






Attention Is All You Need的理解以及pytorch实现transformer框架
仅以这篇文章记录我的思考,本人水平有限,如有错误欢迎指正。
pytorch 代码参考于
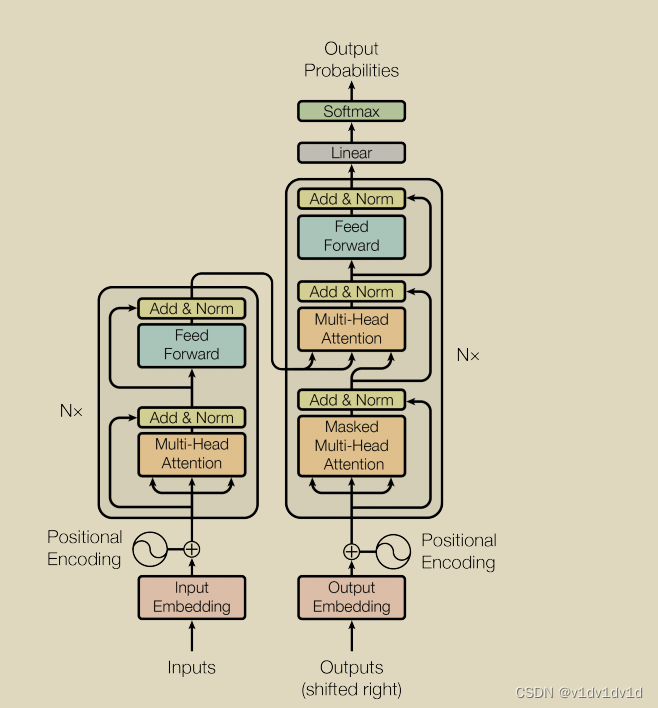
左边部分为编码器encoder,右边部分为解码器decoder。
数据在进入transformer之前,需要进行预处理。
数据预处理的流程为:
1、数据经过embedding编码成给定长度的vector。
# n_src_vocab 为词空间的大小, d_word_vec 为嵌入向量的维度大小
self.src_word_emb = nn.Embedding(n_src_vocab,d_word_vec,padding_idx=pad_idx)
# 因为每一个句子的长度不一定都相同,所以需要将短句子padding成长句子
# padding_idx 的值表明我需要将给定句子中的哪些部分变成0
# 例:
# 假设有一个向量s = [4,3],我需要将其转化成长度为5的向量,当padding_idx = 2 时,我需要在s的后
# 面添加3个2。注意:padding_idx 要小于词空间大小。
embeder = nn.Embedding(5,6,padding_idx=2)
s_padding = torch.LongTensor([4,3,2,2,2])
print(embeder(s_padding))
# output:
tensor([[ 1.6093, 0.3918, 0.5745, -1.5683, 0.4468, 0.4363],
[ 0.0946, 1.4778, -0.3423, -0.6214, -0.2368, 2.1360],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]],
grad_fn=<EmbeddingBackward0>)
经过词嵌入之后,数据的维度就从(batchsize,句子长度,词空间大小)变成了(bacthsize,句子长度,嵌入向量维度大小)
2、数据经过positional encoding 进行位置编码。
由于注意力机制无法从相对位置中学到东西,这显然不是我们想要的,所以论文中加入位置编码使得模型能够学到位置信息。
论文中采用的方法为:

class PositionalEncoding(nn.Module):
def __init__(self, d_hid, n_position=200):
super(PositionalEncoding, self).__init__()
self.register_buffer('pos_table',self._get_sinusoid_encoding_table(n_position,d_hid))
def _get_sinusoid_encoding_table(self, n_position, d_hid):
def get_position_angle_vec(position):
return [position / np.power(10000, 2*(hid_j//2)/d_hid) for hid_j in range(d_hid)]
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
# sinusiod_table 为 (n_position,d_hid)的矩阵
# 这里的d_hid 就是 嵌入向量的维度大小
# 对于奇数列和偶数列分别使用sin和cos函数进行位置编码
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim = 2 * i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim = 2 * i + 1
# 因为要和embedding后的矩阵相加,所以要把sinusoid_table 变成三维矩阵
return torch.FloatTensor(sinusoid_table).unsqueeze(0)
def forward(self, x):
# self.pos_table (1,position,嵌入向量的维度大小)
# 传入的x 为embedding 后的矩阵 (bacthsize,句子长度,嵌入向量维度大小),
#所以x.size(1)为句子长度,由此可见, sentence长度 不能大于 position
return x+self.pos_table[:, :x.size(1)].clone().detach()
3、论文中提到将embedding之后的数据乘 d_model ** 0.5
4、数据经过dropout和layer_norm 输入到encoder中
transformer中的encoder和decoder都由若干个(论文中给定的N = 6)block组成。
encoder 主要由一个多头注意力机制和前馈神经网络构成。
数据在一个 encoder block 的传输过程为:
1、经过处理完毕的数据(batchsize,句子长度,嵌入向量维度大小)首先经过一个 Multi-Head-Attention得到 输入结果和相似矩阵。
单层注意力机制的工作原理图为:
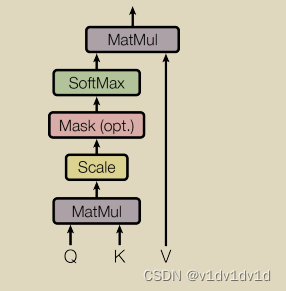
class ScaledDotProductAttention(nn.Module):
def __init__(self,temperature,attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
# 对应论文中的 3.2.1
# q k v 为 经过预处理之后的数据(bacthsize,句子长度,嵌入向量维度大小)
# 在多头注意力机制中,q,k,v需要经过一个linear层,其数据规格为(bacthsize,
# n_head, 句子长度, 嵌入向量维度大小)
# 论文中给定的n_head大小为8
def forward(self,q,k,v,mask=None):
#************************************************************
# transformer中有三个位置需要mask,其中encoder和decoder中的输入端,由于
# 我们为了方便计算给句子填入了很多padding,所以我们要消除padding的影响,所以
#需要用到mask将padding的部分消除掉,具体的方法就是给padding的位置赋值-1e9,使得在
# softmax中尽可能取到较小的值
# decoder中mutil_head_self_attention中需要用到mask。因为在测试验证阶段,
#模型并不知道当前时刻的输入和未来时刻的单词信息。也就是对于一个序列中的第i个token解码的时
#候只能够依靠i时刻之前(包括i)的的输出,而不能依赖于i时刻之后的输出。
#************************************************************
attn = torch.matmul(q / self.temperature , k.transpose(2,3))
if mask is not None:
attn = attn.masked_fill(mask == 0 ,-1e9)
attn = self.dropout(F.softmax(attn,dim=-1))
# attn为相似度矩阵(bacthsize, n_head, 句子长度,句子长度),表示每个单词之间的相似度
output = torch.matmul(attn,v)
# output为ScaledDotProduct的结果:(bacthsize, n_head, 句子长度,嵌入向量维度大小)
# 表示了某个位置的单词和其他单词之间的联系(注意力机制)
return output,attn
简要介绍masked_fill(mask,value)函数:
将mask = true 的位置的值修改为value,并且返回一个tensor。
mask的维度应该和修改之前tensor的维度相同。
a = torch.randn((4,5))
mask = torch.tensor((a<0),dtype=torch.int)
att = a.masked_fill(mask==0,-1e9)
print(mask)
print(a)
print(att)
# tensor([[0, 1, 0, 1, 0],
# [1, 0, 0, 1, 1],
# [1, 1, 0, 1, 1],
# [1, 0, 1, 0, 0]], dtype=torch.int32)
# tensor([[ 2.1491, -1.4706, 1.4266, -0.3748, 1.7167],
# [-0.5562, 0.6225, 1.2637, -2.2184, -0.0277],
# [-0.3011, -0.1465, 0.7531, -0.8896, -1.4539],
# [-2.0891, 0.2769, -1.3625, 1.0822, 0.9978]])
# tensor([[-1.0000e+09, -1.4706e+00, -1.0000e+09, -3.7477e-01, -1.0000e+09],
# [-5.5623e-01, -1.0000e+09, -1.0000e+09, -2.2184e+00, -2.7737e-02],
# [-3.0106e-01, -1.4646e-01, -1.0000e+09, -8.8957e-01, -1.4539e+00],
# [-2.0891e+00, -1.0000e+09, -1.3625e+00, -1.0000e+09, -1.0000e+09]])
论文中使用的多头注意力机制流程图为:
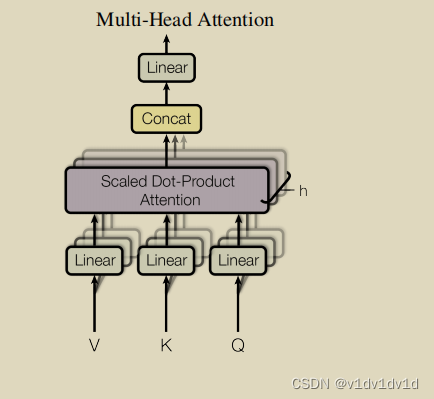
# 实现多头注意力机制及残差网络和 layer norm
class MultiHeadAttention(nn.Module):
def __init__(self,n_head,d_model,d_k,d_v,dropout = 0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
# d_model = 嵌入向量维度大小
# q, k, v 经过Linear层第三维大小从d_model分别变成 d_k*n_head,d_k*n_head,d_v*n_head
self.w_qs = nn.Linear(d_model,d_k * n_head,bias=False)
self.w_ks = nn.Linear(d_model, d_k * n_head, bias=False)
self.w_vs = nn.Linear(d_model, d_v * n_head, bias=False)
self.fc = nn.Linear(n_head * d_v,d_model,bias=False)
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model,eps=1e-6)
def forward(self,q,k,v,mask=None):
# q :(batch_size,len,d_model)
# d_model == word_vector
d_k,d_v,n_head = self.d_k,self.d_v,self.n_head
sz_b = q.size(0)
len_q = q.size(1)
len_k = k.size(1)
len_v = v.size(1)
residual = q
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1)
q, attn = self.attention(q, k, v, mask=mask)
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
# 经过concat 后 q (batch_size,句子长度,n_head * d_v)
# 经过Linear 层使其变为(batch_size,句子长度,d_model)
q = self.dropout(self.fc(q))
q += residual
q = self.layer_norm(q)
# 经过多头注意力计算之后,q经过一个残差网络和layer_norm 输出到前馈神经网络中
return q, attn
2、数据从多头注意力机制流向前馈神经网络
# 注意力机制后面的mlp层
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_in, d_hid, dropout = 0.1 ):
super().__init__()
# d_in 为 d_model
# d_hid 论文中给的数值为:2048
self.w_1 = nn.Linear(d_in,d_hid)
self.w_2 = nn.Linear(d_hid,d_in)
self.lay_norm = nn.LayerNorm(d_in,eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self,x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.lay_norm(x)
return x
经过前馈神经网络之后的数据输入到下一个encoder block或者decoder中。
Decoder 跟Encoder一样,也是由若干个block组成,每一个block由三个部分组成。其中多头注意力层和前馈神经网络和Encoder中的对应部分一样。多出来的一部分为带掩码的多头注意力层。
1、Decoder的输入经过embedding、positional encoding和dropout的处理之后进入Decoder
#n_trg_vocab为输出词空间的大小
#n_position默认为200
#dropout为0.1
self.trg_word_emb = nn.Embedding(n_trg_vocab,d_word_vec,padding_idx=pad_idx)
self.position_enc = PositionalEncoding(d_word_vec,n_position=n_position)
self.dropout = nn.Dropout(p=dropout)
2、进入Decoder的数据依次通过若干个由带掩码的多头注意力层,多头注意力层和前馈神经网络组成的block
class DecoderLayer(nn.Module):
def __init__(self,d_model,d_inner,n_head,d_k,d_v,dropout=0.1):
super(DecoderLayer, self).__init__()
#第一个注意力层
self.slf_attn = MultiHeadAttention(n_head,d_model,d_k, d_v, dropout=dropout)
#第二个注意力层
self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
#前馈神经网络
self.pos_ffn = PositionwiseFeedForward(d_model,d_inner,dropout=dropout)
def forward(self,dec_input,enc_output,
slf_attn_mask=None,dec_enc_attn_mask=None):
#************************************************************
# transformer中有三个位置需要mask,其中encoder和decoder中的输入端,由于
# 我们为了方便计算给句子填入了很多padding,所以我们要消除padding的影响,所以
#需要用到mask将padding的部分消除掉,具体的方法就是给padding的位置赋值-1e9,使得在
# softmax中尽可能取到较小的值
# decoder中mutil_head_self_attention中需要用到mask。因为在测试验证阶段,
#模型并不知道当前时刻的输入和未来时刻的单词信息。也就是对于一个序列中的第i个token解码的时
#候只能够依靠i时刻之前(包括i)的的输出,而不能依赖于i时刻之后的输出。
#************************************************************
# dec_input (batchsize,"句子长度2"(该句子长度可能和encoder中的句子长度不相等),d_model)
dec_output,dec_slf_attn = self.slf_attn(dec_input,dec_input,dec_input,
mask = slf_attn_mask)
#dec_slf_attn 表示decoder输入的向量之间的相似关系。
#dec_output (batchsize,句子长度2,d_model)
#enc_output (batchsize,句子长度,d_model)
# Q K V
# 注意:由论文中的流程图可以看出,第二个注意力层中的Q,K,V 分别对应decoder的第一层注
#意力层的输出,encoder最后的输出,encoder最后的输出。
dec_output,dec_enc_attn = self.enc_attn(dec_output,enc_output,enc_output,
mask = dec_enc_attn_mask)
# dec_enc_attn (batch_size, n_head, decoder的句子长度, encoder的句子长度)
# 其表示decoder的输出和encoder的输出之间的相似关系
# dec_output 经过linear将最后一维由n_head * d_v变成
# d_model最后通过resnet和layer_norm 进入前馈神经网络中 (batchsize,句子长2,d_model)
dec_output = self.pos_ffn(dec_output)
# 最后dec_output经过liner、resnet和layer_norm输出 (batchsize,句子长度2,d_model)
return dec_output,dec_slf_attn,dec_enc_attn
数据通过若干个decoder block块之后,数据通过一个linear层将最后一维由d_model 变成n_trg_vocab(目标向量的维度大小),最后通过softmax输出结果















 599
599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









