







文章目录
step1:环境要求
①安装ffmpeg
这一步很关键。如果没有ffmpeg,librosa读取MP3文件时就会报错。
见笔者的文章:ffmpeg安装
②安装librosa
pip install librosa
③安装soundfile
pip install soundfile
step2:4行代码完成一首歌的格式转换
①导包
import librosa
import soundfile
②读入需要处理的MP3文件
y,sr = librosa.load("./dataset/sample_data/Sakamoto_MerryChristmasMr_Lawrence.mp3")
③用soundfile重写成wav
soundfile.write("./dataset/sample_data/Sakamoto_MerryChristmasMr_Lawrence.wav",y,sr)
综上,完整代码如下:
import librosa
y,sr = librosa.load("./dataset/sample_data/Sakamoto_MerryChristmasMr_Lawrence.mp3")
import soundfile
soundfile.write("./dataset/sample_data/Sakamoto_MerryChristmasMr_Lawrence.wav",y,sr)
注:MP3批量转WAV(保持源文件名不变)
批量保存文件夹中的文件名,参见笔者的文章。
step1:编写转换函数
def audio_mp3_to_wav():
# 原MP3文件所在的文件夹
audio_path = "C:/Users/24061/Desktop/MERcode/EMOPIA_cls-main/emopia_retrain/dataset/EMOPIA_1.0/EMOPIA_1.0/song"
# WAV想要保存的文件夹
save_path = "C:/Users/24061/Desktop/MERcode/EMOPIA_cls-main/emopia_retrain/dataset/EMOPIA_1.0/EMOPIA_1.0/song_wav"
# 把MP3文件名存储在csv文件中,并将文件名存入列表中
songs_id_all = pd.read_csv("C:/Users/24061/Desktop/MERcode/EMOPIA_cls-main/emopia_retrain/dataset/EMOPIA_1.0/EMOPIA_1.0/songs_lists/metadata_by_song_new.csv",index_col=0)
songs_id_all_list = []
for i in songs_id_all.index:
songs_id_all_list.append(i)
# 遍历文件夹
for fn in tqdm(songs_id_all_list):
# 加载文件
waveform, source_sr = librosa.load(Path(audio_path, fn + ".mp3"))
# 想要保存的文件名
pt_path = Path(save_path, fn + ".wav")
# 采样后数据的保存位置。如果没有此文件夹,就创建一个文件夹
if not os.path.exists(os.path.dirname(pt_path)):
os.makedirs(os.path.dirname(pt_path))
# 将音频写成WAV
soundfile.write((pt_path),waveform,source_sr)
step2:调用转换函数
import os
from pathlib import Path
from tqdm.notebook import tqdm
import librosa
import soundfile
audio_mp3_to_wav()
step3:运行
等待写入:

写好的文件如图所示:
转换完成:
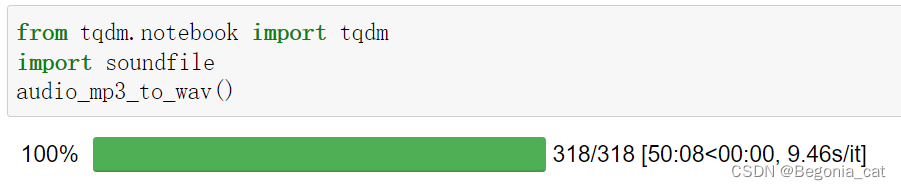
扩展
使用此方法进行mp3转wav,可以解决很多报错问题,如:
解决报错小故事1
-
报错
笔者在做实验时,遇到如下报错:raise RuntimeError(prefix + _ffi.string(err_str).decode('utf-8', 'replace'))
……
RuntimeError: Error opening 'D:\\xxx.wav': File contains data in an unknown format. -
分析网络上的解决方法
搜索了很多资料,很多博主给出的解决方法是:
- 安装ffmpeg
- 卸载librosa😭
……
BUT!笔者想说,安装ffmpeg确实是一个方法,它适用于你的音频均是MP3,想要让代码读取的情况。但如果正确安装ffmpeg后依旧没有解决问题,很可能是因为
你的音频源文件有问题(一些你尚未发现的小问题)。 -
笔者的方法
不过不要担心,这里笔者想提出一个通用的解决办法,不妨试试~。
方法就是:对音频源文件进行处理。采用本文提出的方法,将音频全部重新生成新的WAV文件。 -
笔者的报错解决故事
从上述报错中,细心的读者可能已经发现了,笔者报错代码提示“无法识别wav格式”,欸?有点奇怪了吼!无法识别mp3我理解,无法识别wav我就黑人问号了(因为现有音频处理软件几乎都是支持WAV的,几乎不存在不识别WAV的情况)。于是,笔者打开音频源文件查看了一下:
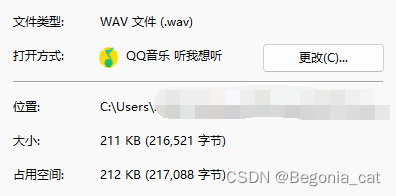
谁家WAV就几kB呀?这个音频应该是个假wav【所谓“假wav”:即,你将一个MP3文件通过修改后缀的方式,得到一个WAV后缀的音频文件,但音频实质上还是MP3】【笔者的音频是由pydub的AudioSegment得来的,查了查,这个包输出的音频是MP3格式,而笔者的命名是xxx.wav,报错原因可能就出在这里】。
使用本文提出的方法,将音频全部重新生成新的WAV文件,再次实验,果然,报错解决了!














 3192
3192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









