






此篇内容仅为1.日志数据清洗
数据下载:百度网盘 请输入提取码 提取码:6uw8
需求:对test.log中的数据进行如下操作
1.日志数据清洗
2.用户留存分析
3.活跃用户分析
4.将各结果导入mysql
使用工具:IDEA,Maven工程下的Scala项目
数据清洗原理解析:
/**此项目清洗数据的内容主要是解析url内的用户行为 1.将初始数据转换成dataFrame型(代码中为orgDF),结构为row(表示一个行的数据),schema(描述dataFrame结构,也可以理解为行的各个属性名称) 2.进行一系列初筛后,得出url解析出来的RDD[ROW](代码中为detailRDD),新的schema(代码中为detailSchema),组成新的dataFrame */
pom.xml依赖设置如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.spark</groupId>
<artifactId>stream</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<spark.version>2.4.3</spark.version>
<scala.version>2.12</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-catalyst_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>14.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scalikejdbc/scalikejdbc -->
<dependency>
<groupId>org.scalikejdbc</groupId>
<artifactId>scalikejdbc_${scala.version}</artifactId>
<version>3.3.5</version><!-- mysql " mysql-connector-java -->
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.17</version>
</dependency>
</dependencies>
</project>一、日志数据清洗
1)分析test.log数据
其由event_time
url
method
status
sip
user_uip
action_prepend
action_client
这八个字段组成,此次清洗内容主要针对url内各用户的不同的响应分析
2)建立spark程序,从本地磁盘读取数据生成rdd(string)
val spark = SparkSession.builder().master("local[1]").appName("DataClear").getOrCreate()
import spark.implicits._
val sc = spark.sparkContext
val linesRDD = sc.textFile("D:\\CODE\\test.log")
//sc.textFile是常用的将文本数据直接转化为rdd的方法3)进行初次清洗数据
test.log中各列属性由 '\t' 进行分隔,所以可以首先用split将每一列属性切分出来
以及为了最后初次清洗出来数据的统一完整性(保证每一行数据都有八列属性值),我们还要使用filter方法将字段少于8的行过滤
再使用trim将每行的每一列数据的非空白字段的部分截取出来
//按照 \t 分割数据,过滤字段数(即列数)少于8的
val line1 = linesRDD.map(x => x.split("\t"))
//取字符串内非空白字段(trim) rdd与row结合即RDD[ROW]
val rdd = line1.filter(x => x.length == 8).map(x => Row(x(0).trim, x(1).trim, x(2).trim, x(3).trim, x(4).trim, x(5).trim, x(6).trim, x(7).trim))创建structType实例后再创建dataFrame,因为我们最终数据是以dataFrame型的数据进行存储
而dataFrame组成结构是(RDD,Schema)即一个RDD[ROW]型和一个StructType型组成
dataFrame结构也可以理解为RDD是一行具体的数据,Schema是每行数据的属性名称
//创建structType实例,设置字段名和类型
val schema = StructType(Array(
StructField("event_time", StringType), //用户浏览时间
StructField("url", StringType), //URL地址
StructField("method", StringType), //GET
StructField("status", StringType), //状态码
StructField("sip", StringType), //IP地址
StructField("user_uip", StringType), //用户UID
StructField("action_prepend", StringType), //用户操作前置
StructField("action_client", StringType) //用户客户端
))
//创建dataFrame
val orgDF = spark.createDataFrame(rdd, schema)
orgDF.show(5)4)具体到主要对url字段进行清洗
*以第一,第二列的数据对所有行数据进行去重
*过滤状态码非200的行
*过滤event_time为空的数据
*将url按照'&'和'='切割
//按照第一列和第二列对数据数据去重,过滤掉状态码非200,过滤掉event_time为空的数据
//orgDF进行sql操作之后变成ds1 dataset[row]类型(也可以叫做dataFrame,只是dataset[row]比dataFrame封装内容更丰富,本质上还是属于dataframe范畴)
val ds1 = orgDF.dropDuplicates("event_time", "url")
.filter(x => x(3) == "200")
.filter(x => StringUtils.isNotEmpty(x(0).toString))
//将url按照"&"以及"="切割,即按照userUID
//userSID//userUIP//actionClient//actionBegin//actionEnd//actionType
//actionPrepend//actionTest//ifEquipment//actionName//id//progress进行切割
val dfDetail = ds1.map(row => {
val urlArray = row.getAs[String]("url").split("\\?") //将?前后的内容作切割
var map = Map("params" -> "null")
if (urlArray.length == 2) { //此时urlArray分成 (?之前的内容,datacenter....)
map = urlArray(1)
.split("&").map(x => x.split("=")) //&是各属性之间的分隔符,=是各属性值指向什么方法或内容
.filter(_.length == 2).map(x => (x(0), x(1))) //将按照=切分后的数据存入map
.toMap
} //.filter(_.length == 2)过滤掉以'='分割之后少于两个元素(即=两边出现的属性不为2个,不符合清洗标准的数据)的Array后再将各属性指向的内容map成规范化的式子
(row.getAs[String]("event_time"), //这里用getAs是因为它所对应的内容是每一行的url中必定有的元素
row.getAs[String]("user_uip"),
row.getAs[String]("method"),
row.getAs[String]("status"),
row.getAs[String]("sip"),
map.getOrElse("actionBegin", ""), //这里用getOrElse是因为url中不一定有这些元素,如果没有那就用空来替代异常值
map.getOrElse("actionEnd", ""),
map.getOrElse("userUID", ""),
map.getOrElse("userSID", ""),
map.getOrElse("userUIP", ""),
map.getOrElse("actionClient", ""),
map.getOrElse("actionType", ""),
map.getOrElse("actionPrepend", ""),
map.getOrElse("actionTest", ""),
map.getOrElse("ifEquipment", ""),
map.getOrElse("actionName", ""),
map.getOrElse("progress", ""),
map.getOrElse("id", "")
)
}).toDF() //将ds1 dataSet[ROW]转成dfDetail 正常的dataFrame型清洗完毕后,"dfDetail"接收的是一组dataFrame数据,但是我们最后新的结构是以url的各个属性为框架的dataFrame
所以我们需要重构schema,即再定义一个新的"detailSchema",用来存放描述新的dataFrame结构的schema
将我们清洗提取出的"dfDetail"这个dataFrame数据用 .rdd 转化成RDD[ROW]格式,最后与以上述所述重构的schema创建detailDF这个新的dataFrame结构
val detailRDD = dfDetail.rdd //.rdd将dataFrame转换成rdd[ROW]类型
val detailSchema = StructType(Array( //重新定义schema结构
StructField("event_time", StringType),
StructField("user_uip", StringType),
StructField("method", StringType),
StructField("status", StringType),
StructField("sip", StringType),
StructField("actionBegin", StringType),
StructField("actionEnd", StringType),
StructField("userUID", StringType),
StructField("userSID", StringType),
StructField("userUIP", StringType),
StructField("actionClient", StringType),
StructField("actionType", StringType),
StructField("actionPrepend", StringType),
StructField("actionTest", StringType),
StructField("ifEquipment", StringType),
StructField("actionName", StringType),
StructField("progress", StringType),
StructField("id", StringType)
))
val detailDF = spark.createDataFrame(detailRDD, detailSchema) //重新创建新的dataFrame结构
detailDF.show(5,false) //truncate为false表示可以显示超过20个字符的数据最后将清洗完毕的数据存入mysql
作者事先在Linux中部署好了 mysql,在终端输入mysql -u root -p,输入mysql密码即可登入mysql
并创建了一个名为spark_dataclear的数据库

回到IDEA,用JDBC连接mysql将数据存入spark_dataclear数据库中
val url = "jdbc:mysql://hadoop01:3306/spark_dataclear"
val prop = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "123456")
prop.setProperty("driver", "com.mysql.jdbc.Driver")
println("开始写入mysql")
detailDF.write.mode(saveMode = "overwrite").jdbc(url, "logDetail", prop) //指定输出到mysql的文件名为logDetail
// orgDF.write.mode("overwrite").jdbc(url,"",prop)
println("写入mysql结束")最后执行整个代码,部分代码结果如下
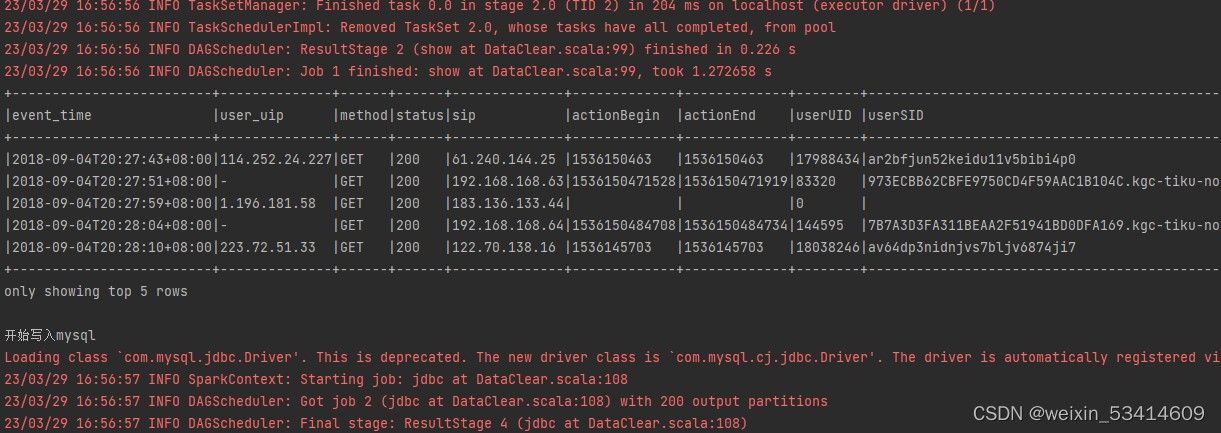

在mysql中查询表也有相应的数据结果

附完整代码:
import org.apache.commons.lang.StringUtils
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
import java.util.Properties
/**原理解释:此项目清洗数据的内容主要是解析url内的用户行为
1.将初始数据转换成dataFrame型(代码中为orgDF),结构为row(表示一个行的数据),schema(描述dataFrame结构,也可以理解为行的各个属性名称)
2.进行一系列初筛后,得出url解析出来的RDD[ROW](代码中为detailRDD),新的schema(代码中为detailSchema),组成新的dataFrame
*/
object DataClear {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[1]").appName("DataClear").getOrCreate()
import spark.implicits._
val sc = spark.sparkContext
val linesRDD = sc.textFile("D:\\CODE\\test.log")
//按照 \t 分割数据,过滤字段数(即列数)少于8的
val line1 = linesRDD.map(x => x.split("\t"))
//取字符串内非空白字段(trim) rdd与row结合即RDD[ROW]
val rdd = line1.filter(x => x.length == 8).map(x => Row(x(0).trim, x(1).trim, x(2).trim, x(3).trim, x(4).trim, x(5).trim, x(6).trim, x(7).trim))
// rdd.foreach(println)
//创建structType实例,设置字段名和类型
val schema = StructType(Array(
StructField("event_time", StringType), //用户浏览时间
StructField("url", StringType), //URL地址
StructField("method", StringType), //GET
StructField("status", StringType), //状态码
StructField("sip", StringType), //IP地址
StructField("user_uip", StringType), //用户UID
StructField("action_prepend", StringType), //用户操作前置
StructField("action_client", StringType) //用户客户端
))
//创建dataFrame
val orgDF = spark.createDataFrame(rdd, schema)
orgDF.show(5)
//按照第一列和第二列对数据数据去重,过滤掉状态码非200,过滤掉event_time为空的数据
//orgDF进行sql操作之后变成ds1 dataset[row]类型(也可以叫做dataFrame,只是dataset[row]比dataFrame封装内容更丰富,本质上还是属于dataframe范畴)
val ds1 = orgDF.dropDuplicates("event_time", "url")
.filter(x => x(3) == "200")
.filter(x => StringUtils.isNotEmpty(x(0).toString))
//将url按照"&"以及"="切割,即按照userUID
//userSID//userUIP//actionClient//actionBegin//actionEnd//actionType
//actionPrepend//actionTest//ifEquipment//actionName//id//progress进行切割
val dfDetail = ds1.map(row => {
val urlArray = row.getAs[String]("url").split("\\?") //将?前后的内容作切割
var map = Map("params" -> "null")
if (urlArray.length == 2) { //此时urlArray分成 (?之前的内容,datacenter....)
map = urlArray(1)
.split("&").map(x => x.split("=")) //&是各属性之间的分隔符,=是各属性值指向什么方法或内容
.filter(_.length == 2).map(x => (x(0), x(1))) //将按照=切分后的数据存入map
.toMap
} //.filter(_.length == 2)过滤掉分割之后还有两个元素(即两个&内的属性有多个,不符合清洗标准的数据)的Array后再将各属性指向的内容map成规范化的式子
(row.getAs[String]("event_time"), //这里用getAs是因为它所对应的内容是每一行的url中必定有的元素
row.getAs[String]("user_uip"),
row.getAs[String]("method"),
row.getAs[String]("status"),
row.getAs[String]("sip"),
map.getOrElse("actionBegin", ""), //这里用getOrElse是因为url中不一定有这些元素,如果没有那就用空来替代异常值
map.getOrElse("actionEnd", ""),
map.getOrElse("userUID", ""),
map.getOrElse("userSID", ""),
map.getOrElse("userUIP", ""),
map.getOrElse("actionClient", ""),
map.getOrElse("actionType", ""),
map.getOrElse("actionPrepend", ""),
map.getOrElse("actionTest", ""),
map.getOrElse("ifEquipment", ""),
map.getOrElse("actionName", ""),
map.getOrElse("progress", ""),
map.getOrElse("id", "")
)
}).toDF() //将ds1 dataSet[ROW]转成dfDetail 正常的dataFrame型
val detailRDD = dfDetail.rdd //.rdd将dataFrame转换成rdd[ROW]类型
val detailSchema = StructType(Array( //重新定义schema结构
StructField("event_time", StringType),
StructField("user_uip", StringType),
StructField("method", StringType),
StructField("status", StringType),
StructField("sip", StringType),
StructField("actionBegin", StringType),
StructField("actionEnd", StringType),
StructField("userUID", StringType),
StructField("userSID", StringType),
StructField("userUIP", StringType),
StructField("actionClient", StringType),
StructField("actionType", StringType),
StructField("actionPrepend", StringType),
StructField("actionTest", StringType),
StructField("ifEquipment", StringType),
StructField("actionName", StringType),
StructField("progress", StringType),
StructField("id", StringType)
))
val detailDF = spark.createDataFrame(detailRDD, detailSchema) //重新创建新的dataFrame结构
detailDF.show(5,false) //truncate为false表示可以显示超过20个字符的数据
val url = "jdbc:mysql://hadoop01:3306/spark_dataclear"
val prop = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "123456")
prop.setProperty("driver", "com.mysql.jdbc.Driver")
println("开始写入mysql")
detailDF.write.mode(saveMode = "overwrite").jdbc(url, "logDetail", prop)
// orgDF.write.mode("overwrite").jdbc(url,"",prop)
println("写入mysql结束")
}
}














 1628
1628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









