







目录
一、回顾逻辑回归
(一)sigmod函数
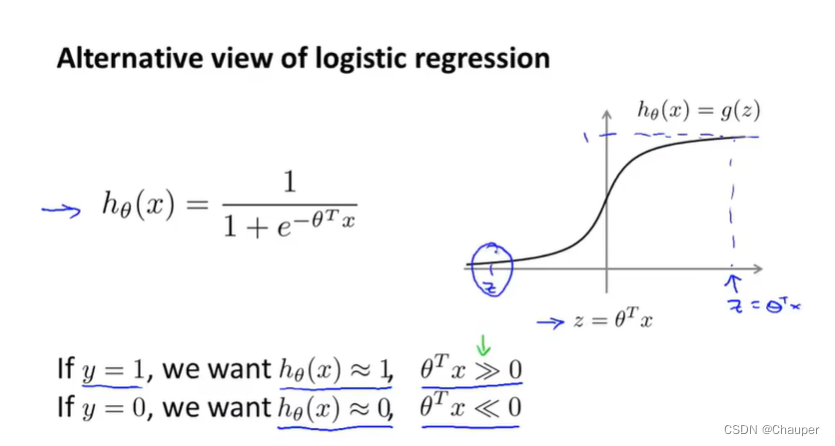
(二)单项代价函数
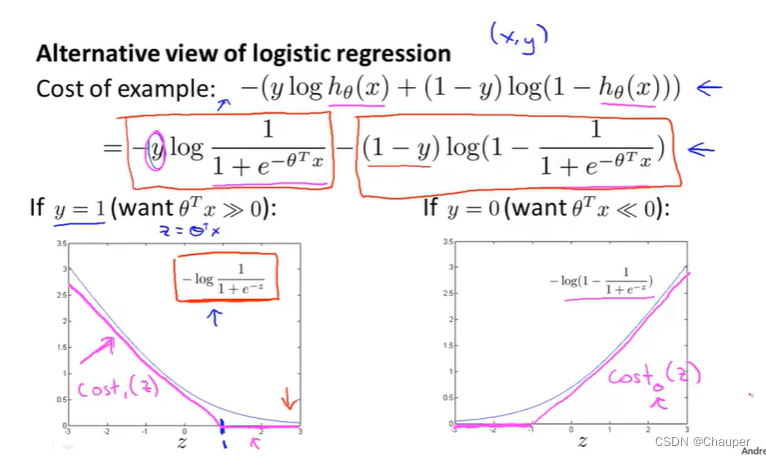
1、y = 1,单项代价函数中“-”号前部分起作用,紫红色cost1(z)是y = 1时支持向量机的函数图像
2、y = 0,单项代价函数中“-”号后部分起作用,紫红色cost0(z)是y = 0时支持向量机的函数图像
二、支持向量机的代价函数
1、与逻辑回归代价函数的对比
①将划线部分换为cost函数
②去掉1/m
③换另一种控制权衡的方式,即将支持向量机中λ换成C ,即A+λ*B换成C*A+B

2、支持向量机的预测
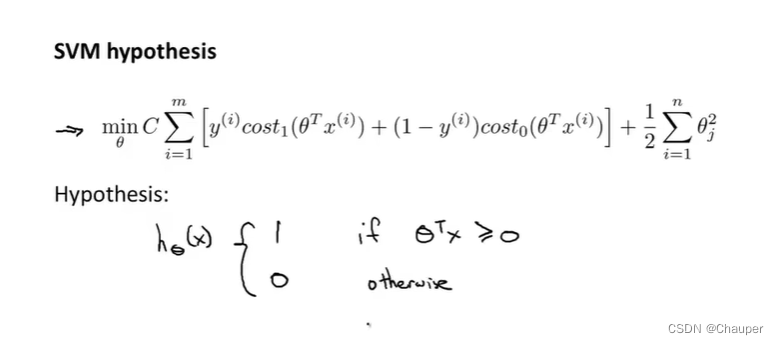
三、又名大间距分类器
1、安全因子定义
θ的转置*x≥1而非是仅仅≥0即可,这意味着设置了一个安全因子,一个安全间距
注:其中参数求和符号上的n=m
2、安全因子的作用
(1)大间距分类器是在C值设很大时得到
C值假设是100000,此时,框内求和函数需为0,才可使代价函数最小化

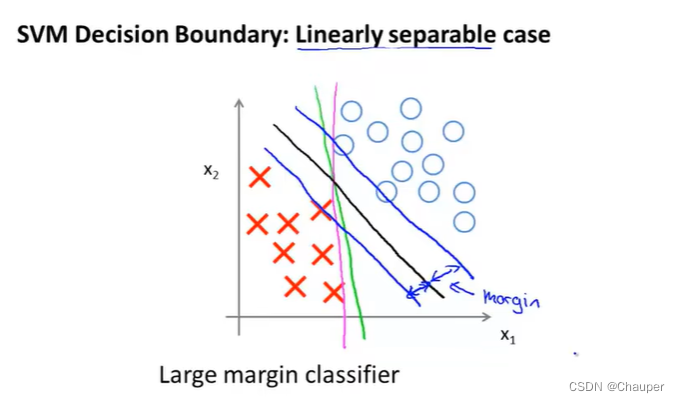
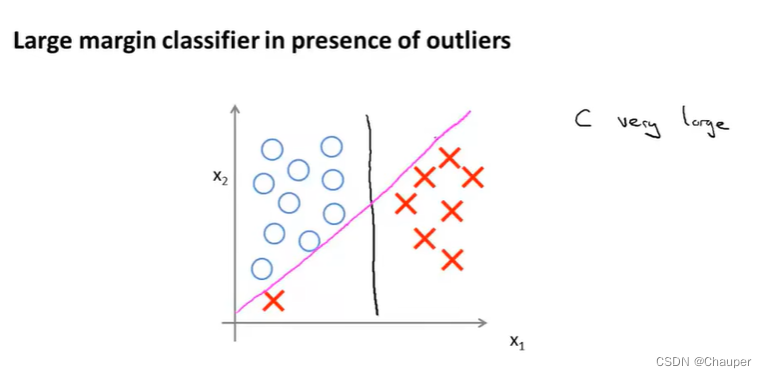
(2)大间距分类器的图示说明
①对比说明
svm画出的是黑色那条,优于绿色和粉色两条分割线,因为他将正负样本以最大的间距分开,即黑色和数据间的最小距离(支持向量机的间距)更大,使得它具有很好的鲁棒性。为什么这个优化问题可以得到这个大间距分类器
②特点
大间距分类器(即C值被设得非常大)对异常点会很敏感,会因一个异常点而改变
(3)C值设得大,间距就大的数学逻辑
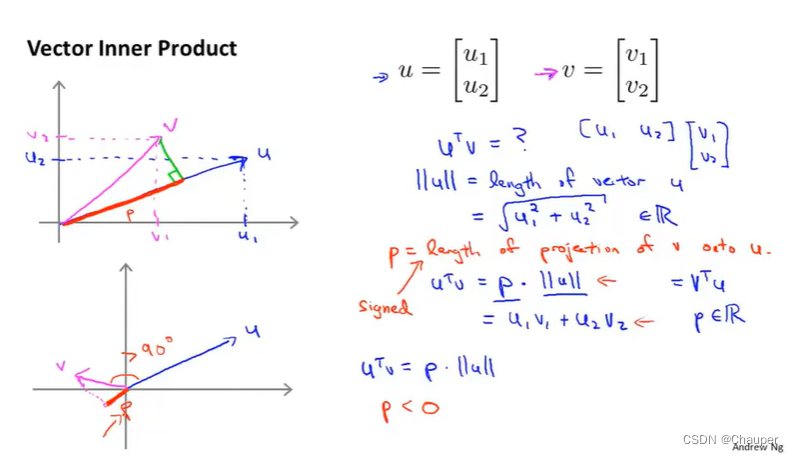
(ⅰ)向量概念:内积、范数(长度)
内积:红色线长度p的是向量VU的内积,即向量V到向量U上的投影
U^T*V=p*||U||=U1V1+U2V2(p的值是有符号的,若v和u之间的夹角是锐角,p是正;若v和u之间的夹角是钝角,p是负)
(ⅱ)支持向量机代价函数简化ⅵⅲ
①即C值取很大时,cost1和cost2都取0时的代价函数;再利用上述的向量概念,等价替换θ^Tx(i),此时假设n=2
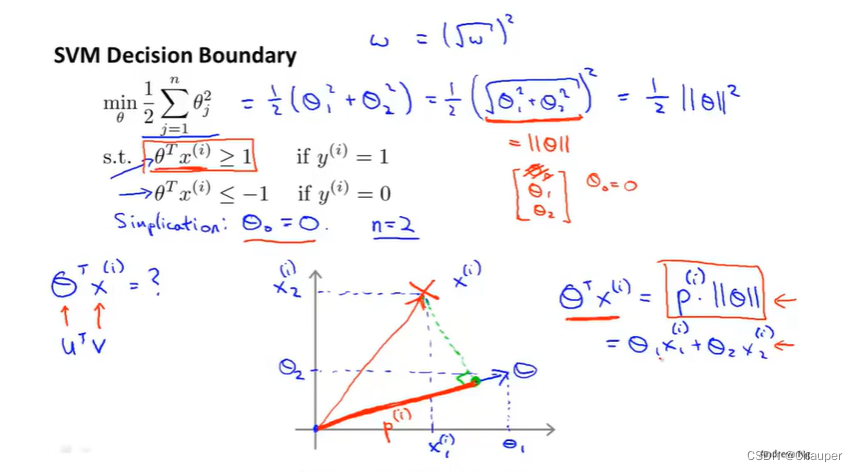
②将等价替换后的p(i)*||θ||代入到优化目标函数中
③图形的一些特点:
θ 0 = 0,说明决策边界必通过原点(0,0),任意一个决策边界都有对应一个θ是与其正交
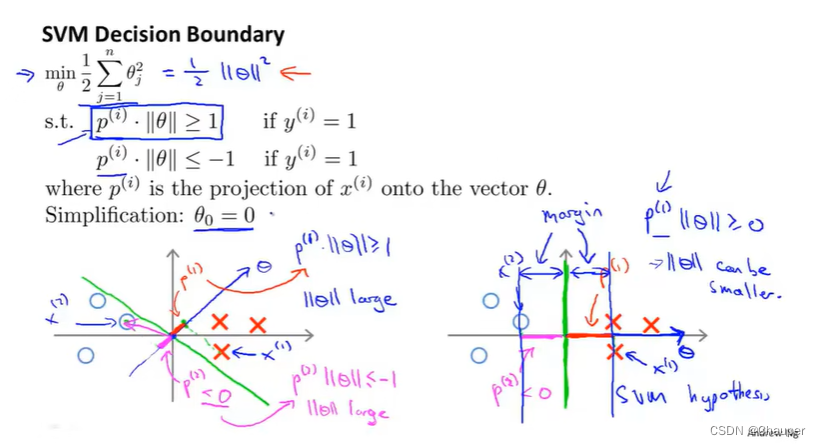
④解释为什么可找到大间距分类器
因为它试图最大化所有p^(i)的范数,也就是训练样本到决策边界的距离,也是训练样本到θ的投影
举例说明:例如n=2、θ0 = 0时的情况,如下图任意一点数据集在θ上的投影即p^(i)都特别小(如左彼岸图p^(1)和p^(2)),则此时若要求
p^(i)*||θ||≥1,||θ||就会很大,所以代价函数则会很大;整体情况如左边图所示。右图中p^(1)和p^(2)都大,所以||θ||更小,从而最后的决策边界时右图所示
四、改造支持向量机
1、核函数的概念
高阶的计算量非常大,是否有其他更好的新的特征可以代替高阶

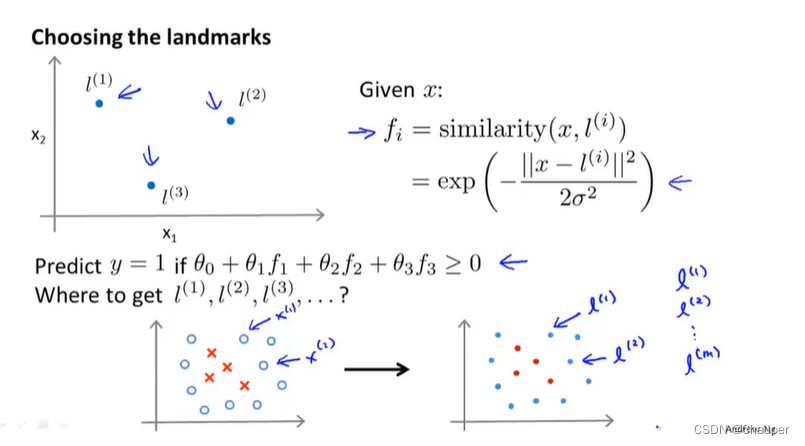
2、构造新特征f1、f2、f3的方法
(1)f1、f2、f3是什么
是相似度的度量,是x与标记的三个点l^(1)、l^(2)、l^(3)的相似度,通过标记点和相似度函数来定义新的特征变量,从而训练复杂的非线性边。
(2)相似度函数similarity(x,l^(i))
就是一个核函数k(x,l^(i))(高斯核函数
(3)f1、f2、f3表达式
如下图所示:标记三个点l^(1)、l^(2)、l^(3),其中f1、f2、f3是相似度函数
注:其中||x-l^(1)||^2是x与 l^(1)的欧式距离,每个标记的l^(i)(i =1,2,3)对应一个fi(i=1,2,3)
(4)f1、f2、f3的数学解释
如果x非常接近标记,那么特征f非常接近于1;如果x和标记非常远,那么特征f非常接近于0,计算如下所示:

(5)f1、f2、f3函数图示
由图中可知
①离特征值越远,则函数值接近0;离特征值越近,则函数值接近1
②高斯核中参数σ越小,凸起的宽度变窄,等高线圈越小,特征变量的值减小的速度变快(越陡)

(6)预测函数
前提:假设θ是已知的,将图中粉色点、湖蓝色点、绿色点这三个训练实例代入公式,观察预测值;
例如粉色这点距离l^(1)近,则f1为1;距离l^(2)和l^(3)远,所以f2和f3都为0;代入公式得出结果
结论:接近l^(1)和l^(2)的预测值都为1,远离l^(1)和l^(2)的预测值都为0;最终得到红色的决策边界,红色决策边界里面的y值为1,外面的y值为0

五、补充细节
应用思想——处理支持向量机中的偏差方差折中
1、如何得到标记点?
方法就是选取样本点,直接将训练样本作为标记点;
而选取的变量x可以是训练集也可以是验证集或是测试集;
将f1、f2、f3组成特征向量f;
将训练的x^(i)分别代入到f1、f2、f3……fm中去,得到x^(i)与其各标记点的相似度,得到合并的向量f来描述特征

2、公式详解

(1)特征f的个数,是实际的标记数+1,其中+1是来自于截距
(2)代价函数中,参数的求和公式上的n=m的,即m个标记点个数,同之前正则化类似,不会正则化θ0
(3)参数中的平方可以换成θ^T*θ,大多数支持向量机在实现的时候,都是用θ^T*Mθ(M是某个向量)替换θ^T*θ,这种形式是另一种略有区别的距离度量方法,是参数θ的缩放版本,使得向量机能能有效的运行,可应用更大的训练集
(4)核函数概念也可运用到其他算法上,但是只有在支持向量机上时,才相得益彰,高级优化机器是专门为支持向量机提出的
(5)参数C,等价于神经网络中的参数1/λ,λ是正则化的系数,λ越大正则化越强,λ越小正则化越弱。
(6)参数σ^2,大σ^2,函数图像变化非常平滑,类似大λ即正则化强,高偏差,低方差
小σ^2,图像变化非常陡峭,类似小大λ即正则化弱,高方差,低偏差
六、使用支持向量机
1、利用现有软件库来寻找最优的θ

2、确认参数:
①参数C的选择
②选择内核参数
case1:线性核的SVM
定义:是指不带核函数的SVM;比如SVM的另一个版本,只是给的是一个标准的线性分类器,可以linear函数去拟合
适合的情况:如特征量大即n大,且m即训练的样本数很小,若想用线性拟合而不是复杂的非线性函数拟合边界的情况
case2:带核的高斯内核函数
第二步:选择σ^2,考虑偏差和方差的权衡
适合的情况:拟合相当复杂的非线性决策边界,高斯函数适合
第三步:提供核函数(如高斯函数),能够输入x1,x2来计算核函数的特征变量fi并返回一个实数;注意若特征变量的大小变化大,在计算之前需要将这些特征变量的大小按比例归一化。(why:若大小相差很大,整个函数就由数值大的特征来决定)所以归一化是保障svm考虑到所有不同的tezhengbianl

3、何时选择线性内核函数或高斯内核等核函数
(1)选择的核函数需要满足莫塞尔定理
why:因为核函数的运行技巧都是基于满足莫塞尔定理的基础上,莫塞尔定理确保所有的svm包和所有的svm软件包能够用 大类的优化方法并从而迅速得到参数θ
(2)其他核函数(很少用 ):
①多项式核函数 (Polynomial kernel),
适用于:x和l都是严格的非负数时,以保证内积值永远不会是负数
公式形式如下图:

②文本字符串核函数(String kernel):适用于当输入的数据是字符串时
③卡方核函数(chi-square kernel)
④直方相交核函数(histogram intersection kernel)
(3)多分类函数
用one-vs-all(一对多)的方法,训练ksvm,k个类别,每个类别从其他的类别中区分开来
分类出y=1和其他类别,得到θ^(1)向量;分类出y=2和其他类别,得到θ^(2)向量;
分类出y=3和其他类别,得到θ^(3)向量…… 最后,用最大的θ^T*X来预测类别i

(4)逻辑回归和svm的选择
case1:特征数量n比训练样本m个数多,如文本分类(一万个特征)使用逻辑回归或不带核的svm
case2:特征数量n少(1-1000),训练样本m大小适中(10-10000),使用高斯核函数的svm
case3:特征数量n少(1-1000),训练样本m大(50000-上百万),高斯核函数运行速度慢
手动创建特征,用逻辑回归或不带核函数的支持向量机(这两个算法相似,在于做相似的事,得出相似的结果)
以上情况都适合用神经网络,根据不同情况的设计不同的结构,缺点是会慢;相比较下,svm包运行快得多;svm是一种凸优化问题,可以找到全局最优解,不用担心局部最优;但是神经网络就存在局部最优这不大不小的问题















 3378
3378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









