







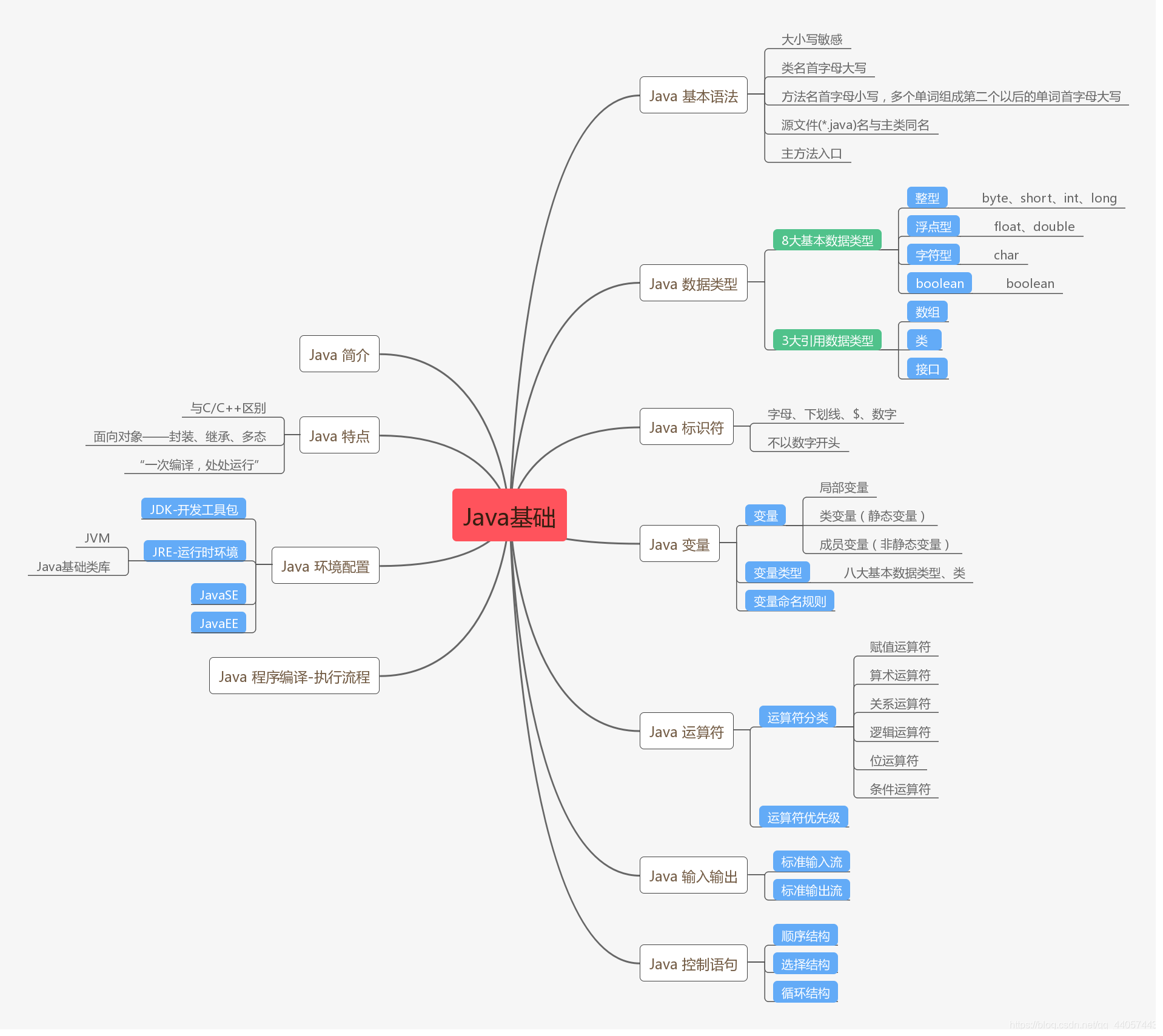
一、Java基础学习导图
二、接下来依照导图拓展内容
1、Java 简介
Java 是面向对象程序设计语言,集安全性、简单性、易用性和跨平台性等于一身,不仅可以解决传统的程序设计问题,更重要的是它与互联网密切相关,特别适合于网络环境下编程使用。
利用 Java 可以开发Java 小程序(Java Applet),Java 应用程序(Java Application),服务器端小程序(Servlet),JSP 程序(Java Sever Page)等。
题外话:Java与JavaScript的关系?
这二者的关系,就如同雷锋与雷峰塔,老婆与老婆饼,也就是没有一点关系。JavaScript 是用于web 前端开发,名字蹭了Java 的热度,现在JavaScript 是非常火的前端语言。
2、Java 语言特点
Java 语言最重要的特点就是 “Write once,run anywhere”,这句话就是 Java 程序员的精神指南。
Java 是一种简单、面向对象、不依赖于机器的结构,具有可移植性、健壮性(鲁棒性)、多线程、安全性,提供了并发的机制,并且具有很高的性能;Java 语言最大限制地利用了网络,Java 的 Applet 可以在网络上传输而不受 CPU 和环境的限制;Java 还提供了丰富的类库,使程序员可以方便地建立自己的系统。
(1)Java 是面向对象的程序设计语言,面向对象的特征如下:
面向对象方法反映了客观世界中现实的实体在程序中的独立性和继承性,有利于提高程序的可维护性和可重用性,具体如下:
- 封装:将对象属性和方法代码封装到一个模块中(类)中,保证软件内部具有优良的模块性的基础,实现“高内聚,低耦合” 。
- 抽象:找出一些事物的相似性和共性,然后归为一个类,该类只考虑事物的相似性和共性,抽象包括行为抽象和状态抽象。
- 继承:在已经存在的类的基础之上进行,将其定义的内容作为自己的内容,并可以加入新的内容或者修改原来的方法适合特殊的需求。
- 多态:同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果,就是多态。具体来说,就是用父类的引用指向子类的对象。作用:提高代码的复用性,解决项目中紧耦合的问题,提高可扩展性。
(2)Java 与 C++ 的异同:
- Java 为解释性语言,C++ 为编译性语言,Java 可以跨平台;
- Java 面向对象,C++ 为了兼容C 语言,保留了一些面向过程的成分,既能面向对象又能面向过程。Java 无全局变量和全局函数;
- Java 没有指针,更安全;
- Java 不支持多继承但是有接口概念;
- Java 不用人工管理内存(申请、释放),提供垃圾回收机制。当堆栈或者静态存储区没有对这个对象的引用时,就会被回收。Java 没有析构函数,但是有finalize()方法;
- Java 没有运算符重载,没有预处理功能。
(3)“一次编译,处处运行”
- Java 规定同一种数据类型在不同的实现中,必须占用相同的内存空间,与硬件平台无关,保证其程序的平台独立性;
- Java 程序的最终实现需要经过 编译 和 解释 两个步骤。Java 语言的编译器生成的可执行行代码称为 字节码,该字节码可以在提供 Java 虚拟机(JVM)的任何一个系统上解释运行,与任何硬件平台无关;
- JVM 是 Java 与平台无关的关键,在 JVM 上有一个 Java 解释器用来解释 Java 编译器编译后的字节码。Java 程序员编写好一个软件后,通过 Java 编译器将 Java 源程序编译为 JVM 的字节码。任何一台计算机只要安装了 JVM,就可以运行这个程序,而不管这种字节码是在什么平台上生成的,因此,Java 程序具有“一次编写,处处运行” 的特点。
(4)更多Java 语言的特点介绍,点击这里学习。
3、Java 环境配置
Java 开发环境配置方法详情,点击这里查看。
要进行 Java 的开发,必须先建立起 Java 的运行环境。有了 Java 的运行环境,就可以利用任何文本编辑器工具编写 Java 程序,再使用 Java 编译程序对源程序进行编译,之后就可以用解释程序来运行了。
Java 目前有三个主要成员:
1)Java SE(Java Standard Edition)——用于工作站、PC 机的 Java 标准平台;(标准版)
2)Java EE(Java Enterprise Edition)——是可扩展的企业级 Java 应用平台;(专业版)
3)Java ME(Java Micro Editon)——是嵌入电子设备的 Java 应用平台(微缩版)
JDK(Java Development Kit)——Java 软件开发工具包,是 Java 的开发环境,JDK 的安装需要配置 环境变量,即 path 和 classpath 的设置,配置时须注意个人的 JDK 安装路径。
PS:Path 的设置主要是为了能够在命令行下找到 Java 编译与运行所用的程序;Classpath 的设置主要为了让 Java 虚拟机找到所需的类库。
JDK 中比较常用的工具:
Javac:Java 编译器,用于将 Java 源代码转换为字节码;
Java:Java 解释器,直接从 Java 的类文件中执行 Java 应用程序字节码;
aapletviewer:小程序浏览器,之中执行HTML文件上 Java 小程序的 Java 浏览器;
Javadoc:根据 Java 源代码及说明语句生成 HTMl 文档;
Jdb:Java 调试器,可以逐步执行程序,设置断点和检查变量;
JRE(Java Runtime Environment)——Java 运行时环境,包含 Java 虚拟机却不包含编译器。
注意:JDK包含JRE。
Java 开发环境有很多,比较常用的有Eclipse、IntelliJ IDEA、NetBeans。
4、Java 程序编译-执行流程
(1)第一个 Java 程序,点击这里学习。至此就掌握了 Java 程序运行的操作步骤,然后看看 Java 程序的开发过程;
(2)Java 程序分为三类,即Application(应用程序),Applet(Java 小程序),Servlet(服务器端小程序)。
应用程序可在计算机中单独运行;Java 小程序只能嵌在 HTML 网页中后运行;Servlet 是运行在服务器端的小程序,可以处理客户传来的请求(request),然后传给客户端(response)。
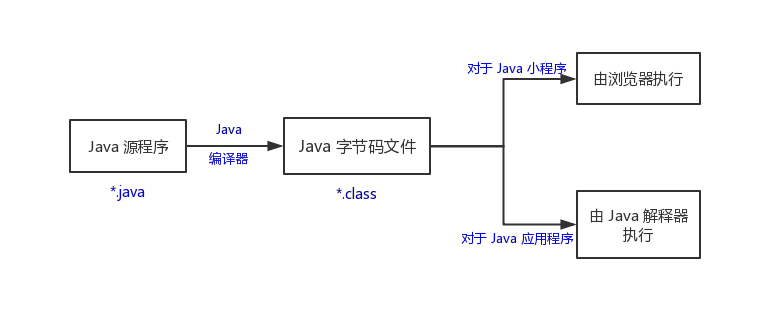
(3)以 Application 和 Applet 为例,Java 程序的开发过程如下图所示:
TODO:
5、Java 基本语法
(1)Java 中的 main 方法
public class Test{
public static void main(String[] args){
System.out.println("Hello,Java");
System.out.println("My name is:"+args[0]);
}
}上面所示就是一个简单的 Java 程序,通过这段代码,可以看到一个完整的 Java 程序的结构:
- 源文件(*.java):源文件带有类的定义,类用来表示程序的一个组件,小程序可能只有一个类,类的内容分需要用 花括号 包含;
- 类:类中带有一个或者多个方法,方法必须在类的内部声明;
- 方法:在方法对于的 花括号 中编写方法要执行的语句。
总结一下:类存在于源文件里面;方法存在于类中;语句存在于方法中。
(2)编写Java程序时,应注意以下几点:
- 大小写敏感:Java是大小写敏感的,这就意味着标识符Hello与hello是不同的。
- 类名:对于所有的类来说,类名的首字母应该大写。如果类名由若干单词组成,那么每个单词的首字母应该大写,例如 MyFirstJavaClass 。
- 方法名:所有的方法名都应该以小写字母开头。如果方法名含有若干单词,则后面的每个单词首字母大写。
- 源文件名:源文件名必须和类名相同。当保存文件的时候,你应该使用类名作为文件名保存(切记Java是大小写敏感的),文件名的后缀为.java。(如果文件名和类名不相同则会导致编译错误)。
- 主方法入口:所有的Java 程序由public static void main(String []args)方法开始执行。
(3)Java 中可以有多个 main() 文件,但是只有与文件名相同的用 public 修饰的类的 main() 才能作为程序的入口,这样的入口有且只有一个!!
6、Java 数据类型
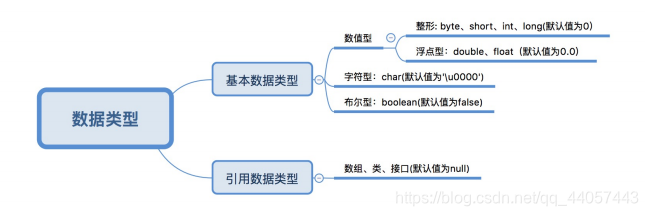
Java 数据类型具体介绍,点击这里学习。
(1)对于上述基本数据类型的选择,建议:
- 在程序开发之中,整数就用int,描述小数用double。
- long一般用于描述日期、时间、内存或文件大小(字节)
- 如果要进行编码转换或者进行二进制流的操作,使用byte(-127~128)
- char一般在描述中文中会用到(基本忽略)
注意:Java 中用双引号括起来的字符串都是 String 类型的示例,字符串类型String不是基本数据类型,是标准 Java 类库提供的一个预定类,两个 String 类型相加或者 String 类型与其他类型用 + 相加的效果就是 拼接。
public class practice{
public static void main(String[] args){
String a = "hel" ;
String b = "lo" ;
String c = a + b ;
System.out.println(c+" "+"world!"+2019) ;
}
}注意:Java 中为了保证可移植性,所有的数值类型所占字节数是固定的,与平台无关(如 int 永远占 4 个字节,long 永远占 8 个字节)
7、Java 标识符
Java语言中,对于变量,常量,函数,语句块也有名字,我们统统称之为Java标识符。
对于Java标识符,有以下三点要求:
- 标识符由字母、数字、_、$ 组成,不能以数字开头,不能用Java中的保留关键字
- 标识符采用有意义的简单命名
- “$”不要在代码中出现
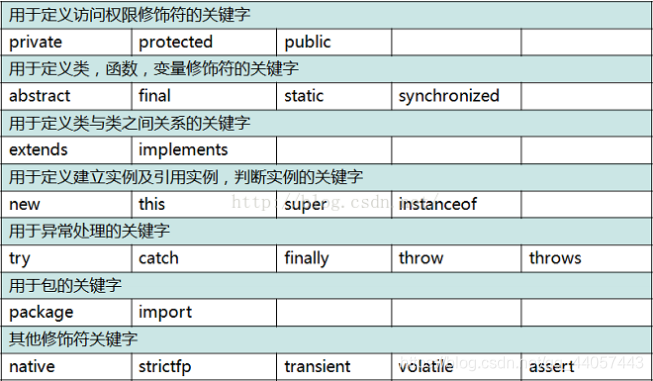
关于 Java 中关键字, 点击这里了解。
Java 中常见关键字如下:
8、Java 变量
public class Variable{
static int allClicks=0; // 类变量
String str="hello world"; // 实例变量
public void method(){
int i =0; // 局部变量
}
}Java 中变量类型,点击这里学习。
在 Java 中,所有的变量在使用前必须声明。声明变量的基本格式如下:
type identifier [ = value][, identifier [= value] ...] ;
注意:Java 中变量的命名推荐采用“驼峰命名”,避免无意义的命名,并且不能使用 Java 中的保留关键字。
在 Java 中不区分变量的声明与定义。
9、Java 运算符
Java 中运算符详情,点击这里学习。
(1)& 和 && 的区别?
&:逻辑与(and),运算符两边的表达式均为 true 时,整个结果才是 true;
&&:短路与,如果第一个表达式为 false,那么不再计算第二个表达式。
| 与 || 类似
10、Java 输入/输出
(1)标准输入流
Scanner in = new Scanner(System.in) ;注意:这里构造了一个 Scanner 对象,并与“标注输入流” System.in 关联,记得在程序的最开始添加 import java.util.Scanner ;
Scanner 类详情,点击这里了解。
(2)标准输出流
System.out.print("helle world") ;以上输出使用了 System.out 对象并调用了它的 print 方法,传递给它一个字符串参数,print 可以将传递给它的参数显示在控制台上,要想换行显示输出就使用 println 。
11、Java 控制语句
控制语句相关教程:循环语句、条件语句、switch-case 语句
注意:Java 中提供了一种带标签的 break 语句,用于跳出多重嵌套的循环语句。标签位于希望跳出的最外层循环之前,且必须紧跟一个冒号。
break 标签应用举例:
public class breakTest{
public static void main(String[] args){
for(int i=0; i<5; i++){
outer:
for(int j=0; j<5; j++){
if(j == 3){
break outer ;
}
System.out.print(i+","+j+" ") ;
}
System.out.println() ;
}
}
}运行显示:
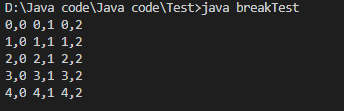
不加 break 标签:
public class breakTest{
public static void main(String[] args){
for(int i=0; i<5; i++){
for(int j=0; j<5; j++){
System.out.print(i+","+j+" ") ;
}
System.out.println() ;
}
}
}运行显示:

总结:不积跬步无以至千里,任何一门语言的学习都是从基础开始的夯实基础,才能进行更深的学习。以上就是 Java 基础入门的一些知识点,如有错误,请大家批评指正!!!

















 6756
6756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









