







Part 1: Titanic 数据集
- urllib
python3了,urllib2已经没了,现在只剩下了urllib,并且被分成了三大部分,.request
.parse 和 .error
并且再python3中不应该import urllib ,而应该直接导入对应的模块
比如说我想用request功能
那么我就得import urllib.request 这样才能正常使用
比较蛋疼
可参考:https://blog.csdn.net/woshikuangdage/article/details/82022150
下载泰坦尼克数据集
import urllib.request
url = "https://raw.githubusercontent.com/GokuMohandas/practicalAI/master/data/titanic.csv"
response = urllib.request.urlopen(url)
html = response.read()
with open('itanic.csv', 'wb') as f:
f.write(html)
#创建一个CSV文件,但此时并没有真正的写入,而是还存在与内存中。需要执行f.close()
以后才可以(但是有自动关闭的机制)
- 数据概览
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df.head() #查看前五行

说明:
pclass: 船舱等级 class of travel
name: 全名 full name of the passenger
sex: 性别 gender
age: 年龄 numerical age
sibsp: 船上旁系亲属,配偶数 # of siblings/spouse aboard
parch: 船上直系亲属(父母,子女)数 number of parents/child aboard
ticket: 船票号 ticket number
fare: 船票费用 cost of the ticket
cabin: 房间位置 location of room
emarked: 上船的港口 (C - 瑟堡Cherbourg, S - 南安普顿Southampton, Q = 皇后镇Queenstown)
survived: 是否存活 (0 - 死亡, 1 - 存活)
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df.name.head() //分类别查看前五行
0 Allen, Miss. Elisabeth Walton
1 Allison, Master. Hudson Trevor
2 Allison, Miss. Helen Loraine
3 Allison, Mr. Hudson Joshua Creighton
4 Allison, Mrs. Hudson J C (Bessie Waldo Daniels)
Name: name, dtype: object
- 叙述性统计
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df.describe() #叙述性统计

说明:
count:数量
mean:平均值
std:标准差
min:最小值
25% :第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第
25%的数字。
50% :中位数
75% :同上类似
max :最大值
- 获取列信息
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df.ticket #获取ticket的信息
结果:
0 24160
1 113781
2 113781
3 113781
4 113781
...
1304 2665
1305 2665
1306 2656
1307 2670
1308 315082
Name: ticket, Length: 1309, dtype: object
- 绘制直方图
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df.age.hist() #绘制age信息直方图

- 返回唯一值
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df.age.unique() #返回age中的唯一值
array([29. , 0.9167, 2. , 30. , 25. , 48. , 63. ,
39. , 53. , 71. , 47. , 18. , 24. , 26. ,
80. , nan, 50. , 32. , 36. , 37. , 42. ,
19. , 35. , 28. , 45. , 40. , 58. , 22. ,
41. , 44. , 59. , 60. , 33. , 17. , 11. ,
14. , 49. , 76. , 46. , 27. , 64. , 55. ,
70. , 38. , 51. , 31. , 4. , 54. , 23. ,
43. , 52. , 16. , 32.5 , 21. , 15. , 65. ,
28.5 , 45.5 , 56. , 13. , 61. , 34. , 6. ,
57. , 62. , 67. , 1. , 12. , 20. , 0.8333,
8. , 0.6667, 7. , 3. , 36.5 , 18.5 , 5. ,
66. , 9. , 0.75 , 70.5 , 22.5 , 0.3333, 0.1667,
40.5 , 10. , 23.5 , 34.5 , 20.5 , 30.5 , 55.5 ,
38.5 , 14.5 , 24.5 , 60.5 , 74. , 0.4167, 11.5 ,
26.5 ])
- 简单筛选数据
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df[df["sex"]=="female"].head() #筛选男性乘客的头部

- 排序
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df.sort_values("age", ascending=False).head()
#按age列进行降序排列,返回头部

DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind=
'quicksort', na_position='last')
参数说明:
by:str or list of str;如果axis=0,那么by="列名",即按列排;如果axis=1,那么
by="行名",按行排;
ascending:布尔型,True则升序,可以是[True,False],默认升序
inplace:布尔型,是否用排序后的数据框替换现有的数据框
kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’
不用太关心
na_position : {‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面
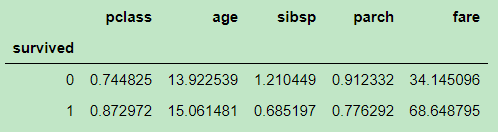
- 数据聚合
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
survived_group = df.groupby("survived") #选中survived列
survived_group.std() #取得标准差
- 使用索引用 iloc 和 loc 查看数据
#loc即location ; iloc即integer location
#两者差不多,loc只能索引列,但iloc还可以索引位置
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df.iloc[0,:] #索引第一行
结果:
pclass 1
name Allen, Miss. Elisabeth Walton
sex female
age 29
sibsp 0
parch 0
ticket 24160
fare 211.338
cabin B5
embarked S
survived 1
Name: 0, dtype: object
说明:
iloc 函数通过索引中的特定位置查看某行或列的数据,所以这里的索引值只接受整数
iloc函数不仅可以索引某一行或者列,事实上可以索引任意位置
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df.iloc[0,1] #索引第一行第二列的信息
#'Allen, Miss. Elisabeth Walton'
- 自己创建一个泰塔尼克数据集?
- DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表。
- 它有点像matlab的矩阵,但是matlab的矩阵只能放数值型值,DataFrame的单元格可以存放数值、字符串等
- DataFrame可以设置列名columns与行名index,可以通过像matlab一样通过位置获取数据也可以通过列名和行名定位
- 直接创建
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(4,4),index = list('0123'),columns = list('ABCD'))
df
A B C D
0 1.777543 1.247423 1.745523 -0.331489
1 -0.336789 -0.001896 -1.099445 -0.207536
2 0.150644 0.829252 -0.574615 1.445202
3 0.722727 -1.159412 0.750426 0.598207
- 使用字典进行创建
import pandas as pd
import numpy as np
dict0 = {'name':["红红","兰兰"],"age":[18,18]}
df = pd.DataFrame(dict0)
df
name age
0 红红 18
1 兰兰 18
- pandas中axis参数
- axis英文释义是轴的意思
- 轴用来为超过一维的数组定义的属性,二维数据拥有两个轴:第0轴沿着行的垂直往下,第1轴沿着列的方向水平延伸。
- 可按下图进行理解

- axis=0 表示进行上下遍历 ;axis=1 表示进行左右遍历
- 很多时候如果不给定axis,那么默认axis=0
- 下面给定例子说明:
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
pd.isnull(df.head()) #判断数据类型是否NaN,并返回头部信息
#此时判断的是所有的坐标位置
pclass name sex age sibsp parch ticket fare cabin embarked survived
0 False False False False False False False False False False False
1 False False False False False False False False False False False
2 False False False False False False False False False False False
3 False False False False False False False False False False False
4 False False False False False False False False False False False
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
pd.isnull(df).any(axis=0) #上下进行筛选出各列是不是存在NaN
pclass False
name False
sex False
age True
sibsp False
parch False
ticket False
fare True
cabin True
embarked True
survived False
dtype: bool
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
#df[pd.isnull(df).any(axis=1)].head()
pd.isnull(df).any(axis=1) #左右进行筛选出各行是不是NaN
0 False
1 False
2 False
3 False
4 False
...
1304 True
1305 True
1306 True
1307 True
1308 True
Length: 1309, dtype: bool
- drop注意区别
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df.dropna() #df.dropna(axis=0)一样的结果
# 删除含有NaN值的行

import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df.dropna(axis=1) # 删除含有NaN值的列

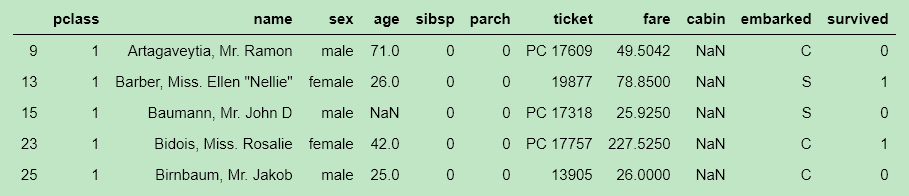
- 数据筛选查找
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df[pd.isnull(df).any(axis=1)].head()
#筛选出存在NaN值的行并且返回头部信息
14. 删除数据
- 删除columns
df = df.drop(["name", "cabin", "ticket"], axis=1)
# 删除暂时不需要的数据条目,其中axis是必须给定的
df.head()

- 删除index(很少用但是确实可以)
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
df = df.drop([0,1], axis=0)
df.head()

- 特征值映射
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
# 特征值映射
df['sex'] = df['sex'].map( {'female': 0, 'male': 1} ).astype(int)
#对于sex列,0映射到female,1映射到male;并设置数据类型为int
df["embarked"] = df['embarked'].dropna().map( {'S':0, 'C':1, 'Q':2} ).astype(int)
#对于embarked列,先弃含NaN的项,再0映射到S,1映射到C,2映射到Q
df.head()

- 合并列(行)
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
# 用lambda表达式创建新特征
def get_together(sibsp, parch):
get_together = sibsp + parch
return get_together
#这个函数想要干的实际上是将两列(行)进行相加并合并成一列(行)数据
df["The Result"] = df[["sibsp", "parch"]].apply(lambda x: get_together(x["sibsp"], x["parch"]), axis=1)
#仔细推敲
df.head()

- 重新组织表头
# 重新组织表头
import pandas as pd
import numpy as np
dict0 = {'name':["红红","兰兰"],"age":[18,18]}
df = pd.DataFrame(dict0)
df = df[['age','name']] #很好理解
df
age name
0 18 红红
1 18 兰兰
- DataFrame 数据的保存和读取
- DataFrame 数据的保存和读取
- df.to_csv 写入到 csv 文件
- pd.read_csv 读取 csv 文件
- df.to_json 写入到 json 文件
- pd.read_json 读取 json 文件
- df.to_html 写入到 html 文件
- pd.read_html 读取 html 文件
- df.to_excel 写入到 excel 文件
- pd.read_excel 读取 excel 文件
import pandas as pd
# 从CSV文件读取到DataFrame
df = pd.read_csv("titanic.csv", header=0)
# 把Dataframe存进CSV文件
df.to_csv("processed_titanic.csv", index=False)# 不储存索引列
Part 2: Chipotle 快餐数据
- pd.read_csv 详解
import pandas as pd
import numpy as np
url = 'https://raw.githubusercontent.com/justmarkham/DAT8/master/data/chipotle.tsv'
chipo = pd.read_csv(url,sep = '\t') #横向跳到下一制表符位置
chipo.head()

- pandas.read_csv()
sep=',' # 以,为数据分隔符
shkiprows= 10 # 跳过前十行
nrows = 10 # 只去前10行
parse_dates = ['col_name'] # 指定某行读取为日期格式
index_col = ['col_1','col_2'] # 读取指定的几列
error_bad_lines = False # 当某行数据有问题时,不报错,直接跳过,处理脏数据时使用
na_values = 'NULL' # 将NULL识别为空值
- 数据集中有多少个列(行)
url = 'https://raw.githubusercontent.com/justmarkham/DAT8/master/data/chipotle.tsv'
chipo = pd.read_csv(url,sep = '\t')
chipo.shape[0]
#4622
chipo.shape[1]
#5
- 打印出全部的列(行)名称
url = 'https://raw.githubusercontent.com/justmarkham/DAT8/master/data/chipotle.tsv'
chipo = pd.read_csv(url,sep = '\t')
chipo.columns #返回列名
Index(['order_id', 'quantity', 'item_name', 'choice_description',
'item_price'],
dtype='object')
url = 'https://raw.githubusercontent.com/justmarkham/DAT8/master/data/chipotle.tsv'
chipo = pd.read_csv(url,sep = '\t')
chipo.index #返回行名
RangeIndex(start=0, stop=4622, step=1)















 2819
2819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









