










Path-Sensitive Code Embedding via Contrastive Learning for Software Vulnerability Detection
一.引言
1.1.现有方法及其局限
Code Embedding,一个意在通过分布式向量表示代码语义的技术,在漏洞检测领域已经取得了一些进展,现有的方法大致可分为2类:
-
Sequence-based:VulDeePecker,SySeVR等,这些方法将代码片段视为一段序列,通过RNN对序列进行分类。
-
Graph-Based:IVDetect,Reveal,Devign等,这些方法首先将代码解析为图结构,之后通过GNN对序列进行分类。
这些方法进行漏洞检测的思路通常是进行二分类,类似的技术在code classification和code summarization任务上取得了成功,但是在漏洞检测领域却并不是很成功。主要原因是:
-
这些方法的代码表示并没有区分Program Path(路径),GNN也不会区分Path。
-
图的特征是通过GNN的Message Passing机制从图中相邻的结点对学到的。但是,这并不会区分可行/不可行的value-flow (data-dependence) paths。
因此,模型并没有理解潜在的漏洞path,这也大大限制了模型定位漏洞的能力。作者也提出了下面的Insights:
-
模型需要学习的是可行的value-flow (data-dependence) paths而不是整个图结构。
-
Code2Vec将代码表示为AST Path Bags,这就是一个AST Path集合,不过AST Path数量庞大,作者将程序表示为可行的value-flow path集合,最后这些value-flow paths会被聚合为整个程序向量。
-
尽管如此,程序中value-flow path的数量依旧是不确定的,所以需要Path selection来选取最重要的path。
1.2.作者的解决方案
基于上面的Insights作者提出了ContraFlow,一个漏洞检测框架,概览如下:
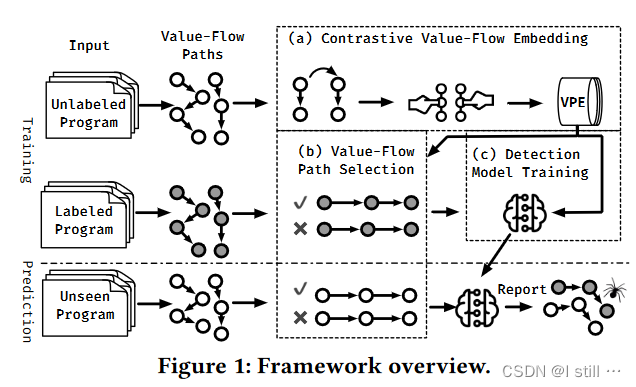
这个流程可分为下面几个阶段
-
( a ) Contrastive Value-Flow Embedding:这个阶段主要目的是通过对比学习方式训练一个value-flow embedding model, Value-flow Path Encoder(VPE),训练过程如下,这一步会预训练出一个VPE并应用在后面2个阶段。
-
首先用SVF从未标注的数据集中提取一个Value Flow Path集合
-
然后使用数据增强手段来生成contrastive value-flow representations
-
然后利用标准Noise Contrastive Estimate (NCE)loss函数最大化语义相似value-flow path之间的向量相似度。
-
-
( b ) Value-Flow Path Selection:这个阶段的主要目的是从程序提取的Value-Flow Path中选取可行并且具备代表性的path。
-
首先采用预训练的VPE生成输入path集合的向量,然后采用 self-supervised active learning 来捕获最具代表性的path集合并使得embedding更加多样化。
-
之后就是可行性分析,value-flow path通常伴有条件分支,这一步主要排除路径条件不能全部满足的path。
-
-
( c ) Detection Model Training:这一步主要是从(b)中选取的path集合和(a)中预训练的VPE中训练一个分类器进行漏洞分类
-
首先利用VPE获取path的初始向量
-
然后通过Muti-head层获取每个path的contextual vector,之后通过一个soft attention layer聚合所有path的向量,同时计算每个path的权重
-
训练好的分类器可以根据attention score给path分配权重并计算buggy path
-
可以看到训练的模型包括VPE, self-supervised active learning和分类器,其中VPE和分类器应用到了最终的漏洞检测器中。
二.Motivating Example
这个Example来自POCO project,属于CWE-840,漏洞触发的根源是API误用,在 rebuild_list(&hd) 后调用了 set_status(&hd)。其中 hd 变量在第2行定义,第6行被修改,第13行被使用,2-6-13是一个漏洞触发路径。
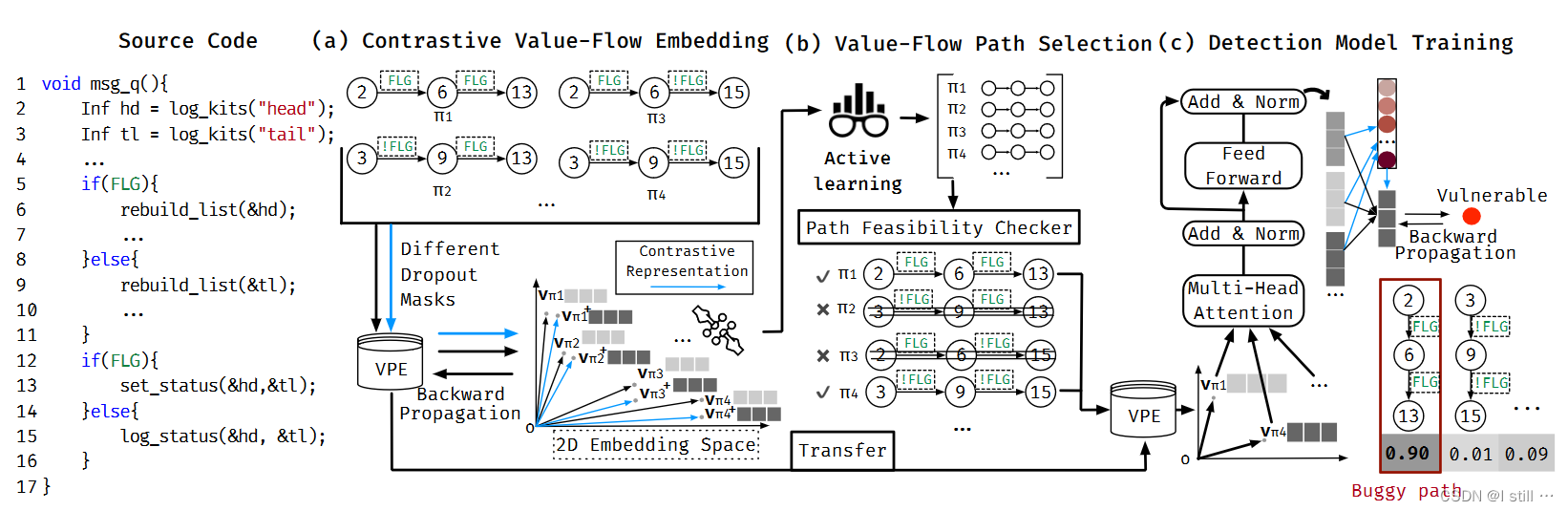
-
首先在阶段 (a) 提取了4个value-flow path( π 1 : 2 − 6 − 13 \pi_1 : 2-6-13 π1:2−6−13 , π 2 : 2 − 6 − 15 \pi_2 : 2-6-15 π2:2−6−15, π 3 : 3 − 9 − 13 \pi_3 : 3-9-13 π3:3−9−13, π 4 : 3 − 9 − 15 \pi_4 : 3-9-15 π4:3−9−15),作者将这4条路径2次输入到VPE中,每次使用不同的dropout,可以分别获取向量 v π 1 , v π 2 , v π 3 , v π 4 v_{\pi_1}, v_{\pi_2}, v_{\pi_3}, v_{\pi_4} vπ1,vπ2,vπ3,vπ4 和 v π 1 + , v π 2 + , v π 3 + , v π 4 + v_{\pi_1}^+, v_{\pi_2}^+, v_{\pi_3}^+, v_{\pi_4}^+ vπ1+,vπ2+,vπ3+,vπ4+。其中,VPE的训练目标是相似的embedding vector距离相近 ( v π 1 , v π 1 + v_{\pi_1}, v_{\pi_1}^+ vπ1,vπ1+),而不同的vector距离较远 ( v π 1 , v π 3 + v_{\pi_1}, v_{\pi_3}^+ vπ1,vπ3+),这一步采用的loss是NCE loss。
-
阶段(b) 首先根据self-supervised active learning获取 π 1 − π 4 \pi_1 - \pi_4 π1−π4 的排序,之后这些path会进行可行性分析。其中 π 2 \pi_2 π2 和 π 3 \pi_3 π3 不可行, 2 − 6 − 15 2-6-15 2−6−15 中 6 6 6 需要满足条件
FLG而 15 15 15 要满足条件!FLG, π 3 \pi_3 π3 反之亦然。 -
阶段 ( c ) 中对于输入path π 1 , π 4 \pi_1, \pi_4 π1,π4。首先用VPE 计算其向量 v π 1 , v π 4 v_{\pi_1}, v_{\pi_4} vπ1,vπ4,然后 v π 1 , v π 4 v_{\pi_1}, v_{\pi_4} vπ1,vπ4 会输入Muti-head层计算每个path的contextual vector,然后所有path的contextual vector会输入soft attention层,聚合成整个程序的向量,同时每个path都会对应1个attention权重,表明这个path的贡献程度。图中 π 1 \pi_1 π1 的贡献达到 90%,最有可能是漏洞path。
三.ContraFlow
3.1.Contrastive Value-Flow Embedding
3.1.1.path vectorizing
提取到了value-flow path,首先要将path向量化,一个path π \pi π 由多个statement s s s 组成,可以视作一个statement sequence。VPE向量化pipeline如下所示(这里介绍VPE模型结构):
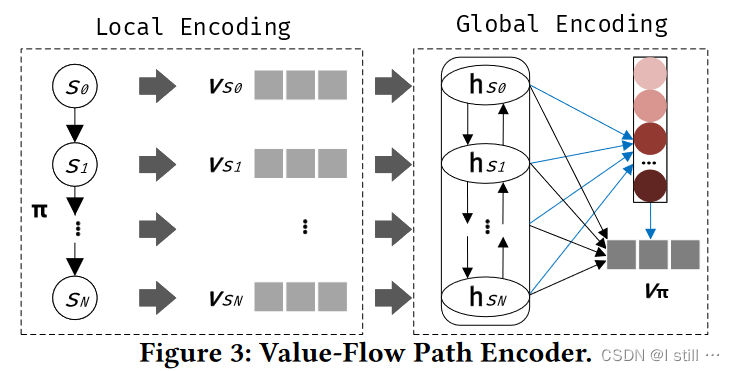
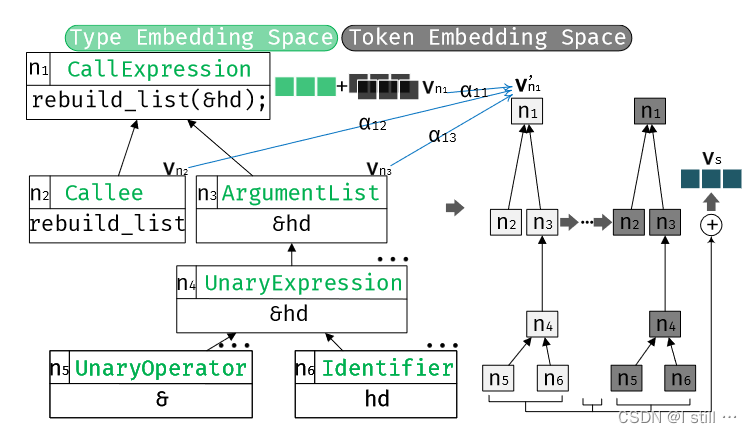
Local Encoding主要目的是独立地向量化每个statement,向量化statement
s
s
s 用到了
s
s
s 的AST subtree,下图给出了一个示例。首先对于
s
s
s 的AST子树中的一个结点
n
i
n_i
ni,它的初始结点向量
v
n
i
v_{n_i}
vni 通过 node type 和 node token(类似Devign和Reveal)生成,之后通过下面公式更新
v n i ′ = ∑ j ∈ C i ∪ { i } α i j . W . v n j v_{n_i}^{'} = \sum_{j \in C_i \cup \{i\}} \alpha_{ij} .W.v_{n_j} vni′=j∈Ci∪{i}∑αij.W.vnj
-
C i C_i Ci 是 n i n_i ni 的子结点
-
W W W 是VPE的参数
-
α i j \alpha_{ij} αij 是 n i n_i ni 和 n j n_j nj 之间的attention值
之后按如下方式生成
s
s
s 的summary vector
v
s
m
v_{sm}
vsm:
v s m = [ 1 N ∑ i = 1 N v n i ′ ∣ ∣ max j = 1 N v n j ′ ] v_{sm} = [\frac{1}{N} \sum_{i=1}^N v_{n_i}^{'} || \max_{j=1}^N v_{n_j}^{'} ] vsm=[N1i=1∑Nvni′∣∣j=1maxNvnj′]
其中用到的模型可能有多层 ( L L L 层),statement vector v j k = ∑ l = 1 L v s m l v_{jk} = \sum_{l=1}^L v_{sm}^l vjk=∑l=1Lvsml,而最终statement向量 v s = d r o p o u t ( W . v j k ) v_s = dropout(W.v_{jk}) vs=dropout(W.vjk)
Global Encoding根据每个statement的向量生成path向量,前一步计算出了每个statement的向量 v s 0 , v s 1 , . . . , v s N v_{s_0}, v_{s_1}, ..., v_{s_N} vs0,vs1,...,vsN,这一步通过BGRU将 v s 0 , v s 1 , . . . , v s N v_{s_0}, v_{s_1}, ..., v_{s_N} vs0,vs1,...,vsN 转化为 h s 0 , h s 1 , . . . , h s N h_{s_0}, h_{s_1}, ..., h_{s_N} hs0,hs1,...,hsN,这一组向量描述了一组def-use(data-dependence)关系。之后通过attention机制将所有hidden向量聚合为path向量 π \pi π。
3.1.2.Contrastive Value-Flow Embedding Algorithm
这一步主要目的是训练VPE,算法如下图所示
 首先对比学习用到的数据对中,path
π
\pi
π 会输入VPE 2次根据不同的dropout获得向量
v
π
v_\pi
vπ 和
v
π
+
v_\pi^{+}
vπ+,这作为positive,而
v
π
v_\pi
vπ 和其它path的向量会组成negative。这种数据增强操作比element deletion或者substitution要好。
首先对比学习用到的数据对中,path
π
\pi
π 会输入VPE 2次根据不同的dropout获得向量
v
π
v_\pi
vπ 和
v
π
+
v_\pi^{+}
vπ+,这作为positive,而
v
π
v_\pi
vπ 和其它path的向量会组成negative。这种数据增强操作比element deletion或者substitution要好。
之后,作者用Noise Contrastive Estimate (NCE) loss函数训练VPE,path向量的相似度用余弦相似度衡量。
s i m ( v π i , v π j ) = v π i T . v π j ∣ ∣ v π i ∣ ∣ . ∣ ∣ v π j ∣ ∣ sim(v_{\pi_i}, v_{\pi_j}) = \frac{v_{\pi_i}^T. v_{\pi_j}}{||v_{\pi_i}||. ||v_{\pi_j}||} sim(vπi,vπj)=∣∣vπi∣∣.∣∣vπj∣∣vπiT.vπj
path π i \pi_i πi 的 loss定义如下:
l o s s ( v π i ) = − log exp ( s i m ( v π i , v π i + ) ) ∑ k = 1 B exp ( s i m ( v π i , v π k + ) loss(v_{\pi_i}) = -\log \frac{\exp(sim(v_{\pi_i}, v_{\pi_i}^{+}))}{\sum_{k=1}^B \exp(sim(v_{\pi_i}, v_{\pi_k}^{+})} loss(vπi)=−log∑k=1Bexp(sim(vπi,vπk+)exp(sim(vπi,vπi+))
B B B 为1个Batch的数量,一个Batch的Loss为
L = 1 B ∑ i = 1 B l o s s ( π i ) L = \frac{1}{B} \sum_{i=1}^B loss(\pi_i) L=B1i=1∑Bloss(πi)
3.2.Value-Flow Path Selection
3.2.1.Value-Flow Active Learning
这一步主要目的是选取出具有代表性的path,参考的是文献 [ 2 ] ^{[2]} [2],给定通过VPE向量化好的path集合 H = [ v π 1 , . . . , v π n ] ∈ R n × d H = [v_{\pi_1}, ..., v_{\pi_n}] \in R^{n \times d} H=[vπ1,...,vπn]∈Rn×d,选取出 H ′ ∈ R k × d ⊆ H H^{'} \in R^{k \times d} \subseteq H H′∈Rk×d⊆H,这里引入了1个encoder-decoder模型。需要优化的参数为2个矩阵 Q , P ∈ R n × n Q, P \in R^{n \times n} Q,P∈Rn×n,优化目标包括最小化下面目标的距离:
-
H H H 和 Q . H Q.H Q.H
-
cluster centroid matrix C C C,通过K-means聚合得到
-
H H H 和decoder输出 G G G
训练完毕后,作者为 Q , P Q, P Q,P 的每一列计算 l2-norm 值,生成2个ranking vector q ^ , p ^ ∈ R n \hat q, \hat p \in R^n q^,p^∈Rn,之后,这两个ranking vector会聚合并降序排序,然后就可以选取top-k value flow path了。
3.2.2.Value-Flow Path Feasibility Analysis
这一步只要进行path-sensitive分析,分析目标是排除控制流约束条件不能得到满足的路径,形式化描述就不写了,可以用下图展示:
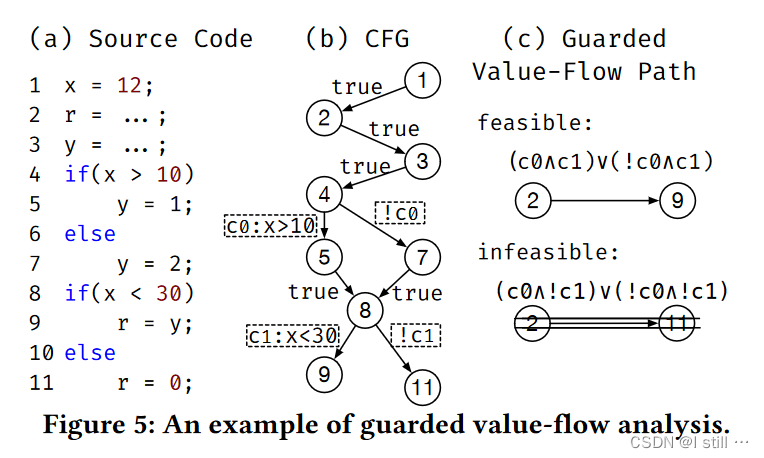 简而言之
简而言之
-
如果没有约束条件,那么就是
True -
如果有约束条件,那么看整条路径上的所有约束能不能同时满足,不能为
False, 能为True
3.3.Detection Model Training
这里就是训练分类器了,分类器的输入是Path集合的向量 V = [ v π 1 , . . . , v π N ] ∈ R N × d e m b V = [v_{\pi_1}, ..., v_{\pi_N}] \in R^{N \times d_{emb}} V=[vπ1,...,vπN]∈RN×demb, N N N 是path数量。而分类器主要包含1个Muti-head attention层+1个soft attention层+1个线性分类层
muti-head的计算过程如下:
h i = A t t n ( V . W i Q , V . W i K ) . V . W i V h_i = Attn(V.W_i^Q, V.W_i^K).V.W_i^V hi=Attn(V.WiQ,V.WiK).V.WiV
V ′ = [ h 1 ∣ ∣ . . . ∣ ∣ h h ] . W o V^{'} = [h1 || ... || h_h].W^o V′=[h1∣∣...∣∣hh].Wo
V ′ ∈ R N × d c t x V^{'} \in R^{N \times d_{ctx}} V′∈RN×dctx 是muti-head层输出, W i Q , W i K , W i V , W o W_i^Q, W_i^K, W_i^V, W^o WiQ,WiK,WiV,Wo是muti-head层参数, soft attention层计算如下:
α i c = exp ( v π i T ) . a c ∑ j = 1 N exp ( v π j T ) . a c \alpha_i^c = \frac{\exp(v_{\pi_i}^T).a_c}{\sum_{j=1}^{N} \exp(v_{\pi_j}^T).a_c} αic=∑j=1Nexp(vπjT).acexp(vπiT).ac
v c = ∑ i = 1 N α i c . v π i v_c = \sum_{i=1}^{N} \alpha_i^c. v_{\pi_i} vc=i=1∑Nαic.vπi
v
c
v_c
vc 是soft attention层输出的整个程序的向量,
a
c
a_c
ac
是soft attention层的参数,之后
v
c
v_c
vc 会输入一个全连接层+softmax进行分类。
给定训练好的模型,整个系统大概可以总结如下:
-
VPE部分可能包括一个embedding模型用来根据node token生成node初始向量, 一个attention层用来向量化AST子树生成statement向量,一个BGRU+attention用来生成path向量。
-
Value-Flow Selection部分包括一个Encoder-Decoder来选取代表性path,以及一个约束求解模块进行可达性分析。
-
分类器包括1个Muti-Head生成contextual vector, 1个soft attention层聚合多个path + 1个全连接层分类。
四.实验设计
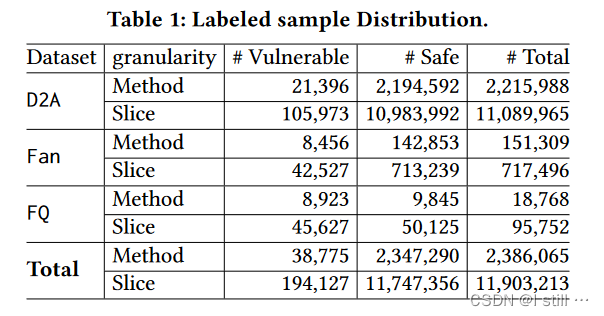
数据集用到了D2A, Fan和FFMpeg+QEMU。数据集基本信息如下:
首先源代码被编译为LLVM IR,然后输入到SVF中解析value-flow graph(可能会从LLVM层面的VFG映射到源代码层面的VFG),提取AST子树用到了Joern,约束求解用到了Z3 SMT求解器。对比实验包括SySeVR,VulDeePecker,Reveal,DeepWukong, Devign, IVDetect, VulDeeLocator, VGDetector。
实验可分为下面3部分:
-
RQ1: Can ContraFlow outperform existing learning-based vulnerability detection approaches? 分为二分类对比和漏洞定位对比
-
RQ2:How do different settings affect ContraFlow’s overall performance? 分为几个消融实验:有没有对比学习,不同的path selection策略,预训练模型的不同
-
RQ3:How do different dataset scales for training affect the performance of ContraFlow?在不同训练数据集大小下模型性能的不同
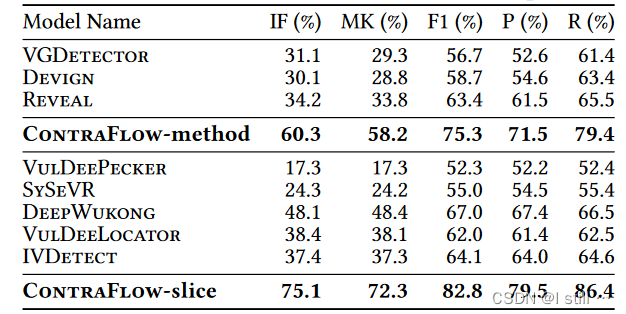
评估指标,针对二分类用到了:IF,MK, F1 3个指标,IF = Recall + TNR - 1,MK = Precision + TNA - 1
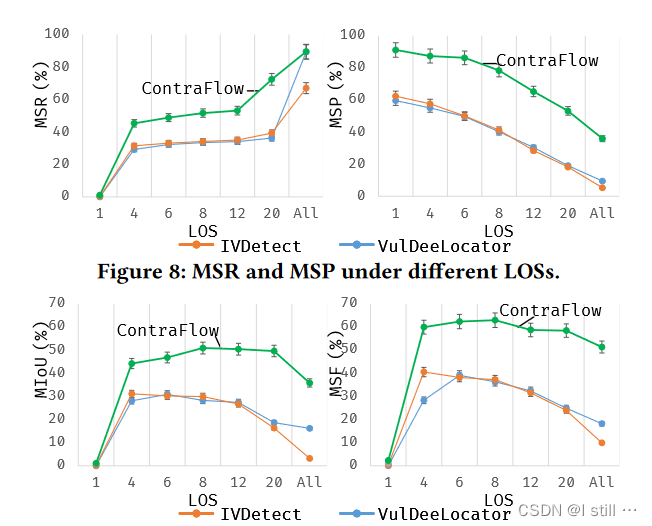
对漏洞定位用到了MSR, MSP, MIOU 3个指标:
-
s d s_d sd 为检测出的漏洞行, s l s_l sl 为标注漏洞行
-
MSR = ∣ s d ∩ s l ∣ ∣ s l ∣ \frac{|s_d \cap s_l|}{|s_l|} ∣sl∣∣sd∩sl∣
-
MSP = ∣ s d ∩ s l ∣ ∣ s d ∣ \frac{|s_d \cap s_l|}{|s_d|} ∣sd∣∣sd∩sl∣
-
MIOU = ∣ s d ∩ s l ∣ ∣ s d ∪ s l ∣ \frac{|s_d \cap s_l|}{|s_d \cup s_l|} ∣sd∪sl∣∣sd∩sl∣
实验结果就列出部分
4.1.RQ1
二分类对比如下:
而漏洞定位结果如下(只对比了VulDeeLocator和IVDetect),横轴代表漏洞行数量:
4.2.RQ2
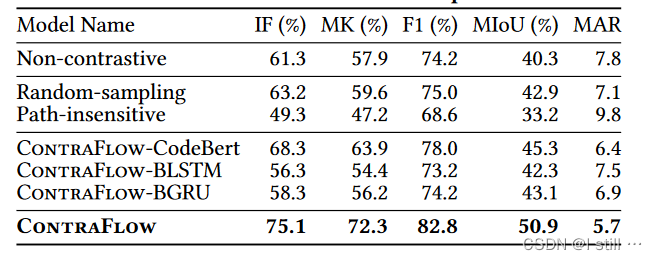 首先,没有对比学习会导致ContraFlow性能下降明显,对于path selection中随机sample path或者在后面不进行path sensitive分析都会让ContraFlow性能明显下降,下面3个ContraFlow-CodeBert xxx 是指用CodeBert直接向量化node statement,不考虑AST子树特征,可以看到不考虑AST子树会让ContraFlow的性能出现下降
首先,没有对比学习会导致ContraFlow性能下降明显,对于path selection中随机sample path或者在后面不进行path sensitive分析都会让ContraFlow性能明显下降,下面3个ContraFlow-CodeBert xxx 是指用CodeBert直接向量化node statement,不考虑AST子树特征,可以看到不考虑AST子树会让ContraFlow的性能出现下降
4.3.RQ3
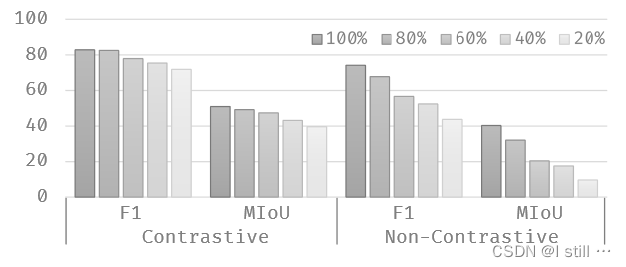
训练数据量减少时模型性能出现了明显的下降
五.总结
这篇Paper中作者提出了ContraFlow,一个新的path-sensitive的漏洞检测器,框架中作者多次用到attention机制,同时作者将更多程序分析知识应用到漏洞检测中,用可行的value flow path集合作为程序表示显著提升了检测器的效果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









