






是什么?
是一个框架和分布式处理引擎,擅长处理有界和无界的数据集,是一个流批统一的处理框架
流处理和批处理是什么?
流处理:来一个处理一个,就像是流水线工作,它是即时处理的,是一个实时的处理;
批处理:顾名思义,一次读取一批数据,对这一批数据一起处理,它不是实时处理,是一种离线的处理
数据的生成,一般都是流式的。
Flink的核心特性
Flink作为第三代分布式流处理器,拥有以下核心特性:
1. 高吞吐和低延迟。每秒处理百万个事件,毫秒级延迟。
2. 结果的准确性。提供了事件时间(event-time)和处理时间(processing-time)语义,对于乱序事件流,事件时间语义能够提供一致且准确的结果。
3. 精确一次(exactly-once)的状态一致性保证。
4. 可以连接到最常用的存储系统。如 HDFS、S3、JDBC、Apache Kafka等。
5. 高可用。
6. 能够更新应用程序代码将作业(jobs)迁移到不同的Flink集群,而不会丢失应用程序的状态。
拥有分层API(图源:剑指大数据)
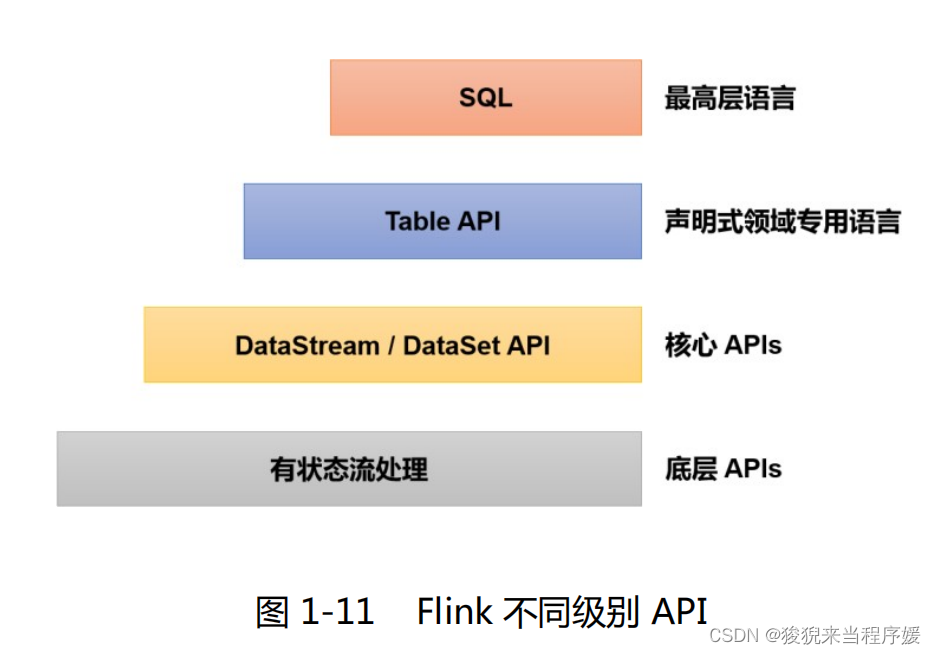
其中 DataStream用于处理有界或无界数据流, DataSet 用于处理有界数据流。
Spark与Flink的区别
Spark 核心是批处理,尝试在批处理之上支持流计算,那么对于它来说,像Flink这样的实时计算,就会被看成一个个微小的批处理,因此对于Spark而言,并不是真正意义上的“流处理”,而是一个个“微批次”处理。
因为总是进行批处理,所以有一个积攒的过程,会造成额外开销,在低延迟的表现上就不如Flink。
Spark 的底层数据模型是 RDD (弹性分布式数据集),Spark Streaming 进行微批处理的底层接口 DStream ,实际上处理的也是一组组小批数据 RDD 的集合。

而Flink 的核心是流处理,因此它认为即使是批处理,也可以被统一为流处理。它将实时数据当做标准的、无界的流,而将离线数据当做有界的流。
吞吐量小,在海量数据的批处理领域,其优势不如Spark明显。
Flink 的基本数据模型是基于 DataFlow (数据流)及事件(event)序列的。
一个事件在一个节点处理完毕后可以直接发送给下一个节点进行处理。
无界数据流:有头没尾,数据的生成和传递会开始但永远不会结束。【因为数据一直在生成,因此无法等到数据全部传递完毕,因此必须做连续处理,为保证准确性,又必须按顺序处理到来的数据】
有界数据流:有头有尾,数据流有明确定义的开始和结尾。【因为数据的传递有结束,因此可以等待数据全部传递完毕再进行处理,因此不需要严格保证数据的顺序,因为所有数据抵达后,总能按正确的顺序对数据进行排列。】















 3671
3671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









