










Learch: a Learning-based Strategies for Path Exploration in Symbolic Execution
一.Introduction
这篇paper目的是想解决符号执行存在的一个关键问题:路径爆炸(path explosion)
解决方案,选择能够达到高覆盖率的promising states,避免不会提高覆盖率的state,现有的人工策略基于下面属性
-
-
instruction count
-
深度优先搜索:klee中用到的策略,优先选出最新的state,当碰到tight loop的时候容易卡死(循环体内代码很少,但是循环次数很多)
-
Random State Search(RSS):klee中用到的策略,从pending states中随机选取一个state探索,可以避免tight loop,但是总会产生相同的testcase
-
Random Path Selection (RPS):klee中用到的策略,使用二叉树存储已经探索过的代码的信息,每一个叶子结点代表一个当前state,非叶子结点是forks,选取state时,工具从root往叶子结点遍历,方向随机选取。可以避免RSS中的fork bombing问题,但是也会产生相同的testcase
-
Coverage-Optimized Search (COS):klee中用到的策略,通过计算未覆盖代码与当前state的距离等信息来计算权重
-
-
Subpath-Guided Search:目的在于优先探索程序中的less traveled part,利用Program profiling,已经集成到klee中,一个path可以记为一个branch序列 π = < s 0 , s 1 , . . . , s k > \pi = <s_0, s_1, ..., s_k> π=<s0,s1,...,sk>,一个length-n subpath可以记为 < s i + 1 , . . . , s i + n > <s_{i+1}, ..., s_{i + n}> <si+1,...,si+n>,工具使用优先队列 P P P,存储的信息为 < π , f > <\pi, f> <π,f>, π \pi π 表示一个length-n subpath, f f f 表示该subpath, P P P 顶部是频率最低的subpath。每一个state都会对应一个subpath π \pi π 保存最新n个branch condition(测试的时候 n = 1 , 2 , 4 , 8 n = 1, 2, 4, 8 n=1,2,4,8)
-
constraint search depth:约束搜索深度
-
hand-crafted fitness:即Fitness-Guided Search Strategy,给定1个target predicate和1个path,根据fiteness函数为path计算fitness value,越小的优先级越高
上述策略可能会陷入局部对某种属性有利的部分而忽视代码中其它可能相关的(提高覆盖率,或者安全问题)部分。
public bool TestLoop(int x, int[] y) {
1 if (x == 90) {
2 for (int i = 0; i < y.Length; i++)
3 if (y[i] == 15)
4 x++;
5 if (x == 110)
6 return true;
}
7 return false;
}
针对上述示例基于DFS和BFS的搜索策略就不管用了(常规时间内不可能了)
因此作者提出了Learch,通过ML的方法学习一个state选择策略,对state赋予reward并选择高reward的state进行搜索,相比于人工策略更有效。
Learch的2个阶段:
-
训练阶段,训练一个回归模型,在每个iteration:
-
在训练样本(程序)上运行符号执行,并使用不同的人工策略来生成多种多样的tests
-
对tests中的每一个state,提取高层特征(比如人工策略中的几种特征),并基于覆盖率的提升和搜索该state消耗的时间计算reward
-
通过前面的步骤可以得到一个标注数据集,用这个数据集来训练一个回归模型
-
-
测试阶段
Learch被应用在klee上,并在52个coreutils程序和10个real-world程序上进行了测试,覆盖率提升超过20%,多发现超过10%的安全问题。用被Learch升级过的klee生成seed进行Fuzz,AFL可以触发更多bug path。
二.Motivation
-
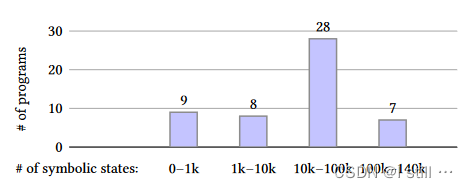
Large number of candidate states:下图中作者对coreutils测试集中的52个程序用Klee进行运行测试,这些程序运行时产生的状态数量如下图所示,28个程序产生的状态数在10k-100k之间,数量非常庞大。
-
Limitations of existing manually designed heuristics.
三.符号执行框架
符号执行的目标: 找到一组测试用例tests能最大化代码覆盖率
a r g m a x t e s t s = s y m E x e c ( p r o g , s t r a t e g y ) ∣ ∪ t ∈ t e s t s c o v e r a g e ( t ) ∣ s y m E x e c T i m e argmax_{tests=symExec(prog, strategy)} \frac{|\cup_{t \in tests} coverage(t)|}{symExecTime} argmaxtests=symExec(prog,strategy)symExecTime∣∪t∈testscoverage(t)∣
策略:策略是将state映射为数值(衡量重要程度)的函数,selectState 一般会选择权重最高的state优先探索,以klee中的DFS策略举例
-
权值为state对应的深度
-
selectState会选择深度最大的state进行探索 -
update会更新state的深度
一个完美的策略能实现以下目标:
r e w a r d ( s t a t e ) = ∣ ∪ t ∈ t e s t F r o m ( s t a t e ) c o v e r a g e ( t ) ∣ ∑ d ∈ s t a t e s F r o m ( s t a t e ) s t a t e T i m e ( d ) reward(state) = \frac{|\cup_{t \in testFrom(state)} coverage(t)|}{\sum_{d \in statesFrom(state) stateTime(d)}} reward(state)=∑d∈statesFrom(state)stateTime(d)∣∪t∈testFrom(state)coverage(t)∣
但是计算
t
e
s
t
F
r
o
m
(
s
t
a
t
e
)
testFrom(state)
testFrom(state) 和
s
t
a
t
e
s
F
r
o
m
(
s
t
a
t
e
)
statesFrom(state)
statesFrom(state) 是做不到的,所以现有的方法大部分直接根据某些属性制订人工策略。因此作者提出了 Learch,通过一个ML回归模型来从某个state中提取feature(extractFeature),将feature输入到模型中计算reward,而在训练时会统计
t
e
s
t
F
r
o
m
(
s
t
a
t
e
)
testFrom(state)
testFrom(state),
s
t
a
t
e
s
F
r
o
m
(
s
t
a
t
e
)
statesFrom(state)
statesFrom(state) 相关信息,基于这2个数据产生reward label,训练时让model尝试根据提取的feature预测出的reward,再将训练好的model应用到其它场景下。
四.LEARCH
4.1.Assigning a Reward to Explored States
-
定义2(test),
symExec生成的一个Test是一个三元组(states, input, cov)-
s t a t e s = [ s t a t e 0 , s t a t e 1 , . . . , s t a t e n ] states = [state_0, state_1, ..., state_n] states=[state0,state1,...,staten] 是一个 state list,每一个state对应一个分支、 s t a t e i state_i statei 对应的分支在CFG中后面跟着的是 s t a t e i + 1 state_{i + 1} statei+1 对应的分支,因此
states对应着 test触发的program path。 -
input是约束求解器求解 s t a t e n state_n staten 对应的约束构造出的一个具体输入,执行的路径是states对应的program path。 -
cov是覆盖的代码行。
-
针对从一个程序中提取的test集合,作者构造了一个tests tree。
-
定义3(Tests Tree),给定从一个程序中提取的一系列test集合tests [ t e s t 0 , t e s t 1 , . . . , t e s t m ] [test^0, test^1, ..., test^m] [test0,test1,...,testm], 其Tests Tree为:
-
每一个node对应tests中的一个state(不同的test可能有相同的state)
-
对于 t e s t i test^i testi 中的 states s t a t e j i state^i_j stateji 和 s t a t e j + 1 i state^i_{j + 1} statej+1i,前者为后者的父节点
-
t o t a l C o v ( s t a t e ) = { n e w C o v ( s t a t e ) i f s t a t e i s l e a f ∑ c ∈ c h i l d r e n ( s t a t e ) t o t a l C o v ( c ) o t h e r w i s e totalCov(state) = \left\{ \begin{aligned} newCov(state) && {if \; state \; is \; leaf\;}\\ \sum_{c \in children(state)} totalCov(c) && {otherwise}\\ \end{aligned} \right. totalCov(state)=⎩ ⎨ ⎧newCov(state)c∈children(state)∑totalCov(c)ifstateisleafotherwise
t o t a l T i m e ( s t a t e ) = s t a t e T i m e ( s t a t e ) + ∑ c ∈ c h i l d r e n ( s t a t e ) t o t a l T i m e ( c ) totalTime(state) = stateTime(state) + \sum_{c \in children(state)}totalTime(c) totalTime(state)=stateTime(state)+c∈children(state)∑totalTime(c)
r e w a r d ( s t a t e ) = t o t a l C o v ( s t a t e ) t o t a l T i m e ( s t a t e ) reward(state) = \frac{totalCov(state)}{totalTime(state)} reward(state)=totalTime(state)totalCov(state)
4.2.Strategy Learning Algorithm
-
生成带标签数据集,输入的是程序集合 p r o g s progs progs 以及策略集合 s t r a t e g i e s strategies strategies:
![[algo3CCS21.png]]
-
Iterative learning for producing multiple learned strategies
![[algo4CCS21.png]]
五.Instantiating Learch On Klee
5.1.Features and Model
选取的特征包括:
| 特征 | 描述 |
|---|---|
| stack | state对应的call stack的大小,越大,代表执行的深度越大 |
| successor | CFG上该state对应的basic block的后继结点数量 |
| testCase | 到目前为止生成的test数量 |
| coverage | 包括state对应的branch覆盖的新指令和新源代码行数量、state对应的path覆盖的新指令和新源代码行数量 |
| constraint | 这是1个32维向量,是该state对应的path constraint的bag-of-word向量表示 |
| depth | state对应的path中fork的数量 |
| cpicnt | 对应在state的当前函数内执行的指令数 |
| icnt | 当前state对应的指令执行的次数 |
| covNew | 当前state的最后一条新覆盖指令,并计算其与当前指令的距离 |
| subpath | 当前state对应的subpaths之前已被探索的次数 |
模型为前馈神经网络,代码如下:
class PolicyFeedforward(nn.Module):
def __init__(self, input_dim, hidden_dim):
super().__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.scaler = StandardScaler()
self.net = nn.Sequential(
nn.Linear(self.input_dim, self.hidden_dim),
nn.ReLU(),
nn.Linear(self.hidden_dim, self.hidden_dim),
nn.ReLU(),
nn.Linear(self.hidden_dim, 1)
)
def forward(self, x):
return self.net(x)
def do_train(self, x, y, args):
batch_size = args.batch_size
num_batch = len(x) // batch_size + (1 if len(x) % batch_size else 0)
self.scaler.fit(x)
optimizer = torch.optim.Adam(self.parameters(), lr=args.lr, weight_decay=args.weight_decay)
loss_func = nn.MSELoss()
for i in range(args.epoch):
self.train()
epoch_loss = 0
for j in tqdm(list(range(num_batch))):
x_batch, y_batch = x[j*batch_size:(j+1)*batch_size], y[j*batch_size:(j+1)*batch_size]
x_batch = self.scaler.transform(x_batch)
x_batch, y_batch = torch.FloatTensor(x_batch).to(device), torch.FloatTensor(y_batch).to(device).unsqueeze(1)
y_out = self(x_batch)
loss = loss_func(y_out, y_batch)
epoch_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'epoch {i}, loss {epoch_loss/num_batch}')
if args.model_dir:
os.makedirs(args.model_dir, exist_ok=True)
self.save(os.path.join(args.model_dir, f'model_{i}.pt'))
self.save(os.path.join(args.model_dir, f'model.pt'))
def score(self, x, y, args):
batch_size = args.batch_size
num_batch = len(x) // batch_size + (1 if len(x) % batch_size else 0)
y_tmp = torch.FloatTensor(y)
u, v = 0, ((y_tmp - y_tmp.mean()) ** 2).sum().item()
self.eval()
with torch.no_grad():
for i in range(num_batch):
x_batch, y_batch = x[i*batch_size:(i+1)*batch_size], y[i*batch_size:(i+1)*batch_size]
x_batch = self.scaler.transform(x_batch)
x_batch, y_batch = torch.FloatTensor(x_batch).to(device), torch.FloatTensor(y_batch).to(device).unsqueeze(1)
y_out = self(x_batch)
u += (y_batch - y_out).pow(2).sum().item()
return (1 - u/v)
@staticmethod
def load(path):
if use_cuda == 'cuda':
model_file = torch.load(path)
else:
model_file = torch.load(path, map_location='cpu')
model = PolicyFeedforward(model_file['input_dim'], model_file['hidden_dim'])
model.load_state_dict(model_file['state_dict'])
model.scaler = model_file['scaler']
return model
def save(self, path):
torch.save({
'input_dim': self.input_dim,
'hidden_dim': self.hidden_dim,
'state_dict': self.state_dict(),
'scaler': self.scaler,
}, path)
5.2.Security Violations
作者利用Clang’s Undefined Behavior Sanitizer (UBSan)检测输入程序并标记五种安全违规行为
-
Integer overflow:
+, -, *, /, %运算以及有符号和无符号整数的求反 -
Oversized shift:检查移位量是否等于或大于移位变量的位宽度,或小于零
-
Out-of-bounds array reads/writes:检查数组读取和写入的索引是否等于或大于数组大小
-
Pointer overflow:检查指针算术是否溢出
-
Null dereference:检测空指针的使用或空解引用的创建
当发生任何UBSan违规时,将调用特定函数。作者添加了用于捕获这些函数并生成触发冲突的具体测试用例(整数溢出除外,Klee已经支持整数溢出了)。作者注意到,Klee不限于UBSan的违规行为,但支持更多违规行为的难度取决于处理程序的实现。
六.Experimental Evaluation
RQ包括:
-
Can Learch cover more code than existing manual heuristics?
-
Can Learch discover more security violations?
-
Can Learch generate better initial seeds for fuzzing?
-
What is the impact of Learch’s design choices?
Benchmarks:
用到的程序
| 类别 | 名称 | 用途 |
|---|---|---|
| 真实 | diffutils 3.7 | 测试 |
| 真实 | findutils 4.7.0 | 测试 |
| 真实 | grep 3.6 | 测试 |
| 真实 | gawk 5.1.0 | 测试 |
| 真实 | patch 2.7.6 | 测试 |
| 真实 | binutils 2.36 ((objcopy and readelf)) | 测试 |
| 真实 | make 4.3 | 测试 |
| 真实 | cjson 1.7.14 | 测试 |
| 真实 | sqlite | 测试 |
| coreutils | coreutils 8.31 | 测试 + 训练 |
baseline策略包括:
-
rss (random state search)
-
rps (random path search):
-
nurs:cpicnt, nurs:depth
-
sgs (subpath-guided search)
-
portfolio:4种策略的组合,rps, nurs:cpicnt, nurs:depth, and sgs.
关于实验的具体信息我就不写了,大家有兴趣可以看看论文。
七.代码实操
-
直接根据learch提供的Dockerfile创建docker容器,不过需要注意的是里面用到了
git clone和pip3 install,我因为网络原因卡在这了,于是我做了如下改动:-
替换
RUN git clone https://github.com/stp/stp.git为RUN git clone https://gitclone.com/github.com/stp/stp.git(后面还有一个git clone xxx) 也要替换 -
在
pip3 install xxx后面添加-i https://pypi.tuna.tsinghua.edu.cn/simple
-
说一下docker中的目录结构,大致如下:
root
-- klee-uclibc
-- stp
-- learch
-- Dockerfile
-- README.md
-- klee
-- learch
到了 /root/learch 目录下就跟作者提供的源代码目录结构相同了。
在这里面 klee 是作者修改过的klee,主要是添加了ML-based searcher,需要与训练过的model交互,训练model的代码都是用python写的,在 learch 目录下,不过我C++功底不太好,就只看了 learch 目录下的
-
生成数据集
-
cd到benchmarks目录下运行/prepare_coreutils.sh coreutils_all.txt,然后在benchmarks目录下会多出一个coreutils-8.31文件夹和coreutils-8.31.tar.xz文件(下载的coreutils-8.31) -
然后
cd到train目录下,运行./train_data.sh b2sum ~/train_data 60 0 "random-path",运行完之后/root目录下多了个train_data文件夹,一路cd,在/train_data/random-path-0/b2sum保存着刚刚生成的数据
-
train_data 目录如下:
`-- train_data
`-- random-path-0
`-- b2sum
|-- all_features.npy
|-- all_lengths.npy
|-- assembly.ll
|-- final.bc
|-- info
|-- messages.txt
|-- run.istats
|-- run.stats
|-- test000001.cov
|-- test000001.covnew
|-- test000001.cvc
|-- test000001.features.csv
|-- test000001.features.csv.new
|-- test000001.ktest
|-- test000002.cov
|-- test000002.covnew
|-- test000002.cvc
|-- test000002.features.csv
|-- test000002.features.csv.new
|-- test000002.ktest
|-- test000003.cov
|-- test000003.cvc
|-- test000003.features.csv
|-- test000003.features.csv.new
|-- test000003.ktest
|-- test000004.cov
|-- test000004.cvc
|-- test000004.features.csv
|-- test000004.features.csv.new
|-- test000004.ktest
|-- test000005.cov
|-- test000005.cvc
|-- test000005.features.csv
|-- test000005.features.csv.new
|-- test000005.ktest
|-- test000006.cov
|-- test000006.cvc
|-- test000006.features.csv
|-- test000006.features.csv.new
|-- test000006.ktest
|-- test000007.cov
|-- test000007.cvc
|-- test000007.features.csv
|-- test000007.features.csv.new
|-- test000007.ktest
|-- test000008.cov
|-- test000008.covnew
|-- test000008.cvc
|-- test000008.features.csv
|-- test000008.features.csv.new
|-- test000008.ktest
|-- test000009.cov
|-- test000009.covnew
|-- test000009.cvc
|-- test000009.features.csv
|-- test000009.features.csv.new
|-- test000009.ktest
|-- test000010.cov
|-- test000010.covnew
|-- test000010.cvc
|-- test000010.features.csv
|-- test000010.features.csv.new
|-- test000010.ktest
|-- test000011.cov
|-- test000011.covnew
|-- test000011.cvc
|-- test000011.features.csv
|-- test000011.features.csv.new
|-- test000011.ktest
|-- test000012.cov
|-- test000012.cvc
|-- test000012.features.csv
|-- test000012.features.csv.new
|-- test000012.ktest
|-- test000013.cov
|-- test000013.covnew
|-- test000013.cvc
|-- test000013.features.csv
|-- test000013.features.csv.new
|-- test000013.ktest
|-- test000014.cov
|-- test000014.cvc
|-- test000014.features.csv
|-- test000014.features.csv.new
|-- test000014.ktest
|-- test000015.cov
|-- test000015.cvc
|-- test000015.features.csv
|-- test000015.features.csv.new
|-- test000015.ktest
|-- test000016.cov
|-- test000016.covnew
|-- test000016.cvc
|-- test000016.features.csv
|-- test000016.features.csv.new
|-- test000016.ktest
|-- test000017.cov
|-- test000017.covnew
|-- test000017.cvc
|-- test000017.features.csv
|-- test000017.features.csv.new
|-- test000017.ktest
|-- test000018.cov
|-- test000018.covnew
|-- test000018.cvc
|-- test000018.features.csv
|-- test000018.features.csv.new
|-- test000018.ktest
|-- test000019.cov
|-- test000019.covnew
|-- test000019.cvc
|-- test000019.features.csv
|-- test000019.features.csv.new
|-- test000019.ktest
|-- test000020.cov
|-- test000020.covnew
|-- test000020.cvc
|-- test000020.features.csv
|-- test000020.features.csv.new
|-- test000020.ktest
|-- test000021.cov
|-- test000021.covnew
|-- test000021.cvc
|-- test000021.features.csv
|-- test000021.features.csv.new
|-- test000021.ktest
|-- test000022.cov
|-- test000022.cvc
|-- test000022.features.csv
|-- test000022.features.csv.new
|-- test000022.ktest
|-- test000023.cov
|-- test000023.covnew
|-- test000023.cvc
|-- test000023.features.csv
|-- test000023.features.csv.new
|-- test000023.ktest
|-- test000024.cov
|-- test000024.cvc
|-- test000024.features.csv
|-- test000024.features.csv.new
|-- test000024.ktest
|-- test000025.cov
|-- test000025.covnew
|-- test000025.cvc
|-- test000025.features.csv
|-- test000025.features.csv.new
|-- test000025.ktest
|-- test000026.cov
|-- test000026.covnew
|-- test000026.cvc
|-- test000026.features.csv
|-- test000026.features.csv.new
|-- test000026.ktest
|-- test000027.cov
|-- test000027.cvc
|-- test000027.features.csv
|-- test000027.features.csv.new
|-- test000027.ktest
|-- test000028.cov
|-- test000028.cvc
|-- test000028.features.csv
|-- test000028.features.csv.new
|-- test000028.ktest
|-- test000029.cov
|-- test000029.covnew
|-- test000029.cvc
|-- test000029.features.csv
|-- test000029.features.csv.new
|-- test000029.ktest
|-- test000030.cov
|-- test000030.covnew
|-- test000030.cvc
|-- test000030.features.csv
|-- test000030.features.csv.new
|-- test000030.ktest
|-- test000031.cov
|-- test000031.cvc
|-- test000031.features.csv
|-- test000031.features.csv.new
|-- test000031.ktest
|-- test000032.cov
|-- test000032.covnew
|-- test000032.cvc
|-- test000032.features.csv
|-- test000032.features.csv.new
|-- test000032.ktest
|-- test000033.cov
|-- test000033.cvc
|-- test000033.features.csv
|-- test000033.features.csv.new
|-- test000033.ktest
|-- test000034.cov
|-- test000034.covnew
|-- test000034.cvc
|-- test000034.features.csv
|-- test000034.features.csv.new
|-- test000034.ktest
|-- test000035.cov
|-- test000035.covnew
|-- test000035.cvc
|-- test000035.features.csv
|-- test000035.features.csv.new
|-- test000035.ktest
|-- test000036.cov
|-- test000036.covnew
|-- test000036.cvc
|-- test000036.features.csv
|-- test000036.features.csv.new
|-- test000036.ktest
|-- test000037.cov
|-- test000037.covnew
|-- test000037.cvc
|-- test000037.features.csv
|-- test000037.features.csv.new
|-- test000037.ktest
|-- test000038.cov
|-- test000038.cvc
|-- test000038.features.csv
|-- test000038.features.csv.new
|-- test000038.ktest
|-- test000039.cov
|-- test000039.covnew
|-- test000039.cvc
|-- test000039.features.csv
|-- test000039.features.csv.new
|-- test000039.ktest
|-- test000040.cov
|-- test000040.cvc
|-- test000040.features.csv
|-- test000040.features.csv.new
|-- test000040.ktest
|-- test000041.cov
|-- test000041.cvc
|-- test000041.features.csv
|-- test000041.features.csv.new
|-- test000041.ktest
|-- test000042.cov
|-- test000042.covnew
|-- test000042.cvc
|-- test000042.features.csv
|-- test000042.features.csv.new
|-- test000042.ktest
|-- test000043.cov
|-- test000043.cvc
|-- test000043.features.csv
|-- test000043.features.csv.new
|-- test000043.ktest
|-- test000044.cov
|-- test000044.covnew
|-- test000044.cvc
|-- test000044.features.csv
|-- test000044.features.csv.new
|-- test000044.ktest
|-- test000045.cov
|-- test000045.covnew
|-- test000045.cvc
|-- test000045.features.csv
|-- test000045.features.csv.new
|-- test000045.ktest
`-- warnings.txt
info中保存的信息如下:
klee --simplify-sym-indices --write-cvcs --write-cov --output-module --disable-inlining --optimize --use-forked-solver --use-cex-cache --libc=uclibc --posix-runtime --external-calls=all --watchdog --max-memory-inhibit=false --switch-type=internal --dump-states-on-halt=false --output-dir=/root/train_data/random-path-0/b2sum --env-file=/tmp/test.env --run-in-dir=/tmp/sandbox-b2sum/sandbox --max-memory=4096 --max-time=60s --feature-dump --feature-extract --use-branching-search --search=random-path /root/learch/learch/benchmarks/coreutils-8.31/obj-llvm/src/b2sum.bc --sym-args 0 1 10 --sym-args 0 2 2 --sym-files 1 8 --sym-stdin 8 --sym-stdout
PID: 19283
Using monotonic steady clock with 1/1000000000s resolution
Started: 2022-09-12 08:50:18
BEGIN searcher description
<BranchingSearcher>, baseSearcher:
<GetFeaturesSearcher>, baseSearcher:
RandomPathSearcher
</GetFeaturesSearcher>
</BranchingSearcher>
END searcher description
Finished: 2022-09-12 08:51:19
Elapsed: 00:01:01
KLEE: done: explored paths = 372
KLEE: done: avg. constructs per query = 117
KLEE: done: total queries = 1877
KLEE: done: valid queries = 1095
KLEE: done: invalid queries = 782
KLEE: done: query cex = 1877
KLEE: done: total instructions = 785558
KLEE: done: completed paths = 45
KLEE: done: generated tests = 45
可以看到有45个test,每个test对应1个cov文件表示覆盖了哪些文件哪些代码行,1个covnew文件,1个cvc文件,2个csv文件,一个ktest文件
-
然后运行
cd到/root/learch/learch/train目录下运行python3 collect_scores.py --prog_list ../benchmarks/coreutils_train.txt --output_dir ~/train_data --iter 0,我这里只用到了b2sum一个程序,所以如果你也只用了这一个程序记得将benchmarks/coreutils_train.txt清到只剩下b2sum一行,运行完之后train_data目录下会生成all_features-0.npy和all_lengths-0.npy2个npy文件,可以看出 klee,score.py和collect_scores.py一起完成paper中算法3 Generating a supervised dataset-
klee完成 t e s t s ← s y m E x e c ( p r o g , s t r a t e g y ) tests \leftarrow symExec(prog, strategy) tests←symExec(prog,strategy)
-
score.py完成 n e w D a t a ← d a t a F r o m T e s t s ( t e s t s ) newData \leftarrow dataFromTests(tests) newData←dataFromTests(tests) 和 d a t a s e t ← d a t a s e t ∪ n e w D a t a dataset \leftarrow dataset \cup newData dataset←dataset∪newData ( n e w D a t a newData newData 对应代码中all_features.npy文件) -
collect_scores.py第34-37行代码完成 d a t a s e t ← d a t a s e t ∪ n e w D a t a dataset \leftarrow dataset \cup newData dataset←dataset∪newData,而26-28行(内容如下)完成算法4中的 d a t a s e t ← d a t a s e t ∪ n e w D a t a dataset \leftarrow dataset \cup newData dataset←dataset∪newData
-
if args.iter > 0:
data.append(np.load(os.path.join(args.output_dir, f'all_features-{args.iter-1}.npy')))
lengths.append(np.load(os.path.join(args.output_dir, f'all_lengths-{args.iter-1}.npy')))
一个test(test00001.feature.csv)对应的csv文件内容如下(key太多了,列举不下):
| Index | QueryCost | … |
|---|---|---|
| 0 | 0 | … |
| 1 | 0.007 | … |
| 3 | 0.019 | … |
| 4 | 0.218 | … |
csv中所有的key包括:Index,QueryCost,QueryCostAcc,InstsCovAcc,LinesCovAcc,InstsCovNew,LinesCovNew,Depth,Stack,GeneratedTestCases,InstCount,CPInstCount,NumSucc,InstsSinceCovNew,SGS1,SGS2,SGS4,SGS8,Constant,NotOptimized,Read,Select,Concat,Extract,ZExt,SExt,Not,Add,Sub,Mul,UDiv,SDiv,URem,SRem,And,Or,Xor,Shl,LShr,AShr,Eq,Ne,Ult,Ule,Ugt,Uge,Slt,Sle,Sgt,Sge
Index 对应的是该state对应的索引(同一个state可能出现在多个test中,比如test00002中也有state 1),QueryCost 表示该state的stateTime,csv中前1个state是后一个state的parent,在遍历csv时,作者的代码是反向遍历的,就是为了方便累计totalTime,同时每一个test的最后1个state是leaf结点,作者在计算feature的时候drop掉最后1行数据(可能是leaf结点已经不需要做决策了)
-
运行
model.py,进入调试模式,可以发现,model的目标是将每个state的feature(47维向量)映射到reward(label是根据paper中综合所有Tests根据totalTime和totalCov计算出来的),用到的loss是MSE Loss,model.py完成的是算法4中的功能(主体功能在model.do_train中定义 )-
n e w S t r a t e g y ← t r a i n S t r a t e g y ( d a t a s e t ) newStrategy \leftarrow trainStrategy(dataset) newStrategy←trainStrategy(dataset) 为训练代码,需要注意的是 t r a i n S t r a t e g y trainStrategy trainStrategy 也可以包含多个epoch,只是在 t r a i n S t r a t e g y trainStrategy trainStrategy 内部训练数据集不会改变
-
s t r a t e g i e s ← n e w S t r a t e g y strategies \leftarrow {newStrategy} strategies←newStrategy 对应模型保存,以后就只加载新模型了
-
代码我就分析到这里,我接触klee并不多,所以作者对klee的修改我就没写了。总的来说learch的ML部分乍一看是强化学习,但实际上依旧是有监督学习,原理上要简单很多。















 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









