







Hadoop HA 部署
Hadoop 规划集群
| cpu101 | cpu102 | cpu103 | |
|---|---|---|---|
| HDFS | NameNode | NameNode | NameNode |
| JournalNode | JournalNode | JournalNode | |
| DataNode | DataNode | DataNode | |
| ZKFC | ZKFC | ZKFC | |
| YARN | ResourceManager | ResourceManager | ResourceManager |
| NodeManager | NodeManager | NodeManager | |
| Zookeeper | Zookeeper | Zookeeper | Zookeeper |

HA 集群部署
HA 集群准备
Hadoop 部署 :
https://blog.csdn.net/qq_44226094/article/details/122993590
创建文件(所有节点)
在 opt 目录下创建一个 ha 文件夹
sudo mkdir ha
修改 用户
sudo chown cpu:cpu ha


将 /opt/module/ 下的 hadoop-3.1.3 拷贝到 /opt/ha 目录下
cp -r /opt/module/hadoop-3.1.3 /opt/ha/

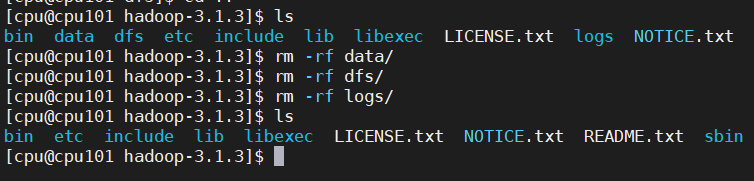
删除 data 和 logs , dfs 目录
rm -rf data/
rm -rf dfs/
rm -rf logs/
HDFS-HA 配置
配置 core-site.xml
/opt/ha/hadoop-3.1.3/etc/hadoop 文件中
vim core-site.xml
<configuration>
<!-- 把多个 NameNode 的地址组装成一个集群 mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/ha/hadoop-3.1.3/data</value>
</property>
<!-- 指定 zkfc 要连接的 zkServer 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>cpu101:2181,cpu102:2181,cpu103:2181</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 cpu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>cpu</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.HTTP.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.HTTP.groups</name>
<value>*</value>
</property>
<!-- 配置该cpu(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.cpu.hosts</name>
<value>*</value>
</property>
<!-- 配置该cpu(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.cpu.groups</name>
<value>*</value>
</property>
<!-- 配置该cpu(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.cpu.users</name>
<value>*</value>
</property>
<!-- 解决 : JN 还启动不起来, NN 就会报错 -->
<!-- NN 连接 JN 重试次数,默认是 10 次 -->
<property>
<name>ipc.client.connect.max.retries</name>
<value>20</value>
</property>
<!-- 重试时间间隔,默认 1s -->
<property>
<name>ipc.client.connect.retry.interval</name>
<value>5000</value>
</property>
</configuration>

配置 hdfs-site.xml
vim hdfs-site.xml
<configuration>
<!-- NameNode 数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/name</value>
</property>
<!-- DataNode 数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/data</value>
</property>
<!-- JournalNode 数据存储目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>${hadoop.tmp.dir}/jn</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中 NameNode 节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<!-- NameNode 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>cpu101:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>cpu102:8020</value>
</property><property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>cpu103:8020</value>
</property>
<!-- NameNode 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>cpu101:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>cpu102:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>cpu103:9870</value>
</property>
<!-- NameNode 的 https 通信地址 -->
<property>
<name>dfs.namenode.https-address.mycluster.nn1</name>
<value>cpu101:9871</value>
</property>
<property>
<name>dfs.namenode.https-address.mycluster.nn2</name>
<value>cpu102:9871</value>
</property>
<property>
<name>dfs.namenode.https-address.mycluster.nn2</name>
<value>cpu103:9871</value>
</property>
<!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://cpu101:8485;cpu102:8485;cpu103:8485/mycluster</value>
</property>
<!-- 访问代理类: client 用于确定哪个 NameNode 为 Active -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要 ssh 秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/cpu/.ssh/id_rsa</value>
</property>
<!-- 启用 nn 故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- datanode通信通过域名 -->
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
<!-- HDFS副本的数量 3 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>

配置 mapred-site.xml
vim mapred-site.xml
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>cpu102:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cpu102:19888</value>
</property>
<!-- 找到mapreduce -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/ha/hadoop-3.1.3</value>
</property>
<!-- 找到mapreduce -->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/ha/hadoop-3.1.3</value>
</property>
<!-- 找到mapreduce -->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/ha/hadoop-3.1.3</value>
</property>
</configuration>

YARN-HA 配置

配置 yarn-site.xml
vim yarn-site.xml
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 启用 resourcemanager ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 声明两台 resourcemanager 的地址 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!--指定 resourcemanager 的逻辑列表-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<!-- ========== rm1 的配置 ========== -->
<!-- 指定 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>cpu101</value>
</property>
<!-- 指定 rm1 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>cpu101:8088</value>
</property>
<!-- 指定 rm1 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>cpu101:8032</value>
</property>
<!-- 指定 AM 向 rm1 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>cpu101:8030</value>
</property>
<!-- 指定供 NM 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>cpu101:8031</value>
</property>
<!-- ========== rm2 的配置 ========== -->
<!-- 指定 rm2 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>cpu102</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>cpu102:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>cpu102:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>cpu102:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>cpu102:8031</value>
</property>
<!-- ========== rm3 的配置 ========== -->
<!-- 指定 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>cpu103</value>
</property>
<!-- 指定 rm1 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>cpu103:8088</value>
</property>
<!-- 指定 rm1 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm3</name>
<value>cpu103:8032</value>
</property>
<!-- 指定 AM 向 rm1 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm3</name>
<value>cpu103:8030</value>
</property>
<!-- 指定供 NM 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm3</name>
<value>cpu103:8031</value>
</property>
<!-- 指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>cpu101:2181,cpu102:2181,cpu103:2181</value>
</property>
<!-- 指定 resourcemanager 的状态信息存储在 zookeeper 集群 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- ResourceManager 启用工作保留恢复 -->
<property>
<name>yarn.resourcemanager.work-preserving-recovery.enabled</name>
<value>true</value>
</property>
<!-- RM保留的已完成应用程序的最大数量 -->
<property>
<name>yarn.resourcemanager.max-completed-applications</name>
<value>1000</value>
</property>
<!-- RM状态存储保留的最大已完成应用程序数 -->
<property>
<name>yarn.resourcemanager.state-store.max-completed-applications</name>
<value>1000</value>
</property>
<!-- nodemanager重启时恢复状态,启用该功能时必须配置nodemanager端口号(不配置的话就是每次重启yarn时随机生成端口号,两次端口号不同就会导致恢复失败) -->
<property>
<name>yarn.nodemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 启用恢复时节点管理器将在其中存储状态的本地文件系统目录 -->
<property>
<name>yarn.nodemanager.recovery.dir</name>
<value>/opt/ha/hadoop-3.1.3/tmp/yarn-nm-recovery</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://cpu102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 每个任务最小可用内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<!-- 每个任务最多可用内存, 默认8182MB -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
<!-- 物理内存和虚拟内存比率 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>

分发
xsync hadoop-3.1.3/

运行 HA
配置环境变量
将 HADOOP_HOME 环境变量更改到 HA 目录(三台机器)
sudo vim /etc/profile.d/my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/ha/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin

source /etc/profile
分发 :
sudo /home/cpu/bin/xsync /etc/profile.d/my_env.sh

启动 namenode
启动 journalnode 服务 ( 所有节点 )
hdfs --daemon start journalnode

格式化 namenode
hdfs namenode -format

启动 nn1
hdfs --daemon start namenode
同步 nn1 的元数据信息
cpu101 中
hdfs namenode -bootstrapStandby
cpu102 中
hdfs namenode -bootstrapStandby


cpu102 中
hdfs --daemon start namenode

cpu103 中
hdfs --daemon start namenode

将[nn1]切换为 Active
hdfs haadmin -transitionToActive nn1
查看是否 Active
hdfs haadmin -getServiceState nn1
初始化 HA 在 Zookeeper 中状态
关闭所有 HDFS 服务
stop-dfs.sh

保证 ZooKeeper 启动
https://blog.csdn.net/qq_44226094/article/details/123119682
zk.sh start
初始化 HA 在 Zookeeper 中状态
hdfs zkfc -formatZK

启动 HA 服务脚本
vim myhadoopHa.sh
内容 :
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop HA 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh cpu101 "/opt/ha/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh cpu101 "/opt/ha/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh cpu102 "/opt/ha/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop HA 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh cpu102 "/opt/ha/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh cpu101 "/opt/ha/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh cpu101 "/opt/ha/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac

授权 :
chmod 777 myhadoopHa.sh

分发
xsync ~/bin/myhadoopHa.sh

启动服务
myhadoopHa.sh start

QuorumException: Got too many exceptions to achieve quorum size 2/3 解决方案
https://blog.csdn.net/qq_44226094/article/details/123408901
查看服务状态
查看 namenode 状态
hdfs haadmin -getServiceState nn1
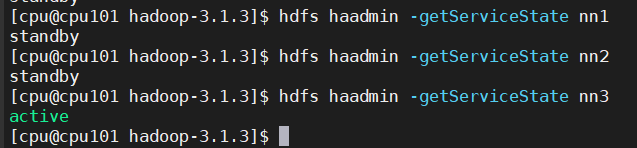
查看
yarn rmadmin -getServiceState rm1
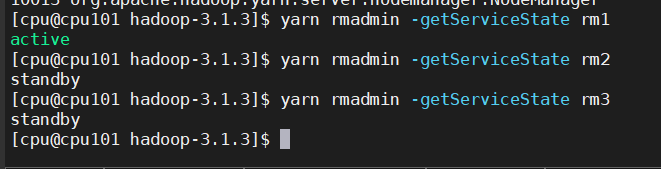




测试 HA
Operation category READ is not supported in state standby 解决方案 :
https://blog.csdn.net/qq_44226094/article/details/123419924
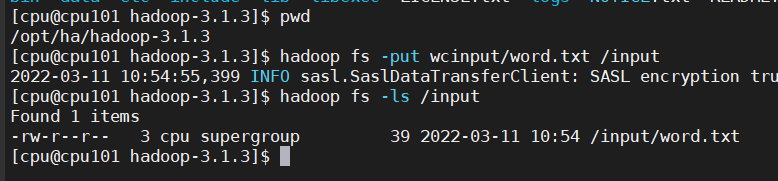
创建目录
hadoop fs -mkdir /input

上传文件
hadoop fs -put wcinput/word.txt /input
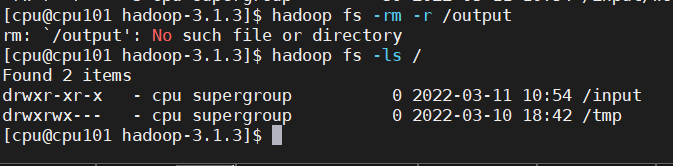
删除 HDFS 上已经存在的输出文件
hadoop fs -rm -r /output
执行 wordcount 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
查看内容
hadoop fs -ls /output
hadoop fs -cat /output/part-r-00000

将 Active NameNode 进程 kill
kill -9 namenode 的进程 id
kill -9 resourcemanager 的进程 id















 4193
4193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









