










Graphick
1.Introduction
作者提出了一种partial context-sensitive pointer analysis算法。artifact地址。
motivating example

这幅图中在对21行 A a = (A)c1.get(); 和 23行 B b = (B)c2.get(); 进行类型验证 (cast 是否会发生异常) 时需要准确分析出 a 指向object A1,b 指向object B1。如果用context-insensitive方法分析,那么 C::set 方法中 data = e 可推导出 this.data 指向 {A1, B1},因此 a, b 都会指向 {A1, B1},会判定 cast 操作不安全。
通过context(object)-sensitive分析可以得出在context C1 下调用 C::set, this.data 指向 A1,在context C2 下调用指向 B1。但是如果全量context-sensitive分析 F1, F2 两个object之后也会展开,而并没有带来精度提升。因此需要一种选择性的context-sensitive策略。
之前的工作
[
2
]
,
[
3
]
^{[2],[3]}
[2],[3]提出了object-allocation-graph (上述代码的OAG如下所示) 来描述object之间的context关系。前面示例的OAG如下图所示,F1, F2 的成员函数中分配了 A1, B1, C1, C2。而 C1, C2 的成员函数分配了 O。
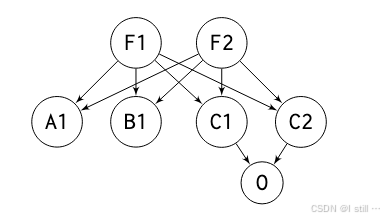
下图为policy推导出的选中进行context-sensitive分析的结点满足的条件:
-
1.其所有前驱结点入变边数量在 [ 0 , ∞ ] [0, \infty] [0,∞],出边数量在 [ 2 , ∞ ] [2, \infty] [2,∞]。
-
2.其所有结点入变边数量在 [ 0 , ∞ ] [0, \infty] [0,∞],出边数量在 [ 0 , ∞ ] [0, \infty] [0,∞]。
-
3.其所有后继结点入变边数量在 [ 2 , ∞ ] [2, \infty] [2,∞],出边数量在 [ 0 , ∞ ] [0, \infty] [0,∞]。
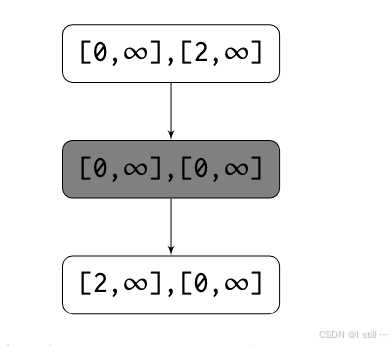
满足条件的object只有 C1, C2。因此对 C1, C2 所有成员函数调用进行context-sensitive分析。
2.Preliminaries
2.1.Baseline Pointer Analysis
| Notation | 含义 | 示例 |
|---|---|---|
| V \mathbb{V} V | 程序变量集合 | A a 定义了一个 A 类型变量 a |
| H \mathbb{H} H | 堆分配点(allcation site)集合 | v = new C 新建了一个 C 类型的堆对象 |
| M \mathbb{M} M | 方法(method)集合 | void main() { ... } 为 main 方法 |
| C \mathbb{C} C | 调用context | 定义为一个allocation sites序列 |
| H C \mathbb{HC} HC | 堆context | 定义为一个allocation sites序列,和 H C \mathbb{HC} HC 等价 |
| t h i s m this_m thism | 方法
m
m
m 的 this 变量 | |
| p a r a m m param_m paramm | 方法 m m m 的形参 | |
| r e t u r n m return_m returnm | 方法 m m m 的返回值 | |
| ∥ \Vert ∥(原文的符号打不出来) | 在一个序列后append一个元素,用来在context中添加一个allocation site | s = < a 1 , . . . , a n > s = <a_1, ..., a_n> s=<a1,...,an>, s ∥ a ′ = < a 1 , . . . , a n , a ′ > s \Vert a^{'} = <a_1, ..., a_n, a^{'}> s∥a′=<a1,...,an,a′> |
| ⌈ ⌉ k \lceil \rceil_{k} ⌈⌉k | 取序列后 k k k 个元素 | ⌈ ⟨ a 1 , a 2 , . . . , a n ⟩ ⌉ k = ⟨ a n − k + 1 , . . . , a n ⟩ \lceil⟨a_1, a_2, ... , a_n ⟩\rceil_{k} = ⟨a_{n−k+1}, ... , a_n ⟩ ⌈⟨a1,a2,...,an⟩⌉k=⟨an−k+1,...,an⟩ |
在对象敏感分析中,调用context和堆context等价。
| 指令类型 | 示例 | 关键信息 | 说明 |
|---|---|---|---|
Alloca | v = n e w C v = new \; C v=newC | ( v a r , h e a p , i n M e t h ) (var, heap, inMeth) (var,heap,inMeth) | 变量(v), 堆对象(new C), 语句所处方法 |
Copy | x = y x = y x=y | ( t o , f r o m , i n M e t h ) (to, from, inMeth) (to,from,inMeth) | from变量 y, to变量 x, 语句所处方法 |
Field Load | x = y . f x = y.f x=y.f | ( t o , f r o m , f l d , i n M e t h ) (to, from, fld, inMeth) (to,from,fld,inMeth) | from变量 y, to变量 x, 加载的fld f, 语句所处方法 |
Field Store | x . f = y x.f = y x.f=y | ( t o , f l d , f r o m , i n M e t h ) (to, fld, from, inMeth) (to,fld,from,inMeth) | from变量 y, to变量 x, 写入的fld f, 语句所处方法 |
Call | x = y . m c a l l e e ( a r g ) x = y.m_{callee}(arg) x=y.mcallee(arg) | ( r e t u r n , b a s e , c a l l e e , a r g , c a l l e r ) (return, base, callee, arg, caller ) (return,base,callee,arg,caller) | return变量 x,base变量 y,callee函数 m,参数 arg,以及语句所处方法caller |
| 分析输出 | 映射关系 | 说明 |
|---|---|---|
VarPtsTo | V × C → ( H × H C ) \mathbb{V} \times \mathbb{C} \rightarrow (\mathbb{H} \times \mathbb{HC}) V×C→(H×HC) | 将变量 v v v 映射到在context c c c 下所有所有指向的 (heap context, heap object) 对。 |
FldPtsTo | H × H C × F → ( H × H C ) \mathbb{H} \times \mathbb{HC} \times \mathbb{F} \rightarrow (\mathbb{H} \times \mathbb{HC}) H×HC×F→(H×HC) | 将heap object h h h 的field f f f ( h . f h.f h.f) 映射到在context h c hc hc 下的所有 (heap context, heap object) 对。 |
MethodCtx | M → C \mathbb{M} \rightarrow \mathbb{C} M→C | 将method m m m 映射到所有涉及到的context下 |
context-sensitive指针分析transfer rule如下,context-insensitive规则本质上就是将所有 h c t x hctx hctx 固定为常量。
| 指令 | 规则 |
|---|---|
Alloca | ( v a r , h e a p , i n M e t h ) ∈ A l l o c c t x ∈ M e t h o d C t x ( i n M e t h ) h c t x = ⌈ c t x ⌉ m a x H ( h e a p , h c t x ) ∈ V a r P t s T o ( v a r , c t x ) \frac{(var, \; heap, \; inMeth) \in Alloc \quad ctx \; \in \; MethodCtx(inMeth) \quad hctx = \lceil ctx \rceil_{maxH}}{(heap, \; hctx) \; \in \; VarPtsTo(var, \; ctx)} (heap,hctx)∈VarPtsTo(var,ctx)(var,heap,inMeth)∈Allocctx∈MethodCtx(inMeth)hctx=⌈ctx⌉maxH |
Copy | ( t o , f r o m , i n M e t h ) ∈ C o p y c t x ∈ M e t h o d C t x ( i n M e t h ) V a r P t s T o ( f r o m , c t x ) ⊆ V a r P t s T o ( t o , c t x ) \frac{(to, \; from, \; inMeth ) \in Copy \quad ctx \; \in \; MethodCtx(inMeth)}{VarPtsTo(from, \; ctx) \; \subseteq \; VarPtsTo(to, \; ctx)} VarPtsTo(from,ctx)⊆VarPtsTo(to,ctx)(to,from,inMeth)∈Copyctx∈MethodCtx(inMeth) |
Field Load | ( t o , f r o m , f l d , i n M e t h ) ∈ F l d L o a d c t x ∈ M e t h o d C t x ( i n M e t h ) ( h e a p , h c t x ) ∈ V a r P t s T o ( f r o m , c t x ) F l d P t s T o ( h e a p , h c t x , f l d ) ⊆ V a r P t s T o ( t o , c t x ) \frac{(to, \; from, \; fld, \; inMeth) \in FldLoad \quad ctx \; \in \; MethodCtx(inMeth) \quad (heap, \; hctx) \; \in \; VarPtsTo(from, \; ctx)}{FldPtsTo(heap, \; hctx , \; fld ) \; \subseteq \; VarPtsTo(to, ctx)} FldPtsTo(heap,hctx,fld)⊆VarPtsTo(to,ctx)(to,from,fld,inMeth)∈FldLoadctx∈MethodCtx(inMeth)(heap,hctx)∈VarPtsTo(from,ctx) |
Field Store | ( t o , f l d , f r o m , i n M e t h ) ∈ F l d S t o r e c t x ∈ M e t h o d C t x ( i n M e t h ) ( h e a p , h c t x ) ∈ V a r P t s T o ( t o , c t x ) V a r P t s T o ( f r o m , c t x ) ∈ F l d P t s T o ( h e a p , h c t x , f l d ) \frac{(to, \; fld, \; from, \; inMeth) \in FldStore \quad ctx \; \in \; MethodCtx(inMeth) \quad (heap, \; hctx) \; \in \; VarPtsTo(to, \; ctx)}{VarPtsTo(from, \; ctx) \; \in \; FldPtsTo(heap, \; hctx, \; fld)} VarPtsTo(from,ctx)∈FldPtsTo(heap,hctx,fld)(to,fld,from,inMeth)∈FldStorectx∈MethodCtx(inMeth)(heap,hctx)∈VarPtsTo(to,ctx) |
Call | ( r e t u r n , b a s e , c a l l e e , a r g , c a l l e r ) ∈ C a l l c t x ∈ M e t h o d C t x ( c a l l e r ) ( h e a p , h c t x ) ∈ V a r P t s T o ( b a s e , c t x ) c t x ′ = ⌈ h c t x ∥ h e a p ⌉ m a x K c t x ′ ∈ M e t h o d C t x ( c a l l e e ) V a r P t s T o ( a r g , c t x ) ⊆ V a r P t s T o ( p a r a m c a l l e e , c t x ′ ) ( h e a p , h c t x ) ∈ V a r P t s T o ( t h i s c a l l e e , c t x ′ ) V a r P t s T o ( r e t u r n c a l l e e , c t x ′ ) ⊆ V a r P t s T o ( r e t u r n , c t x ) \frac{(return, \; base, \; callee, \; arg, \; caller) \; \in \; Call \quad ctx \; \in \; MethodCtx(caller) \quad (heap, hctx) \; \in \; VarPtsTo(base, ctx) \quad ctx^{'} \; = \; \lceil hctx \; \Vert \; heap \rceil_{maxK}}{ctx^{'} \; \in \; MethodCtx(callee) \quad VarPtsTo(arg, ctx) \; \subseteq \; VarPtsTo(param_{callee}, ctx^{'}) \quad (heap, hctx ) \in VarPtsTo(this_{callee} , ctx^{'}) \quad VarPtsTo(return_{callee} , ctx^{′}) \subseteq VarPtsTo(return, \; ctx)} ctx′∈MethodCtx(callee)VarPtsTo(arg,ctx)⊆VarPtsTo(paramcallee,ctx′)(heap,hctx)∈VarPtsTo(thiscallee,ctx′)VarPtsTo(returncallee,ctx′)⊆VarPtsTo(return,ctx)(return,base,callee,arg,caller)∈Callctx∈MethodCtx(caller)(heap,hctx)∈VarPtsTo(base,ctx)ctx′=⌈hctx∥heap⌉maxK |
2.2.Parameterization
Parametric Object Sensitivity: 前面分析规则中对context深度的处理涉及到计算 m a x K maxK maxK 值。作者定义了一个 C o n t e x t A b s t r a c t i o n : H → [ 0 , m a x K ] ContextAbstraction: H \rightarrow [0, maxK] ContextAbstraction:H→[0,maxK] 函数将heap object映射到context深度。
Parametric Heap Abstraction: 堆抽象有2种方式, allocation-based以及type-based。allocation-based为每一个 new 调用点分配一个object,type-based为每个class type分配一个object。分析出来的 VarPtsTo 和 FldPtsTo 集合会调整如下,作者定义了一个
H
e
a
p
A
b
s
t
r
a
c
t
i
o
n
HeapAbstraction
HeapAbstraction 函数,如果
H
e
a
p
A
b
s
t
r
a
c
t
i
o
n
(
h
e
a
p
)
=
=
a
l
l
o
c
HeapAbstraction(heap) == alloc
HeapAbstraction(heap)==alloc,那么object为allocation-site,反之,为
t
y
p
e
o
f
(
h
e
a
p
)
typeof(heap)
typeof(heap)。
-
VarPtsTo: V × C → ( ( H + T ) × H C ) \mathbb{V} \times \mathbb{C} \rightarrow ((\mathbb{H} + \mathbb{T}) \times \mathbb{HC}) V×C→((H+T)×HC) -
FldPtsTo: ( H + T ) × H C × F → ( ( H + T ) × H C ) (\mathbb{H} + \mathbb{T}) \times \mathbb{HC} \times \mathbb{F} \rightarrow ((\mathbb{H} + \mathbb{T}) \times \mathbb{HC}) (H+T)×HC×F→((H+T)×HC)
3.Graphick
graphick的策略由feature描述,feature为一个 ( p r e v , ( [ a , b ] , [ c , d ] ) , s u c c ) (prev, ([a, b], [c, d]), succ) (prev,([a,b],[c,d]),succ) 3元组。interval pair ( [ a , b ] , [ c , d ] ) ([a, b], [c, d]) ([a,b],[c,d]) 表示被选中的node入边数量在 [ a , b ] [a, b] [a,b] 之间出边数量在 [ c , d ] [c, d] [c,d] 之间。 p r e v prev prev 和 s u c c succ succ 为interval序列,描述前驱和后继结点入边和出边数量。
策略由一组参数 ∏ = < F 1 , F 2 , . . . F k > \prod = <F_1, F_2, ... F_k> ∏=<F1,F2,...Fk> 组成, F i F_i Fi 包含一组feature。策略会给OAG上每一个结点赋予一个degree j j j,如果被 F 1 F_1 F1 选中,那么 j = 1 j = 1 j=1,被 F k F_k Fk 选中,那么 j = k j = k j=k。如果同时被多个feature选中,那么取最大值。degree j j j 表示进行 j-context-sensitive分析。作者的insight大概在于OAG上不同pattern(比如自身入度多少,出度多少;前驱后继入度、出度)的node应该用不同的上下文敏感度进行分析。具体多少无法人工指定需要学习。策略的学习需要训练样本(也就是几个程序),学习的核心包含一个Learning Minimal Abstraction函数和一个Learning a Set of Features函数。
(1).Learning Minimal Abstraction
指针分析的目标是能够尽可能以最少的代价验证程序中的 cast 操作是否会fail。文中有一个公式
p
r
o
v
e
d
(
F
P
(
a
)
)
=
p
r
o
v
e
d
(
F
P
(
k
)
)
proved(F_P(a)) = proved(F_P(k))
proved(FP(a))=proved(FP(k)),左边表示基于策略对每个OAG结点赋予的degree进行敏感性分析能够达到的精度(能够验证may-cast-fail的数量),右边表示用精度最高的敏感性分析(每个OAG结点都采用最大值
k
k
k-context-sensitive分析)。学习的目标就是学到minimal abstraction来分配degree。算法如下,概括一下就是一个搜索算法,复杂度为
k
⋅
2
∣
C
P
∣
k · 2^{|C_P|}
k⋅2∣CP∣。
∣
C
P
∣
|C_P|
∣CP∣ 可以理解是OAG的结点数量。

(2).Learn a Set of Feature
给每个degree j j j 学习一组feature F j F_j Fj。过程如下面Algo3所描述。

学习单个feature过程如Algo4描述,其中 S c o r e ( f , C ) = ∑ P ∈ P ∣ C ∩ γ G P ( P ) ( f ) ∣ ∑ P ∈ P ∣ γ G P ( P ) ( f ) ∣ Score(f , C) = \frac{\sum \textit{P} \in P | C \cap \gamma_{G_P}(P)(f)|}{\sum \textit{P} \in P | \gamma_{G_P}(P)(f)|} Score(f,C)=∑P∈P∣γGP(P)(f)∣∑P∈P∣C∩γGP(P)(f)∣,大概意思是如果策略选中的node都在 C C C 中,那么score为1;当开始选中 C C C 之外的node,score开始下降。这里需要人工指定一个阈值 θ \theta θ。具体过程太复杂了,就不展开了。
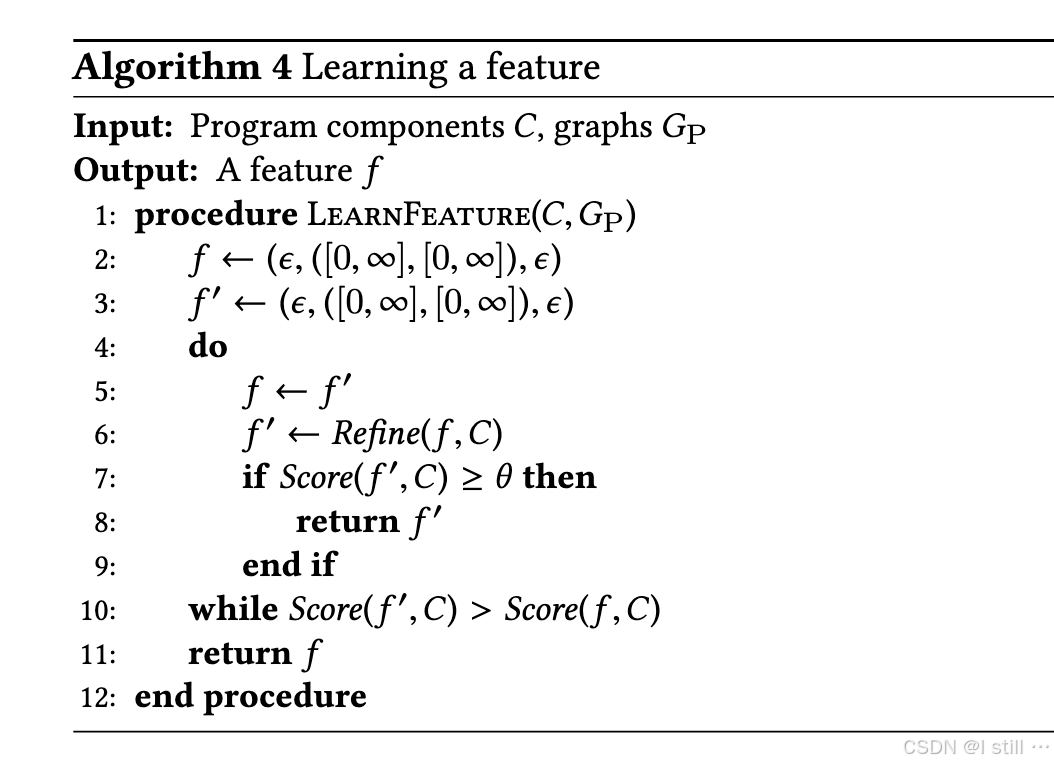
4.Evaluation
-
RQ1: Graphick与baseline策略比较性能如何?
-
RQ2: learning开销如何?超参数 θ \theta θ 对Graphick性能有什么影响?
-
RQ3: 学习到的策略能看出什么insight?
作者基于Doop实现Graphick。对于精度:
-
1.cast-fail分析,作者跟随之前的work采用may-fail分析,也就是只要存在fail的可能就报错。
-
2.作者拿polymorphic call sites和call-edges的数量作为额外精度指标,理论上数量越少精度越高。
每次分析作者设定超时时间3 hours,对于 θ \theta θ,作者从0.1到0.9每个0.1取值(总共9个)。对于每个feature,作者限定最多选择3 node。
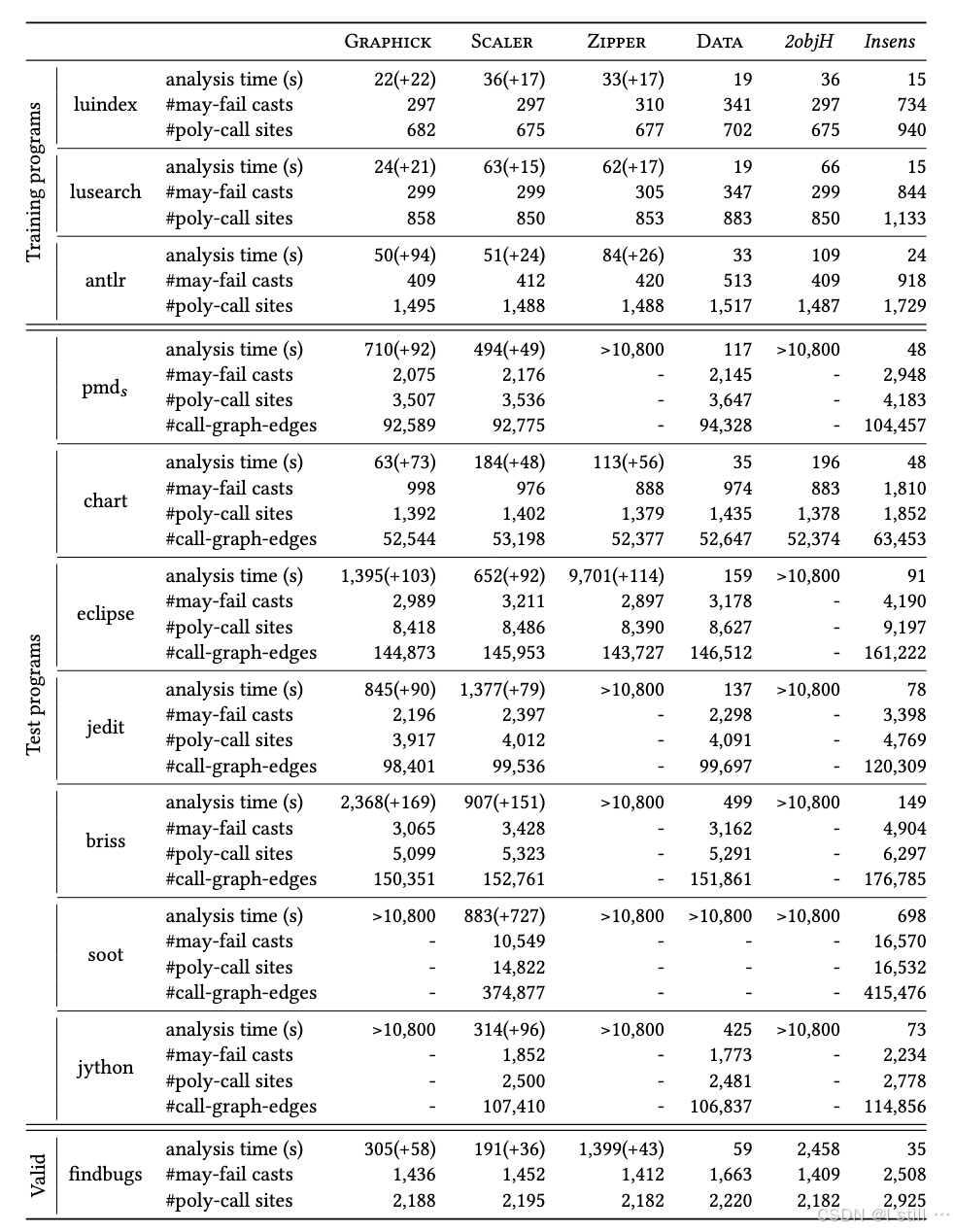
对于benchmark,作者从decapo选择10个(luindex, lusearch, antlr, pmdm , chart, eclipse, fop, bloat, xalan, and jython),以及从之前工作选择7个 (pmds , jedit, briss, soot, findbugs, JPC, checkstyle)。
这里先放出RQ1的部分结果。RQ2的跳过。
baseline:
-
Scaler: 基于OAG的人工制定的object-sensitivity策略。
-
Zipper: 基于PFG的人工制定的object-sensitivity策略。
-
Data:一种learning-based object-sensitivity策略。
-
2objH: 2-object-sensitivity、1-context sensitivity heap。默认精度上限,开销最大。
-
Insens: 不敏感的分析,精度下限,开销最小。
作者选择3个程序作为训练集,1个验证集,剩下13个测试集。效果如下:
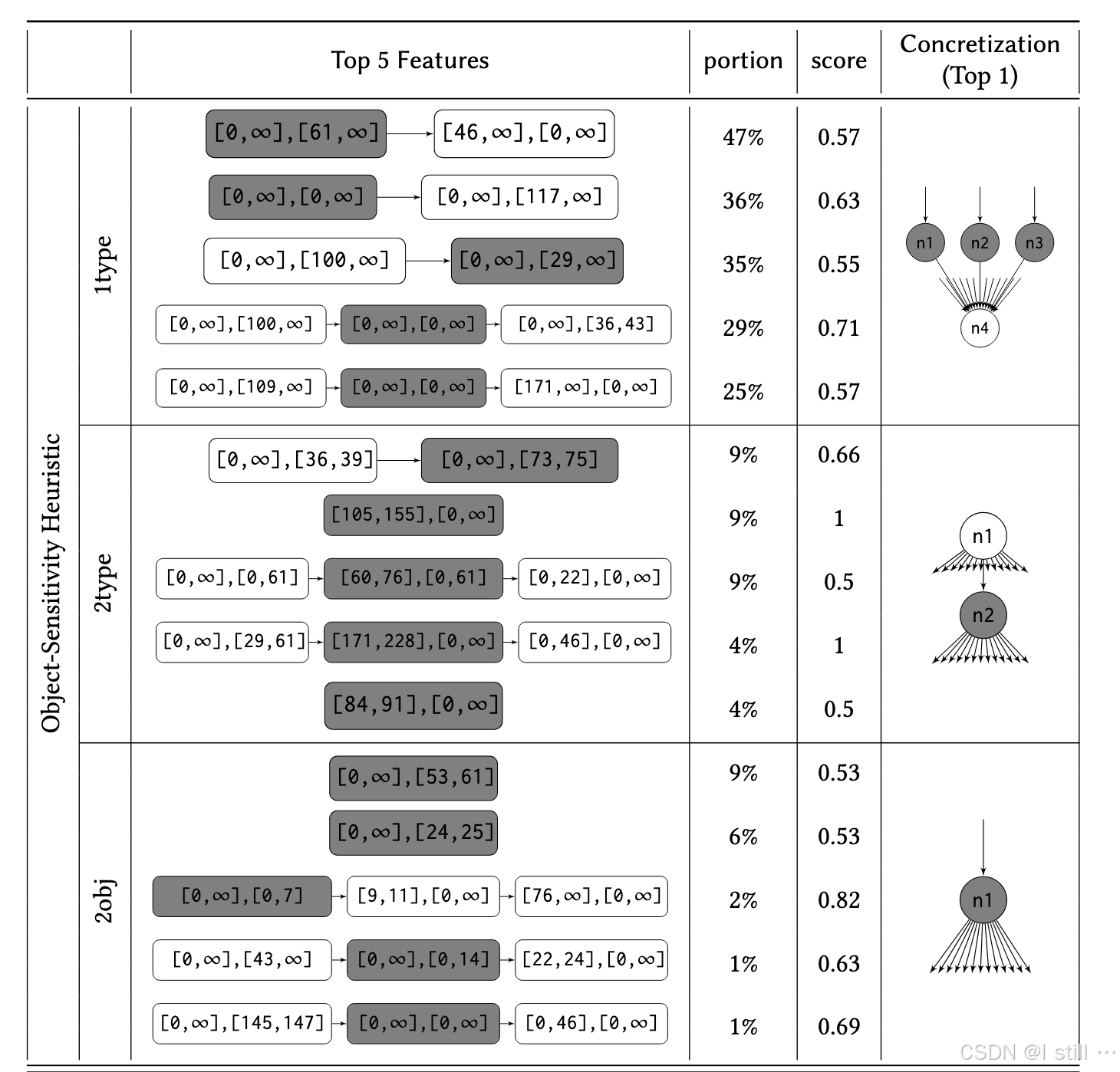
RQ3: 作者限制最大上下文敏感度是2,学习的策略总共包含了197个feature,总共包含68个2-object-sensitivity feature,29个2-type-sensitivity feature, 以及100个1-type-sensitivity feature。下图列出了几个top-5 feature,portion表示它们选择的precision-critical nodes的占比,score表示得分。

















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









