









目录
【在Spark集群不同节点之间共享变量】
广播变量
允许程序缓存一个只读的变量在集群的每台机器上。
一个广播变量
,通过调用 brvar = SparkContext.broadcast(v) 方法,从一个普通变量v中创建出来;
广播变量是 v 的一个包装变量,值可以通过value方法访问,各个节点都可以通过 brVar.value 来引用广播的数据。
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.master('local[1]').appName('RDD Demo').getOrCreate()
sc = spark.sparkContext
conf = {'ip':'192.168.1.1', 'key':'cumt'}
# 广播变量
brVar = sc.broadcast(conf)
# 获取广播变量的值
a = brVar.value
a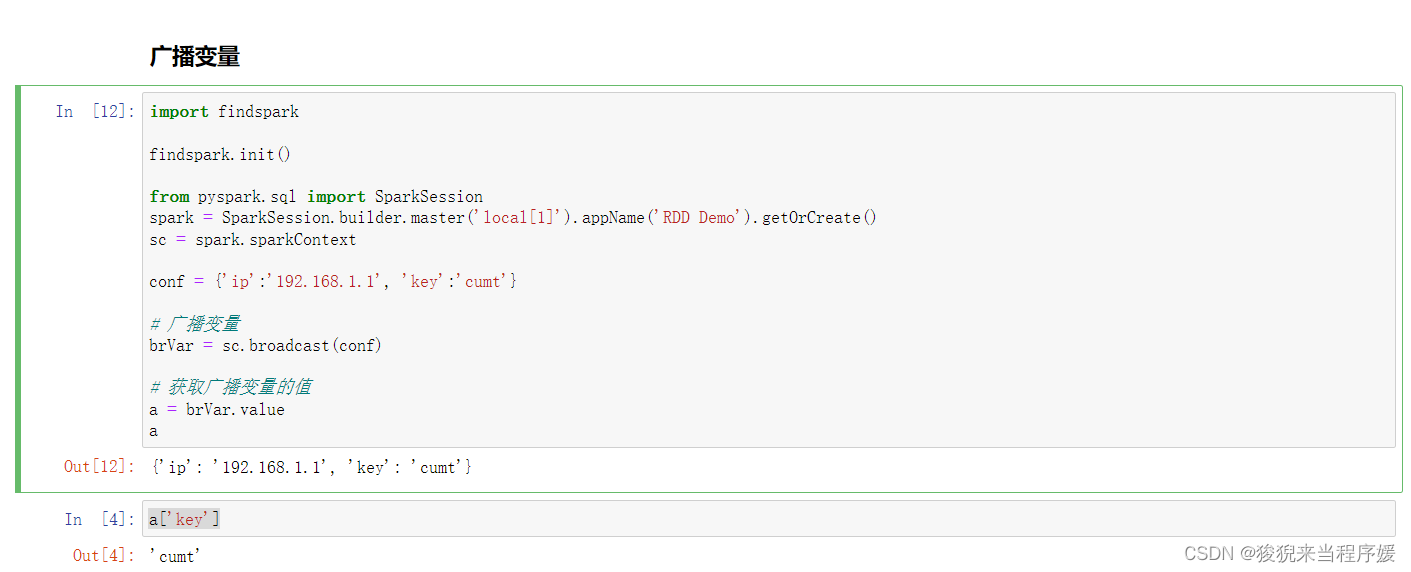
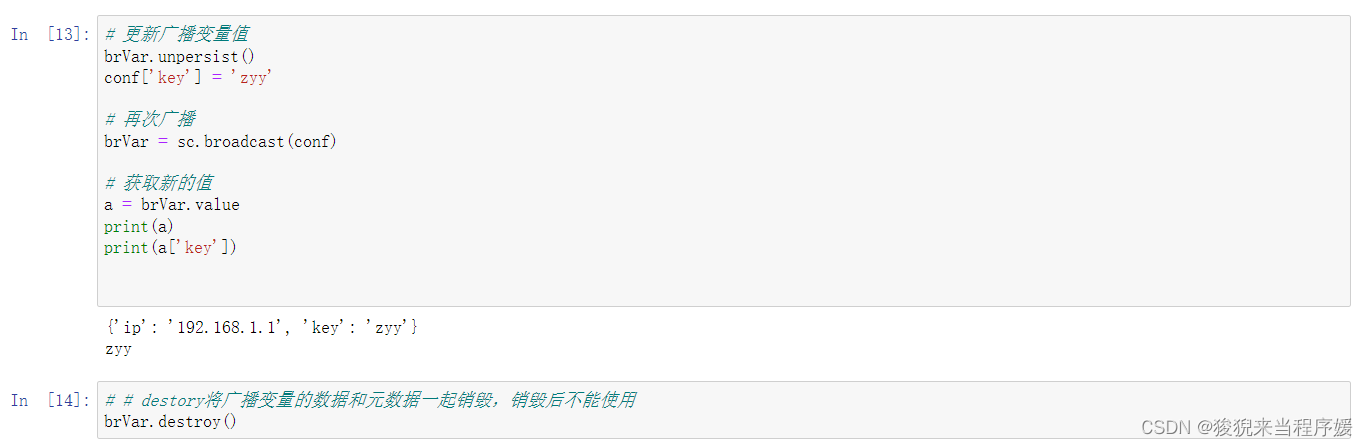
累加器
# 是一种只能利用关联操作做“加”操作的变数
# 常见作用:调试时进行相关事件的计数
# SparkContext.accumulator(v) 根据初始变量 v 创建出累加器对象
# Spark 集群上,不同节点的计算任务都可以用add方法或使用+=进行累加
# 累加器是一种只可加的变数对象
rdd = sc.range(1,101)
# 创建累加器,初始值0
acc = sc.accumulator(0)
def fcounter(x):
global acc
if x % 2 == 0:
acc += 1
rdd_counter = rdd.map(fcounter)
# 获取累加器数值
print(acc.value)
# 定制存储级别,保证多次正确获取累加器值
rdd_counter.persist()
print(rdd_counter.count())
print(acc.value)
# 保证准确性,只能用一次动作操作
# 若要多次使用,要在RDD对象上用persist()或cache()进行阻断操作,切断依赖,保证只执行一次
print(rdd_counter.count())
print(acc.value)















 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









