







目录
集群启动
方法一:
/export/servers/hadoop-3.3.3/sbin/start-all.sh
方法二:
去hadoop-3.3.3目录下执行sbin/start-all.sh
一、基本概念
分布式系统:
容错性(低耦合)
可恢复性(发生故障,不丢失数据)
一致性(一个作业/任务的失败不影响最终结果)
可扩展性(负载增加导致性能下降而非出现故障,资源随容量按比例增加)
为了满足上述要求,有以下操作:
- 数据添加到集群后马上被分发出去,存在多个节点上;
【最好用节点处理本地存储的数据,以将网络流量最小化】
- 数据存储在固定大小(通常为128MB)的块中,每个块跨系统多次复制,以提供冗余和数据安全;
- 通常将计算作为一个作业。作业被分解成任务,每个节点针对单个数据块执行任务;
- 编写作业时,通常不用考虑网络编程、时间或底层的基础设施;
【开发人员专注于数据和计算,而不是分布式编程细节】
- 任务独立,节点在处理期间不通信,保证没有死锁的进程依赖;
- 作业通常通过任务冗余来容错;
【保证单个节点或任务的失败不会导致最终计算结果的不正确或不完整】
- 主程序将工作分配给woker节点,针对各自负责的数据进行并行运算。
二、Hadoop架构
1.组成
HDFS(有时缩写DFS)——分布式文件系统:管理存储在集群磁盘上的数据
YARN——集群资源管理器:给希望执行分布式计算的应用程序分配计算资源
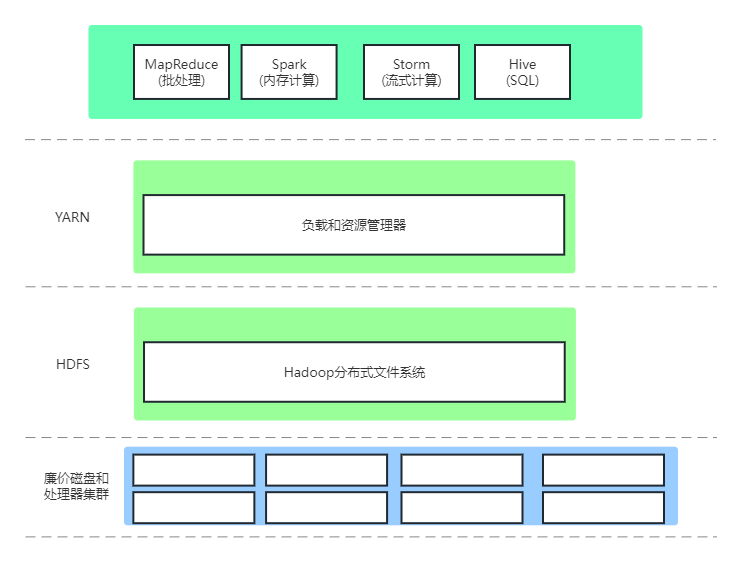
Hadoop是一个以协调方式运行的机器集群
Hadoop其实是运行在集群上的软件的名称,由一组计算机上运行的6种后台服务器组成。
HDFS和YARN提供了一个接口API
集群就是运行HDFS和YARN的一组计算机
集群是水平扩展的
Hadoop的进程是服务,在进程节点上运行,每个进程在自己的JVM中运行,因此每个守护进程都有自己的系统资源分配,并由操作系统独立管理
HDFS和YARN由几个守护进程(后台运行,不需要用户输入的软件)实现
2.HDFS
| master服务 | worker服务 |
| NameNode(入口) 【存储文件系统目录树、文件元数据、集群中每个文件的位置; 访问HDFS,必须先通过从NameNode请求信息来查找相应存储节点】 | DataNode 【存储和管理本地磁盘上的HDFS块; 报告各个数据存储的健康状况和状态报告给NameNode】 |
| Secondary NameNode 【代表NameNode执行内务任务并记录检查点】 ** 并非NameNode的备份 ** |
集中式存储架构
采用WORM(写一次,读多次)模式【不允许随机写入或追加到文件】
用来存储计算的原始输入、计算阶段之间的中间结果、整个作业的最终结果。
文件块
HDFS文件分为多个块,块大小通常为64MB 或 128MB
块大小:可以在HDFS中读取或写入的最小数据量
默认情况下,块被复制3份
数据管理
主NameData:记录组成文件的块和块所在的位置
与每个文件相关联的元数据被存储在NameNode的master节点的内存中
3.YARN
| master服务 | worker服务 |
| ResourceManager(入口) 【为应用程序分配和监视可用的集群资源; 处理集群上作业的调度】 | NodeManager 【单个节点上运行和管理、处理任务; 报告任务运行时的健康状况和状态】 |
| ApplicationMaster 【根据ResourceManager的调度,协调在集群上运行的特定应用程序】 ** 并非NameNode的备份 ** |
MapReduce 是 I/O密集型
YARN 将工作负载管理和资源管理分离,以便多个应用程序可以共享一个集中的公共资源管理服务
4.使用分布式文件系统
HDFS实质上是一个分布式远程文件系统
# 下载 shakespeare.txt
wget https://github.com/bbengfort/hadoop-fundamentals/raw/master/data/shakespeare.txt.zip
# 解压zip文件
unzip shakespeare.txt.zip
# 将文件复制到分布式文件系统
hadoop fs -copyFromLocal shakespeare.txt shakespeare.txt
【完整命令:
hadoop fs -put /file_system_example/shakespeare.txt hdfs://localhost/user/root/shakespeare.txt 】# 创建分层目录树
hadoop fs -mkdir corpora
# 列出远程主目录的内容
hadoop fs -ls
【删除时通常使用 rm -R 进行递归删除
移动文件到本地时需要注意,通常使用管道输出到其他程序,如 less 或 more】
# 读取远程文件内容
hadoop fs -cat shakespeare.txt | less
【使用cat,通过管道传递给less查看】
# 从分布式文件系统获取文件
hadoop fs -get shakespeare.txt ./shakespeare.from-remote.txt
# hadoop fs -copyToLocal shakespeare.txt ./shakespeare.from-remote.txt
# 从分布式文件系统删除文件
hadoop fs -moveToLocal shakespeare.txt
文件权限类型 r 读 w 写 x 执行
HDFS文件权限执行被忽略了
5.MapReduce的示例
map函数:
输入:一系列键值对,在每个键值对上单独运算
输出:0个或多个键值对(按照键来分组,根据键被用于各个reduce函数的输入)
reduce函数;
应用于一个输入列表,输出单个聚合值
MapReduce分阶段框架
- HDFS本地数据以键值对形式加载到一个映射过程;
- mapper输出0个或多个键值对,计算得到的值映射到一个特定的键;
- 基于键对键值进行shuffle和sort操作,然后传递给reducer,reducer获得键的所有值
- reducer输出map归约结果(0个或多个键值对)
示例程序
# 下载java程序文件
# WordCount.java 执行作业的MapReduce驱动类
# WordMapper.java 发射单词的mapper类
# SumReducer.java 统计单词的reducer类
# 本地下载,上传至服务器的/file_system_example文件夹(自己创建)
# 解压zip文件
unzip -o -d /file_system_example WordCount.zip
# 编译成JAR文件
cd /file_system_example/WordCount
hadoop com.sun.tools.javac.Main WordCount.java
提示过时API,修改WordCount.java
//Job job=new Job(getConf()); 这是原来的代码
Job job = Job.getInstance(getConf()); //这是修改后的# 编译通过
# 打包(按书上会报错,找不到mapper)
jar cf wc.jar WordCount.class WordMapper.class SumReducer.class
将作业提交到集群进行统计
# 使用 hadoop jar命令
# 该命令连接到ResourceManager,发送wc.jar文件,让其在所有节点上执行
# 需要作业归档文件的路径,调用main方法所在类名
# 输入输出路径都是HDFS路径,且输出路径不能再分布式文件系统上(防止覆盖或删除集群数据)
hadoop jar wc.jar WordCount shakespeare.txt wordcounts
可以看到此时hadoop目录下多了一个输出结果的文件夹wordcounts
查看该目录
# 计算中使用的每个reducer都应该有一个part文件
# 此外,还应该有一个_SUCCESS和_logs目录,用于存储作业相关信息
# 为了读取作业结果,针对远程文件系统中的part文件执行cat命令,通过管道传给less
hadoop fs -ls wordcounts
hadoop fs -cat wordcounts/part-r-00000 | less
【当MapReduce作业出问题】
# 使用crtl+C只能终止显示进度的进程,不能真正停止作业
# 列出集群上目前正在运行的所有作业
hadoop job -list
# 通过输出标识要终止的作业id,通过-kill终止
hadoop job -kill $JOBID
【可以通过托管ResourceManager服务的机器的8088端口访问其Web UI】














 1190
1190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









