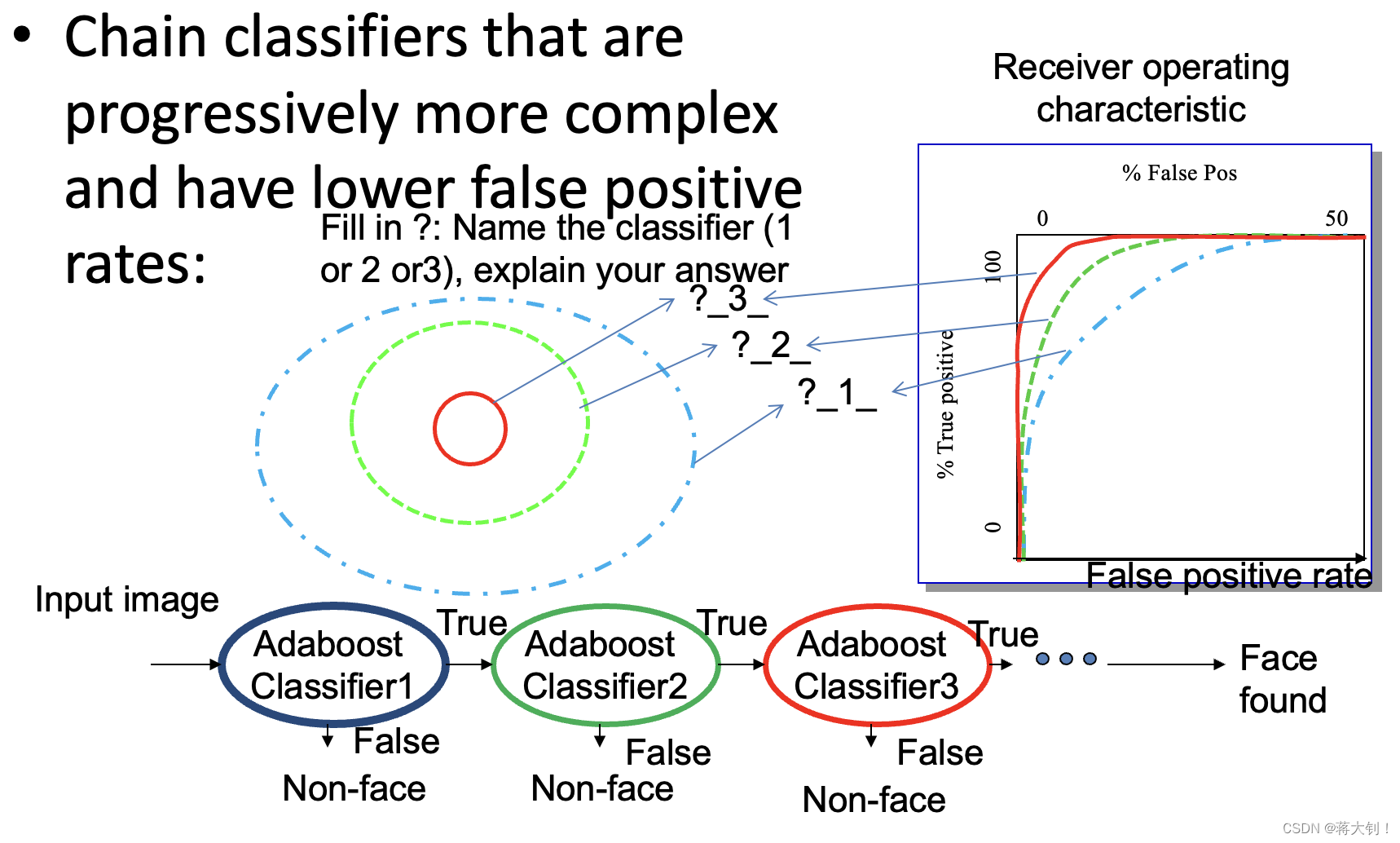
Attentional Cascade
为了改善false positive rate,采用了一种强分类器连结的方式,如下所示。从简单的分类器开始,每次都能够排除一些分类效果不好的特征窗口。
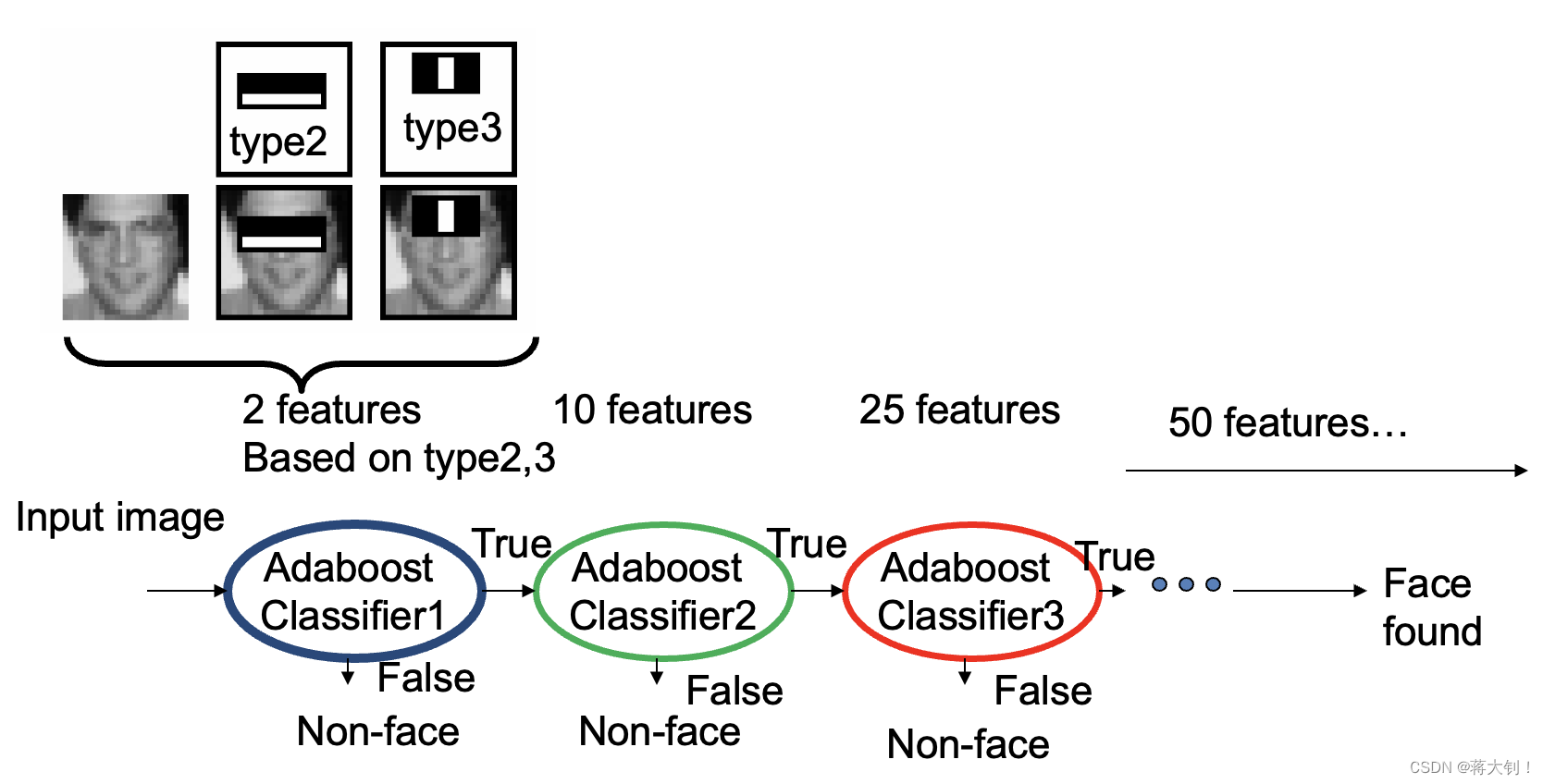
最终分类效果得到了较大的改善:

















 2552
2552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











