






机器学习分类模型存在一种情况叫偏斜类。偏斜类简单理解就是在训练模型时由于正样本和负样本之间的严重不平衡,导致模型最后检测全部都是1或者全部都是0。假设正样本的y值为1,当正样本远远多于负样本的时候,训练好的模型就会一直输出1,这会给我们判断模型优劣带来一定的障碍,比如模型输出1的概率是99.8%,输出0的概率是0.2%,这里我们就会认为模型的精度很好,误差很小。但是其实这种结果是由于数据集的不平衡导致的。因此我们迫切需要一种新方法判断模型的优劣
因此我们接下来引出两个参数是查准率(Precision)和查全率(Recall)
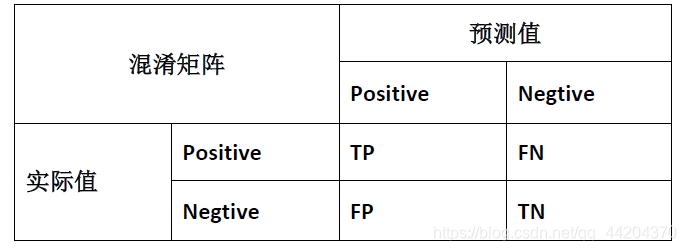
我们将算法预测的结果分成四种情况:
- 正确肯定(True Positive,TP):预测为真,实际为真
- 正确否定(True Negative,TN):预测为假,实际为假
- 错误肯定(False Positive,FP):预测为真,实际为假
- 错误否定(False Negative,FN):预测为假,实际为真
我们用图来展示这四种情况
误差的表示方法为:
ACC = (TP+TN)/(TP+FP+TN+FN)
查准率通俗的来讲:算法预测的True里面,实际真的True的样本占的比例;
查全率真正的True里面,算法也预测出True的样本占的比例。
则:查准率=TP/(TP+FP)。例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率=TP/(TP+FN)。例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。
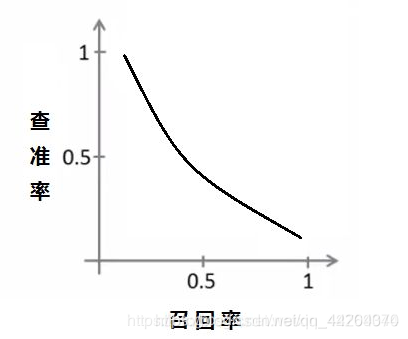
查准率和召回率的关系是这样的:在这里插入图片描述
怎么去权衡两者呢?使用 F1Score 能够更好的衡量算法的效果:
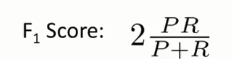
它是精确率与召回率的调和均值,当精确率和召回率都高时,F1Score也会高
但是,有时候我们对精确率和召回率不能一视同仁,我们用一个参数β来度量两者之间的关系
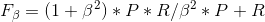
如果β>1,召回率有更大影响
如果β<1,精确率有更大影响
如果β=1,精确率和召回率影响相同,和F1Score形式一样
误差分析是机器学习中判断一个模型优劣的检验方式,有兴趣的读者可以自己了解一下机器学习中的误差分析。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









