






实验内容:
实验数据来自一家大型石油气配送企业,目前业务区域已经涵盖湖北省内大部分城市。企业面向的客户身份比较复杂,主要分为五类客户群体:居民、商户、上门、信用客户、合作商。
居民,商户,上门的区别主要是价格不同,居民客户是指用量少的客户,商户是指用量比较大的客户,上门客户是指离直营门店近的客户,具体的购买价格(按每公斤单价)排序:居民 > 上门 > 商户。
信用客户是指可以先送气后结账的客户。
合作商是指企业的合作商户,直接从企业批量订购石油气卖给当地客户。
本次实验主要将企业的数据上传到MaxCompute数仓,在云端对这些客户数据进行统计,得到每个分类下的客户数量。
实验思路:
1.进入DataWorks上传本地数据到MaxCompute数仓。
2.通过DataWorks对MaxCompute数仓数据进行查询操作。
实验步骤:
下载CSV文件。
DataWorks上传的默认数据源为CSV文件,实验前需要先下载CSV文件。
https://university-labfileapp.oss-cn-hangzhou.aliyuncs.com/%E5%AE%8F%E9%B9%8F--%E5%A4%A7%E6%95%B0%E6%8D%AEACA/gas.csv
在【产品与服务列表】搜索框输入DataWorks,在搜索结果中点击大数据开发治理平台DataWorks,进入DataWorks控制台

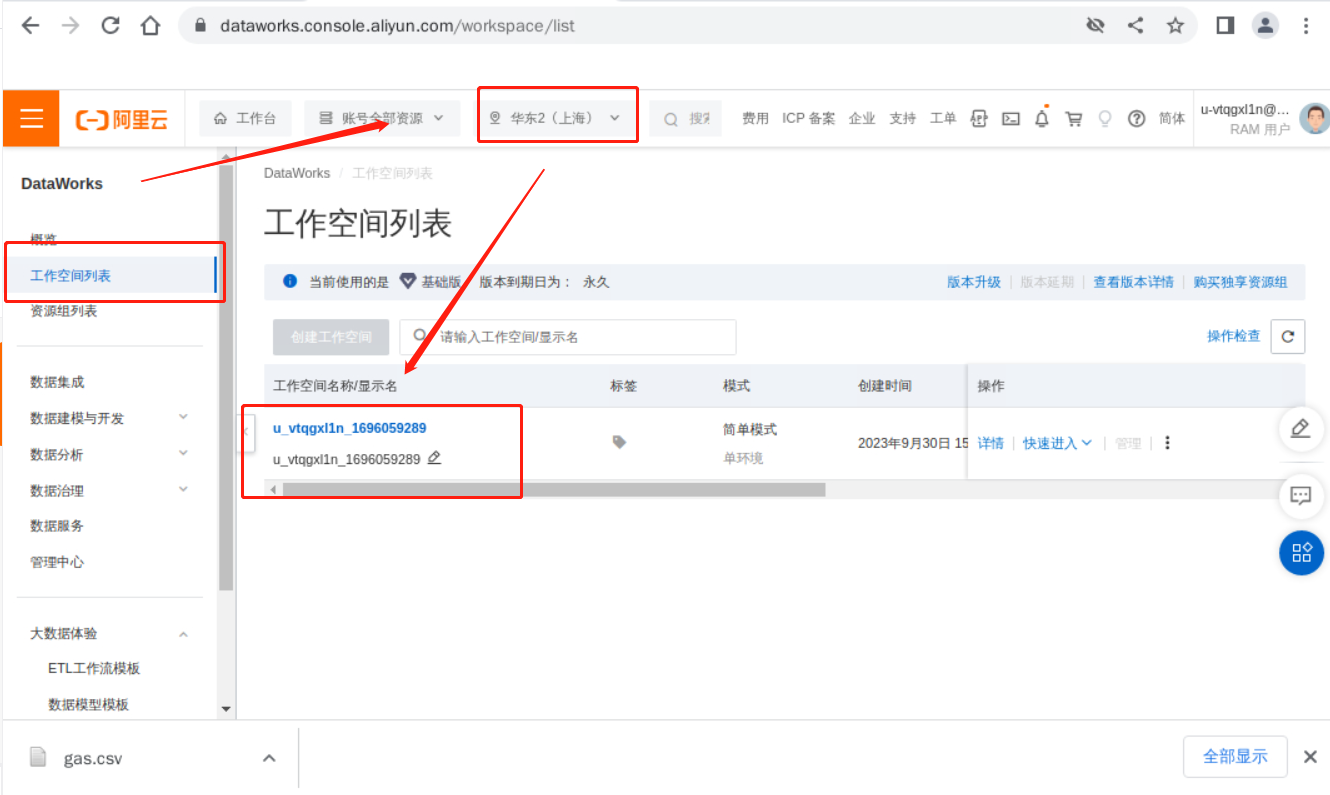
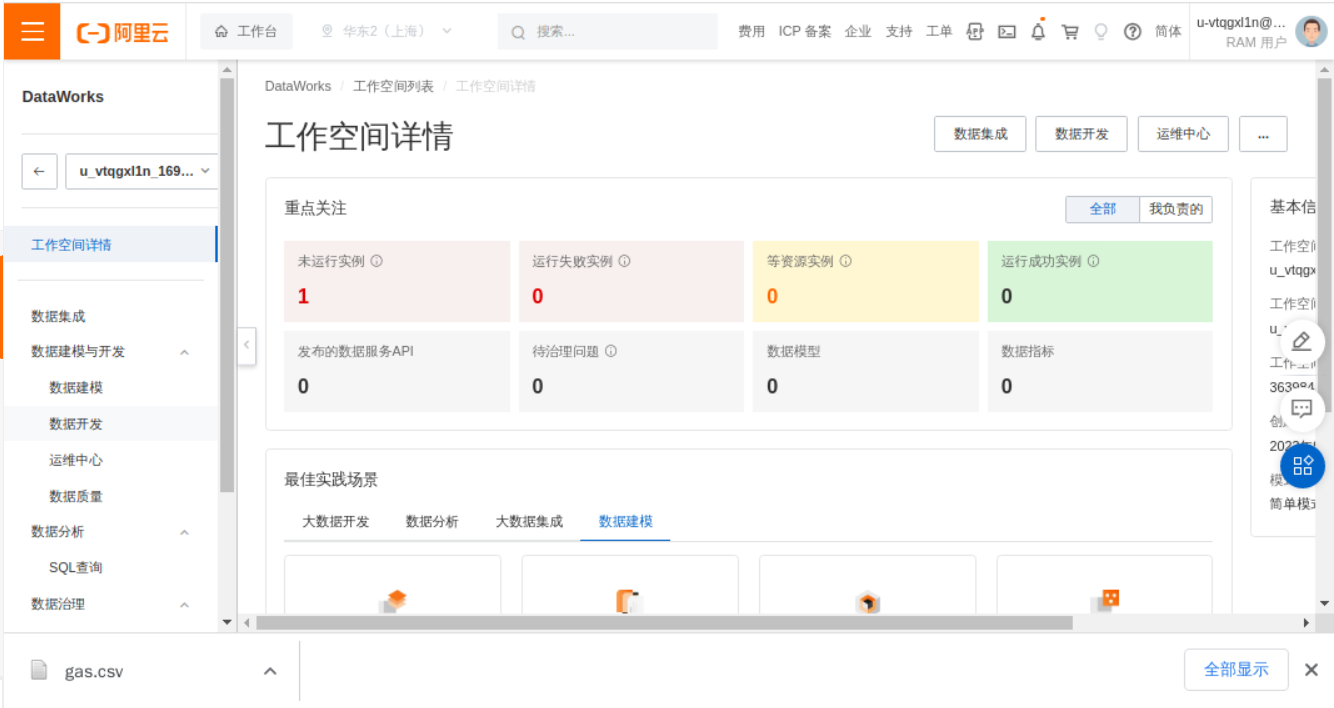
点击进入工作空间,选择数据开发。
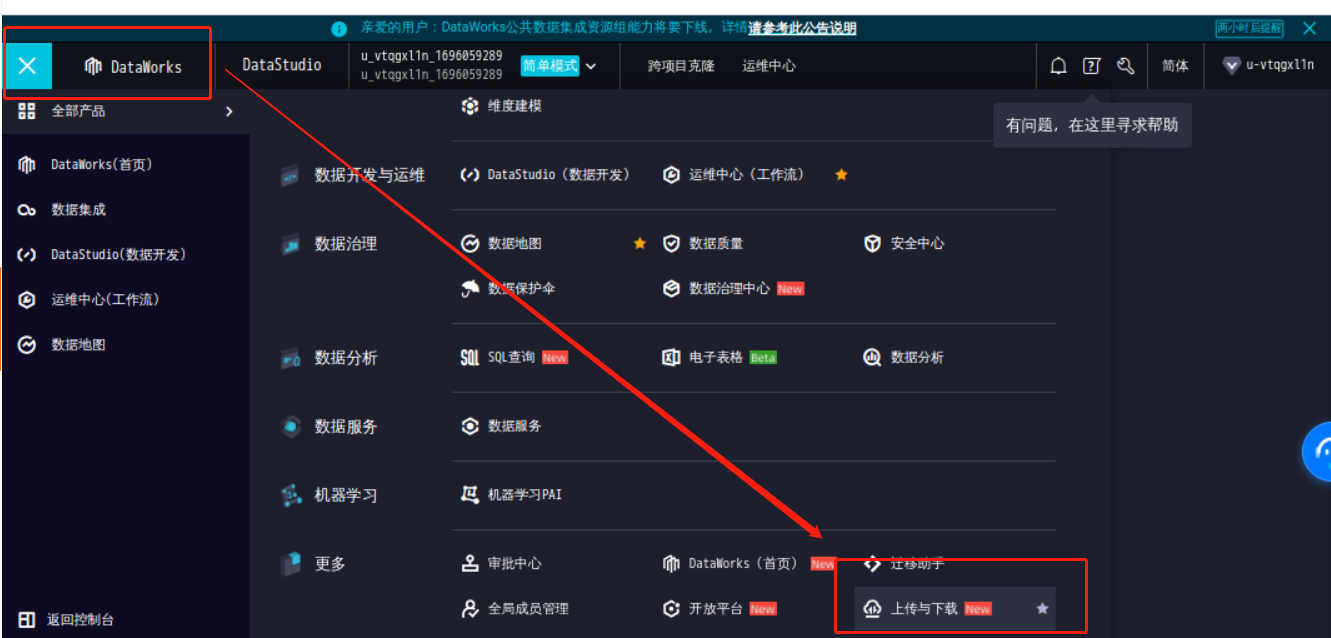
点击目录栏,选择上传和下载。
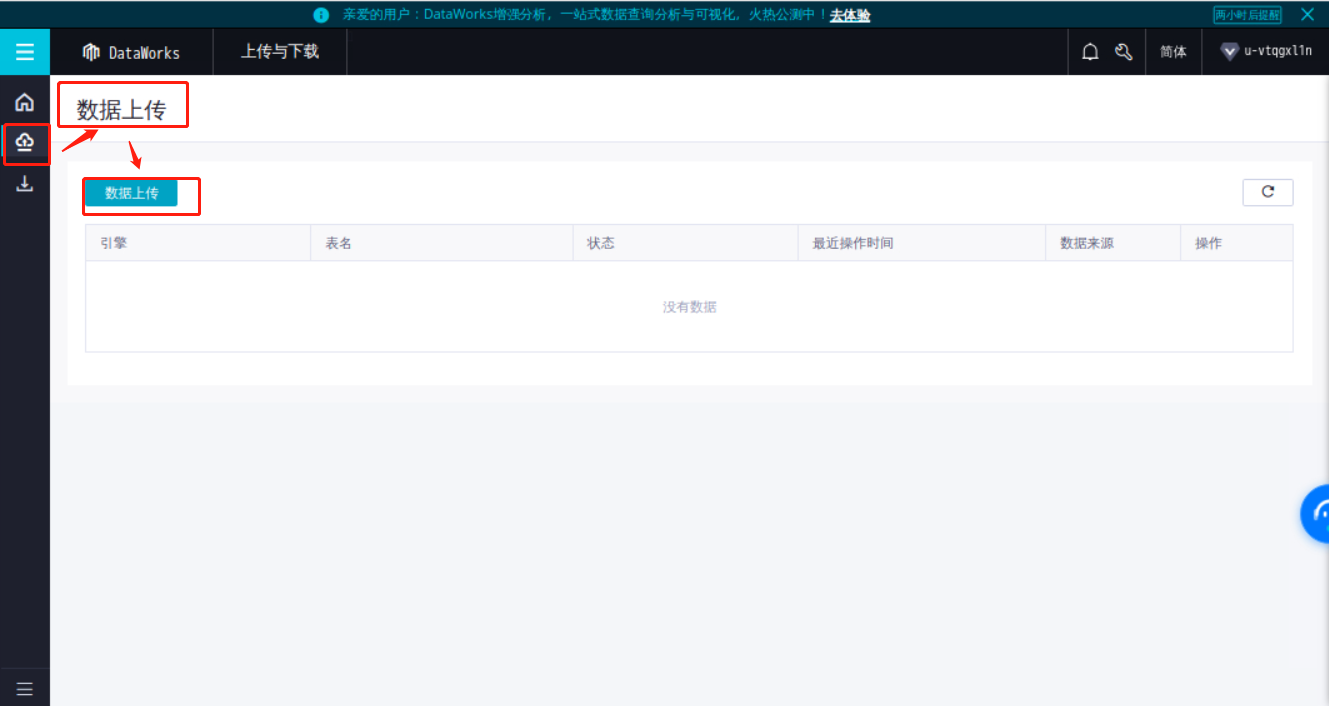
点击上传,选择数据上传按钮。
选择刚刚下载的文件。
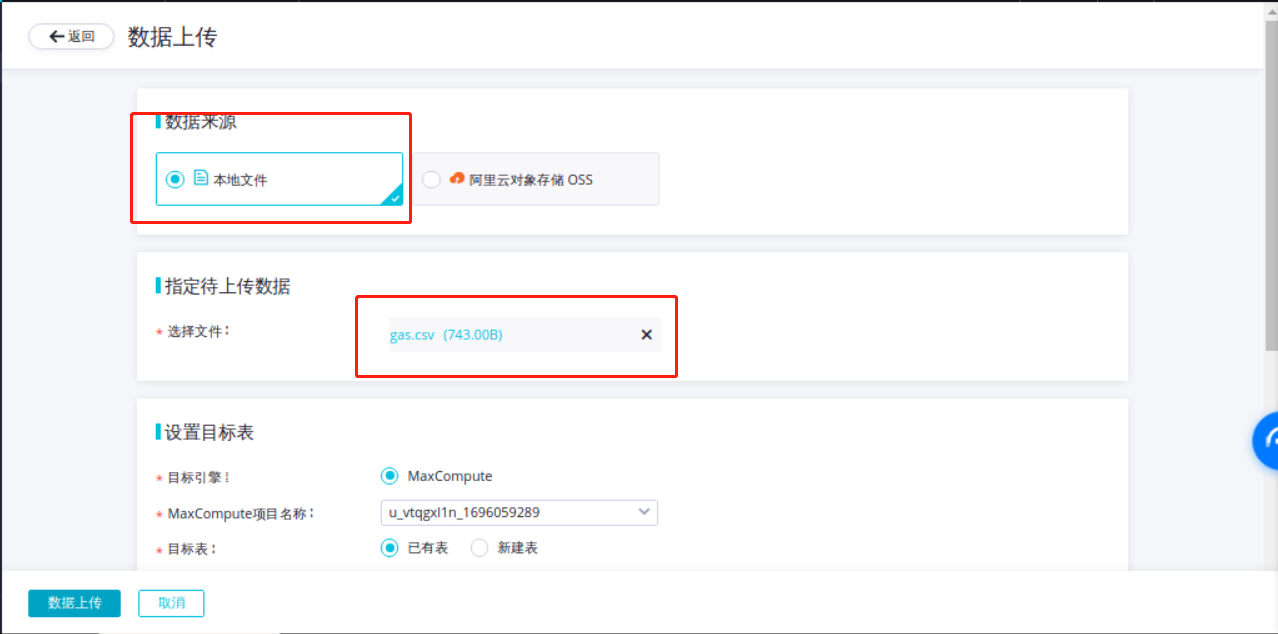

DataWorks会自动解析上传的CSV数据,所有字段属性都设置STRING。
由于DataWorks不支持字段名为中文,需要将字段名称改为英文或数字,修改字段名称,如下图所示:

上方的表格为上传的CSV文件预览数据,点击【提交】将数据保存到MaxCompute数仓。

点击提交按钮的效果如下图所示:

上传完成后会跳转到表管理页面,如下图所示:

点击数据查询。

找到【我的MaxCompute表】点击【添加】,在左侧出现【我的MaxCompute表】
只有添加了我的MaxCompute表数据集后才能继续实验。
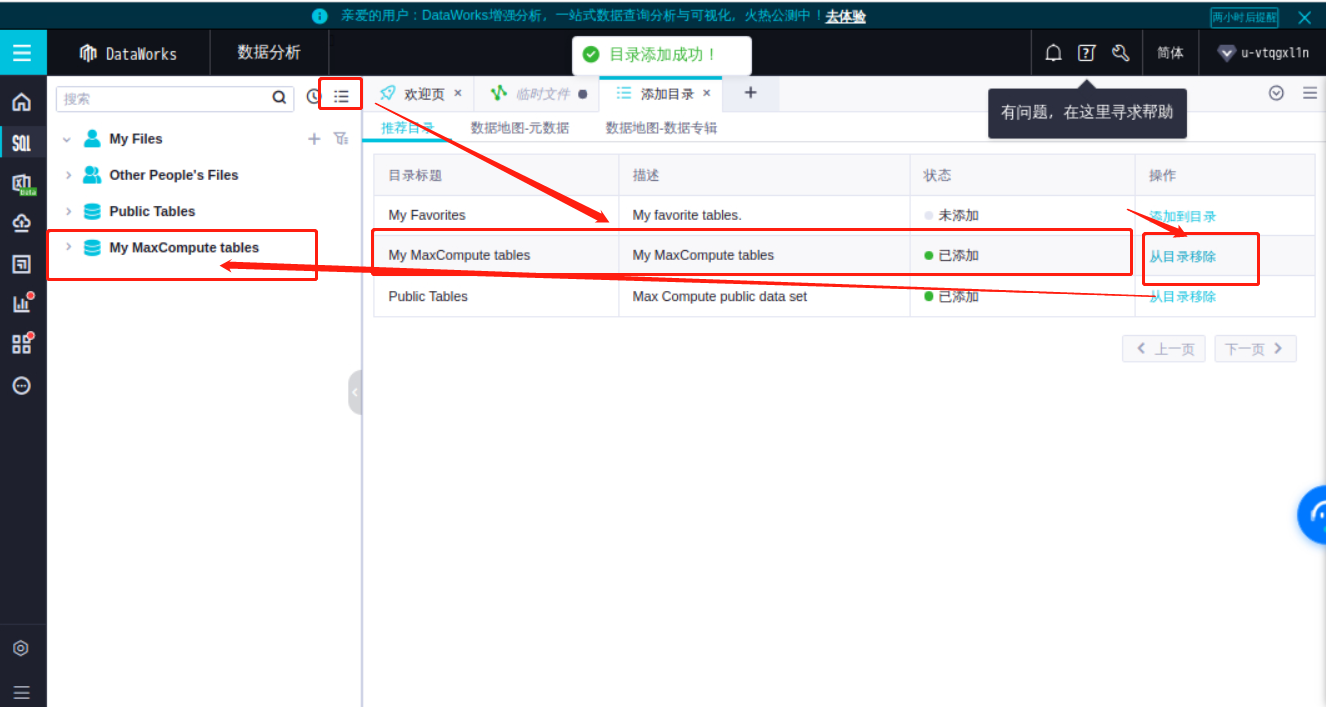
如图,在搜索框输入【test_gas】,下方出现刚才创建的数据表


在右侧出现对应的SQL查询语句。

效果如下图所示,自动生成了一个临时文件,并自动生成了刚刚创建的test_gas表的SQL语句
在查询上传的数据之前,先按照以下步骤对数据源进行授权
如下图,首先点击右上角 按钮,然后点击【数据源】下拉框,再点击【安全中心】进行页面跳转


运行效果如下图所示:

**体验客户分类的统计操作**
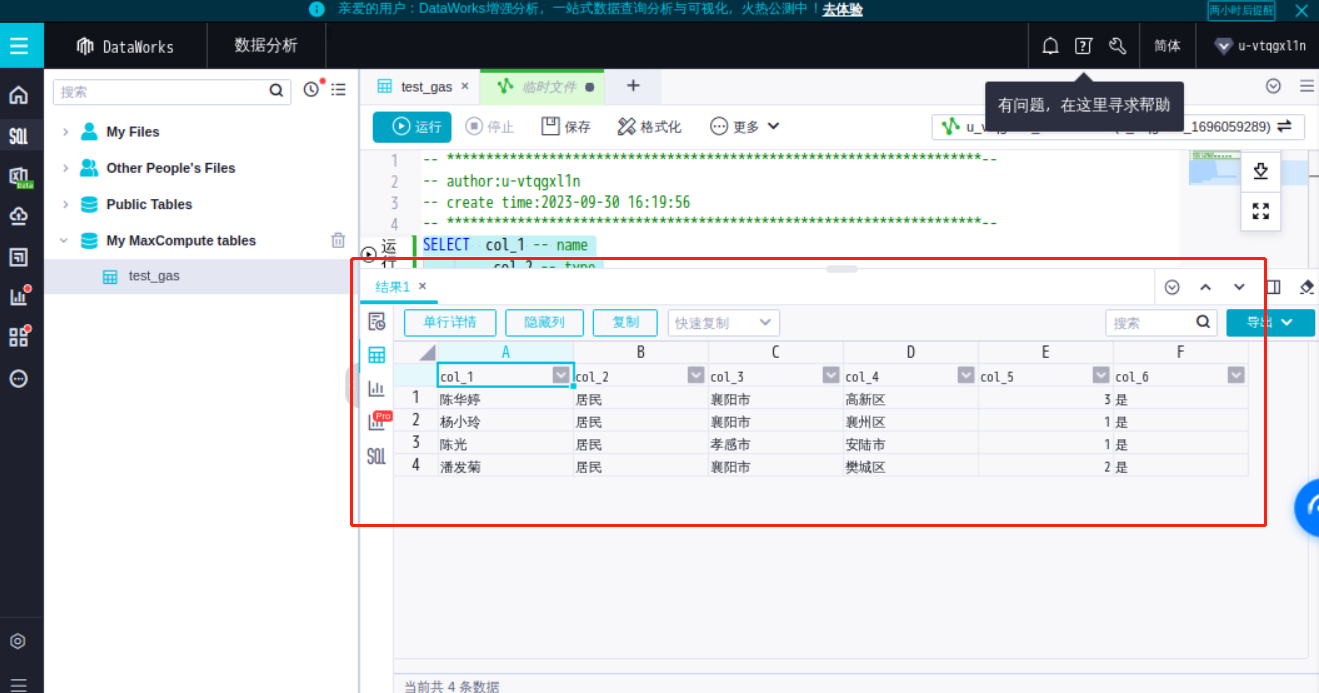
查询居民身份的客户数据
在SQL查询编辑页面,删除上一步自动生成的SQL语句,输入以下SQL语句,并如下图所示将项目名称修改过来(注意:SQL语句中的项目名称一定要与当前MaxCompute项目名称一致)
SELECT col_1 -- name
,col_2 -- type
,col_3 -- city
,col_4 -- area
,col_5 -- floor
,col_6 -- yajin
FROM u_vtqgxl1n_1696059289.test_gas
where col_2='居民'
LIMIT 200
;
//相比前一段SQL代码,增加了WHERE 客户身份 = ‘居民’WHERE 代表增加查询条件,这段SQL代码的查询条件为客户身份等于【居民】的数据
运行效果如下图所示,所有的居民客户就出现了
实验总结:
通过本次实验,学会了如何将本地数据上传到阿里云MaxCompute数仓,同时学习了如何查询,筛选我们上传的数据。















 1543
1543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









