







1. 背景
1.1 技术背景
当时在前东家工作的时候,主要是tob私有化的搜索推荐项目。智能搜索推荐系统需要很多的用户数据进行清洗,也就是所谓的ETL(Extract,Transform,Load)。之前一直使用组内自研的一个数据清洗框架(简称XXX)进行处理。
组内自研的框架XXX,主要使用Linux标准输入流作为input,标砖输出流作为output。此外也支持hadoop运行,输入则变为文件。
一般情况下的XXX框架使用方法:
cat input.json | -c local -m map -f map.yml | -c local -m shuffle| -c local -m reduce reduce.yml 这个命令行表示:将input.json源文件(注:包括多行数据,每一行数据都是json格式)作为标准输入,之后进入map阶段,map的配置需要读取map.yml文件;map之后进入shuffle阶段,也就是根据key排序;之后进入reduce阶段,reduce的配置参考reduce.yml。-c local表示采用本地模式运行,还有-c hadoop 支持hadoop运行。
input.json文件示例:
{"title":"大话西游", "director":"周星驰"}
{"title":"美人鱼", "director":"周星驰"}
{"title":"警察故事", "director":"成龙"}
{"title":"警察故事2", "director":"成龙"}map.yml文件:
Mapper:
RenameMapper:
OriginField: Director
TargetField: Daoyanreduce.yml:
Reducer:
GroupbyReducer:
OriginField: Daoyan
大致就是将原始文件中,"director"字段重命名为"Daoyan",再根据"Daoyan"字段Reduce操作,生成一个数组。
输出为Linux标准输出。输出结果为:
{"Daoyan":"周星驰","title":["美人鱼","大话西游"]}
{"Daoyan":"成龙","title":["警察故事1","警察故事2"]}这里用到了Map Reduce的思想。Map Reduce的论文参考:
MapReduce: simplified data processing on large clusters: Communications of the ACM: Vol 51, No 1
1.2 项目背景
当时给某个金融客户投标,发现我们的数据处理框架不能满足要求。
原因主要是:
1. 原始命令行操作就是单线程,肯定不能满足处理速度上的需求;
2. cat 文件作为输入的方式不是很优雅;
真实原因:
投标时候,自研的数据处理框架被客户大声嘲笑……
“Hadoop已经是上一代的技术了,这年头都用Spark了。”
“你们真的是XXX公司的吗?”
疑似客户内心表情:

即使使用了hadoop,hadoop相比于spark有以下劣势:
1. hadoop基于磁盘,而spark优先基于内存运算;
2. hadoop的算子实际上只有map和reduce两种,对于复杂的计算需要各种job来完成,管理较为复杂;相比之下spark的shuffle成本较低;
3. spark提供了批处理、交互式、机器学期(MLib)、图计算(GraphX)等更高级的功能;
4. Spark中通过DAG有向无环图可以实现良好的容错;
5. 经过测试,spark基于磁盘运算时,速度能比hadoop快10倍,基于内存时能快100倍;
(参考文章:开源SQL-on-Hadoop系统一览 - 知乎 和Spark和Hadoop的异同点比较分析(很详细哦!!!)_故明所以的博客-CSDN博客_hadoop和spark的相同和区别
)
于是领导要求把spark和组内的自研框架做一个整合,毕竟甲方说啥就是啥。
1.3 设计目标
新版本的框架大致需求如下:
1. 需要支持命令行操作,能够在单机环境下运行;
2. 需要支持在spark集群下操作;
3. 尽量能复用之前的配置文件,以及之前的一些模块;
4. 输入文件主要是json类型的数据,也要支持csv文件(之前就已经支持了);
5. 充分挖掘spark的性能,把处理耗时大幅度减少;
6. 支持docker方式运行和k8s部署
7. 能用就行,反正ToB私有化就是高级外包……伺候好甲方爸比就行
2. spark介绍
Apache Spark 是一个快速的,通用的集群计算系统。它对 Java,Scala,Python 和 R 提供了的高层 API,并有一个经优化的支持通用执行图计算的引擎。它还支持一组丰富的高级工具,包括用于 SQL 和结构化数据处理的 Spark Sql,用于机器学习的MLib,用于图计算的GraphX和Spark Streaming。参考文档:http://spark.apachecn.org/#/docs/1
2.1 spark架构简介
参考文章:图文详解 Spark 总体架构 [禅与计算机程序设计艺术] - 腾讯云开发者社区-腾讯云

术语说明:
Driver
Driver的主要功能,总结如下:
- 运行应用程序的main函数
- 创建spark的上下文
- 划分RDD并生成有向无环图(DAGScheduler)
- 与spark中的其他组进行协调,协调资源等等(SchedulerBackend)
- 生成并发送 Task到 Executor(TaskScheduler)
Task
指定并行的task数量
spark.default.parallelism=1000参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
Executor
Executor是spark任务(task)的执行单元,运行在worker上,但是不等同于worker,实际上它是一组计算资源(cpu核心、memory)的集合。一个worker上的memory、cpu由多个executor共同分摊。
DAG: 有向无环图
1、用户提交的应用程序,Spark底层会根据宽依赖、窄依赖自动生成DAG。
2、反应出RDD之间的依赖关系
Executor:进程——运行在工作节点上,负责运行Task
Task:Executor的工作单元,也叫任务
Job:用户提交的作业,Job包含多个Task
Stage:是Job的基本调用单元,Job根据宽窄依赖划分不同的Stage,一个Stage中包含一个或者多个同种Task
一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成。
2.2 pyspark demo代码
2.2.1 map算子
参考:PySpark map() Transformation - Spark by {Examples}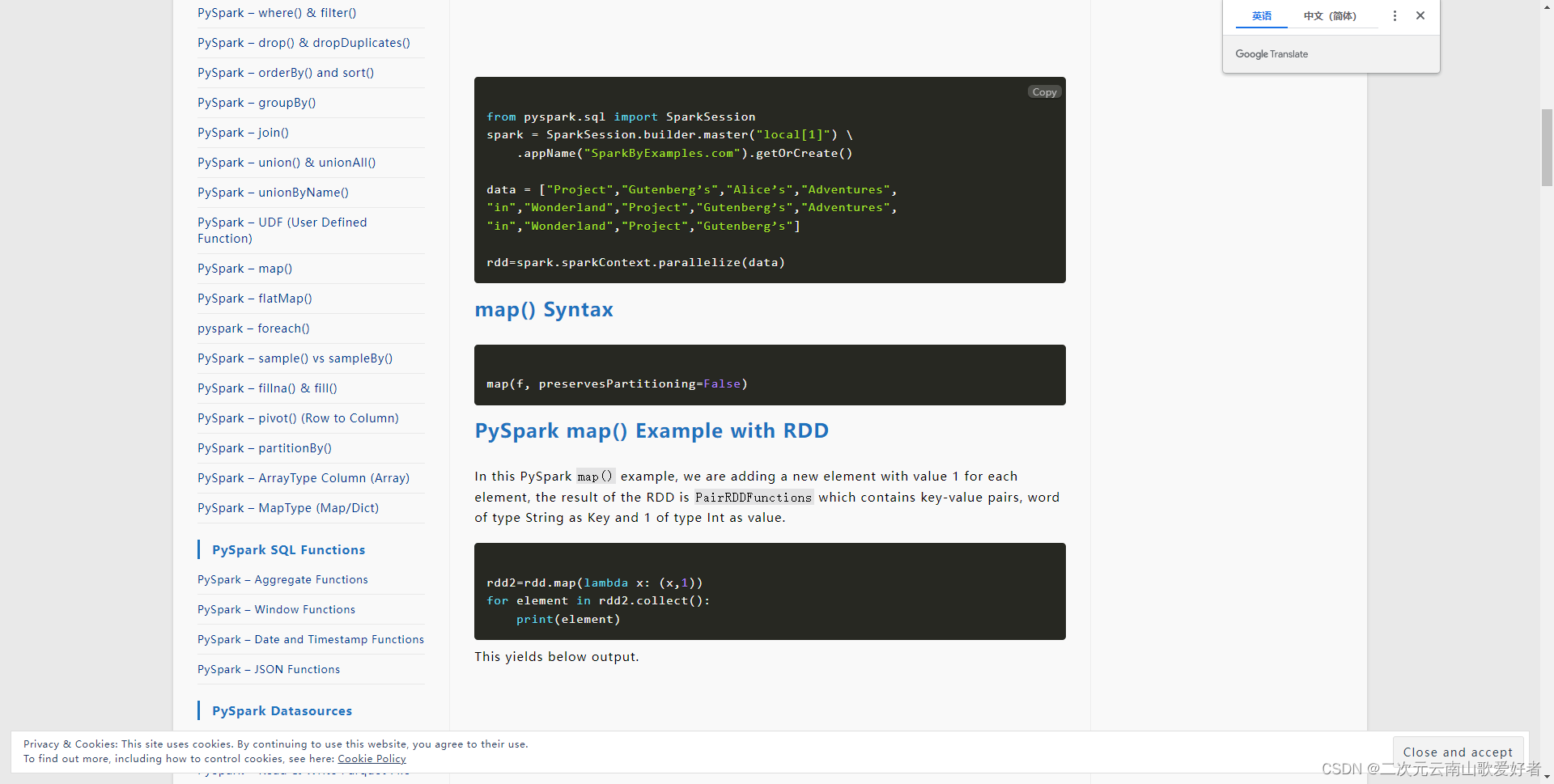
输出:
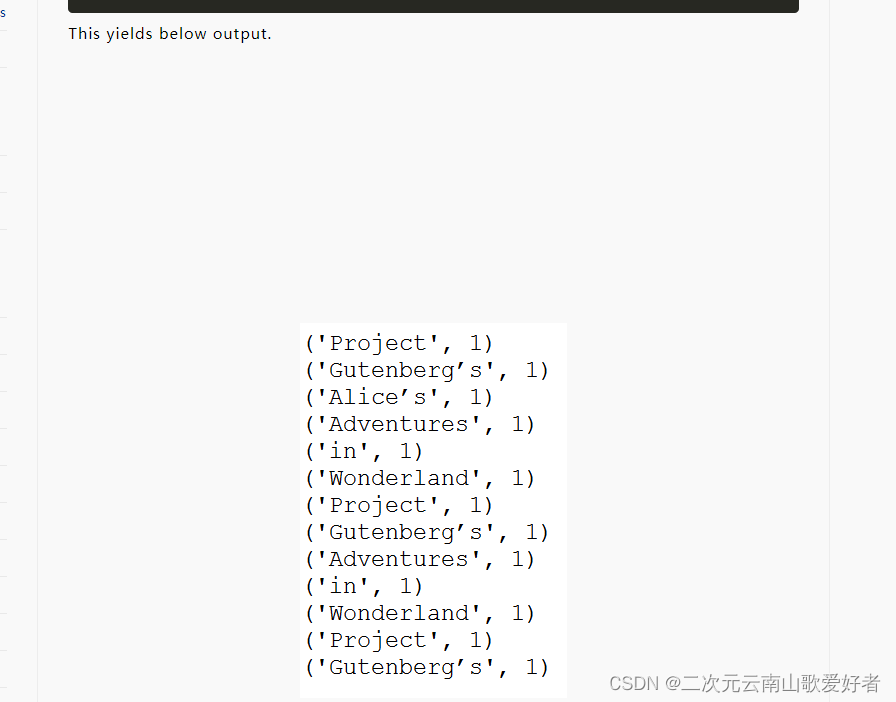 这个map算子的功能很简单,就是对每一条数据,给这条数据加上一个元素整数1,最后生成多个tuple。
这个map算子的功能很简单,就是对每一条数据,给这条数据加上一个元素整数1,最后生成多个tuple。
2.2.2 reduceByKey算子
参考官方文档:pyspark.RDD.reduceByKey — PySpark 3.1.2 documentation

这个reduce就是简单的根据key累加的计算。
其他各类算子就不做更多展示了。
3. 具体设计
具体设计中,将原先的命令行进行了一些小修改。
3.1 命令行示例
xxx -c spark -f spark_conf.yaml去除了-m的选项,一个是感觉 map和reduce没分开的必要,就整合到一块了;
另一个原因,则是考虑到spark的生命周期中,数据的流转形式是rdd,而spark还是基于内存的,所以map和reduce就应该放在一个配置当中,作为一个完整的声明周期
3.2 yml文件配置示例
# spark_conf.yml
mode:
local[8] # 指定运行模式
file_input:
file_input_path: /user/opt/file/input
file_input_alia: inputRdd
operators:
RenameMapper:
InputRdd: inputRdd
OriginField: Director
TargetField: Daoyan
OutputAlias: RenameRdd
RenameMapper:
InputRdd: RenameRdd
OriginField: Daoyan
TargetField: Daoyan2
OutputAlias: RenameRdd2
OutputPath: /user/opt/file/map_output1
SparkGroupbyReducer:
InputRdd: RenameRdd
OriginField: Daoyan
OutputPath: /user/opt/file/reduce_output1解释一下yml文件。
首先也是从"/user.opt.file/input"路径中读取文件;
之后进行rename;
之后再rename(这里的rename只是为了演示一下,rdd可以来源于文件转化也可以来源于之前的RDD),
之后再groupbyReducer一下,生成array。
实际效果同章节1.1的一致,只是多了个RenameRdd2,存储到/user/opt/file/map_output1
下面讲讲yml文件中的一些设计理念。
3.2.1 关于rdd
rdd,弹性分布式数据集(resilient distributed dataset)简称RDD ,他是一个元素集合,被分区地分布到集群的不同节点上,可以被并行操作,RDD可以从hdfs(或者任意其他的支持Hadoop的文件系统)上的一个文件开始创建,或者通过转换驱动程序中已经存在的集合得到。
不了解rdd的开发人员可以把rdd简单理解为一个被转来转去、并且每一步转化能生成rdd的数据集合。
以下是几种rdd的生成方式。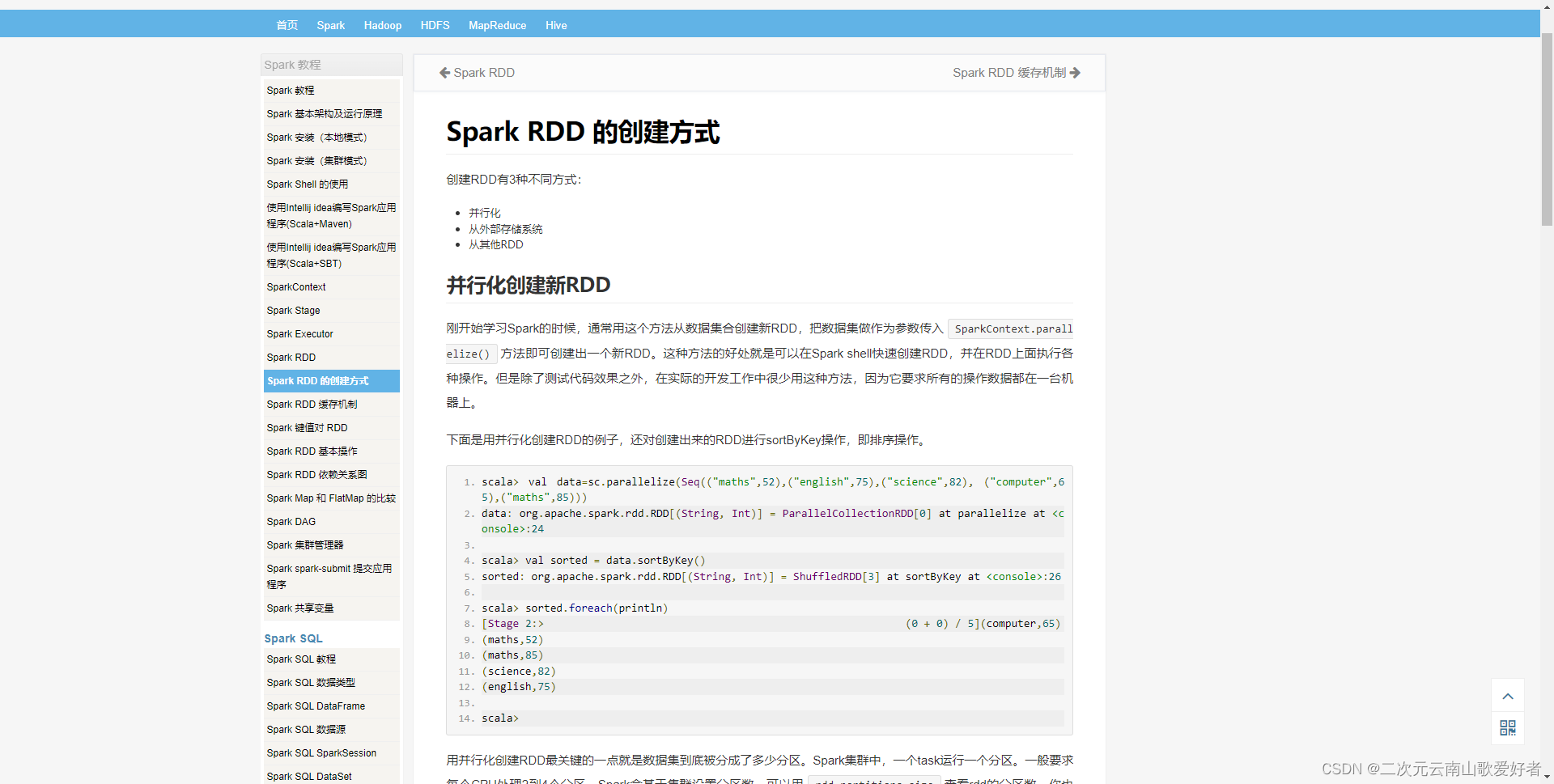
(参考:RDD:创建的几种方式(scala和java)_花和尚也有春天的博客-CSDN博客_scala 创建rdd Spark RDD 的创建方式 | Spark 教程)
另外由于spark使用中,一般都会建议spark的生命周期内复用rdd,所以在设计时候将rdd存放到了内存中,并取了alias别名,思想上有点碰瓷Spring的单例模式。
除此之外,考虑到测试环境的内存有限,所以使用了pyspark的rdd持久化函数对rdd持久化。
参考: pyspark · PyPI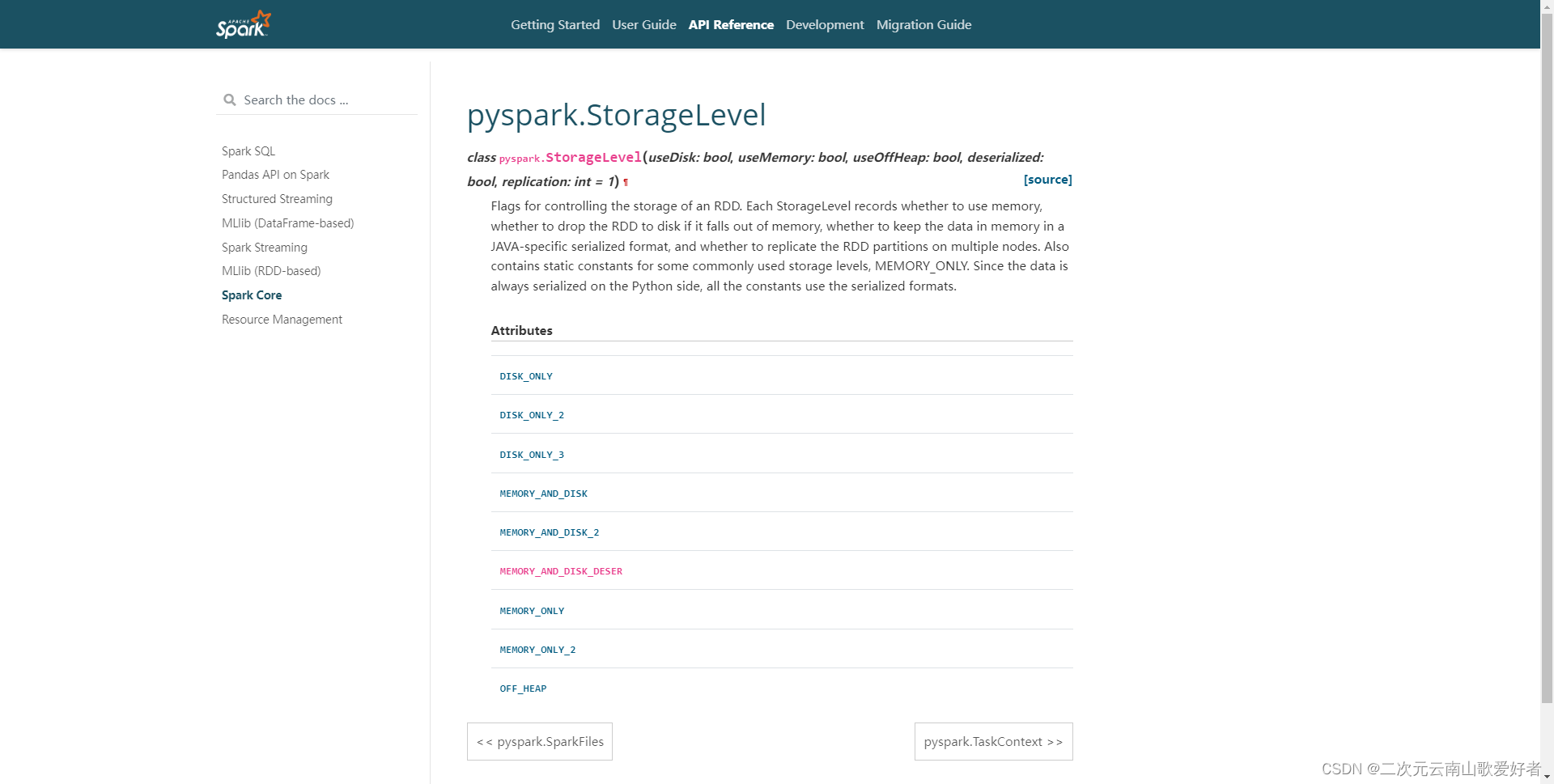
其中,DISK_ONLY即只存储到磁盘;MEMORY_AND_DISK模式,会先存储到内存,内存不够再存储到磁盘;MEMORY_ONLY只会存储到内存。
不同的DISK_ONLY策略会涉及到是否序列化等选项,设计时候先选择MEMORY_AND_DISK。
其他一些持久化的内容参考:RDD持久化 | Spark 编程指南简体中文版
3.2.2 关于pyspark运行模式
参考:Spark快速入门系列(2) | Spark 运行模式之Local本地模式 - 腾讯云开发者社区-腾讯云
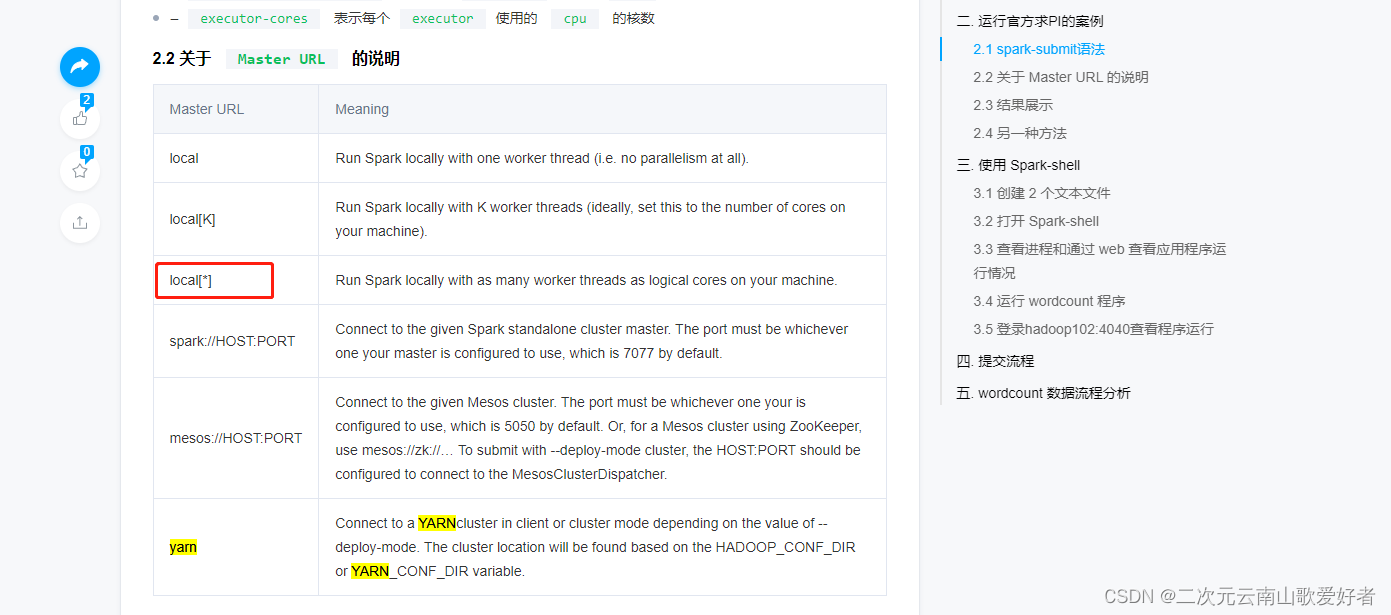
简单说,pyspark支持运行local模式,local模式本地启动一个或多个线程;支持spark://HOST:PORT模式,可以连接到远程的spark机器;也支持mesos和yarn集群模式。
实际上,spark还支持运行stand-alone的本地集群模式。但是pyspark不支持stanalone模式。

补充:原生的spark还支持local-cluster模式:
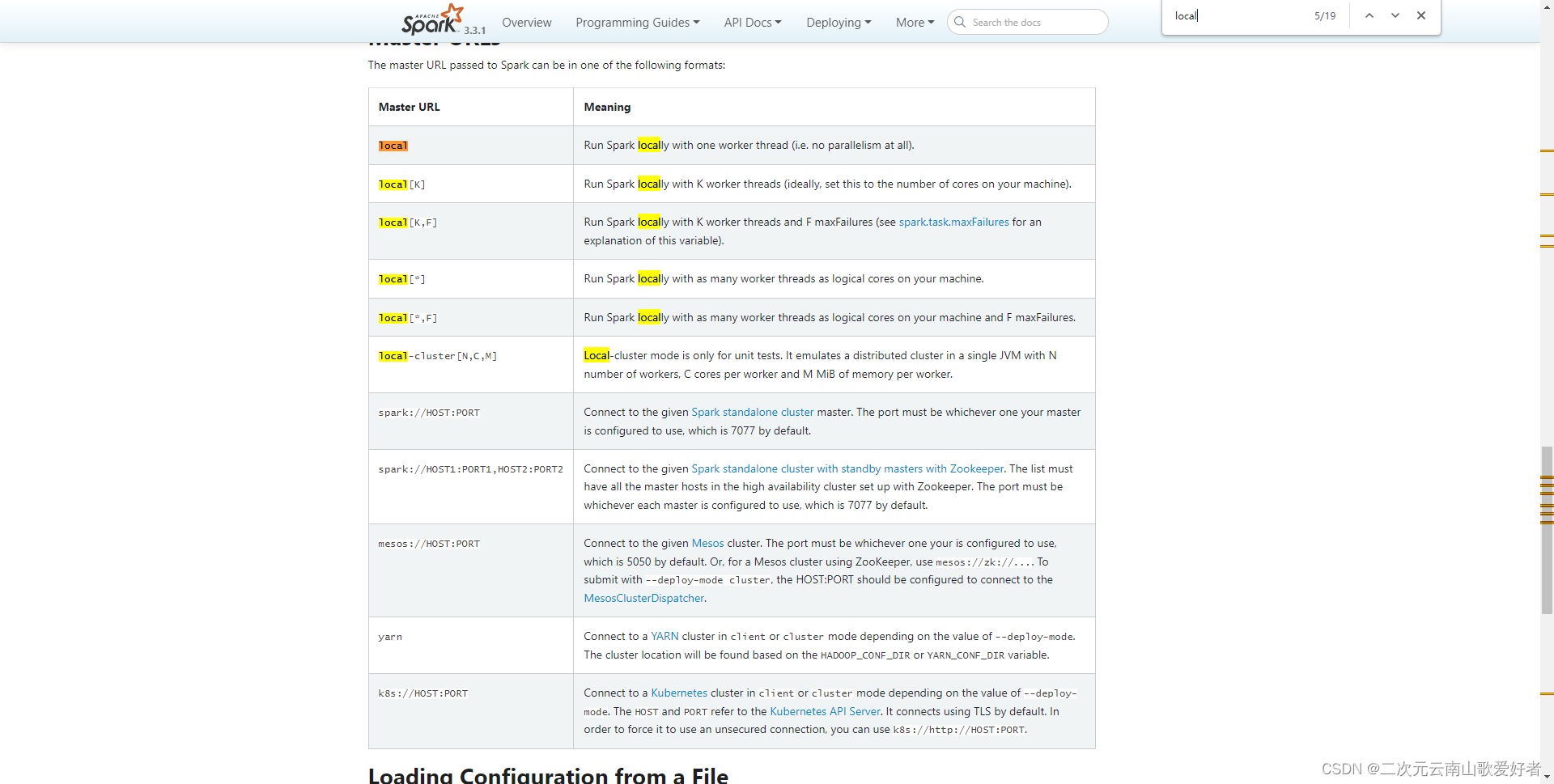
但是pyspark似乎不支持。印象中pyspark配置local-cluster也不会报错,但和cluster没啥区别。参考 Submitting Applications - Spark 3.3.1 Documentation
3.2.3 关于pyspark读取文件:
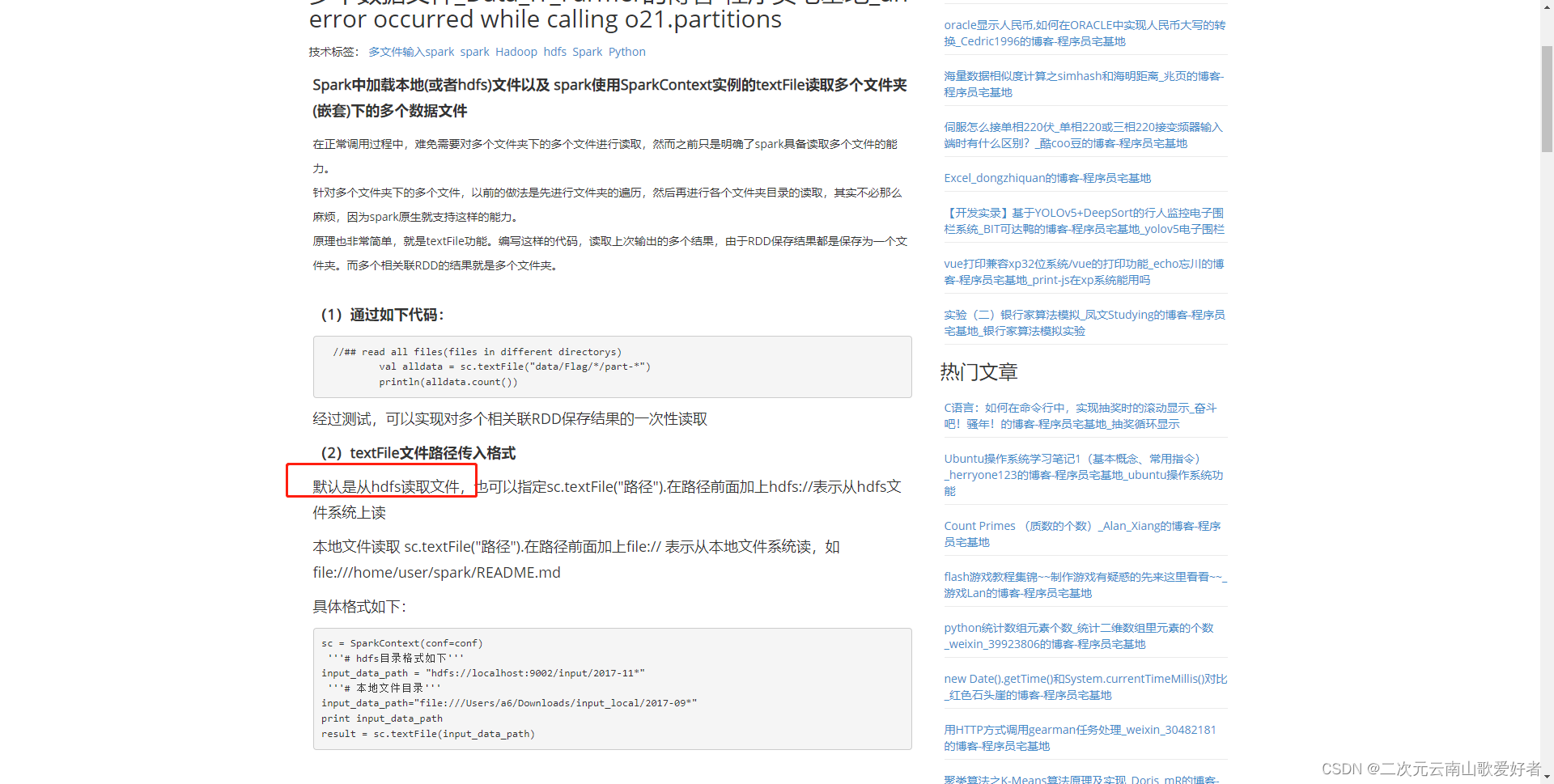
pyspark会默认读取hdfs文件,没有安装hdfs系统才会读取本地文件。如果安装了hdfs且路径不对也会报错,可以用前缀"file://"来指定本地文件,用"hdfs://"指定hdfs文件系统。参考:Spark中加载本地(或者hdfs)文件以及 spark使用SparkContext实例的textFile读取多个文件夹(嵌套)下的多个数据文件_Data_IT_Farmer的博客-程序员宅基地_an error occurred while calling o21.partitions - 程序员宅基地
3.3 支持spark集群的配置
spark支持yanr集群部署也支持mesos集群部署。其中spark的yarn集群和hadoop的yarn集群是同一个设计理念(不确定,如果描述有误欢迎补充)。
具体步骤参考: https://blog.csdn.net/u011250186/article/details/110963093
下图中标注了一些原文的注意事项,可以注意到,pyspark进行集群的submit工作时候,需要上传python包,并指定运行的python文件。

(因为客户是个银行爸爸,银行有spark2.4.3的集群,所以肯定要上集群模式,于是就命令行模式就没用了……白干了…… )
关于Mesos,贴一下官方文档:Running Spark on Mesos - Spark 3.3.1 Documentation 由于实际工作中没有使用到,就不赘述了。
3.4 支持docker和kubernetes
支持docker很简单,就是在编写dockerFile的时候,安装java(pyspark也依赖java环境),安装相应版本的python和pyspark依赖;安装xxx组件;docker打包。
编译好了docker容器的tar包,基本就等于完成了kubernetes的镜像。由于ETL数据清洗是个定时任务,所以使用到了kubernetes的定时任务调度执行。 kubernetes的cronjob定时任务参考:使用 CronJob 运行自动化任务 | Kubernetes 即可。

不过实际使用中,又用到了前东家自研的一个k8s管理平台,该平台配置了前端页面,可以可视化操作kubernetes。
(结果后端体调试客户的kubernetes集群还需要自己装k9s进行远程调试,也不知道怎么设计的……)
4. 性能对比
以下是100G数据处理耗时对比:
| 单机 | 厂内机器1 | 厂内机器2 | 备注 |
| 配置 | 16G内存 8核 | 64G内存 32核 | |
| 是否安装hadoop | 是 | 是 | |
| 老版本xxx单线程运行耗时 | 2小时 | 50分钟 | 机器一和机器2的磁盘性能也有差距 |
| 新版本xxx spark模式配置 | local[16] | local[64] | |
| 新版本xxx spark模式耗时 | 20分钟 | 8分钟 |
可见运行速度有了数倍提升。(显然的……毕竟从单线程到多线程……)
同时机器性能也影响处理耗时。
另外还涉及到linux的超线程技术:
linux 超线程及其原理,以及如何查看是否开启了超线程_Arlingtonroad的博客-CSDN博客_linux 超线程
复制一下超线程技术的原理:
一个线程在执行时会占用CPU资源,其他线程想要得到执行就必须等待该线程将CPU资源让出。
利用超线程技术,模拟出的两个逻辑内核共享同一个CPU资源,所以同一时刻可以有两个线程都占用CPU资源,因此这两个线程都可以得到执行,这就是实现同一时间执行两个线程的并行操作。
比如说:
有个单核的CPU,想要运行一个多线程的程序,通常情况下,只能是由Cpu在线程之间来回调度,但是当开启了超线程之后,可以在一个线程执行整数指令集的时候,而恰好在这个时候,另一个线程执行浮点指令集,而这两个指令集分别由整数指令单元和浮点指令单元来执行。就可以同时执行这两个线程,这就叫超线程。而且实际上,是有大量资源被闲置着的。超线程技术允许两个线程同时不冲突地使用CPU中的资源。指令单元闲置,可以通过超线程的技术来达到提高利用率。这叫做硬件多线程技术。
5. 踩坑记录
5.1 pyspark 对python版本的支持
当时组内python的版本强制为py3.6,不过很多人开发时候都用py3.8或者3.9(那时候3.10没出)。
结果运行时候报错:
TypeError:an integer is required(got type bytes)
这个原因是……当时pyspark3.x版本不支持python3.8(那时候python3.8刚出不久)。
pyspark踩坑:Python worker failed to connect back和an integer is required - 欣欣姐 - 博客园
幸好客户的spark版本是2.4.x,所以最后使用python 3.6版本就好。
pyspark的release note 参考:pyspark · PyPI
5.2 pyspark 依赖出错
运行时候报错:
py4j.protocol.Py4JError: org.apache.spark.api.python.PythonUtils.isEncryptionEnabled does not exist in the JVM
# 来源:https://bbs.huaweicloud.com/blogs/373322看着是个很唬人的问题,最后发现就是pyspark依赖没找到,解决方法参考pyspark开发环境搭建_路过的好心人1的博客-CSDN博客_findspark.init():
使用findspark.init()解决。
5.3 pyspark进程无法停止
这个问题暴露在实际部署阶段。那时候使用k9s查看pyspark定时任务的运行状态,结果经常任务卡住,没有在预定时间推出进程,导致service各种出错。
这个是因为spark的算子分为transformation和action两大类型。参考
简单说,transformation就是从rdd转为rdd,action则是对rdd处理后不会转为rdd。
transformation是懒加载的(参考:Spark:常用transformation及action,spark算子详解_51CTO博客_spark的transformation算子)

所以有时候会有这种case:
读取原始文件,生成了rdd1,rdd1转化为rdd2并触发action;与此同时rdd1又被转化为rdd3,但是没有触发action,导致整个程序卡住。
最后的做法就是简单粗暴地在每次rddtransformation之后,都进行一次action操作(df.show)PySpark show() - Display DataFrame Contents in Table - Spark by {Examples}
这样也方便结合kubernetes的kubectl logs命令,对问题进行跟踪排查。
5.4 dataframe的join问题
数据清洗的过程中难免遇到join操作,因为设计时候不支持SQL(真实原因是:对组内某些研发而言,写SQL就跟要他们命一样……),所以没有办法从写spark sql层面进行处理。
最后是使用dataFrame的join功能进行操作。
pyspark其实是支持join on多个字段,并且也不要求字段一样(参考:
pyspark.sql.DataFrame.join — PySpark 3.1.2 documentation)

但是这有一个前提,就是df的列名应该是提前设置好的(
How to join on multiple columns in Pyspark? - GeeksforGeeks):

但是这种用法在当时设计时候就很难处理……因为属性名称等于说是写死的。最后只能妥协,暂时采用join的on单字段的方法。这就导致本设计下,df的join十分的难用,只能join on 单个字段,且这两个字段名称要一致(来源一文让你记住Pyspark下DataFrame的7种的Join 效果_独家雨天的博客-CSDN博客_pyspark left join):

ps:现在回头看,其实如果用反python的exec,应该能解决这个问题,但可能隐藏的坑也会很多
5.5 文件转化问题
pyspark本身其实支持直接读取本地文件和hdfs文件:
(参考PySpark实现从HDFS读取数据实现WordCount - 简书)
换句话说,pyspark在读取文件时候,会尝试从hdfs上进行读取,如果hdfs系统不存在,然后才会尝试读取本地文件(不过如果装了hdfs,且hdfs的路径出错,是否会出错就没有试过了)。
但是有时候pyspark想要根据字符串路径,指定读取hdfs文件,需要使用py4j操作:
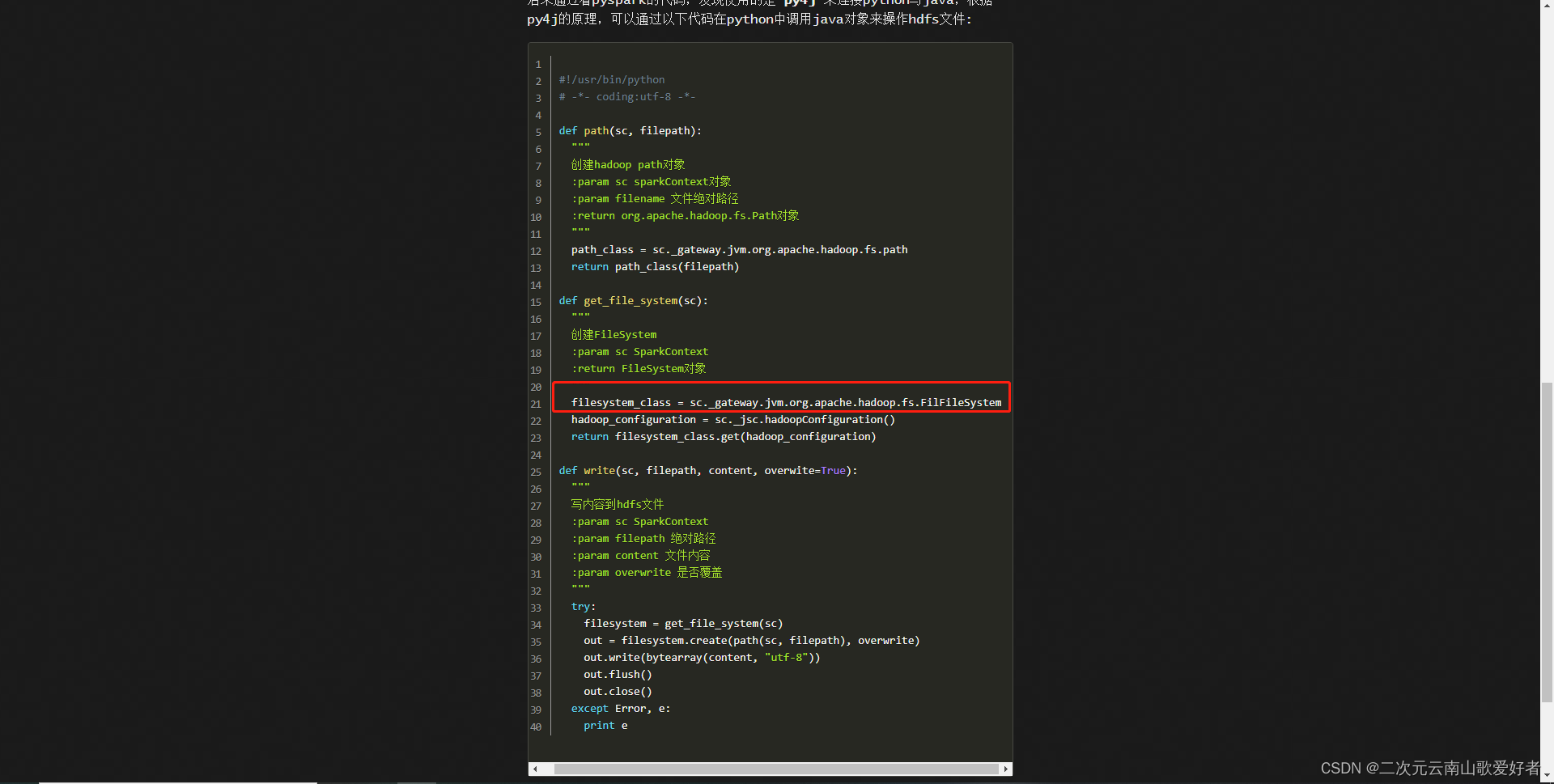
py4j 介绍参考官网: Welcome to Py4J — Py4J
具体背景有点忘记了,不过大概就是某个场景下没法用sc.textFile,需要手动操作,调用py4j处理,语法还是比较绕的。
5.6 pyspark 接入pandas:
当时还要将结果接入pandas。
pandas是一个Python的统计库。当时另一个组内的框架是基于pandas的。pandas教程参考:Pandas 数据结构 – DataFrame | 菜鸟教程
为了加快pandas读取文件的速率,另一个统计框架的数据源必须是pickle文件。pickle文件读取参考:
Pandas读取文件的效率-CSV VS Pickle - 知乎
实际上spark是支持将dataFrame存储为pickle文件的:
pyspark.SparkContext.pickleFile — PySpark 3.3.1 documentation

但是这么 生成的pickle文件,pandas读取不了……
最后只能手动在代码中,在spark执行完成之后,将rdd转为json再存储为pickle文件。
(不要问为啥不直接用spark进行统计,要是这么做了另一个轮子就废了,轮子的发明者会kill me without mercy)
5.7 spark集群无法使用命令行操作
需要上传python编译好的包到客户的spark集群上,并且无法使用命令行方式;
5.8 python 伪多线程问题
参考: 为什么老说python是伪多线程,怎么解决?_Badrain_Guo的博客-CSDN博客_python 伪多线程
简单而言,python中有一个GIL( the Global Interpreter Lock ,全局解释锁),是常规 python 解释器的核心部件,是一个用于保护 Python 内部对象的全局锁(在进程空间中唯一),保障了解释器的线程安全。
在测试过程中,由于没有scala版本或者java版本的真.多线程处理进行对比,无法确定pyspark的性能是否弱于scala或者java版本的spark。不过根据查到的一些资料显示,pyspark在性能上的确比scala spark要差一些。
Spark环境中Python和Scala对比_一只不会爬的虫子的博客-CSDN博客_pyspark scala 对比

6.总结
0. spark很牛逼,但也不建议文章中这么用……














 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









