







文章目录
这章主要是介绍反向传播的神经网络,其中的过程以及相关计算,虽然有些知识在本科的人工智能课上有了解过,但是感觉当时学习的知识不成体系且没有深入本质,这次上课就感觉整个知识体系建立了起来。
反向传播神经网络
首先可以在心中搭起框架,一个神经网络可以理解为用若干个samples去训练出Weight(W)和Bias(b),从而可以利用这个网络将unknown input分类成不同的类别。其中:
- forward pass是在训练好神经网络后的使用,用它对unknown input进行分类;
- 而如何训练出weight和bias则是运用forward pass和backward pass.

Feed Forward Propagation前向传播
Feed Forward Propagation前向传播多是用于classification和recognition的任务中的,根据输入输出预测结果。
在用前向传播的神经网络进行分类的时候,我们假设其网络结构已经训练出来了,即Weight和Bias都已经知道了。
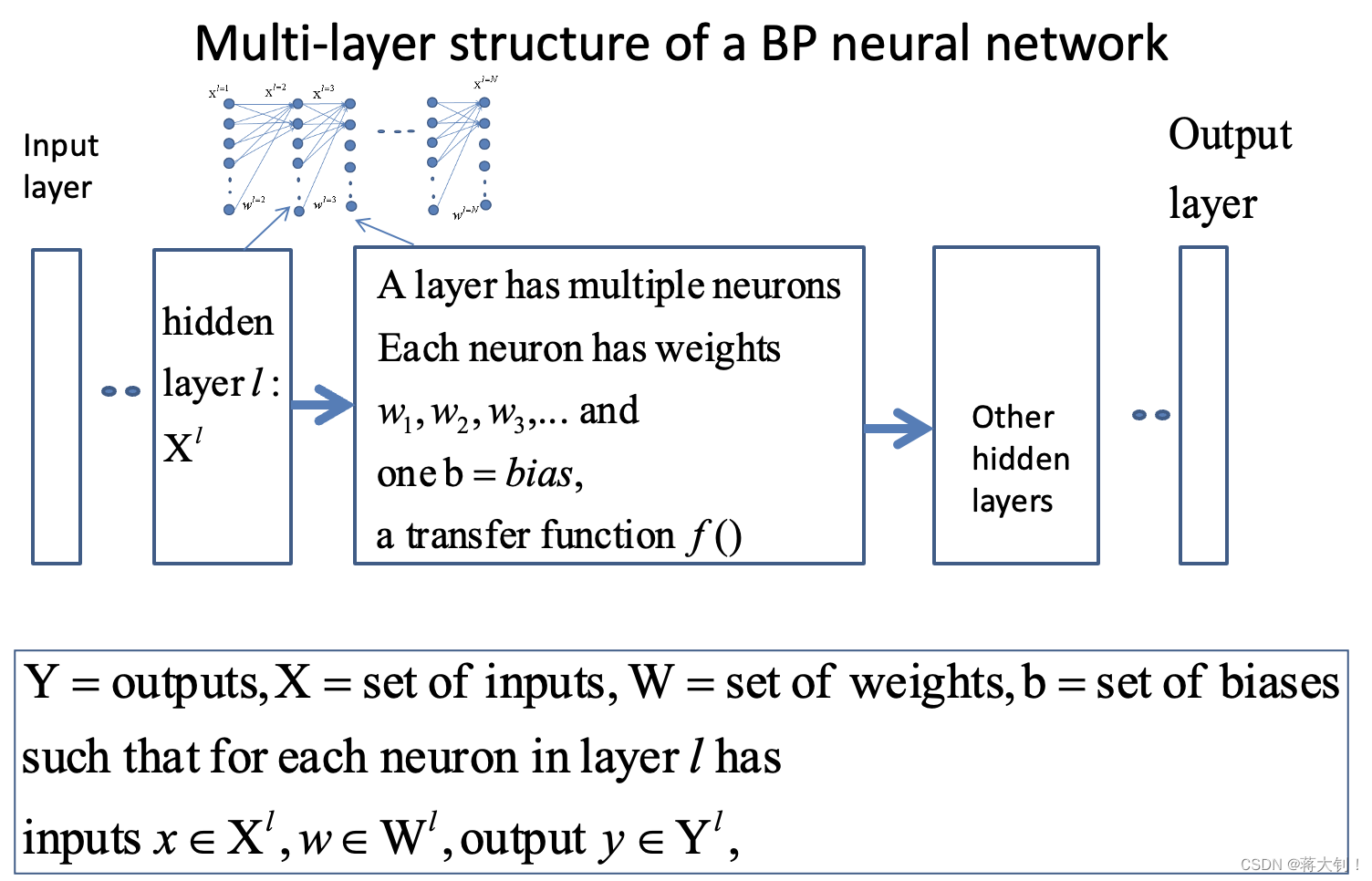
常规的流程我们都清楚,这方面主要就是集中于一些参数Weight和Bias个数的统计
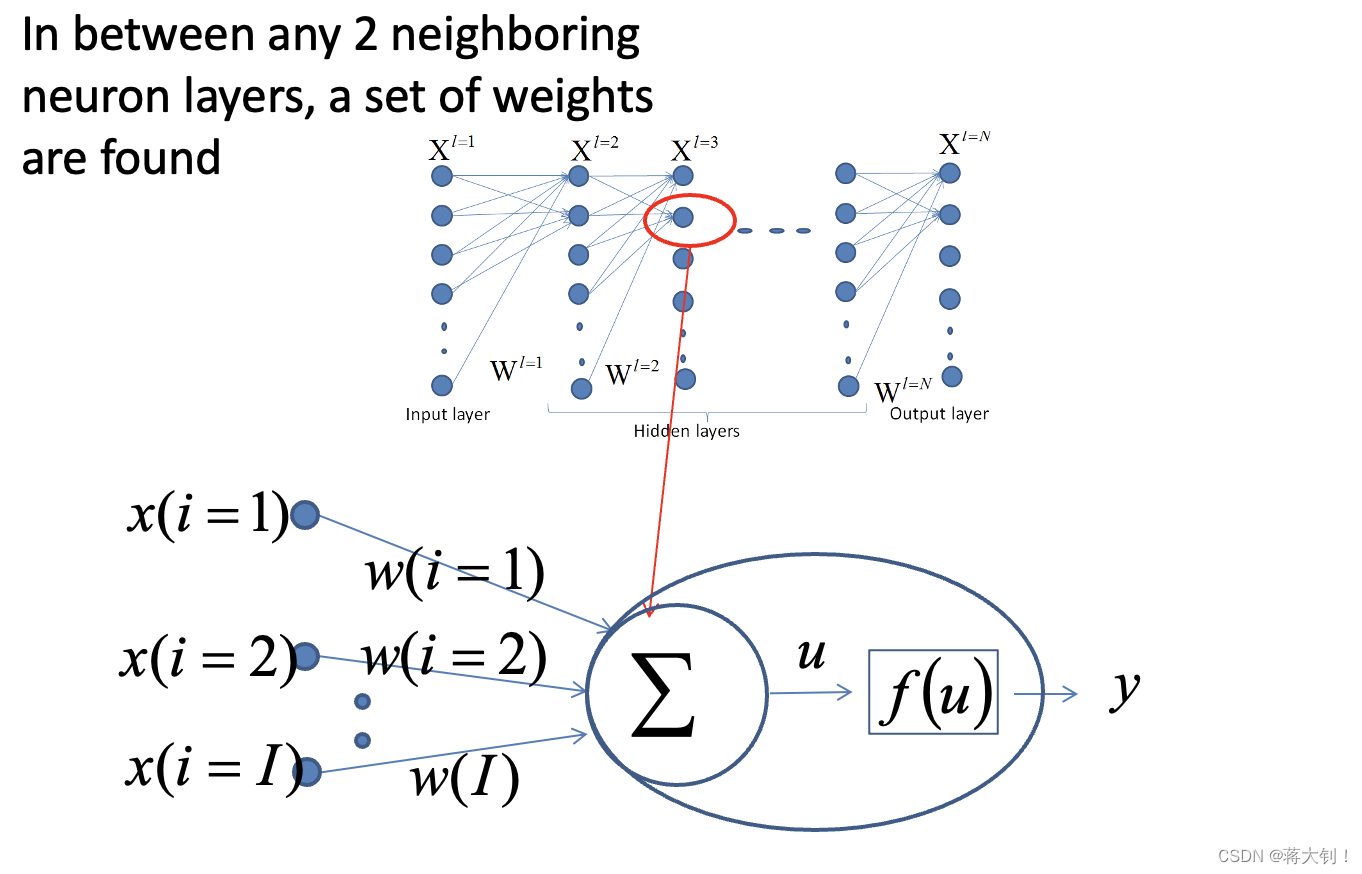
- Weight参数个数为神经网络中所有神经元nuron之间的连接数,如下图为两两层数之间的连接数之和。
- Bias参数个数为神经网络中除了inputs neurons后,剩下所有的神经元个数。
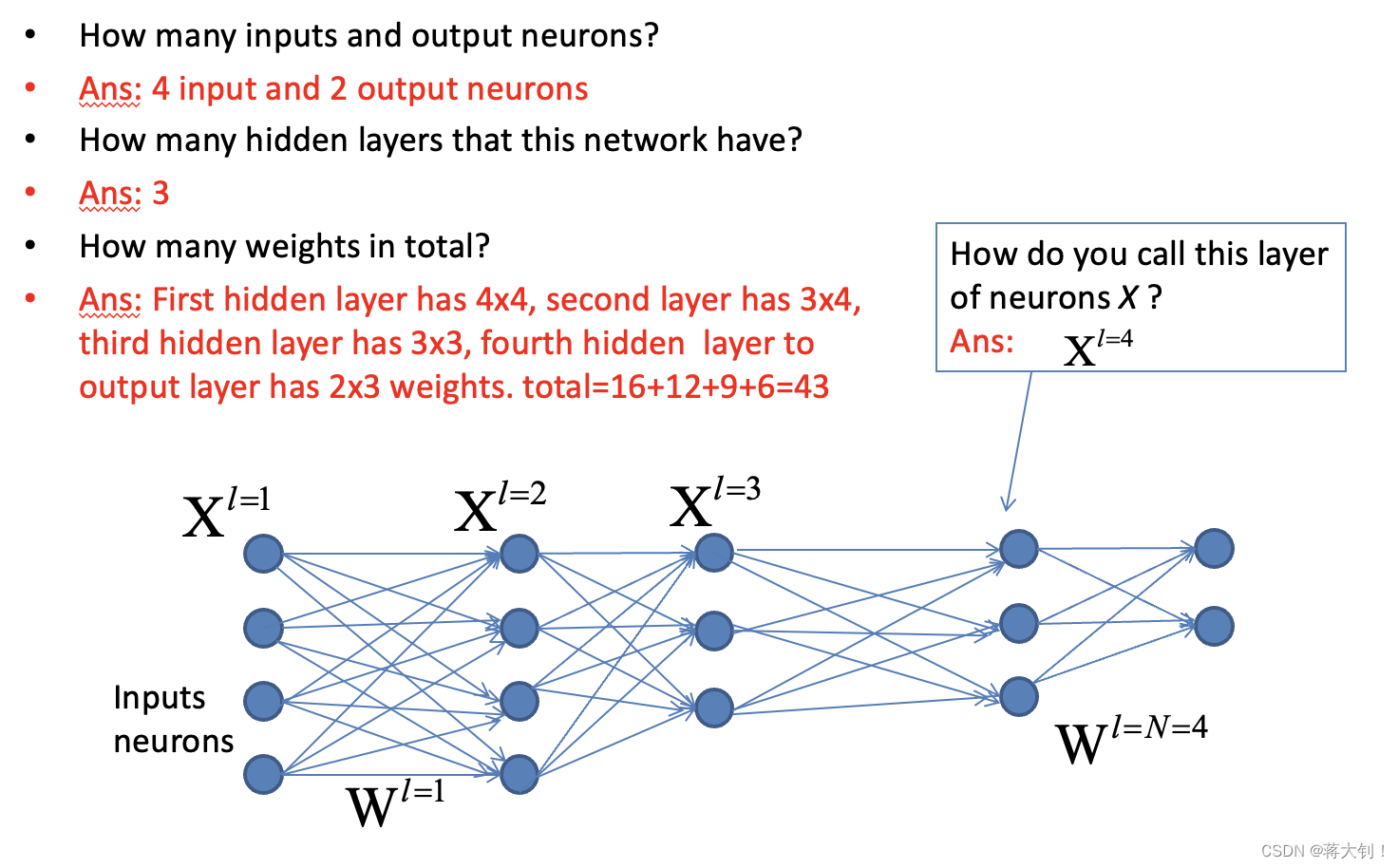
对于其中的神经元(包括Hidden Layers和Output Layer),需要了解其激励函数的原理:
y = f ( u ) y=f(u) y=f(u)
u = ∑ i = 1 i = I [ w ( i ) x ( i ) ] + b , u=\sum\limits_{i=1}^{i=I}[w(i)x(i)]+b, u=i=1∑i=I[w(i)x(i)]+b,
b b b=bias, x x x=input, w w w=weight, u u u=internal signal
Typically f ( ) f() f() is a logistic (Sigmod) function,i.e.
f ( u ) = 1 1 + e x p ( − β u ) f(u)=\frac{1}{1+exp{(-\beta u)}} f(u)=1+exp(−βu)1, assume β = 1 \beta=1 β=1 for simplicity,
therefore f ( u ) = 1 1 + e − ( ∑ i = 1 i = I [ ω ( i ) x ( i ) ] + b ) f(u)=\frac{1}{1+e^{-\left(\sum_{i=1}^{i=I}[\omega(i) x(i)]+\mathrm{b}\right)}} f(u)=1+e−(∑i=1i=I[ω(i)x(i)]+b)1
一个神经元激励计算的例子如下:

Back Propagation
Back propagation主要用于训练神经网络的,它也包括forward processing预测结果的过程,根据预测出来的结果对神经网络进行反向处理backward processing,更新网络权重。
这部分关键在于误差e的计算,以及在两种情况下如何进行权重更新。
Error计算
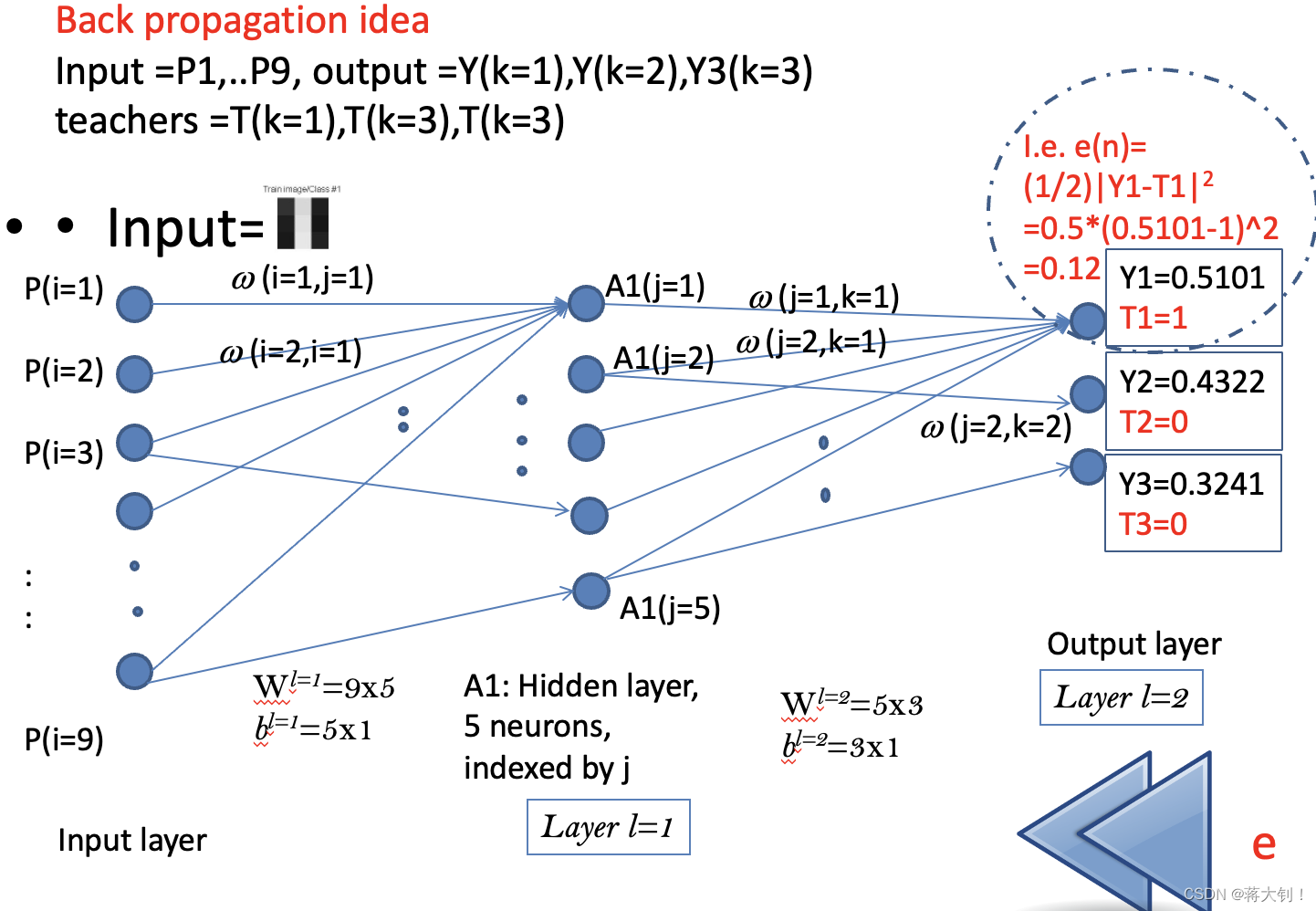
图中e(n)表示的是样本n在类别1上产生的误差,
Y
1
、
Y
2
、
Y
3
Y1、Y2、Y3
Y1、Y2、Y3分别代表在三个类别上neurons的输出(并没有经过softmax层),
T
1
、
T
2
、
T
3
T1、T2、T3
T1、T2、T3代表真实类别标签的三个分量。
权重的更新为
w
n
e
w
=
w
o
l
d
−
η
∗
∂
E
∂
w
w_{new}=w_{old}- \eta*\frac{\partial E}{\partial w}
wnew=wold−η∗∂w∂E,
η
\eta
η为learning rate, 如下图证明所示,这样的更新可以使得系统整体的误差
E
E
E不断减小。

Weight Updating
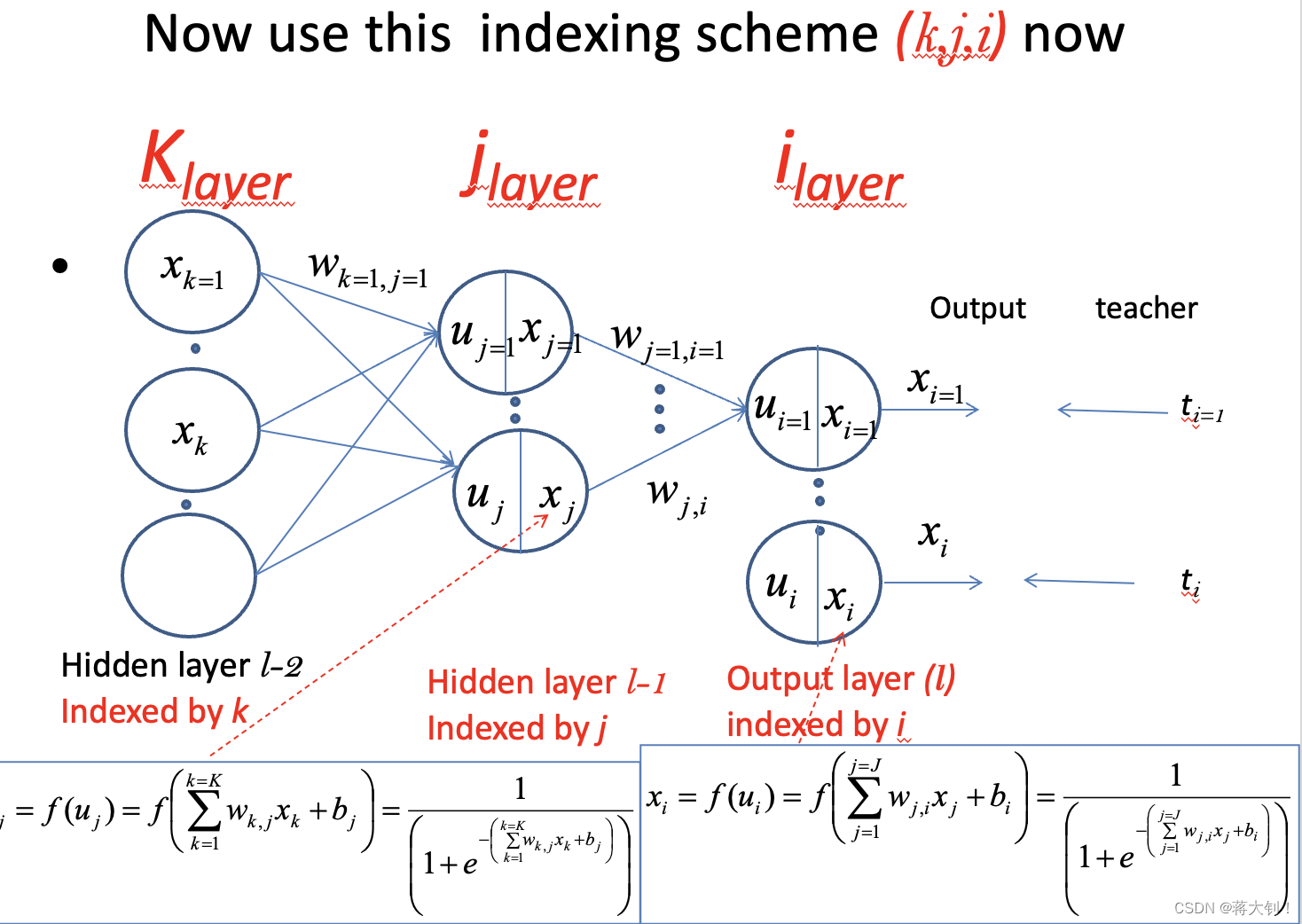
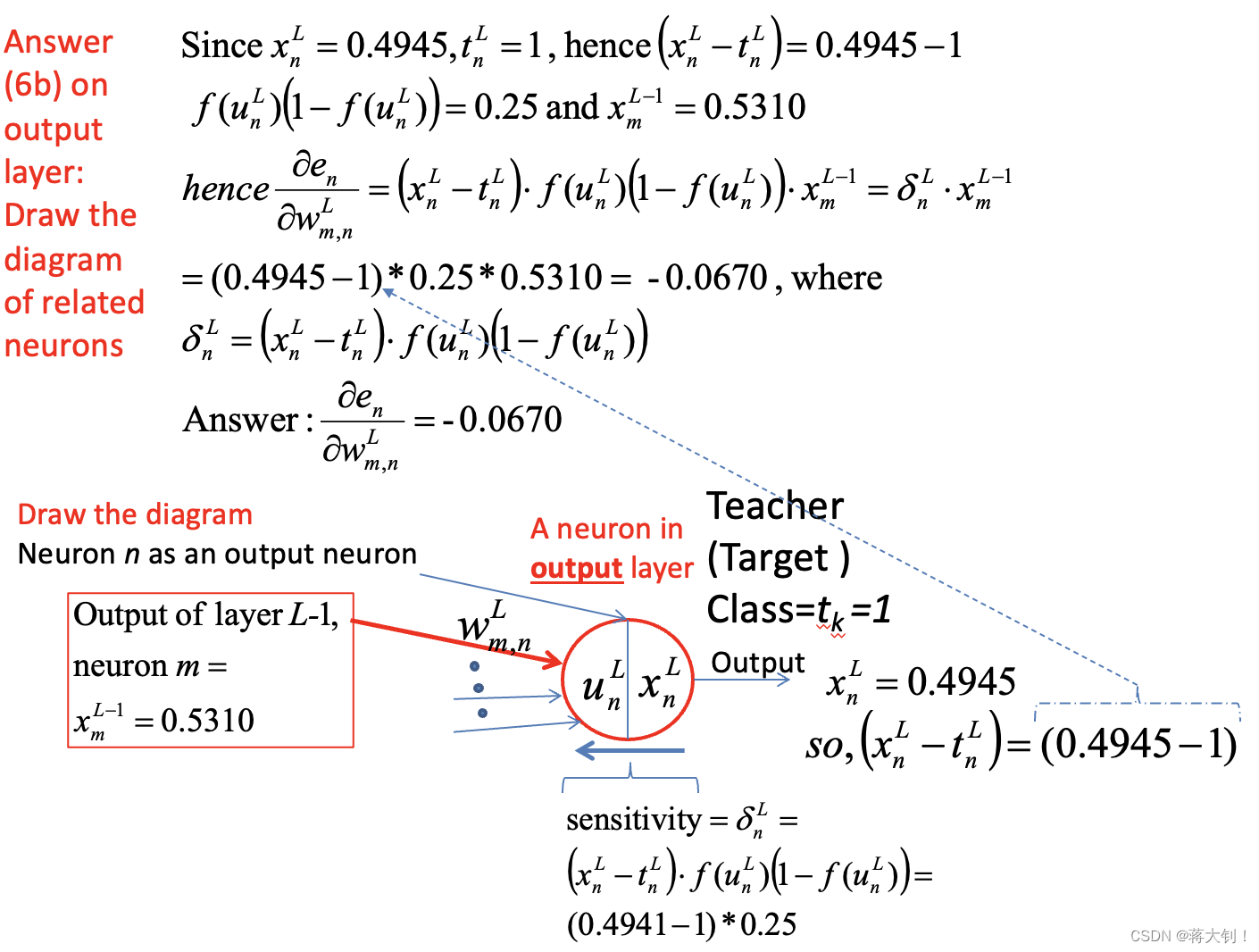
Case1: Between the hidden layer and the output layer
简单地理解来说,就是误差
ε
\varepsilon
ε对预测值
x
i
x_i
xi求偏导,然后预测值
x
i
x_i
xi针对其计算中的e的指数上的和
u
i
u_i
ui求偏导,最后该和
u
i
u_i
ui对
w
j
,
i
w_{j,i}
wj,i求偏导。
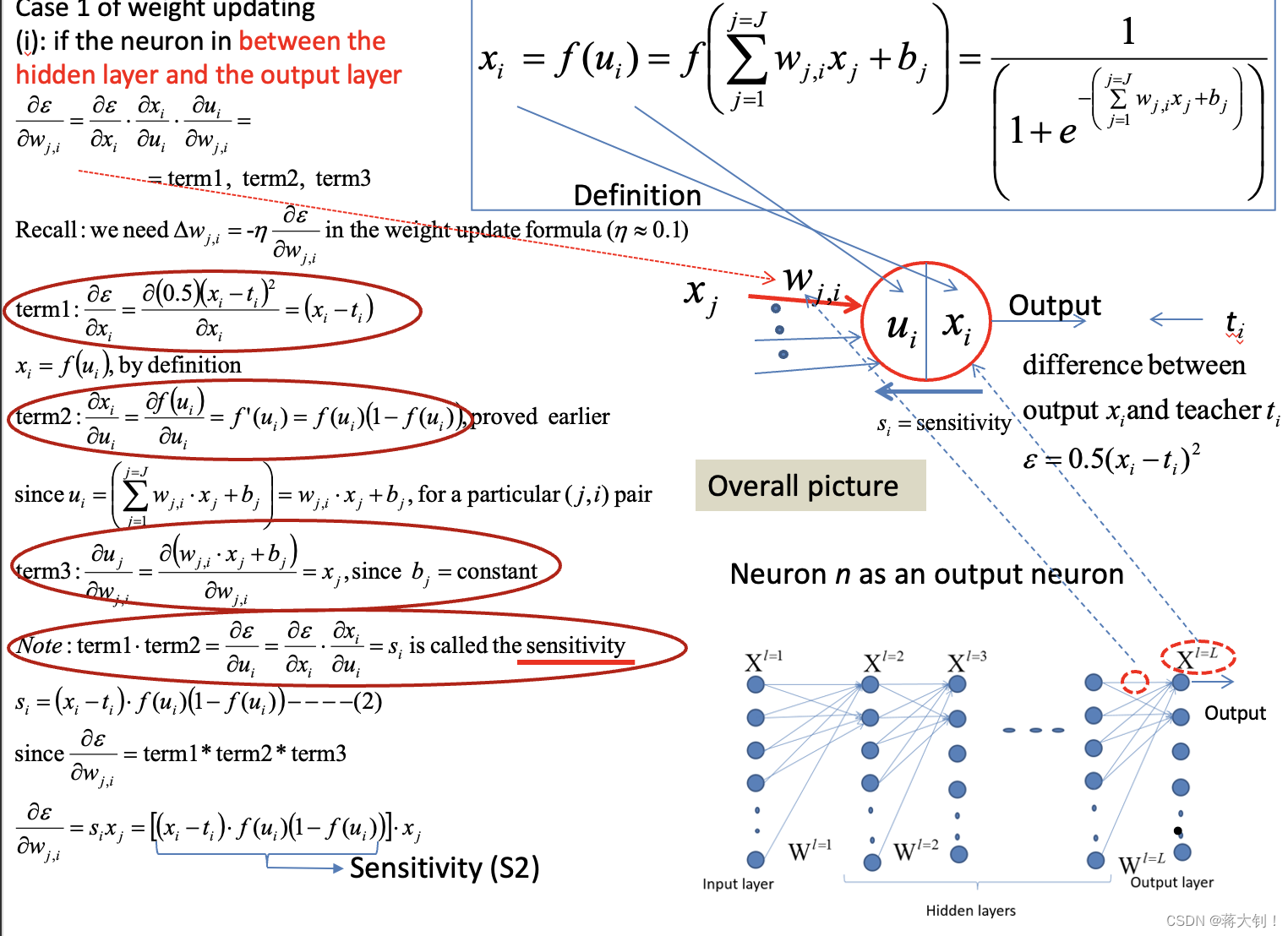
其中的sensitivity表示出来,可以复用在后面链式a hidden layer and a hidden layer之间状态更新的链式求导,链式前面sensitivity都一致,不一致的是后面
u
i
u_i
ui对
w
j
,
i
w_{j,i}
wj,i还是对
x
j
x_j
xj求导。
Case2: Between a hidden layer and a hidden layer
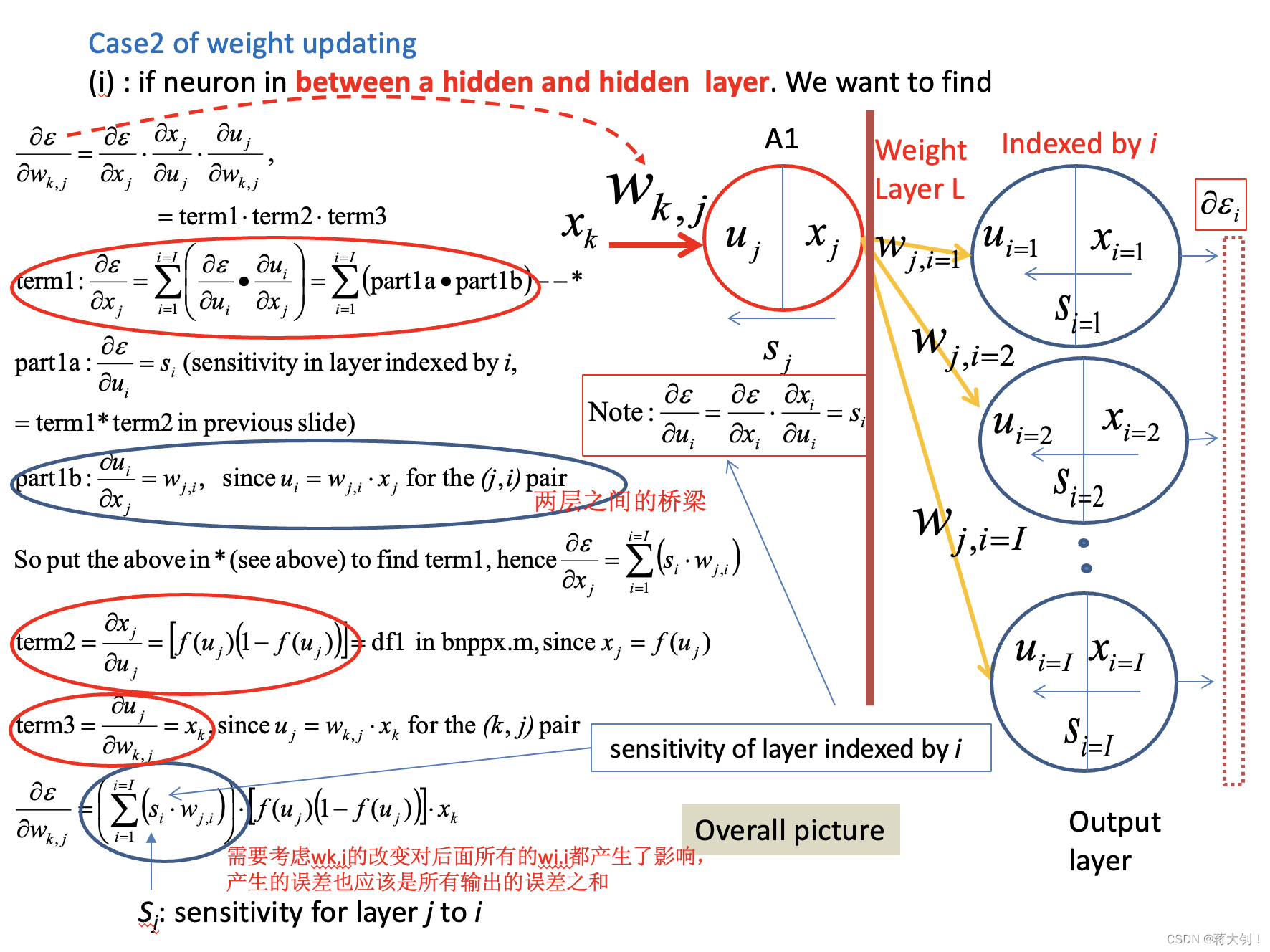
实现改进的方面
Full Batch and mini-batch weight update
这是一种加快训练速度的方式,我们将所有数据用于训练的一轮称作one epoch. 在一个epoch中每多少个训练样本用于权重更新称作batch size.
- Full-batch: 训练需要多次epoch,每次epoch将所有训练样本的gradient用于更新权重,一个epoch进行一次 backward pass.
- Mini-batch:在一个epoch中,每几个样本的gradient进行权重更新,一个epoch进行多次 backward pass.
- Online batch size: 每个样本的gradient都用于权重更新,batch size=1,前面的很多概念都是这个下面的。

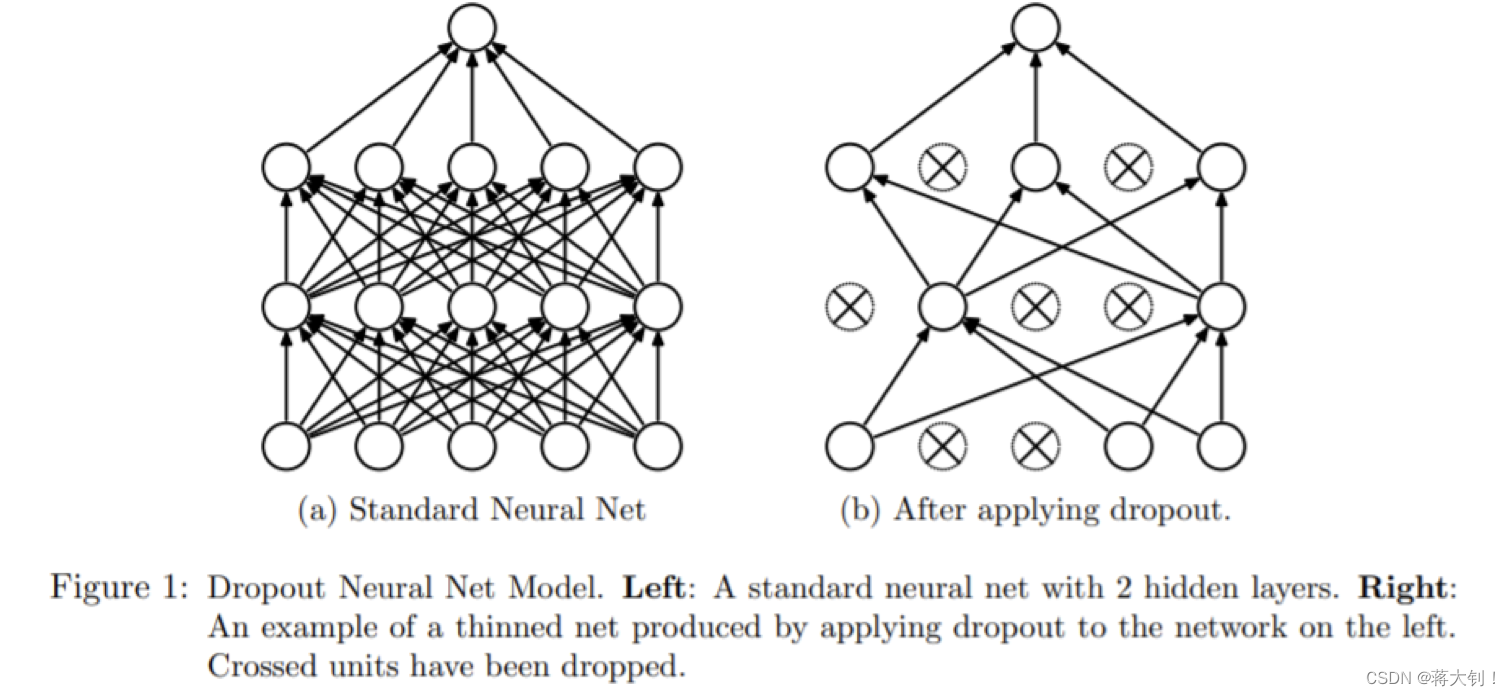
Dropout
丢掉神经网络中的几个节点预防过拟合overfitting。
Adaptive Moment estimation
之前的权重更新都是
w
=
w
−
α
∗
g
w=w-\alpha*g
w=w−α∗g,现在引入momentum和root mean square,处理噪声问题带来的稀疏的gradient。

相关题目
weight update between the hidden layer and the output layer
weight update Between a hidden layer and a hidden layer


















 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











