










单通道语音信噪分离算法研究
摘要:为了评估单通道语音信噪分离的效果,本文分别对六种传统语音增强算法进行了探讨。在理想的高斯白噪声环境下,子空间法增强后的语音信号输出信噪比SNR最大,VMD(Variational Mode Decomposition, VMD)增强后的语音信号语谱图保留频率细节部分更多,分段信噪比 segSNR 最高。在八种不同场景不同信噪比复杂环境下,维纳滤波法增强后的语音信号分段信噪比segSNR最大,语音感知度最高。
关键词:语言增强;VMD;子空间;维纳滤波法;
目录
1 绪论 2
2 单通道语音增强技术 3
2.1 语音与噪声特性 3
2.1.1 语音特性 3
2.1.2 噪声特性 4
2.2 语音增强算法 4
2.2.1 谱减法 4
2.2.2 时域维纳滤波 5
2.2.3子空间 6
2.2.4 小波分析 7
2.2.5 变分模态分解 8
2.3 语音增强算法的性能评估标准 10
2.3.1 主观评价标准 10
3. 语音增强效果及评估 12
3.1 数据来源 12
3.2 仿真效果及分析 12
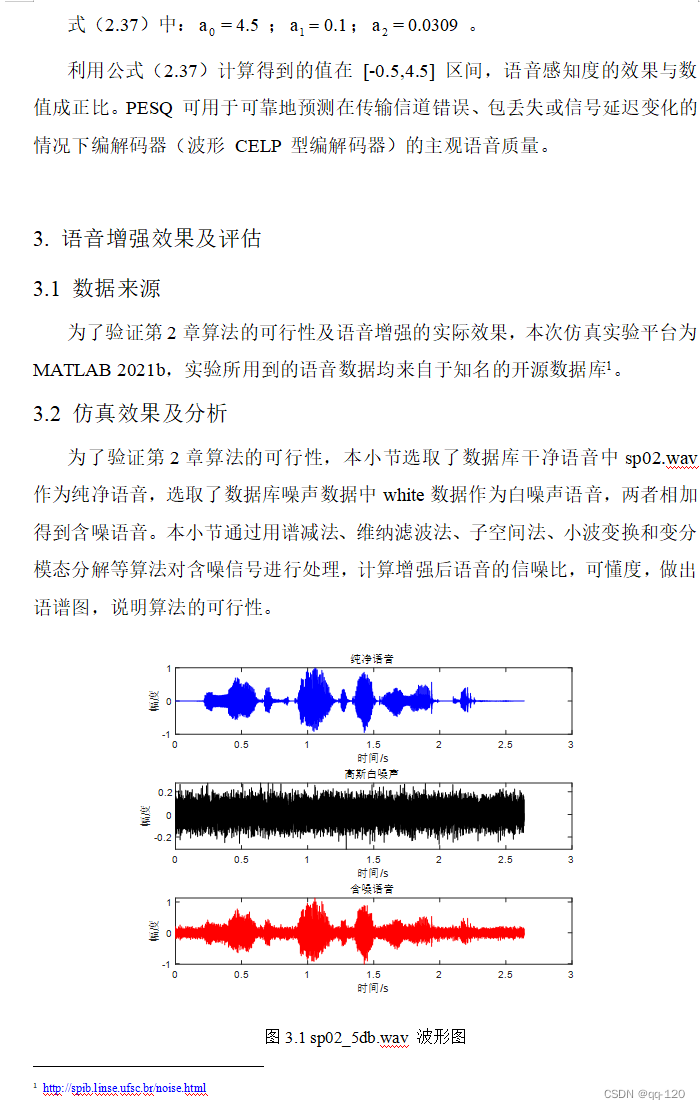
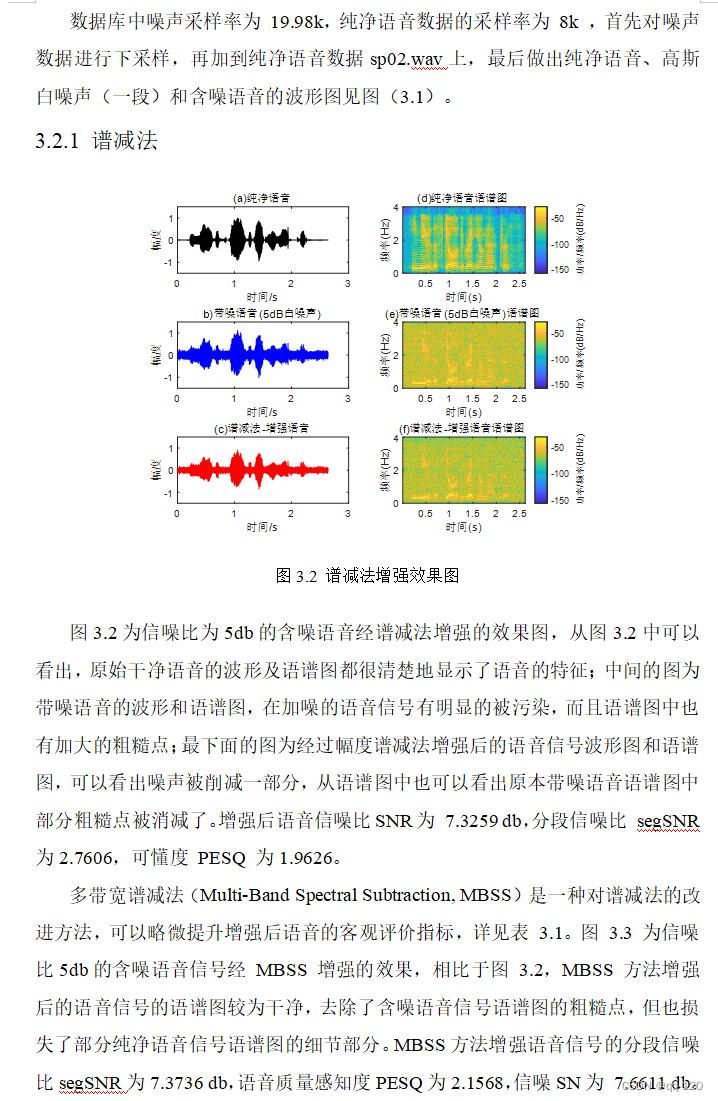
3.2.1 谱减法 13
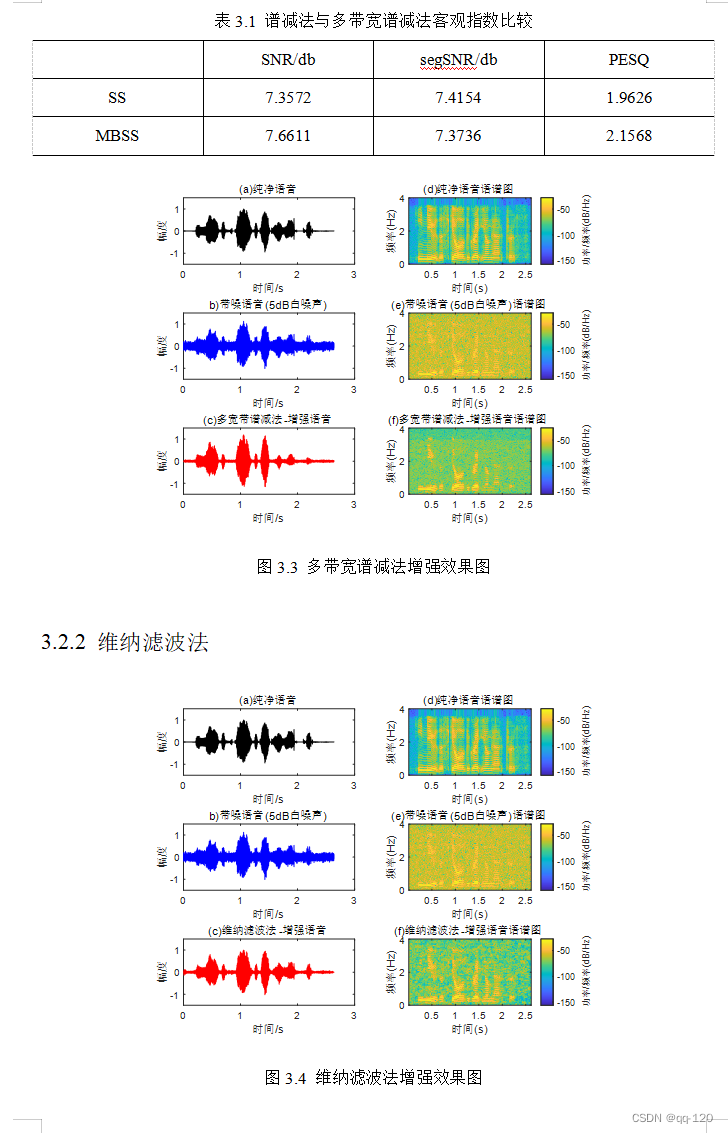
3.2.2 维纳滤波法 14
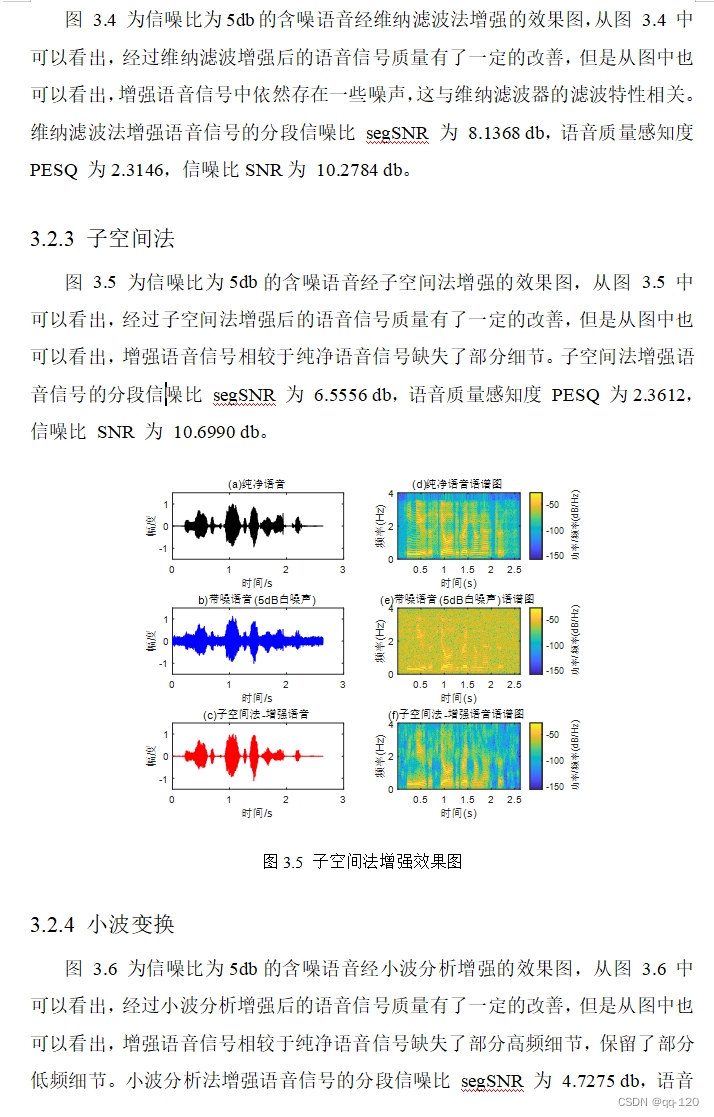
3.2.3 子空间法 15
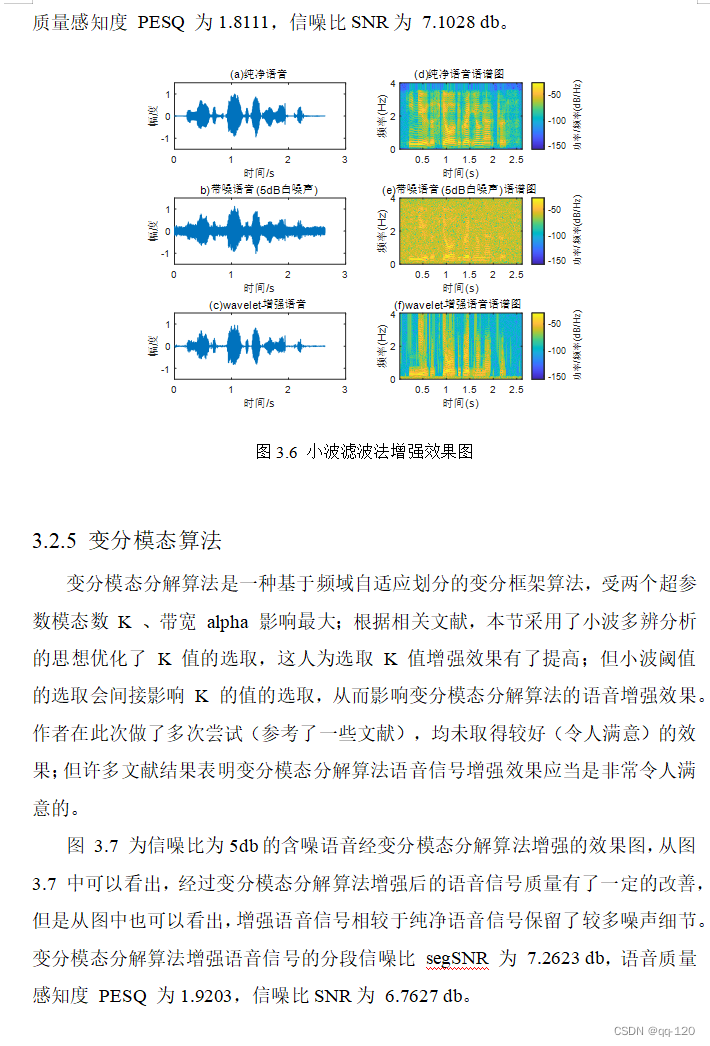
3.2.4 小波变换 15
3.2.5 变分模态算法 16
3.3 客观分析 17
4. 结论 20
5. 致谢 21
6. 参考文献 22
1 绪论
在单麦克风场景下,语音增强算法主要通过对带噪语音信号进行时域、频域、时频域、KLT域以及 SVD 域的系数变换,并根据变换后的系数特征来区分纯净的语音信号和噪声,进而达到信噪分离的目的。在简单场景下输入信噪比较高的情况下,可以直接通过将噪声系数置零来达到语音增强的目的,但对于复杂场景下低信噪比的带噪语音信号简单地进行噪声系数置零可能会导致增强后的语音信号失真。
在八九十年代,所提出大多数语音增强算法是基于频域的。最先谱减法(Spectral Subtraction, SS)思想含噪语音信号能量谱与前几帧估计到的平均能量谱相减,得到估计到的增强语音信号能量谱;但其中噪声能量谱估计得不准确会导致频谱过减而产生“音乐噪声”,降低了语音增强质量。然而,谱减法还存在“相位问题”,将带噪语音信号的相位直接作为增强语音信号的相位可能会造成失真现象。基于统计模型的语音增强算法有维纳滤波法(Wiener Filter, WF)、最小均方误差(Minimum Mean Square Error, MMSE)算法等;MMSE算法增强后的语音信号中残留噪声量相对较少,其中最小均方误差(Log-MMSE)算法残留噪声更少且舒适度得到了提升。子空间(subspace)方法的原理是将观测信号的向量空间分解为信号子空间和噪声子空间,通过保留信号子空间和消除噪声子空间并从而估计出干净语音。在复杂环境低信噪比情况下,子空间方法仍不能有效地分离出噪声。
由于语音信号非线性、非平稳性等性质,传统的傅里叶变换方法已不再适用。针对语音信号的非平稳、时变等特性,许多学者提出了一些基于时频域方法。小波变换(Wavelet Transform, WT)是时间和频率的局部化分析,通过伸缩平移运算对信号逐步进行多尺度细化,最终达到高频处时间细分,低频处频率细分,能自动适应时频信号分析的要求,从而可聚焦到信号的任意细节。大量实验表明小波变换能够在很大程度上对非平稳信号进行去噪,增强语音信号的信噪比优于其他传统方法增强语音信号的信噪比,但小波去噪的关键取决于阈值的选取,一个合适的小波阈值可以达到较好的语音增强效果,且小波变换不适用于非线性信号。经验模态分解(Empirical mode decomposition, EMD)算法根据信号的局部特性将带噪信号分解为有限个固有模态函数(Intrinsic mode function, IMF),从而适用于非线性非平稳信号,大量实验结果表明增强语音信号质量在不同程度上均有一定的提升;但EMD算法可能会由于端点检测不准确造成模态混叠现象,造成语音重构信号不准确,从而导致语音质量下降。针对EMD存在模态混叠问题,EEMD (Ensemble EMD)、CEEMD (Complementary EEMD)算法可以避免模态混叠现象发生,但无法消除。为了解决EMD的模态混叠问题,Konstantin Dragomiretskiy和 Dominique Zosso提出了变分模态分解 (Variational Mode Decomposition, VMD)算法,实验表明该算法可以避免端点检测所造成的模态混叠问题,从而增强语音信号质量要明显好于EMD增强语音信号质量
本课程论文第2章介绍了几种传统的单声道语音增强算法和语音质量评估的主、客观指标。第3章为不同语音增强方法对在不同场景下不同信噪比的语音信号进行去噪增强,然后在客观评价的尺度下分别计算分段信噪比和语音感知度。
2 单通道语音增强技术
2.1 语音与噪声特性
2.1.1 语音特性
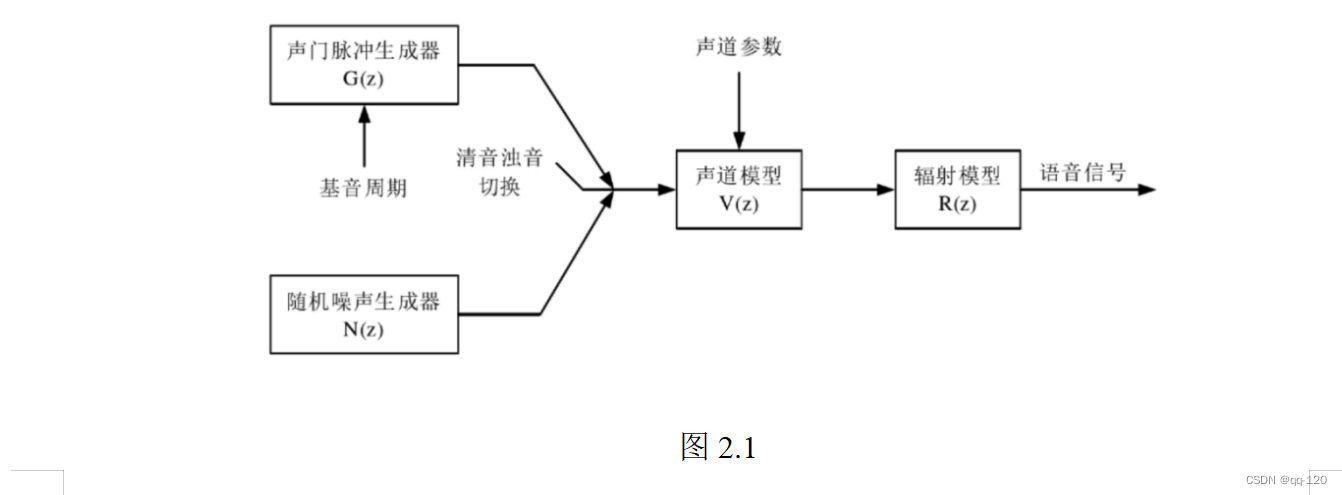
语音信号是一个典型的随机信号,虽然其二阶统计量的变化随时间变化但是其满足短时平稳性,即在很短的时间内(10~30ms)可以把语音信号看成平稳随机过程。语音信号具有周期性,这是人体本身的发声机制所决定的。实际工程中可通过提取语音信号的基音周期进行一系列的语音信号处理,同时研究语音的声学特征可很好的提升语音可懂度与质量。在工程模型中,声带与声道可分别看作激励源和滤波器,而声带的震动可以是周期同时也可以是非周期的。图 2-1 为工业中通用的语音产生模型。











篇幅太长,省!
详见文件资源。
[1] 吉慧芳,贾海蓉,王雁.改进相位谱补偿的语音增强方法[J].计算机工程与应用, 2019,55(08):48-52.
[2] Thimmaraja G. Yadava, H. S. Jayanna, Speech enhancement by combining spectral subtraction and minimum mean square errorspectrum power estimator based on zero crossing[J]. International Journal of Speech Technology, 2019, 22(3): 639-648.
[3] Yadava T G, Jayanna H S. Speech enhancement by combining spectral subtraction and minimum mean square error-spectrum power estimator based on zero crossing[J]. International Journal of Speech Technology, 2019, 22(3): 639-648.
[4] Yan L, Addabbo P, Zhang Y, et al. A sparse learning approach to the detection of multiple noise-like jammers[J]. IEEE Transactions on Aerospace and Electronic Systems, 2020, 56(6): 4367-4383.
[5] Dragomiretskiy K, Zosso D. Variational mode decomposition[J]. IEEE transactions on signal processing, 2013, 62(3): 531-544.
[6] 郭欣. 基于K-SVD稀疏表示的语音增强算法研究[D].太原理工大学,2016.
[7]路敬祎,马雯萍,叶东,姜春雷.基于VMD的声音信号增强算法研究[J].机械工程学报,2018,54(10):10-15.
[8] 陆振宇,卢亚敏,夏志巍,黄现云.基于变分模态分解和小波分析的语音信号去噪方法[J].现代电子技术,2018,41(13):47-51.
[9] 贾海蓉,张雪英,牛晓薇.用小波包改进子空间的语音增强方法[J].太原理工大学学报,2011,42(02):117-120.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











