







大家早上好,本人姓吴,如果觉得文章写得还行的话也可以叫我吴老师。欢迎大家跟我一起走进数据分析的世界,一起学习!
感兴趣的朋友可以关注我或者我的数据分析专栏,里面有许多优质的文章跟大家分享哦。
目录
推荐收藏的Hive语言大全
必须要看的前言
收藏本篇文章,意味着你拥有了一份超级完善的Hive语言书籍。本篇博客涵盖了几乎所有MySQL知识点,文末也给出了一些编写Hive时的一些优化建议。你也可以把这篇博客当作一本小“词典”,遇到遗忘了的知识点也随时可以查阅。总而言之,希望大家喜欢这篇博客,也更希望这篇博客能给大家带来帮助。
一、入门需知
1 创建数据库
1.1 创建数据库
create database if not exists csdn_test;
其中if not exists可以不写,但如果已经存在了csdn_test这个数据库就会报错。
1.2 查看数据库
show databases;
1.3 删除数据库
删除空数据库 drop database 数据库名;
drop database csdn_test;
为防止删除的数据库不存在发生报错,最好采用if exists判断数据库是否存在。
drop database if exists csdn_test;
如果数据库不为空,但又想删除怎么办?在最后加个cascade。
drop database csdn_test cascade;
1.4 进入数据库
use csdn_test;
2 Hive数据类型
2.1 数字类
| 类型 | 长度 | 备注 |
|---|---|---|
| TINYINT | 1字节 | 有符号整型 |
| SMALLINT | 2字节 | 有符号整型 |
| INT | 4字节 | 有符号整型 |
| BIGINT | 8字节 | 有符号整型 |
| FLOAT | 4字节 | 有符号单精度浮点数 |
| DOUBLE | 8字节 | 有符号双精度浮点数 |
| DECIMAL | – | 可带小数的精确数字字符串 |
1字节可以存8个0/1。
2.2 日期时间类
| 类型 | 长度 | 备注 |
|---|---|---|
| TIMESTAMP | – | 时间戳,内容格式:yyyy-mm-dd hh:mm:ss[.f…] |
| DATE | – | 日期,内容格式:YYYY- MM- DD |
| INTERVAL | – | – |
这里的时间戳可以理解为离具体指定的某个时间点相差的时间(精确到秒)。
2.3 字符串类
| 类型 | 长度 | 备注 |
|---|---|---|
| STRING | – | 字符串 |
| VARCHAR | 字符数范围1 - 65535 | 长度不定字符串 |
| CHAR | 最大的字符数:255 | 长度固定字符串 |
2.4 Misc类
| 类型 | 长度 | 备注 |
|---|---|---|
| BOOLEAN | – | 布尔类型 TRUE/FALSE |
| BINARY | – | 字节序列 |
2.5 复合类
| 类型 | 长度 | 备注 |
|---|---|---|
| ARRAY | – | 包含同类型元素的数组,索引从0开始 ARRAY<data_type> |
| MAP | – | 字典 MAP<primitive_type, data_type> |
| STRUCT | – | 结构体 STRUCT<col_name : data_type [COMMENT col_comment],…> |
| UNIONTYPE | – | 联合体UNIONTYPE<data_type, data_type, …> |
这些的联合体需要说一下,MAP类型就像Python中的DICT字典型数据,都是一个关键字key对应一个关键值value;UNIONTYPE 类型的数据可以存放任何数据,包括字符串类、数组型和MAP型等。后面会有例子详细说明。
3 Hive建表
首先需要说明的是,Hive建表的时候可以选择建立内部表或者是外部表。而内部表和外部表的区别主要如下。
- 从数据管理来看,内部表主要是由Hive自身管理,而外部表需要由HDFS管理;
- 从数据存储的位置来看,内部表数据是在/user/hive/warehouse,外部表则是可以通过LOCATION关键词来指定存储位置,不然默认也是和内部表存储位置相同;
- 从删除表来看,删除内部表时可以直接删除元数据及存储数据,而删除外部表仅仅会删除元数据;
- 从修改表来看,内部表的修改会直接同步给元数据,而外部表需要进行修复操作(MSCK REPAIR TABLE table_name;)
3.1 直接建表法
先给大家列一个建表的语句格式:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
看着有点乱?没关系,我们待会会一个个提到。
注意下面语句中如果已存在相同名字的表,会报错。
create table test_Create_Table(id int,name string);
--查看当前库表名
show tables;
--查看建表信息
show create table test_Create_Table;
--查看表结构
desc test_Create_Table;
和创建数据库一样,IF NOT EXIST可以忽略同名表的异常问题。
create table if not exists test_Create_Table(id int,name string);
EXTERNAL ,可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
--不指定路径,同内表路径一致
create external table test_External_Table(id int,name string);
--指定路径创建外部表(要求为新建路径)
create external table test_External_Location(id int, name string) location '/new_dir';
LIKE,可以复制表的结构,但注意并没有复制表中的数据。感觉很容易理解:创建一个像…的表。
create table test_like like test_create_table;
COMMENT,就是给表或者字段添加描述。
create table table_Comment(id int comment '编号',name string comment '姓名') comment '员工信息表';
PARTITIONED BY,用于指定分区,后文会详细讲解分区和分桶。
ROW FORMAT,这里是指行数据的格式,后文也会专门讲解。
STORED AS,如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCE 。
LOCATION,指定表在HDFS的存储路径。
CLUSTERED,表示的是按照某列聚类,例如在插入数据中有两项“张三,数学”和“张三,英语”。若是CLUSTERED BY name,则只会有一项,“张三,(数学,英语)”,这个机制也是为了加快查询的操作。
3.2 查询建表法
create table NewTableBySelect as select * from test_create_table;
需要注意的是,这里select 中选取的列名会作为新表的列名(所以通常是要取别名),会改变表的属性、结构,比如只能是内部表、分区分桶也没了;另外,select 中选取的列名会作为新表的列名(所以通常是要取别名),会改变表的属性、结构,比如只能是内部表、分区分桶也没了。同时,目标表不允许使用外部表,会报错创建的表存储格式会变成默认的格式 TEXTFILE ,不过可以指定表的存储格式,行和列的分隔符等。
3.3 like建表法
这里在3.1 介绍like的时候说过了。
反正大体上建表就是这几种方法,大家要先掌握好。
4 分隔符
4.1 字段分隔符
语法:fields terminated by '\t' (hive 默认的字段分隔符为ascii码的控制符 \001 ctrl + V+A)
--设置字段分隔符
create table test_delimit(id int, name string) row format delimited fields terminated by '^B';
--查看字段分隔符
desc formatted test_delimit;
我们可以运行看一下。

可以看到,这里的分隔符信息出现了我们设置好的^B。当然,你想设置啥都可以。
4.2 array 类型成员分隔符
语法:collection items terminated by ','
数组分分隔符一般都是设置为逗号。
我们运行个例子看看结果。
已知"C:\Users\24721\Desktop\"目录下的data1.txt文件内容为:
123|华为Mate10|1235,345
456|华为Mate30|89,635
789|小米5|452,63
1235|小米6|785,36
4562|OPPO Findx|7875,3563
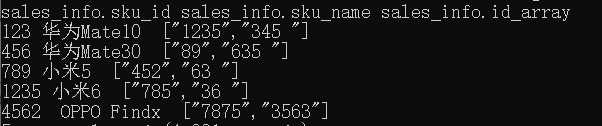
现在我们要做的就是建立一个表,并且把这个文件中的数据正常导入到该表中,具体实现代码如下。
--指定 |为字段分隔符 ,为数组分隔符
create table sales_info(
sku_id string comment '商品id',
sku_name string comment '商品名称',
id_array array<string> comment '商品相关id列表')
row format delimited fields terminated by '|'
collection items terminated by ',' ;
--装载本地文件到 sales_info中
load data local inpath "C:\Users\24721\Desktop\data1.txt" overwrite into table sales_info;
--通过查询语句查看数据
select * from sales_info;
结果如下:
4.3 map:Key和Value之间的分隔符
语法:map keys terminated by ':'
我们在举一个例子:已知"C:\Users\24721\Desktop\"下的data2.txt中的内容如下:
123|华为Mate10|id:1111,token:2222,user_name:zhangsan1
456|华为Mate30|id:1113,token:2224,user_name:zhangsan3
789|小米5|id:1114,token:2225,user_name:zhangsan4
1235|小米6|id:1115,token:2226,user_name:zhangsan5
4562|OPPO Findx|id:1116,token:2227,user_name:zhangsan6
现在我们要做的就是建立一个表,并且把这个文件中的数据导入到该表中,具体实现代码如下。
--创建含有map类型的数据表
create table mapkeys(
sku_id string comment '商品id',
sku_name string comment '商品名称',
state_map map<string,string> comment '商品状态信息')
row format delimited
fields terminated by '|'
map keys terminated by ':';
--将本地data2.txt数据加载到mapkeys表
load data local inpath "C:\Users\24721\Desktop\data2.txt" overwrite into table mapkeys;
--查看表内数据是否与文件一致
select * from mapkeys;
运行结果如下:

如图,建表插入数据成功。
但大家仔细看的话可以发现,state_map字段中的只有一个key(“id”),剩下全被当作value。这很明显不是我们最终想要的。那怎么办,我们可以加上一个collection items terminated by ','。
具体如下:
--创建含有map类型的数据表
create table mapkeys2(
sku_id string comment '商品id',
sku_name string comment '商品名称',
state_map map<string,string> comment '商品状态信息')
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':';
--将本地data2.txt数据加载到mapkeys表
load data local inpath "C:\Users\24721\Desktop\data2.txt" overwrite into table mapkeys2;
--查看表内数据是否与文件一致
select * from mapkeys2;

此时的结果才是我们想要的。
4.4 行分隔符
语法:lines terminated by '\n'。
建表时得放在最后,不过这个建表时一般没有人写上去,因为目前默认"\n"同时也只支持"\n"。
4.5 使用多字符作为分隔符
- 使用MultiDelimitSerDe的方法来实现
--创建多分隔符表
CREATE TABLE test_MultiDelimit(id int, name string ,tel string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe' WITH SERDEPROPERTIES ("field.delim"="##")
STORED AS TEXTFILE;
--查看表
desc formatted test_MultiDelimit;
运行结果如下:

- 使用RegexSerDe的方法实现,但注意RegexSerDe仅支持字符串类型的,不能有其他类型。
CREATE TABLE test1(id string, name string ,tel string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES ("input.regex" = "^(.*)\\#\\#(.*)$")
STORED AS TEXTFILE;
5 分区表创建
这部分是我在上一篇博客中的Hive数据模型就提到了的,可以说着部分是Hive较为特色的部分。
5.1 使用分区表的意义
使用分区表的意义大致如下:使用分区技术,避免hive全表扫描,提升查询效率;同时能够减少数据冗余进而提高特定(指定分区)查询分析的效率。
注意,在逻辑上分区表与未分区表没有区别,在物理上分区表会将数据按照分区键的列值存储在表目录的子目录中,目录名为“分区键=键值”。你可以把建立分区想象成我建了个文件夹,把一些相似(或者说你想要的类型)的数据存放到文件夹中。
分区表这么好用,所以查询时尽量利用分区字段。如果不使用分区字段,就会全部扫描。
5.2 分区表类型
分区表类型:静态分区和动态分区。区别在于前者是我们手动指定的,后者是通过数据来判断分区的。
5.3 建立分区
静态分区和动态分区的建表语句是一样的。
注意:PARTITIONED BY ()括号中指定的分区名不能跟表中的字段名一样。
-- 创建分区表 PARTITIONED BY (分区字段名 分区字段类型)
create table test_partition1(
sku_id string comment '商品id',
sku_name string comment '商品名称')
PARTITIONED BY (sku_class string);
--建立分区表之后,此时没有数据,也没有分区,需要建立分区
--创建分区
alter table test_partition1 add partition(sku_class='xiaomi') ;
--查看表现有分区
show partitions test_partition1;

此时分区test_partition1以及建好。
当然,我们可以通过多字段分区,具体如下。
-- 创建分区表 PARTITIONED BY (分区字段名 分区字段类型,分区字段名2 分区字段类型2) 多字段分区
create table test_partition_mul(
sku_id string comment '商品id',
sku_name string comment '商品名称')
PARTITIONED BY (sku_class string,sku_lable string);
--添加分区
alter table test_partition_mul add IF NOT EXISTS
partition(sku_class='xiaomi',sku_lable='dianzi');
--查看现有分区
show partitions test_partition_mul;

此时分区test_partition_mul以及建好。
往静态分区添加数据的语句如下:
insert into table test_partition_mul
partition(sku_class='xiaomi',sku_lable='dianzi') values('001','xiaomi1');
insert into table test_partition_mul
partition(sku_class='xiaomi',sku_lable='dianzi') select sku_id,sku_name from sales_info;
不过使用insert插入数据的速度往往会偏慢,大家可以采用load data的方法加载本地文件到分区表中。
load data local inpath '本地文件路径' into table test_partition partition (sku_class='xiaomi',sku_lable='dianzi');
动态分区插入数据的方法如下:
insert into table test_partition_mul partition(sku_class,sku_lable) values ('001','xiaomi2','xiaomi','dianzi');
5.4 删除分区 drop
语法:alter table 表名 drop partition(分区字段名=取值);
alter table test_partition1 drop partition(sku_class='xiaomi');
--查看分区:
show partitions test_partition1;

此时说明删除成功。
6 分桶表创建
为什么要有分桶技术?分桶是啥意思,有啥作用?分区和分桶的区别有哪些?
这就给你一一解答。
- 当单个分区或者表中的数据量越来越大的时候,分区不能更细粒地划分数据时,可以采用分桶技术进行更细粒度的划分和管理;
- 分桶的实质其实就是对分桶的字段做了hash,然后存放到对应的文件中;
- 分桶可以提高join查询效率,方便进行抽样;
至于分桶和分区的区别呢,主要有一下几个地方:
- 分区使用的是表外字段,而分桶使用的是表内字段(也就是说分区时分区名不能取表字段名,而分桶是得指定表字段名吗);
- 分桶是更细粒度的划分、管理数据,更多用来做数据抽样、JOIN操作;
- 分桶随机分割数据库,而分区是非随机分割数据库;
- 分桶是对应不同的文件(细粒度),而分区是对应不同的文件夹(粗粒度);
- 普通表(外部表、内部表)、分区表这三个都是对应HDFS上的目录,同表对应的是目录里的文件。
如果到这没听懂,没关系,接着往下看。
语法:create table 表名(字段1 类型1,字段2,类型2 ) clustered by(表内字段) sorted by(表内字段) into 分桶数 buckets
--创建分桶表
create table test_buckets(
sku_id string comment '商品id',
sku_name string comment '商品名称')
clustered by(sku_id) into 3 buckets;
但记得先设置自动分桶开关:
set hive.enforce.bucketing=true;
添加数据到分桶表:
insert into test_buckets select sku_id,sku_name from sales_info;
7 非hive环境下执行hql
虽然内容很简单,但是还是得介绍一下。
怎么执行一堆命令,可以将hql语句放到一个文件中,采用hive -f "文件路径"即可,注意这个是在非hive环境下运行。
而hive -e "hql语句"则是直接执行hive语句。
二、Hive操作语言
1 加载数据
1.1 从本地装载数据
这个其实在前面也已经提到了。
普通表:load data local inpath '数据文件路径' [overwrite] into table 表名 ;
其中overwrite表示覆盖原有数据,没有的话则表示添加数据。
load data local inpath 'E:hadoop/datas/payments.txt' into table payments;
分区表:load data local inpath '数据文件路径' [overwrite] into table 表名 partition (分区字段=值);
load data local inpath 'E:hadoop/datas/product_category_level1.txt' into table product_category partition(level=1);
分桶表:load data local inpath '数据文件路径' [overwrite] into table 表名;
--开启分桶功能
set hive.enforce.bucketing=true;
-- 忽略掉安全检查
hive.strict.checks.bucketing=false;
load data local inpath 'E:hadoop/datas/shop.txt' into table shops;
1.2 从HDFS加载数据
- cmd上传到HDFS文件系统中。
语法:hdfs dfs -put 本地文件路径 hdfs路径
hdfs dfs -put "C:\Users\24721\Desktop\product_info.txt" "/datas"
- 文件数据加载到Hive表中。
语法:load data inpath 'hdfs数据文件路径' into table 表名;
load data inpath '/datas/product_info.txt' into table product_info;
同理分区表要指定分区,分桶表与普通表加载数据一样。
2 插入数据
2.1 普通表
语法:insert into 表名 values(值)或者insert overwrite 表名 values(值)。
2.2 分区表
静态分区:
insert into test_partition1 partition(sku_class="xiaomi") values(1,'sku_new');
动态分区:
insert into test_partition1 partition(sku_class) values(1,'sku_new','苹果');
2.3 分桶表
语法:insert into 分桶表表名
insert into test_buckets values(1,'sku_new');
3 导出数据
3.1 导出到本地文件系统
语法:INSERT OVERWRITE LOCAL DIRECTORY '文件夹路径' ROW FORMAT DELIMITED FIELDS TERMINATED by '字段分隔符' 查询语句;
PS: 会重写指定文件夹 (一定要小心覆盖掉有用的文件),有新建文件夹功能, 导出的文件都名都为000000_0。另外,默认分隔符是用系统指定的,和本身建表语句指定的没有关系。
INSERT OVERWRITE LOCAL DIRECTORY 'E:/hadoop/datas/test_output' ROW FORMAT DELIMITED FIELDS TERMINATED by '\t' select * from sales_info;
3.2 导出到HDFS
语法:INSERT OVERWRITE DIRECTORY '文件夹路径' 查询语句;
与导出到本地文件系统相比,少了个local。
4 删除表
4.1 删除所有数据
语法:truncate table 表名
使用truncate仅可删除内部表数据,不可删除表结构。
(就相当于你有个房子,现在只是把里面的东西都搬走,但是房子的架构啥的都没变)。
truncate table byselect;
使用cmd删除外部表数据(hdfs dfs -rm -r 外部表路径):
hdfs dfs -rm -r /datas/test_Exteranl/*
4.2 删除表部分数据
有partition表
- 删除具体partition
语法:alter table table_name drop partition(partiton_name='value'))
--查看数据
select * from test_partition1;
show partitions test_partition1;
--删除指定分区
alter table test_partition1 drop partition(sku_class = 'xiaomi');
- 删除partition内的部分信息(
INSERT OVERWRITE TABLE)
INSERT OVERWRITE TABLE test_partition_mul
PARTITION(sku_class='xiaomi',sku_lable='dianzi')
SELECT sku_id,sku_name FROM test_partition_mul
WHERE sku_id='1235';
重新把对应的partition信息写一遍,通过WHERE 来限定需要留下的信息,没有留下的信息就被删除了。
无partiton表
语法:INSERT OVERWRITE TABLE 表名 SELECT * FROM 表名 WHERE 条件;。
--插入测试数据
insert into sales_info(sku_id,sku_name) values(1,'a');
--删除不为2的数据
insert overwrite table sales_info(sku_id,sku_name) select sku_id,sku_name from sales_info where sku_id='2';
删除整个表
使用drop可删除整个表(drop table 表名)
drop table test_external;
三、Hive查询语言
1 内置运算符
1.1 关系运算符
| 运算符 | 操作 | 描述 |
|---|---|---|
| A = B | 所有基本类型 | 如果表达A等于表达B,结果TRUE ,否则FALSE。 |
| A != B | 所有基本类型 | 如果A不等于表达式B表达返回TRUE ,否则FALSE。 |
| A < B | 所有基本类型 | 如果表达式A小于表达式B为TRUE,否则FALSE。 |
| A <= B | 所有基本类型 | 如果表达式A小于或等于表达式B为TRUE,否则FALSE |
| A > B | 所有基本类型 | 如果表达式A大于表达式B为TRUE,否则FALSE。 |
| A >= B | 所有基本类型 | 如果表达式A大于或等于表达式B为TRUE,否则FALSE。 |
| A [NOT] BETWEEN B AND C | 基本数据类型 | 如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可达到相反的效果。 |
| A IS [NOT] NULL | 所有类型 | 如果A等于NULL,则返回TRUE,反之返回FALSE, NOT 正好相反。 |
| A IN(数值1, 数值2) | 所有类型 | 如果A存在指定的数据中,则返回TRUE,反之返回FALSE。 |
| A [NOT] LIKE B | 字符串 | 如果A与B匹配的话,则返回TRUE;反之返回FALSE。%代表任意多个字符,_代表一个字符 % _。 |
| A RLIKE B | 字符串 | 如果A或B为NULL;如果A任何子字符串匹配Java正则表达式B;否则FALSE。 |
| A REGEXP B | 字符串 | 等同于RLIKE。 |
1.2 算术运算符
| 运算符 | 操作 | 描述 |
|---|---|---|
| A + B | 所有数字类型 | A加B的结果 |
| A - B | 所有数字类型 | A减去B的结果 |
| A / B | 所有数字类型 | A除以B的结果 |
| A % B | 所有数字类型 | A除以B.产生的余数 |
1.3 逻辑运算符
| 运算符 | 操作 | 描述 |
|---|---|---|
| A AND B | boolean | 如果A和B都是TRUE,否则FALSE。 |
| A && B | boolean | 类似于 A AND B. |
| A OR B | boolean | TRUE,如果A或B或两者都是TRUE,否则FALSE。 |
| A || B | boolean | 类似于 A OR B. |
| NOT A | boolean | TRUE,如果A是FALSE,否则FALSE。 |
| !A | boolean | 类似于 NOT A. |
1.4 复杂的运算符
| 运算符 | 操作 | 描述 |
|---|---|---|
| A[n] | A是一个数组,n是一个int | 它返回数组A的第n个元素,第一个元素的索引0。 |
| M[key] | M 是一个 Map<K, V> key 的类型为K | 它返回对应于映射中关键字的值。 |
| S.x | S 是一个结构 | 它返回S的s字段 |
2 内置函数
2.1 数学函数
| 返回类型 | 签名 | 描述 |
|---|---|---|
| BIGINT DOUBLE | round(double a) round(double a, int d) | 返回double类型的整数值部分 (遵循四舍五入) 返回指定精度d的double类型 |
| BIGINT | floor(double a) | 返回等于或者小于该double变量的最大的整数 |
| BIGINT | ceil(double a) | 返回等于或者大于该double变量的最小的整数 |
| DOUBLE | rand() rand(int seed) | 返回一个0到1范围内的随机数。如果指定种子seed,则会等到一个稳定的随机数序列. |
| DOUBLE | pow(double a, double p) | 返回a的p次幂 |
| DOUBLE | sqrt(double a) | 返回a的平方根 |
| DOUBLE INT | abs(double a) abs(int a) | 返回数值a的绝对值 |
2.2 日期函数
| 返回类型 | 签名 | 描述 |
|---|---|---|
| STRING | from_unixtime(bigint unixtime[, string format]) | 转化UNIX时间戳(从1970-01-01 00:00:00 UTC到指定时间的秒数) 到当前时区的时间格式 |
| BIGINT | unix_timestamp() unix_timestamp(string date) unix_timestamp(string date, string pattern) | 获得当前时区的UNIX时间戳 转换格式为"yyyy-MM-dd HH:mm:ss"的日期到UNIX时间戳。如果转化失败,则返回0 转换pattern格式的日期到UNIX时间戳。如果转化失败,则返回0 |
| STRING | to_date(string timestamp) | 返回日期时间字段中的日期部分 |
| INT | year(string date) month (string date) day (string date) | 分别返回日期中的年 月 天 |
| INT | hour (string date) minute (string date) second (string date) | 分别返回日期中的时 分 秒 |
| INT | weekofyear (string date) | 返回日期在当年的第几周 |
| INT | datediff(string enddate, string startdate) | 返回结束日期减去开始日期的天数 日期有格式要求 yyyy-mm-dd hh:MM:ss 或 yyyy-mm-dd |
| STRING | date_add(string startdate, int days) | 返回开始日期startdate增加days天后的日期 add_months(string startdate, int months) |
| STRING | date_sub (string startdate, int days) | 返回开始日期startdate减少days天后的日期 |
2.3 条件判断函数
| 返回类型 | 签名 | 描述 |
|---|---|---|
| T | if(boolean testCondition, T valueTrue, T valueFalseOrNull) | 当条件testCondition为TRUE时,返回valueTrue;否则返回valueFalseOrNull |
| T | coalesce(T v1, T v2, …) | 返回参数中的第一个非空值;如果所有值都为NULL,那么返回NULL |
| T | CASE a WHEN b THEN c [WHEN d THEN e] [ELSE f] END | 如果a等于b,那么返回c;如果a等于d,那么返回e;否则返回f |
| T | CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END | 如果a为TRUE,则返回b;如果c为TRUE,则返回 d;否则返回e |
2.4 字符串函数
| 返回类型 | 签名 | 描述 |
|---|---|---|
| INT | length(string A) | 返回字符串A的长度 |
| STRING | reverse(string A) | 返回字符串A的反转结果 |
| STRING | concat(string A, string B…) | 返回输入字符串连接后的结果,支持任意个输入字符串 |
| STRING | concat_ws(string SEP, string A, string B…) | 返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符 |
| STRING | substr(string A, int start),substring(string A, int start) substr(string A, int start, int len),substring(string A, int start, int len) | 返回字符串A从start位置到结尾的字符串 返回字符串A从start位置开始,长度为len的字符串 |
| STRING | upper(string A) ucase(string A) | 返回字符串A的大写格式 |
| STRING | lower(string A) lcase(string A) | 返回字符串A的小写格式 |
| STRING | trim(string A) ltrim(string A) rtrim(string A) | 去除字符串两边的空格 除字符串左边的空格 去除字符串右边的空格 |
| STRING | regexp_replace(string A, string B, string C) | 将字符串A中的符合java正则表达式B的部分替换为C |
| STRING | regexp_extract(string subject, string pattern, int index) | 将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符 |
| STRING | parse_url(string urlString, string partToExtract [, string keyToExtract]) | 返回URL中指定的部分。partToExtract的有效值为:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO. |
| STRING | get_json_object(string json_string, string path) | 解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL |
| STRING | space(int n) | 返回长度为n的空格字符串 |
| STRING | repeat(string str, int n) | 返回重复n次后的str字符串 |
| STRING | lpad(string str, int len, string pad) rpad(string str, int len, string pad) | 将str进行用pad进行左补足到len位 将str 进行用pad进行右补足到len位 |
| ARRAY | split(string str, string pat) | 按照pat字符串分割str,会返回分割后的字符串数组 |
| INT | find_in_set(string str, string strList) find_in_set(‘ab’,‘aa,ab,ac’) | 返回str在strlist第一次出现的位置,strlist是用逗号分割的字符串。如果没有找该str字符,则返回0 |
| INT | instr(string str, string substr) instr(“abcde”,“ab”) | 返回substr在str中第一次出现的位置,未出现则返回0(如果参数为NULL则返回NULL;位置从1开始) |
2.5 统计函数
| 返回类型 | 签名 | 描述 |
|---|---|---|
| INT | count(*), count(expr), count(DISTINCT expr[, expr_.]) | count(*)统计检索出的行的个数,包括NULL值的行;count(expr)返回指定字段的非空值的个数;count(DISTINCTexpr[, expr_.])返回指定字段的不同的非空值的个数 |
| DOUBLE | sum(col), sum(DISTINCT col) | sum(col)统计结果集中col的相加的结果;sum(DISTINCT col)统计结果中col不同值相加的结果 |
| DOUBLE | avg(col), avg(DISTINCT col) | avg(col)统计结果集中col的平均值;avg(DISTINCT col)统计结果中col不同值相加的平均值 |
| DOUBLE | min(col) max(col) | 统计结果集中col字段的最小值 统计结果集中col字段的最大值 |
| DOUBLE | var_pop(col) var_samp (col) | 统计结果集中col非空集合的总体方差 统计结果集中col非空集合的样本变量 |
| DOUBLE | stddev_pop(col) stddev_samp (col) | 统计结果集中col非空集合的总体标准差 统计结果集中col非空集合的样本标准差 |
| DOUBLE | percentile(BIGINT col, p) | 求准确的第p个百分位数,p必须介于0和1之间,但是col字段目前只支持整数,不支持浮点数类型 |
| ARRAY | percentile(BIGINT col, array(p1 [, p2]…)) | 功能和上述类似,之后后面可以输入多个百分位数,返回类型也为array,其中为对应的百分位数 |
2.6 复合类型构建访问函数
| 返回类型 | 签名 | 描述 |
|---|---|---|
| MAP | map (key1, value1, key2, value2, …) | 根据输入的key和value对构建map类型 |
| STRUCT | struct(val1, val2, val3, …) | 根据输入的参数构建结构体struct类型 |
| ARRAY | array(val1, val2, …) | 根据输入的参数构建数组array类型 |
| … | A[n] | 返回数组A中的第n个变量值。数组的起始下标为0。 |
| … | M[key] | 返回map类型M中,key值为指定值的value值 |
| … | S.x | 返回结构体S中的x字段 |
| INT | size(Map<K.V>) size(Array) | 返回map类型的长度 返回array类型的长度 |
| … | explode(map | array) |
| Array | collect_set ( col) | 对col行变列并 去重, |
| Array | collect_list ( col) | 对col行变列并 不去重, |
| Array | map_keys(map) | 取map类型的所有Key |
| Array | map_values(map) | 取map类型的所有value |
| T | array_contains(array,obj) | 判断指定的obj 是否村在数组中 |
3 Select 语句结构
语法如下:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]][ORDER BY col_list]
[LIMIT number];
hive语句的执行顺序:
from -->where --> select --> group by -->聚合函数–> having --> order by -->limit
- 全表查询 (select * from 表名)
select * from sales_info;
- 选择特定列查询(select col1,col2,… from 表名 )
select sku_id from sales_info;
- 列重命名(select col1 [as] ,… from 表名)
select sku_id as id from sales_info;
- 返回数组的第一个元素(索引从0开始)
select id_array[0] from sales_info;
- 查看数组中的每个元素
select explode(id_array) from sales_info;
- 数组各元素分行显示,并要有与只对应的sku_id,sku_name
select sku_id,sku_name, id_list from sales_info lateral view explode(id_array) ids as id_list;
--lateral view explode(数组字段) 虚拟表名 as 虚拟表字段
- 把test_hv 表 以sku_id 分组 id_list 转一列显示
select sku_id,collect_set(id_list) from test_HV group by sku_id; --set 集合去重
select sku_id,collect_list(id_list) from test_HV group by sku_id;--list 列表不去重
- 数组转与字符串互换
select *, split(concat_ws(',',id_array),',') from sales_info;
- 返回Map中key 为 id 的值
select state_map['id'] from mapkeys1
- 把map中Key ,value 分两列显示
select explode(state_map) from mapkeys1
- map各元素分行显示,并要有与只对应的sku_id,sku_name
select sku_id,sku_name, infokey,infovalue from mapkeys1 lateral view explode(state_map) infos as infokey,infovalue;
– 查看所有map中的value
select map_values(state_map) from mapkeys1;
- map中不存在指定Key 时 显示 “无”
select state_map['id'],if( state_map['user'] is null , '无',state_map['user']) from mapkeys1;
- 返回结构体中为age元素值
select basic_info.age from test_student;
3.1 Java正则
指代内容的符号:
- \w 指代字符(下划线,数字 ,字母), \W指代非字符(也就是和\w反过来)
- \d 指代数字(0-9), \D指代非数字
- . 指代任意字符
- \s 指代各种空白, \S同上。
- [内容] 包含指定内容,如 [A-Za-z]
- [^内容] 不包含指定的内容,如 [^\d]指除数字以外的任何字符,这里等同于\D。
指代个数的符号:
| 符号 | 代表个数 |
|---|---|
| * | 0-n |
| + | 1-n |
| ? | 0-1 |
| {n} | n |
| {n,} | 至少n |
| {,n} | 最多n |
| {n,m} | n-m |
举例补充:
| 符号 | 含义 |
|---|---|
| ^ | 字符开头 |
| $ | 字符结尾 |
| \d{11} | 11个数字 |
| [a-zA-Z0-9]{8,} | 有至少8个字母或者数字(而且是连续的) |
| ^A.* | 以A开头的任何字符 |
| .*8$ | 以8结尾的任何字符 |
| [A], A | A,A |
3.2 Select——Where
使用WHERE 子句,将不满足条件的行过滤掉。where 后是 关系运算 和 逻辑运算的不同组合。
– Sale_info表中Sku_Name 包含 字母A的
select * from sales_info where sku_name like '%A%';
–Sale_info表中 id_array 有id含有8的
select * from sales_info where concat_ws("",id_array) like '%8%';
select * from sales_info where concat_ws("",id_array) RLIKE '[8]';
select * from sales_info where concat_ws("",id_array) Regexp '8';
–mapkeys1 表中 state_map 中key 含有id的
select * from mapkeys1 where array_contains(map_keys(state_map),"id");
–mapkeys1 表中 state_map user_name 中包含zhang的
select * from mapkeys1 where state_map["user_name"] like "%zhang%";
–mapkeys1 表中姓张的并且名字只有两个字的
select * from mapkeys1 where state_map["user_name"] like "张_";
select * from mapkeys1 where state_map["user_name"] Rlike "^张.";'^张.'
select * from mapkeys1 where state_map["user_name"] Rlike "^张.{1}";
–mapkeys1 表中 state_map字段的 values 包含 A 的(不区分大小写)
select * from mapkeys1 where upper(concat_ws('',map_values(state_map))) like '%A%';
3.3 Select——Group By & 聚合函数
having与where不同点
| where | having |
|---|---|
| where针对表中的列发挥作用,查询数据 | having针对查询结果中的列发挥作用,筛选数据 |
| 不能写分组函数 | 可以使用分组函数 |
| 不受限制 | 只用于group by分组统计语句 |
–统计test_partition1 表中各 sku_class 的个数
select sku_class,count(*) from test_partition1 group by sku_class;
–统计test_student 表basic_info 各age的人数 并显示大于1 的年龄组
select basic_info.age, count(*) renshu from test_student
group by basic_info.age
having renshu > 1;
–mapkeys1 以map列中指定key 对应的值进行分组 并统计记录条数
select state_map["id"],sum(sku_id),count(1) from mapkeys1 group by state_map["id"];
–统计test_partition1 表中各分区记录并且找到大于1的分区
select sku_class,count(*) from test_partition1
group by sku_class
having count(*) > 1;
3.4 Select——Order By
| order by | sort by | distribute by | cluster by | |
|---|---|---|---|---|
| 作用 | order by会对输入做全局排序 | sort by 是单独在各自的reduce中进行排序 | 控制map 中的输出 | 在 reduce中是如何进行划分的 |
| 缺点 | 只有一个Reduce,当输入规模较大时,消耗较长的计算时间 | 不能保证全局有序 | 只是分,没有排序 | 只能做升序 |
- order by (全局排序asc ,desc)
–单列排序
select * from sales_info order by sku_id;
–多列排序
select * from order_data1 order by quantity desc , sales desc limit 20
--limit 可以进行区间取数的 语法 limit n ,m 结果: 从n+1 开始,取m条记录
–别名排序
select order_id ,sales as jine from order_data1 order by jine limit 10;
–默认的升序,默认是的NULLS FIRST
select * from sales_info order by sku_id nulls last;
4 表关联
这里就是重要知识点啦,熟悉MySQL的朋友应该会知道不管是日常使用还是面试提问都会经常出现表关联的相关知识,所以请大家一定认真阅读。
我们先说一下Hive join的限制。其实很明显的一点是,Hive支持类似 mysql 的大部分Join 操作,但是注意只支持等值连接,并不支持不等连接。原因是Hive语句最终是要转换为MapReduce 程序来执行的,但是 MapReduce程序很难实现这种不等判断的连接方式。
另外,在on后面的表达式中,是不支持or的。
好,接着进入重点。
如果数据存储在多个表中,怎样用单条SELECT语句检索出数据?
答案是使用联结。简单地说,联结是一种机制,用来在一条SELECT语句中关联表,因此称之为联结。使用特殊的语法,可以联结多个表返回一组输出,联结在运行时关联表中正确的行。
4.1 内部链接
SELECT vend_name, prod_name, prod_price
FROM vendors INNER JOIN products
ON vendors.vend_id = products.vend_id;
4.2 联结多个表
SELECT prod_name, vend_name, prod_price, quantity
FROM orderitems, products, vendors
WHERE products.vend_id = vendors.vend_id
AND orderitems.prod_id = products.prod_id
AND order_num = 123;
此种关联处理是相当耗费资源的。
4.3 创建高级联结
通过AS关键字使用别名,两点好处:缩短SQL语句;允许在单挑SELECT语句中多次使用相同的表。
SELECT p1.prod_id, p1.prod_name
FROM products AS p1, products AS p2
WHERE p1.vend_id = p2.vend_id
AND p2.prod_id = 'DTNTR'
如上代码中使用两个相同的表分别作为p1, p2,WHERE中选取p2中产品ID为DTNTR的列,此时p2.vend_id就是DTNTR的生产商;p1.vend_id = p2.vend_id 此时意味在p1选取DTNTR的生产商。
4.4 外部联结 OUTER JOIN
这个其实也是考点。
SQL中的关联/查询的方式一共有4种,分别是INNER JOIN(内连接,INNER可以省略)、LEFT OUTER JOIN(左连接,OUTER可以省略)RIGHT OUTER JOIN(右连接,OUTER可以省略)以及FULL JOIN(全连接)。
| 连接方式 | 含义 |
|---|---|
| INNER JOIN | 只保留两张表中完全匹配的结果集。 |
| LEFT JOIN | 返回左表所有的行,而右表中没有匹配的记录则会表示为null。 |
| RIGHT JOIN | 返回右表所有的行,而左表中没有匹配的记录则会表示为null。 |
| FULL JOIN | 在两张表进行连接查询时,返回左表和右表中所有没有匹配的行。 |
值得注意的是,MySQL中是不支持全连接的,不过hive是支持的。
SELECT id, name FROM t1
full JOIN t2 ON t1.id = t2.id
-- 去掉重复值
SELECT distinct id, name FROM t1
full JOIN t2 ON t1.id = t2.id
4.5 组合查询 UNION
UNION对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序。
如果说上述提到的各种连接方式概括为一种形式的话,那就是表与表之间左右连接,而UNION则是上下连接。
UNION的使用很简单。所需做的只是给出每条SELECT语句,在各条语句之间放上关键字UNION。
select distinct customer_id from test_join_order
union
select distinct customer_id from user_info;
--disctinct 使用与否并不影响最终结果, union 有去重功能
select customer_id from test_join_order
union
select customer_id from user_info;
UNION和UNION ALL的区别
简单来讲,就是使用UNION会删除重复的记录,而UNION ALL则不会;UNION会进行排序,而UNION ALL 不会;从效率上看,UNION ALL执行效率高于UNION,如果没有去重的需求,就选用UNION ALL。
4.6 取交集 Intersect
Intersect 对两个结果集进行交集操作,不包括重复行,同时进行默认规则的排序。
select customer_id from test_join_order
Intersect
select customer_id from user_info;
4.7 求差集 Minus
Minus 对两个结果集进行差操作(第一个减去第二个),不包括重复行,同时进行默认规则的排序。
select customer_id from test_join_order Minus select customer_id from user_info
5 使用视图
- 视图是一个虚表,一个逻辑概念,可以跨越多张表。表是物理概念,数据放在表中,视图是虚表,操作视图和操作表是一样的,所谓虚,是指视图下并不存取数据。
- 视图是建立在已有表的基础上,视图赖以建立的这些表称为基表。
- 视图也可以建立再已有的视图上。
- 视图可以简化复杂的查询。
5.1 创建视图
语法:
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name -- 视图名称
[(column_name [COMMENT column_comment], ...) ] --列名
[COMMENT view_comment] --视图注释
[TBLPROPERTIES (property_name = property_value, ...)] --额外信息
AS SELECT ...;
–不指定列创建视图
create view test_view as
select a.order_id, a.order_date,b.customer_id,b.age,b.sex from join_order as a
inner join user_info as b on a.customer_id = b.customer_id
where year=2018 and month=1;
–指定列名
create view test_view_liename(id,order_date,customer_id,age,sex) as
select a.order_id, a.order_date,b.customer_id,b.age,b.sex from join_order as a
inner join user_info as b on a.customer_id = b.customer_id
where year=2018 and month=1;
–以视图创建视图
create view test_fu_view as
select * from test_view_liename;
5.2 查看视图
–查看视图是否创建成功
show tables;
–查看test_view视图结构
desc test_view;
–查看视图的详细信息
desc formatted test_view;
5.3 删除视图
语法:DROP VIEW [IF EXISTS] [db_name.]view_name;
–删除test_view 视图
drop view test_view;
删除视图时,如果被删除的视图被其他视图所引用,删除时不会发出警告,但是引用该视图的其他视图已经失效,需要进行重建或者删除。
5.4 修改视图
语法:ALTER VIEW [db_name.]view_name AS new_select;
其中:
- 在修改指定列的视图后,指定的列名失效。
- 当基表的数据记录增删时,视图也会生变化。
- 当基表删除视图引用的列后,视图会失效。
- 当基表添加列后,视图还是原有的列,对新列不做引用。
- 当基表或基视图被删除后,此视图失效。
alter view test_fu_view as
select a.order_id,b.customer_id from join_order as a
inner join user_info as b on a.customer_id = b.customer_id
where year=2018 and month=1;
5.5 视图总结
- 视图是只读的,不能用作 LOAD / INSERT / ALTER 的目标;
- 在创建视图时候视图就已经固定,对基表的增加列操作将不会反映在视图,删除视图引用的列,图会失效;
- 删除基表并不会删除视图,需要手动删除视图;
- 视图可能包含 ORDER BY 和 LIMIT 子句。如果引用视图的查询语句也包含这类子句,其执行优先级低于视图对应字句
- 创建视图时,如果未提供列名,则将从 SELECT 语句中自动派生列名;
- 创建视图时,如果 SELECT 语句中包含其他表达式,例如 x + y,则列名称将以C0,C1 等形式生成。
6 窗口函数
这个很明显,又是一个重头戏。也是日常应用和面试提问经常会出现的知识点,真希望大家看过我之前写过的这篇博客,虽说MySQL和Hive有点点区别,但只要你理解了MySQL,那还担心不懂Hive?
语法:分析函数(如:sum(), max(), row_number()...) + 窗口子句(over函数)。
6.1 窗口子句
这里先讲下一些窗口子句,后面来详讲窗口函数中的高级函数。
| 窗口子句 | 备注 |
|---|---|
| PRECEDING | 往前 n preceding 从当前行向前n行 |
| FOLLOWING | 往后 n following 从当前行向后n行 |
| CURRENT ROW | 当前行 |
| UNBOUNDED | 起点 |
| UNBOUNDED PRECEDING | 表示该窗口最前面的行(起点) |
| UNBOUNDED FOLLOWING | 表示该窗口最后面的行(终点) |
举例如下:分析overData表中每三天(前一天,当前天,后一天)的销售额合计(保留两位小数点)
select order_date,sales,quantity, round(sum(sales) over(order by order_date rows
between 1 preceding and 1 FOLLOWING ),2) sumday3 from overData;
接下来,我也是直接把我这篇博客中窗口函数的部分办了过来,照用哈哈。
🔴 窗口函数的窗口表示范围,可以理解为将原数据划分范围,也就是分组,然后用函数实现某些目的,相比于GROUP BY , 窗口函数不会减少原来的行数。
- 语法: SELECT 窗口函数 OVER (PARTITION BY 用于分组的列名 ORDER BY 用于排序的列)
- 专用窗口函数:rank(), dense_rank(), row_numer()
当然啦,那些聚合函数在这里要用也可以用。
SELECT *,
rank() over (PARTITION BY class_id ORDER BY SCORE DESC ) AS ranking
FROM class
6.2 rank()、dense_rank()和row_number()
三个函数的主要区别是如何处理并列情况:
- rank()中的并列情况会占用下一个名词的位置, 1,1,1,4
- dense_rank() 不会占用下一个名词 1,1,1,2
- row_number()中,会忽略并列的情况, 1,2,3,4
6.3 CUME_DIST()和PERCENT_RANK()
🔴 CUME_DIST()是一个窗口函数,它返回一组值中值的累积分布。它表示值小于或等于行的值除以总行数的行数。重复的列值接收相同的CUME_DIST()值,计算的时候,取重复值的最后一行的位置。
SELECT name,
score,
ROW_NUMBER() OVER (ORDER BY score) row_num,
CUME_DIST() OVER (ORDER BY score) cume_dist_val
FROM scores;
输出结果:
| name | score | row_num | cume_dist_val |
|---|---|---|---|
| Jones | 55 | 1 | 0.2 |
| Williams | 55 | 2 | 0.2 |
| Brown | 62 | 3 | 0.4 |
| Taylor | 62 | 4 | 0.4 |
| Thomas | 72 | 5 | 0.6 |
| Wilson | 72 | 6 | 0.6 |
| Smith | 81 | 7 | 0.7 |
| Davies | 84 | 8 | 0.8 |
| Evans | 87 | 9 | 0.9 |
| Johnson | 100 | 10 | 1 |
🔴 PERCENT_RANK()和CUME_DIST()一样,是计算某个值在一组有序的数据中累计的分布,但不同在于计算分布结果的方法:(rank - 1) / (total_rows - 1),在此公式中,rank是指定行的等级,total_rows是要计算的行数。复的列值接收相同的CUME_DIST()值,计算的时候,取重复值的第一行的位。具体如下:
SELECT name,
score,
ROW_NUMBER() OVER (ORDER BY score) row_num,
PERCENT_RANK() OVER (ORDER BY score) cume_dist_val
FROM scores;
输出结果:
| name | score | row_num | percent_rank_val |
|---|---|---|---|
| Jones | 55 | 1 | 0.2 |
| Williams | 55 | 2 | 0.2 |
| Brown | 62 | 3 | 0.4 |
| Taylor | 62 | 4 | 0.4 |
| Thomas | 72 | 5 | 0.6 |
| Wilson | 72 | 6 | 0.6 |
| Smith | 81 | 7 | 0.7 |
| Davies | 84 | 8 | 0.8 |
| Evans | 87 | 9 | 0.9 |
| Johnson | 100 | 10 | 1 |
6.4 FIRST_VALUE()和LAST_VALUE()
🔴 FIRST_VALUE()是一个窗口函数,允许您选择窗口框架,分区或结果集的第一行。
SELECT employee_name,
hours,
FIRST_VALUE(employee_name) OVER (
ORDER BY hours
) least_over_time
FROM overtime;
输出结果:
| employee_name | hours | least_over_time |
|---|---|---|
| Steve Patterson | 29 | Steve Patterson |
| Diane Murphy | 37 | Steve Patterson |
| Jeff Firrelli | 40 | Steve Patterson |
| Gerard Bondur | 47 | Steve Patterson |
| Loui Bondur | 49 | Steve Patterson |
| William Patterson | 58 | Steve Patterson |
在此示例中,ORDER BY子句按结果集对行中的行进行了按小时排序,并FIRST_VALUE()选择了第一行,表示加班时间最短的员工。
如果反过来想取加班时间最长的员工,则将FIRST_VALUE()改成LAST_VALUE()
6.5 LAG()和LEAD()
🔴 LAG()函数:从同一结果集中的当前行访问上n行的数据。
语法:LAG(param1, param2, param3)
- param1 字段名
- param2 前面第几行
- param3 当前面第几行没有值时范围的值,没有设置的话就自动返回NULL。
WITH productline_sales AS (
SELECT productline,
YEAR(orderDate) order_year,
ROUND(SUM(quantityOrdered * priceEach),0) order_value
FROM orders
INNER JOIN orderdetails USING (orderNumber)
INNER JOIN products USING (productCode)
GROUP BY productline, order_year
)
SELECT productline,
order_year,
order_value,
LAG(order_value, 1) OVER (
PARTITION BY productLine
ORDER BY order_year
) prev_year_order_value
FROM productline_sales;
输出结果:
| productline | order_year | order_value | prev_year_order_value |
|---|---|---|---|
| Classic Cars | 2013 | 1374832 | NULL |
| Classic Cars | 2014 | 1763137 | 1374832 |
| Classic Cars | 2015 | 715954 | 1763137 |
| Motorcycles | 2013 | 348909 | NULL |
| Motorcycles | 2014 | 527244 | 348909 |
| Motorcycles | 2015 | 245273 | 527244 |
🔴 LEAD()函数:从同一结果集中的当前行访问后n行的数据。
将上述代码中的LAG函数改为LEAD函数。
此时的输出结果:
| productline | order_year | order_value | prev_year_order_value |
|---|---|---|---|
| Classic Cars | 2013 | 1374832 | 1763137 |
| Classic Cars | 2014 | 1763137 | 715954 |
| Classic Cars | 2015 | 715954 | NULL |
| Motorcycles | 2013 | 348909 | 527244 |
| Motorcycles | 2014 | 527244 | 245273 |
| Motorcycles | 2015 | 245273 | NULL |
6.6 NTH_VALUE()
🔴 NTH_VALUE()是一个窗口函数,允许您从有序行集中的第N行获取值。
SELECT employee_name,
salary,
NTH_VALUE(employee_name, 2) OVER (
ORDER BY salary DESC
) second_highest_salary
FROM basic_pays;
输出结果:
| employee_name | salary | second_highest_salary |
|---|---|---|
| Larry Bott | 11798 | NULL |
| Gerard Bondur | 11472 | Gerard Bondur |
| Pamela Castillo | 11303 | Gerard Bondur |
| Barry Jones | 10586 | Gerard Bondur |
| George Vanauf | 10563 | Gerard Bondur |
6.7 NTILE()
🔴 NTILE()函数将排序分区中的行划分为特定数量的组。从每个组分配一个从一开始的桶号。对于每一行,NTILE()函数返回一个桶号,表示行所属的组。
SELECT val,
NTILE(4) OVER (
ORDER BY val
) group_no
FROM ntileDemo;
输出结果:
| val | group_no |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 2 |
| 6 | 3 |
| 7 | 3 |
| 8 | 4 |
| 9 | 4 |
从输出中可以看出,第一组有三行,而其他组有两行。
也就是说,如果不平均,余n个数据,那排在前n的组就会各多一个。
7 子查询
注意点:
- hive 3.1 支持select,from,where 子句中的子查询
select 子查询限制:不支持 if / case when 里的子查询
where 子查询限制:
1.IN/NOT IN 子查询只能选择一列。
2.EXISTS/NOT EXISTS 必须有一个或多个相关谓词。
3.对父查询的引用仅在子查询的WHERE子句中支持。 - 集合中如果含null数据,不可使用not in, 可以使用in
- 主查询和子查询可以不是同一张表
举例如下:
–sales_info 表中 id_array字段每个元素出现的次数
select id,count(*) count from (
select explode(id_array) id from sales_info) sub
group by id;
简单讲就是,在hive3.x中支持在SELECT或者FROM或者WHERE出出现另外一个完整的SELECT语句,但注意不能超出以上所讲的限制。
8 抽样查询
在大数据时代,如果你针对全部数据进行分析的话,往往十分费时,也会占用大量资源,因此一般情况下会选择抽取一小部分数据用于分析或者建模操作。
8.1 随机抽样
使用rand()函数与distribute by ,order by ,sort by 合用进行随机抽样,limit关键字限制抽样返回的数据。
select * from order_data1 order by rand() limit 20;
--distribute和sort关键字可以保证数据在map和reduce阶段是随机分布的
select * from order_data1 distribute by rand() sort by rand() limit 20;
8.2 数据块抽样
- tablesample(n percent) 根据hive表数据的大小(不是行数,而是数据大小)按比例抽取数据,并保存到新的hive表中。
由于在HDFS块层级进行抽样,所以抽样粒度为块的大小,例如如果块大小为128MB,即使输入的n%仅为50MB,也会得到128MB的数据。
--select语句不能带where条件且不支持子查询
create table sample_new as select * from order_data1 tablesample(10 percent)
--10%的数据
如果希望在不同的块中抽取相同的数据,可以改变下面的参数:
set hive.sample.seednumber=<INTEGER>;
- tablesample(nM) 指定抽样数据的大小,单位为M 与PERCENT抽样具有一样的限制,因为该语法仅将百分比改为了具体值,但没有改变基于块抽样这一前提条件。
SELECT * FROM order_data1 TABLESAMPLE(1M) ;
- tablesample(n rows) 指定抽样数据的行数,其中n代表每个map任务均取n行数据
SELECT * FROM order_data1 TABLESAMPLE(10 ROWS);
8.3 分桶抽样
hive中分桶其实就是根据某一个字段Hash取模,放入指定数据的桶中。
语法:TABLESAMPLE(BUCKET x OUT OF y)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。
未分桶的表
--将表随机分成10组,抽取其中的第一个桶的数据
select * from order_data1 tablesample(bucket 1 out of 10 on rand())
已分桶的表
-- 对第一个桶抽样一半
select * from test_bucket tablesample(bucket 1 out of 6 on sku_id) --总桶数/6 = 0.5 从第一个桶开始取,取0.5个桶的数据
--假设是6个桶
select * from test_bucket tablesample(bucket 1 out of 3 on sku_id) --从第一个桶开始 取,取2个桶的数据,第二个桶是 1+3,也就是第4个桶。
9 自定义函数
查看系统内置函数 show functions;
显示内置函数用法 desc function 函数名;
详细显示内置函数用法 desc function extended 函数名;
自定义函数分为三个类别:
UDF(User Defined Function):一进一出(upper(), lower())
UDAF(User Defined Aggregation Function):聚集函数,多进一出(例如count/max/min)
UDTF(User Defined Table Generating Function):一进多出,如lateral view explode()
但这里需要说明的是,创建自定义函数需要用java来编写,而不是用传统的SQL来完成,感兴趣的朋友可以再去了解。
10 一些技巧或建议
在这一部分,会列举一些更好用方法,来代替我们平时常用实现方法,或者是平时使用HQL时的一些建议。
10.1 去重技巧——⽤group by来替换distinct
select distinct customer_id
from test_join_order;
select customer_id
from test_join_order; group by customer_id
10.2 聚合技巧——利⽤窗⼝函数grouping sets、cube、rollup
--数量分布
select quantity,count(*) from test_join_order
group by quantity
--性别分布
select sex,count(distinct user_info.customer_id) from test_join_order
inner join user_info on test_join_order.customer_id = user_info.customer_id
group by sex
--年龄分布
select age,count(distinct user_info.customer_id) from test_join_order
inner join user_info on test_join_order.customer_id = user_info.customer_id
group by age
--缺点:要分别写三次SQL,需要执⾏三次,重复⼯作,且费时
--优化方法(聚合结果均在同⼀列,分类字段⽤不同列来进⾏区分)
select quantity,sex,age,count(distinct user_info.customer_id)
select * from test_join_order
inner join user_info on test_join_order.customer_id = user_info.customer_id
group by quantity,sex,age
grouping sets(quantity,sex,age);
10.3 cube:根据group by 维度的所有组合进⾏聚合
--数量、性别、年龄的各种组合的⽤户分布
SELECT quantity,sex,age, count(distinct user_info.customer_id)
from test_join_order
inner join user_info on test_join_order.customer_id = user_info.customer_id
group by quantity,sex,age
GROUPING SETS (quantity,sex,age,(quantity,sex),(quantity,age),(sex,age), (quantity,sex,age));
--优化写法
SELECT quantity,sex,age, count(distinct user_info.customer_id)
from test_join_order
inner join user_info on test_join_order.customer_id = user_info.customer_id
group by quantity,sex,age with cube;
10.4 rollup:以最左侧的维度为主,进⾏层级聚合,是cube的⼦集
SELECT a.dt,
sum(a.year_amount),
sum(a.month_amount)
FROM(
SELECT substr(order_date,1,4) as dt,
sum(sales) year_amount,
0 as month_amount
FROM order_data1
GROUP BY substr(order_date,1,4)
UNION ALL
SELECT substr(order_date,1,7) as dt,
0 as year_amount,
sum(sales) as month_amount
FROM order_data1
GROUP BY substr(order_date,1,7)
) as a
group by dt;
--优化写法
SELECT year(order_date) as year,
month(order_date) as month,
sum(sales)
FROM order_data1
GROUP BY year(order_date), month(order_date)
with rollup;
10.5 表连接优化
- ⼩表在前,⼤表在后
Hive假定查询中最后的⼀个表是⼤表,它会将其它表缓存起来,然后扫描最后那个表。 - 使⽤相同的连接键
当对3个或者更多个表进⾏join连接时,如果每个on⼦句都使⽤相同的连接键的话,那么只会产⽣⼀个 MapReduce job。 - 尽早的过滤数据
减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使⽤到的字段。
逻辑过于复杂时,引⼊中间表
10.6 如何解决数据倾斜
数据倾斜的表现:
任务进度⻓时间维持在99%(或100%),查看任务监控⻚⾯,发现只有少量(1个或⼏个)reduce⼦任务未完成。因为其处理的数据量和其他reduce差异过⼤。
数据倾斜的原因与解决办法:
- 空值产⽣的数据倾斜
解决:如果两个表连接时,使⽤的连接条件有很多空值,建议在连接条 件中增加过滤。
on a.user_id=b.user_id and a.user_id is not null
- ⼤⼩表连接(其中⼀张表很⼤,另⼀张表⾮常⼩)
解决:将⼩表放到内存⾥,在map端做Join
select /*+ mapjoin(a) */ a.user_id,a.user_name from user_info a join join_order b where b.customer_id = a.customer_id;
- 两个表连接条件的字段数据类型不⼀致
解决:将连接条件的字段数据类型转换成⼀致的
on a.user_id = cast(b.user_id as string)
结束语
题外话:这几天非常开心,自己的几篇博客都上了排行榜,其中更有两篇上了全站综合热榜和大数据领域排行榜第一。
并且今天这篇博客呢,也刚好是我在CSDN发布的第50篇博客,正好凑个半百,也顺势肝出这一篇巨无敌长的博客,或者可以算是对CSDN平台的一次回馈?
那么本篇博客大家也可以当作是一份有关Hive语言的参考书籍,“麻雀虽小五脏俱全”。对于新手而言,也可以在没事的时候或者有疑问的时候翻阅一下。
以后我会出更多有用的文章,大家就三连加关注支持一下吧!当然我更希望的是大家能在这篇博客当中有所得有所获,后续我还会针对Hive出相关的实战项目,尽情期待。
关注我,了解更多相关知识!
CSDN@报告,今天也有好好学习

















 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











