







1 前言
众所周知,协同过滤算法是完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息就可以实现推荐,是一个可解释性很强, 非常直观的模型, 但是也存在一些问题。但是协同过滤当中依旧存在着很多问题。
1.1 协同过滤处理稀疏矩阵的能力太差了。
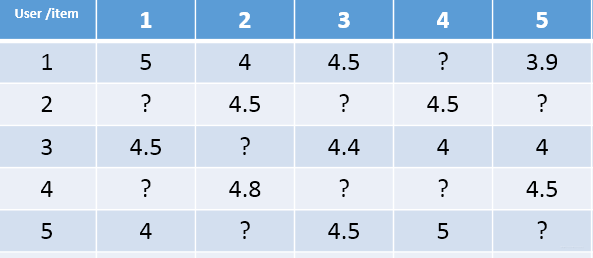
在真实的数据集当中,用户和商品的数量是很多的,因此用户与商品之间很多时候都是没有交互信息的。就比如小明作为用户,假设商品有1亿但是小明一生当中所购买过的商品数量可能不足10W因此有很多交互信息是为0的,所以在真实的数据集当中,这个矩阵是一个系数矩阵。
就比如下图
1.2 协同过滤当中相似度矩阵维护难度较大
在真实的数据集当中,若采用协同过滤算法,我们应该主要维护两个矩阵,即用户相似度矩阵(m x m)和 商品相似度矩阵(n x n)
我们可以简单的计算一下维护的数量级为mxm+nxn,假设有1000W个用户 1亿个商品。那么这维护的结果的数字是很庞大的,难以计算。
因此有人提出了矩阵分解算法。矩阵分解算法在2006年Netfix的推荐算法大赛中大放异彩, 并开始流行, 它的核心思想是通过隐含特征来联系用户兴趣和物品, 首先会解释一下我们总说的隐语义到底是啥意思,这个词语总是感觉会比较抽象, 这个其实类似于NLP里面的embedding, 那么我后面会举一个例子, 让它变得具体一些。
2 隐语义模型
隐语义模型最早在文本领域被提出,用于找到文本的隐含语义。在2006年, 被用于推荐中, 它的核心思想是通过隐含特征(latent factor)联系用户兴趣和物品(item), 基于用户的行为找出潜在的主题和分类, 然后对item进行自动聚类,划分到不同类别/主题(用户的兴趣)。这么说可能有点抽象,所以下面拿项亮老师《推荐系统实践》里面的那个例子看一下:
如果我们知道了用户A和用户B两个用户在豆瓣的读书列表, 从他们的阅读列表可以看出,用户A的兴趣涉及侦探小说、科普图书以及一些计算机技术书, 而用户B的兴趣比较集中在数学和机器学习方面。 那么如何给A和B推荐图书呢?
先说说协同过滤算法, 这样好对比不同:
- 对于UserCF,首先需要找到和他们看了同样书的其他用户(兴趣相似的用户),然后给他们推荐那些用户喜欢的其他书。
- 对于ItemCF,需要给他们推荐和他们已经看的书相似的书,比如作者B看了很多关于数据挖掘的书,可以给他推荐机器学习或者模式识别方面的书。
而如果是隐语义模型的话, 它会先通过一些角度把用户兴趣和这些书归一下类, 当来了用户之后, 首先得到他的兴趣分类, 然后从这个分类中挑选他可能喜欢的书籍。
那下面依然是解密如何通过隐含特征把用户的兴趣和物品分类的:我们下面拿一个音乐评分的例子来看一下隐特征矩阵的含义。
假设每个用户都有自己的听歌偏好, 比如A喜欢带有小清新的, 吉他伴奏的, 王菲的歌曲,如果一首歌正好是王菲唱的, 并且是吉他伴奏的小清新, 那么就可以将这首歌推荐给这个用户。 也就是说是小清新, 吉他伴奏, 王菲这些元素连接起了用户和歌曲。 当然每个用户对不同的元素偏好不同, 每首歌包含的元素也不一样, 所以我们就希望找到下面的两个矩阵:
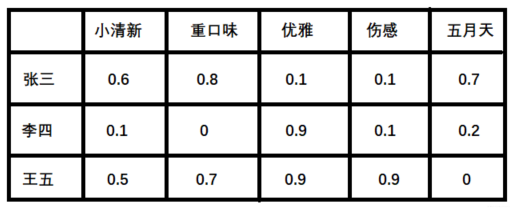
潜在因子—— 用户矩阵Q
这个矩阵表示不同用户对于不同元素的偏好程度, 1代表很喜欢, 0代表不喜欢, 比如下面这样:
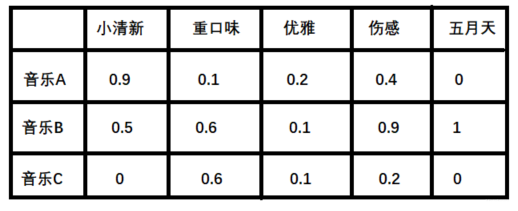
潜在因子——音乐矩阵P
表示每种音乐含有各种元素的成分, 比如下表中, 音乐A是一个偏小清新的音乐, 含有小清新的Latent Factor的成分是0.9, 重口味的成分是0.1, 优雅成分0.2…
利用上面的这两个矩阵, 我们就能得出张三对音乐A的喜欢程度:
张三对小清新的偏好 * 音乐A含有小清新的成分 + 张三对重口味的偏好 * 音乐A含有重口味的成分 + 张三对优雅的偏好 * 音乐A含有优雅的成分…,
在NLP当中下图就叫作隐向量
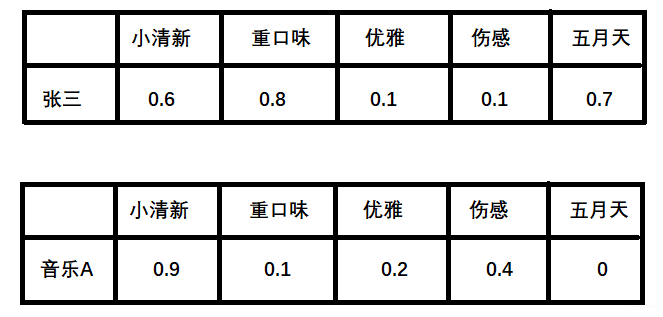
根据隐向量其实就可以得到张三对音乐A的打分,即:
0.6∗0.9+0.8∗0.1+0.1∗0.2+0.1∗0.4+0.7∗0=0.69
最后我们可以得到评分矩阵
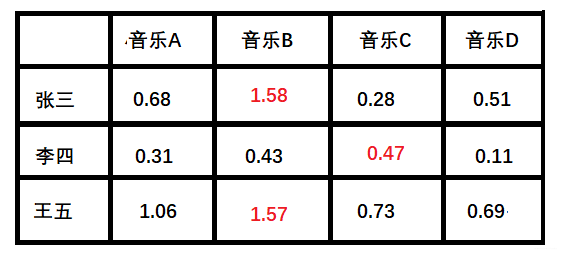
3 矩阵分解的知识
由于真实的数据集当中的矩阵大部分是缺失的,因此我们就拿王喆老师《深度学习推荐系统》的那个图来看一下矩阵分解的过程:
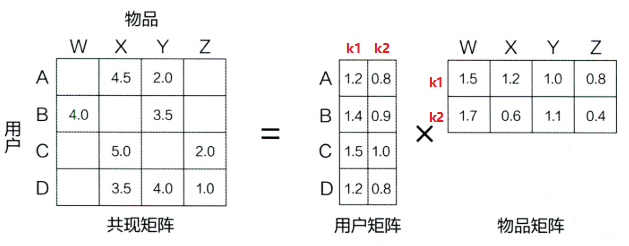

4 Basic SVD
这里其实就和训练模型的思路差不多, 我们拿到了一个用户物品的评分矩阵, 而我们要去计算两个参数矩阵U和V, 我们就可以用求解神经网络模型参数的思路计算这两个矩阵:
首先先初始化这两个矩阵
把用户评分矩阵里面已经评过分的那些样本当做训练集的label, 把对应的用户和物品的隐向量当做features, 这样就会得到(features, label)相当于训练集
通过两个隐向量乘积得到预测值pred
根据label和pred计算损失
然后反向传播, 通过梯度下降的方式,更新两个隐向量的值
未评过分的那些样本当做测试集, 通过两个隐向量就可以得到测试集的label值
这样就填充完了矩阵, 下一步就可以进行推荐了
具体的公式推导




import random
import math
class LFM(object):
def __init__(self, rating_data, F, alpha=0.1, lmbd=0.1, max_iter=500):
"""
:param rating_data: rating_data是[(user,[(item,rate)]]类型
:param F: 隐因子个数
:param alpha: 学习率
:param lmbd: 正则化
:param max_iter:最大迭代次数
"""
self.F = F
self.P = dict() # R=PQ^T,代码中的Q相当于博客中Q的转置
self.Q = dict()
self.alpha = alpha
self.lmbd = lmbd
self.max_iter = max_iter
self.rating_data = rating_data
'''随机初始化矩阵P和Q'''
for user, rates in self.rating_data:
self.P[user] = [random.random() / math.sqrt(self.F)
for x in range(self.F)]
for item, _ in rates:
if item not in self.Q:
self.Q[item] = [random.random() / math.sqrt(self.F)
for x in range(self.F)]
print(self.P)
def train(self):
"""
随机梯度下降法训练参数P和Q
:return:
"""
for step in range(self.max_iter): #遍历次数max_iter
for user, rates in self.rating_data:
for item, rui in rates:
hat_rui = self.predict(user, item) #预测得分
err_ui = rui - hat_rui #计算误差
for f in range(self.F): #梯度下降更新
self.P[user][f] += self.alpha * (err_ui * self.Q[item][f] - self.lmbd * self.P[user][f])
self.Q[item][f] += self.alpha * (err_ui * self.P[user][f] - self.lmbd * self.Q[item][f])
self.alpha *= 0.9 # 每次迭代步长要逐步缩小
def predict(self, user, item):
"""
:param user:
:param item:
:return:
预测用户user对物品item的评分
"""
return sum(self.P[user][f] * self.Q[item][f] for f in range(self.F))
if __name__ == '__main__':
'''用户有A B C,物品有a b c d'''
rating_data = list()
rate_A = [('a', 2.0), ('b', 1.0)]
rating_data.append(('A', rate_A))
rate_B = [('b', 1.0), ('c', 1.0)]
rating_data.append(('B', rate_B))
rate_C = [('c', 1.0), ('d', 1.0)]
rating_data.append(('C', rate_C))
lfm = LFM(rating_data, 2)
lfm.train()
for item in ['a', 'b', 'c', 'd']:
print(item, lfm.predict('A', item)) # 计算用户A对各个物品的喜好程度















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









