







一、简单说明
1、需求

2、数据

3、 部分结果
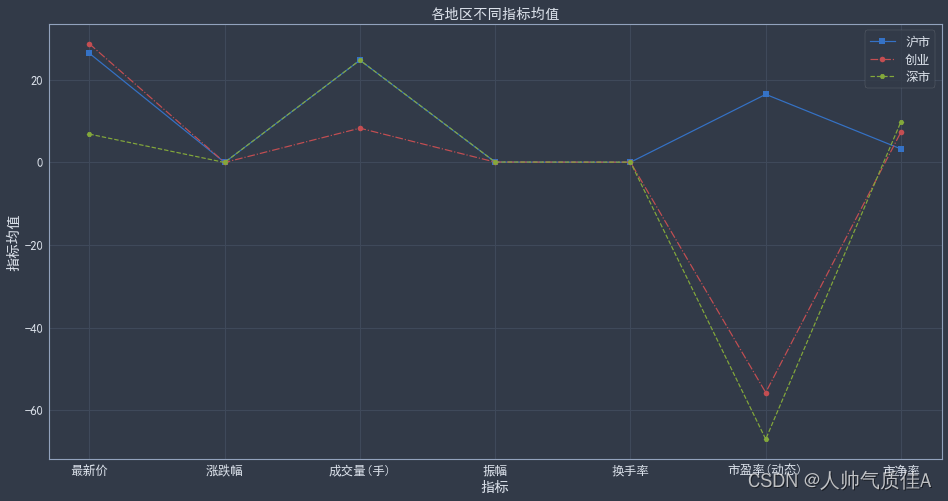
画的图
筛选的股票

二、学习收获
1、如何将DataFrame列的object类型转为自己需要float类型?

这里成交量为例子

转为相应float类型?
具体方法是:
首先先将该字段转换成列表类型,列表中每个元素对应一个字符串;

其次在该列的循环中进行字符串切片,把“万”切除;
然后是在循环中将其转换为float类型,添加到列表元素;
要计算均值方差等还要应用到numpy库来计算,列表不支持直接调用std()和mean()等函数。
def trans(list_e):
c=[]
for i in list_e:
c.append(float(i[:-1]))
return c
np.mean(trans(list(data_shenshi['成交量(手)'])))2、如何筛选出市盈率高且涨幅也大的股票、市盈率高且跌幅大的股票、市盈率低但涨幅高的股票?
用关系散点图,直接观察图的四个角落,能直观判别筛选。
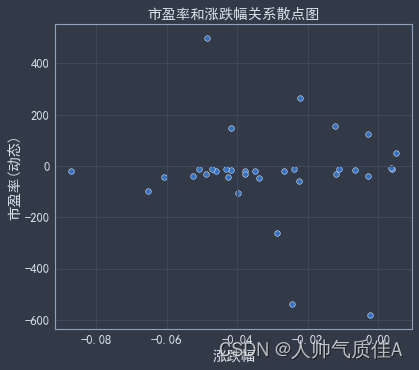
图的左上角、右上角、右下角数据即为所求。
import seaborn as sns
ax = sns.scatterplot(x='涨跌幅', y='市盈率(动态)', data=df_Data)
plt.title('市盈率和涨跌幅关系散点图')
plt.show()三、存一下源码
import numpy as np
import pandas as pd
df_Data=pd.read_excel("gupiao(1).xlsx")
df_Data
a=df_Data.drop(["相关链接","最新价","涨跌额","成交量(手)","成交额","振幅","最高","最低","今开","昨收","量比","换手率","市净率"],axis=1)
a
a.corr()
df_Data.info()
data_hushi = df_Data[df_Data['代码']>=600000]
data_chuangye = df_Data[(df_Data['代码']<600000)&(df_Data['代码']>=100000)]
data_shenshi = df_Data[df_Data['代码']<100000]
list(data_shenshi['成交量(手)'])
#沪市
hushi_mean = []
hushi_std = []
def trans(list_e):
c=[]
for i in list_e:
c.append(float(i[:-1]))
return c
hushi_mean.append(data_hushi['最新价'].mean())
hushi_std.append(data_hushi['最新价'].std())
hushi_mean.append(data_hushi['涨跌幅'].mean())
hushi_std.append(data_hushi['涨跌幅'].std())
hushi_mean.append(np.mean(trans(list(data_shenshi['成交量(手)']))))
hushi_std.append(np.std(trans(list(data_shenshi['成交量(手)']))))
hushi_mean.append(data_hushi['振幅'].mean())
hushi_std.append(data_hushi['振幅'].std())
hushi_mean.append(data_hushi['换手率'].mean())
hushi_std.append(data_hushi['换手率'].std())
hushi_mean.append(data_hushi['市盈率(动态)'].mean())
hushi_std.append(data_hushi['市盈率(动态)'].std())
hushi_mean.append(data_hushi['市净率'].mean())
hushi_std.append(data_hushi['市净率'].std())
#创业
chuangye_mean = []
chuangye_std = []
chuangye_mean.append(data_chuangye['最新价'].mean())
chuangye_std.append(data_chuangye['最新价'].std())
chuangye_mean.append(data_chuangye['涨跌幅'].mean())
chuangye_std.append(data_chuangye['涨跌幅'].std())
chuangye_mean.append(np.mean(trans(list(data_chuangye['成交量(手)']))))
chuangye_std.append(np.std(trans(list(data_chuangye['成交量(手)']))))
chuangye_mean.append(data_chuangye['振幅'].mean())
chuangye_std.append(data_chuangye['振幅'].std())
chuangye_mean.append(data_chuangye['换手率'].mean())
chuangye_std.append(data_chuangye['换手率'].std())
chuangye_mean.append(data_chuangye['市盈率(动态)'].mean())
chuangye_std.append(data_chuangye['市盈率(动态)'].std())
chuangye_mean.append(data_chuangye['市净率'].mean())
chuangye_std.append(data_chuangye['市净率'].std())
#深市
shenshi_mean = []
shenshi_std = []
shenshi_mean.append(data_shenshi['最新价'].mean())
shenshi_std.append(data_shenshi['最新价'].std())
shenshi_mean.append(data_shenshi['涨跌幅'].mean())
shenshi_std.append(data_shenshi['涨跌幅'].std())
shenshi_mean.append(np.mean(trans(list(data_shenshi['成交量(手)']))))
shenshi_std.append(np.std(trans(list(data_shenshi['成交量(手)']))))
shenshi_mean.append(data_shenshi['振幅'].mean())
shenshi_std.append(data_shenshi['振幅'].std())
shenshi_mean.append(data_shenshi['换手率'].mean())
shenshi_std.append(data_shenshi['换手率'].std())
shenshi_mean.append(data_shenshi['市盈率(动态)'].mean())
shenshi_std.append(data_shenshi['市盈率(动态)'].std())
shenshi_mean.append(data_shenshi['市净率'].mean())
shenshi_std.append(data_shenshi['市净率'].std())
columns = ['最新价','涨跌幅','成交量(手)','振幅','换手率','市盈率(动态)','市净率']
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from jupyterthemes import jtplot
jtplot.style(theme='chesterish') #选择一个绘图主题
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(16, 8)) # 设置画布
plt.plot(columns,hushi_mean, 'bs-',
columns, chuangye_mean, 'ro-.',
columns, shenshi_mean, 'gH--') # 绘制折线图
plt.xlabel('指标') # 添加横轴标签
plt.ylabel('指标均值') # 添加y轴名称
plt.title('各地区不同指标均值') # 添加图表标题
plt.legend(['沪市', '创业', '深市'])
plt.show()
plt.figure(figsize=(16, 8)) # 设置画布
plt.plot(columns,hushi_std, 'bs-',
columns, chuangye_std, 'ro-.',
columns, shenshi_std, 'gH--') # 绘制折线图
plt.xlabel('指标') # 添加横轴标签
plt.ylabel('指标方差') # 添加y轴名称
plt.title('各地区不同指标方差') # 添加图表标题
plt.legend(['沪市', '创业', '深市'])
plt.show()
import seaborn as sns
ax = sns.scatterplot(x='涨跌幅', y='市盈率(动态)', data=df_Data)
plt.title('市盈率和涨跌幅关系散点图')
plt.show()
#选取左上角、右上角、右下角数据对应为筛选的股票数据
data_finall = df_Data[((df_Data['市盈率(动态)']>=0)&(df_Data['涨跌幅']>=-0.04))|((df_Data['市盈率(动态)']<-400)&(df_Data['涨跌幅']>=-0.04))]
data_finall.to_csv("筛选的股票.csv",encoding = 'gbk')















 1140
1140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









