






大模型侧工具安装部署实践
这里首先介绍的是大模型侧的工具安装部署实践,至于为什么先提大模型侧后提知识库侧呢?这是因为大模型通常是知识库操作和应用的基础与核心,是提供智能决策的引擎。它们构建了理解和生成文本、图像、语音等多模态反应的基础能力,是整个智能应用的心脏,同时,由于这次主题是本地大模型个人知识库,所以大模型的安装、配置、优化和部署是首要步骤,也是确保知识库工具能够顺畅运行的基石。
随后才转到知识库侧,是因为知识库是大模型应用的扩展和优化层,它们是模型与业务场景的桥梁。知识库如RAG集成,使得模型能精准定位和检索增强生成,通过文档、上下文理解,提高交互式问答等。知识库通过索引申明确定模型的实用性,让模型能够更贴近业务需求,提升用户体验,如MaxKB、Open WebUI等工具提供了直接上传、管理文档、集成知识,使得模型与业务系统无缝对接。因此,知识库是大模型的补充,提升模型在具体应用中发挥价值的关键,所以放在模型之后介绍。
简而言,先模型侧,后知识库,是按照技术实施的逻辑顺序,从基础架构到应用优化,确保理解模型部署到业务场景的深入,逐步构建出高效、用户友好的智能系统。
Ollama部署
Windows部署Ollama
首先,访问Ollama官网(点此到达)。
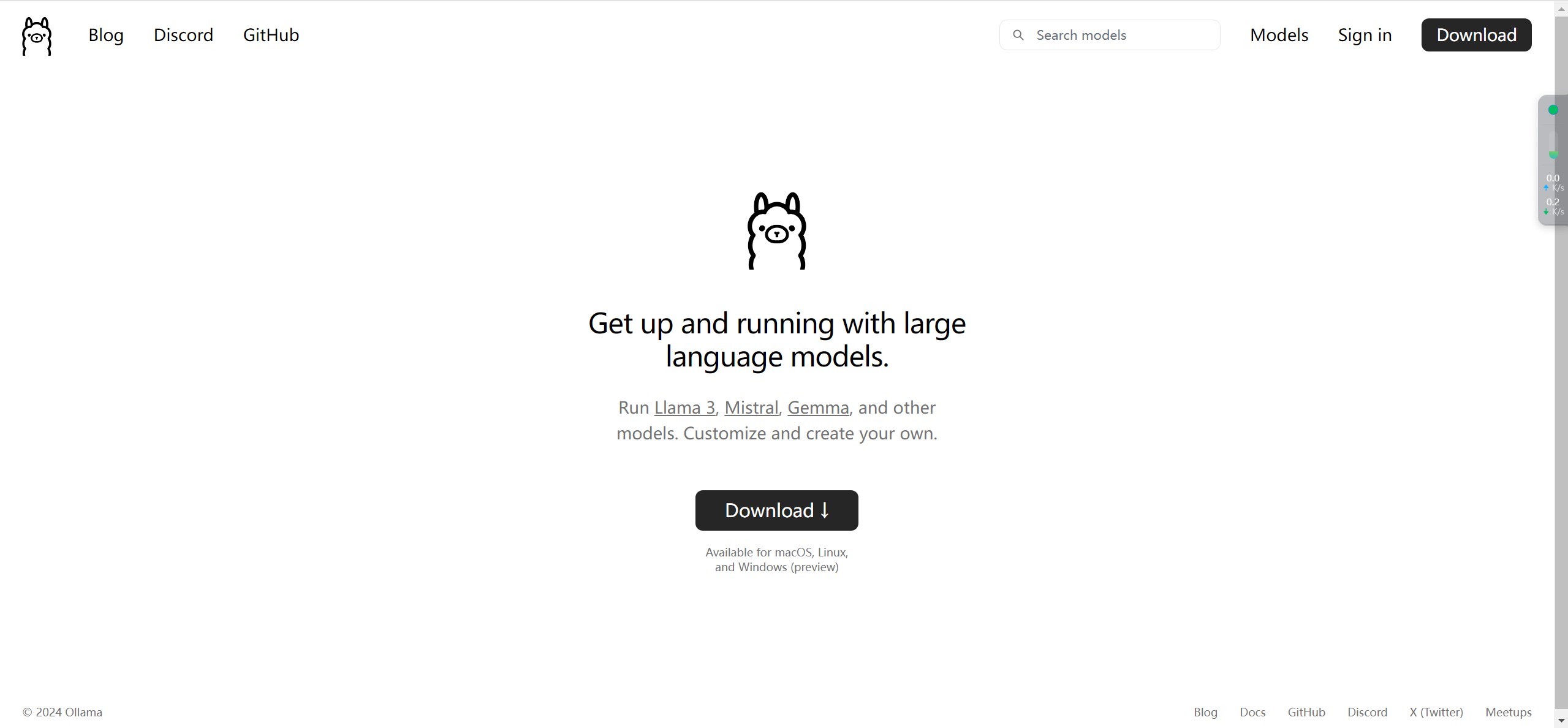
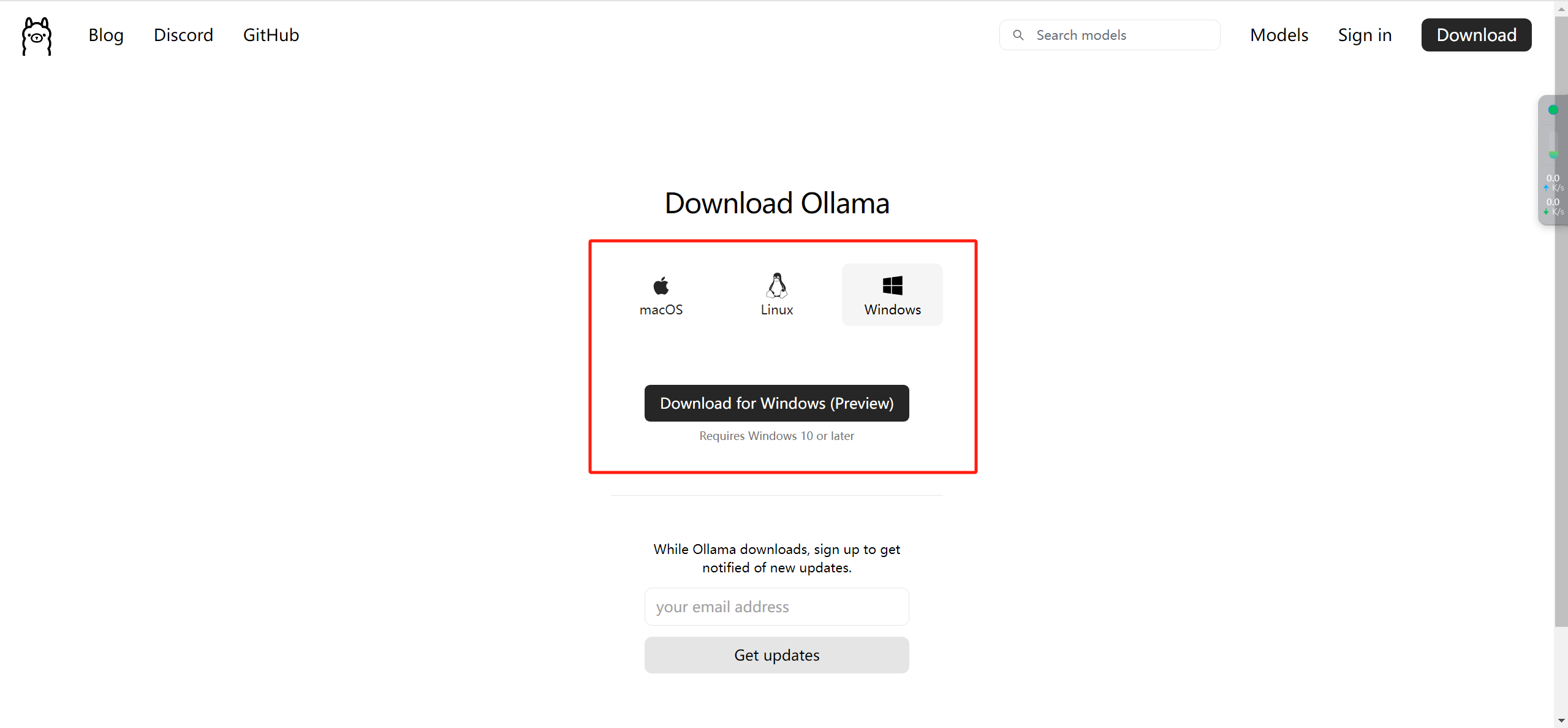
点击下载,选择适配自己电脑的版本。
Windows下载完之后电脑也没弹出快捷启动方式啥的,不知道是不是bug,我这里一般是点击缩略符进到日志目录下,再右键打开终端。
再回到Ollama官网,点击右上角的Models。
可以看到诸多模型如下:
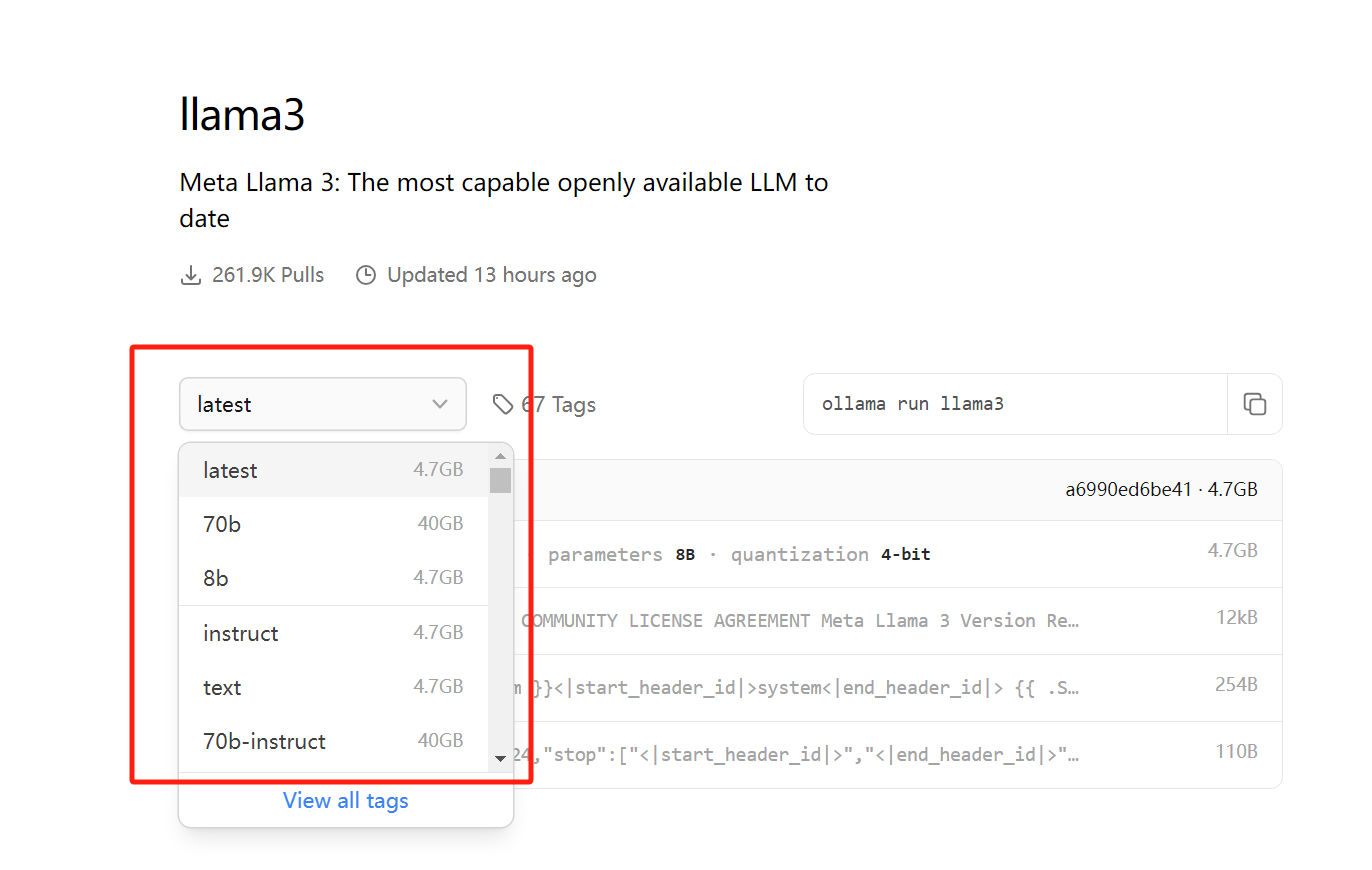
我们点击llama3,可以看到如下界面:
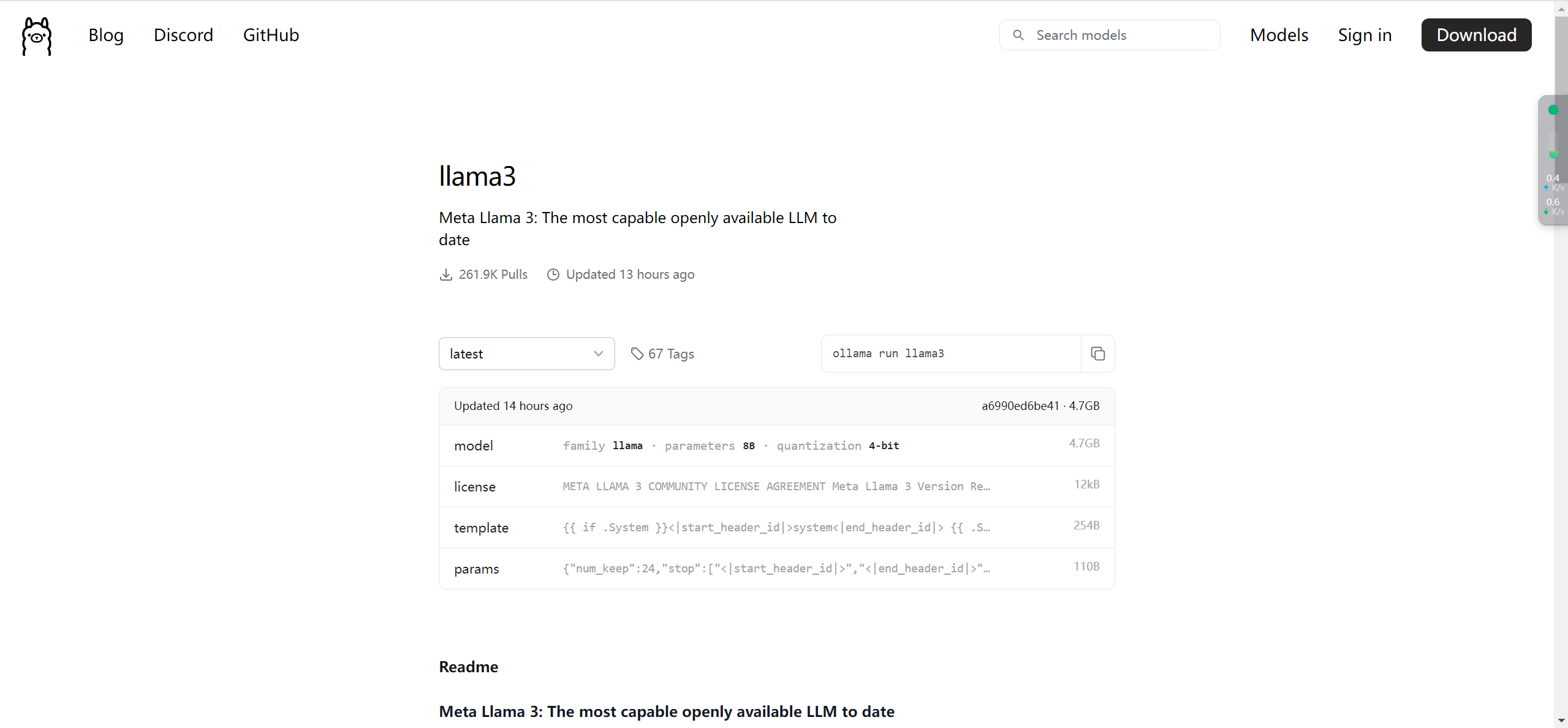
点击latest,可以选择模型的类型,笔记本运行建议8b,服务器可以选择70b(作者笔记本显卡为RTX4070)。
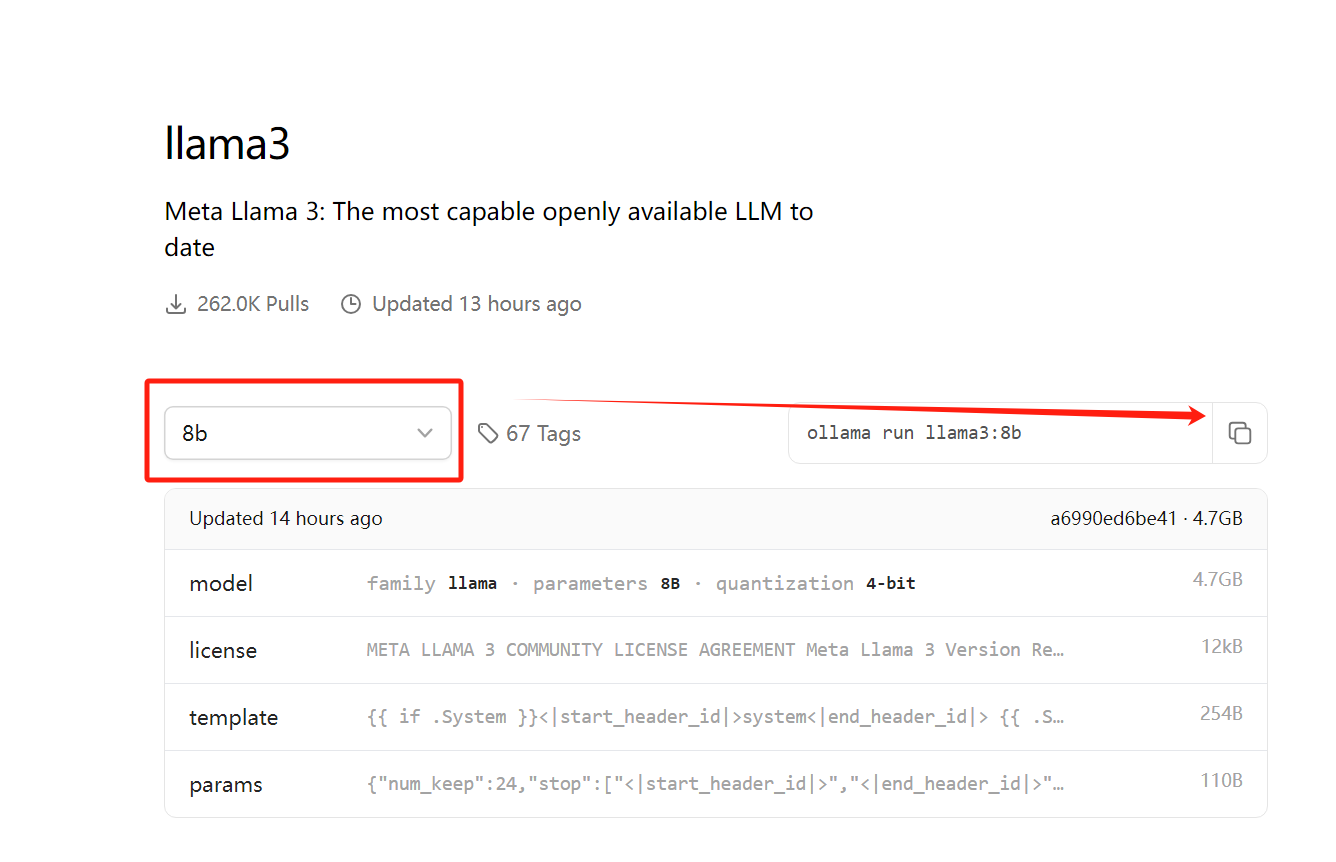
点击复制按钮,粘贴命令行到终端框,执行即可。
ollama run llama3:8b
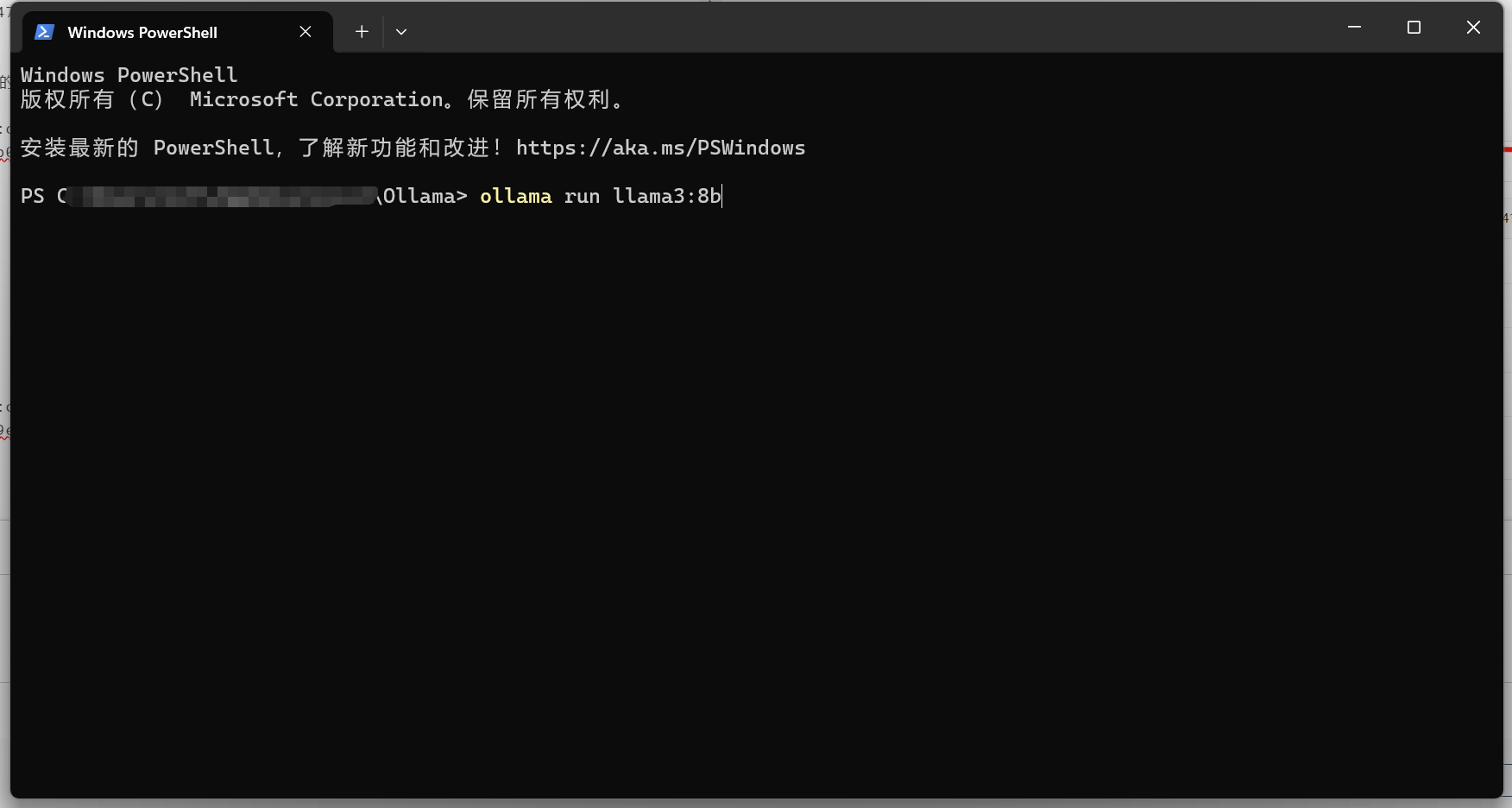
安装好后如下所示:


当然,在Windows环境下其实也可以采用docker来部署Ollama,但是我这里并未提及,一点是因为配置过程稍微麻烦,第二是因为在windows中部署docker会对电脑性能有一定的折损,有Linux操作基础的小伙伴没有必要进行该尝试,直接看下面的Linux部署部分内容就可以了。
Linux部署Ollama
在Linux环境下,部署Ollama也仅仅只需一条命令。前期基础虚拟机搭建可以参看我以前的文章,Linux虚拟机安装操作。
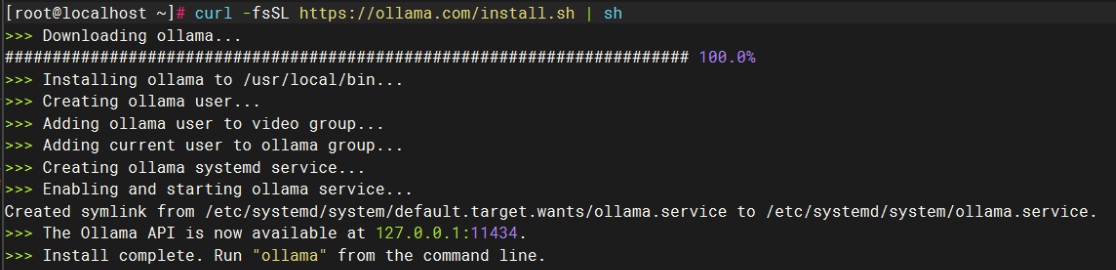
进入虚拟机后,打开命令行,输入
curl -fsSL https://ollama.com/install.sh | sh
此时会提示需要更新包。

执行如下命令更新包:
sudo apt install curl
更新完毕后再次执行,开始部署并启动Ollama:
在这个过程中,极有可能出现超时的情况,需要修改hosts文件,直接将** http://github.com** 做个ip指向,进入如下编辑页面:
sudo vim /etc/hosts
进入后,增加如下配置:
# github 注意下面的IP地址和域名之间有一个空格
140.82.114.3 github.com
199.232.69.194 github.global.ssl.fastly.net
185.199.108.153 assets-cdn.github.com
185.199.109.153 assets-cdn.github.com
185.199.110.153 assets-cdn.github.com
185.199.111.153 assets-cdn.github.com
再次尝试,就不会直接出现超时的情况了,但是由于是国内环境,速度依然不是很理想。
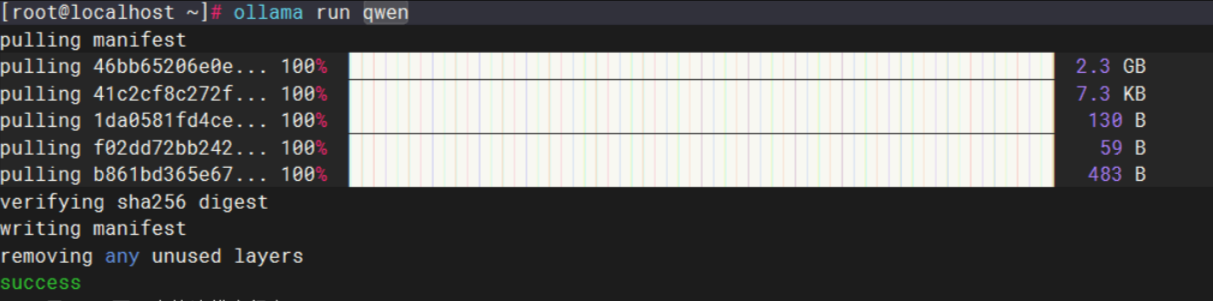
在Ollama安装完成后, 一般会自动启动 Ollama 服务,而且会自动设置为开机自启动,然后这里我直接运行一个千问模型,可以看到运行成功。
除了直接部署之外,也支持采用docker的方式来部署,作者这里也推荐使用这种方式。
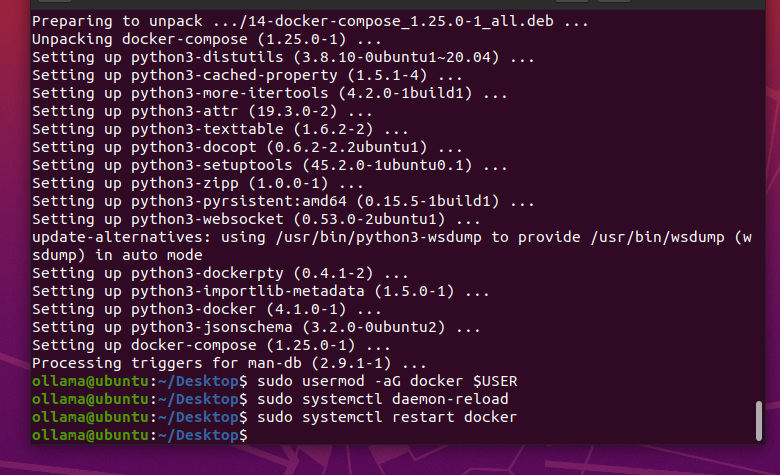
首先是安装 docker 和 docker-compose
sudo apt install docker.io
sudo apt-get install docker-compose
sudo usermod -aG docker $USER
sudo systemctl daemon-reload
sudo systemctl restart docker
然后配置国内 docker 镜像源,修改/etc/docker/daemon.json,增加以下配置:
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com"
]
}
配置好以后重启docker。
sudo systemctl daemon-reload
sudo systemctl restart docker
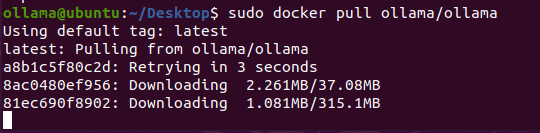
拉取镜像
docker pull ollama/ollama
在docker下,也有几种不同的启动模式(对应路径请按照实际情况更改):
CPU模式
docker run -d -v /opt/ai/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
GPU模式(需要有NVIDIA显卡支持)
docker run --gpus all -d -v /data/ai/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
docker部署ollama web ui
docker run -d -p 8080:8080 --add-host=host.docker.internal:host-gateway --name ollama-webui --restart always ghcr.io/ollama-webui/ollama-webui:main
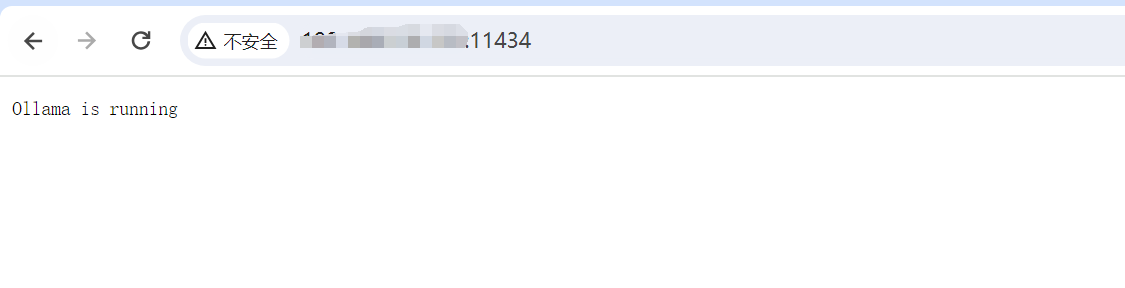
比如我采用CPU模式启动:

在浏览器中可以通过 服务器IP:11434 来进行访问查看 , 如下所示则是正常启动 。
然后运行模型:
docker exec -it ollama ollama run llama3

安装完成后正常体验即可,如果觉得命令行不好看,也可以尝试上面的Web-UI部署。
Ollama使用技巧
模型更换存储路径
在windows系统中下载时,很不科学的一点就是默认使用C盘来存放模型文件,本来C盘就不够用,这一下载模型少说七八个GB就没了。但是莫慌,我们可以通过修改环境变量来设置指定模型的目录位置。
【电脑】——>右键【属性】——>【高级系统设置】——>【高级】——>【环境变量】
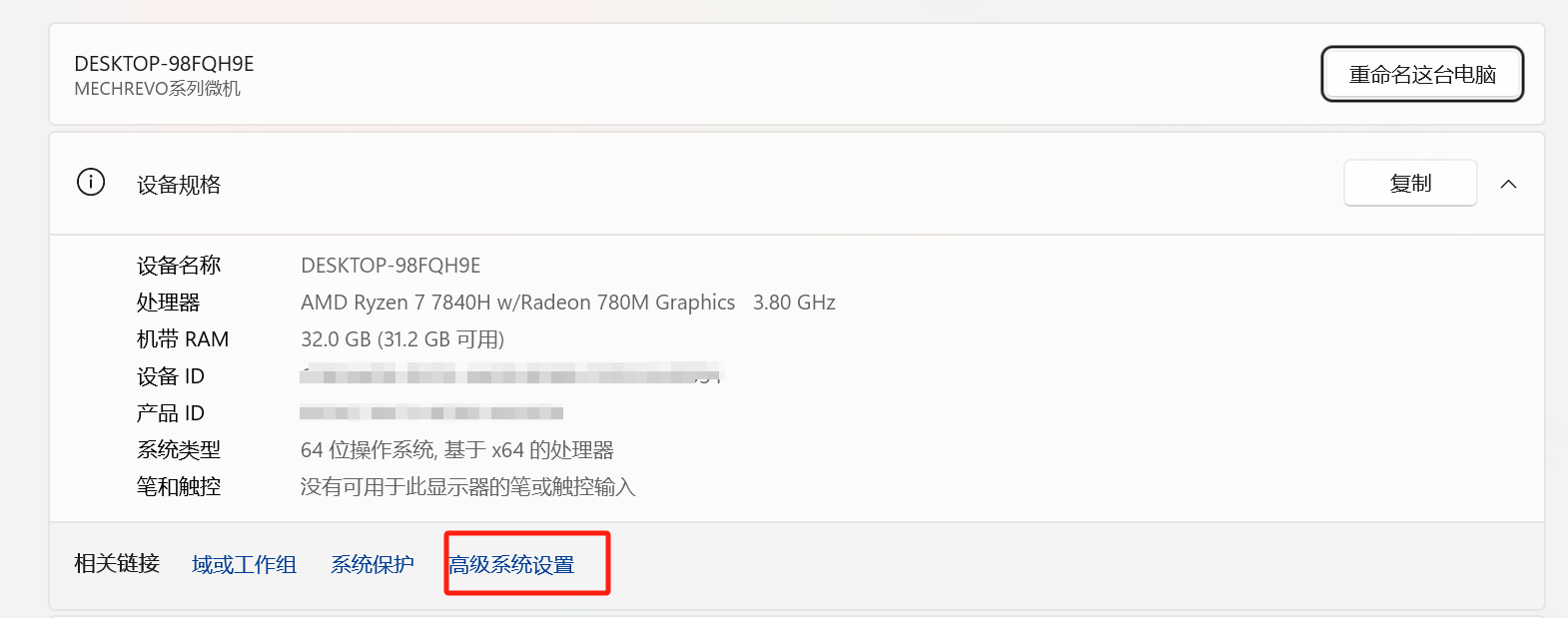
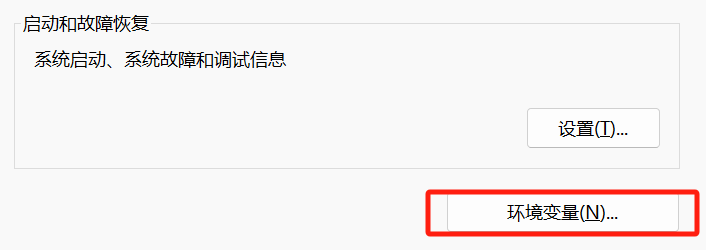
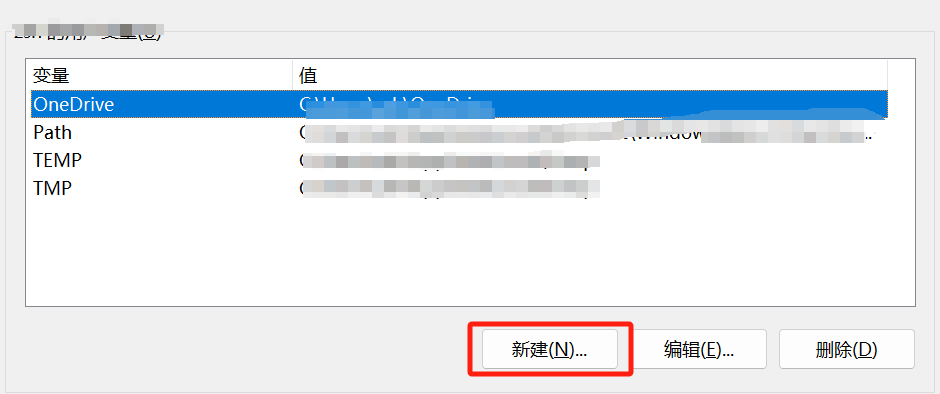
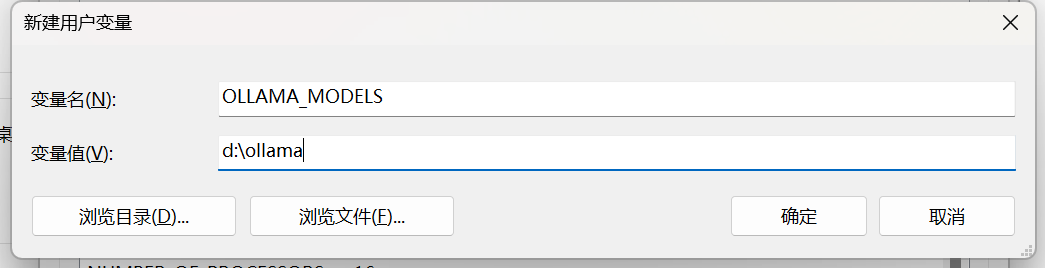
我们通过设置环境变量(OLLAMA_MODELS)来指定模型目录,可以通过系统设置里来配置环境变量(系统变量或者用户变量)
而在Linux系统中,默认地址是~/.ollama/models, 如果想移到别的目录,同样也是设置环境变量OLLAMA_MODELS:
export OLLAMA_MODELS=/data/ollama
导出某个模型
这里以 llama3:8b为例,先查看模型信息:
ollama show --modelfile llama3:8b
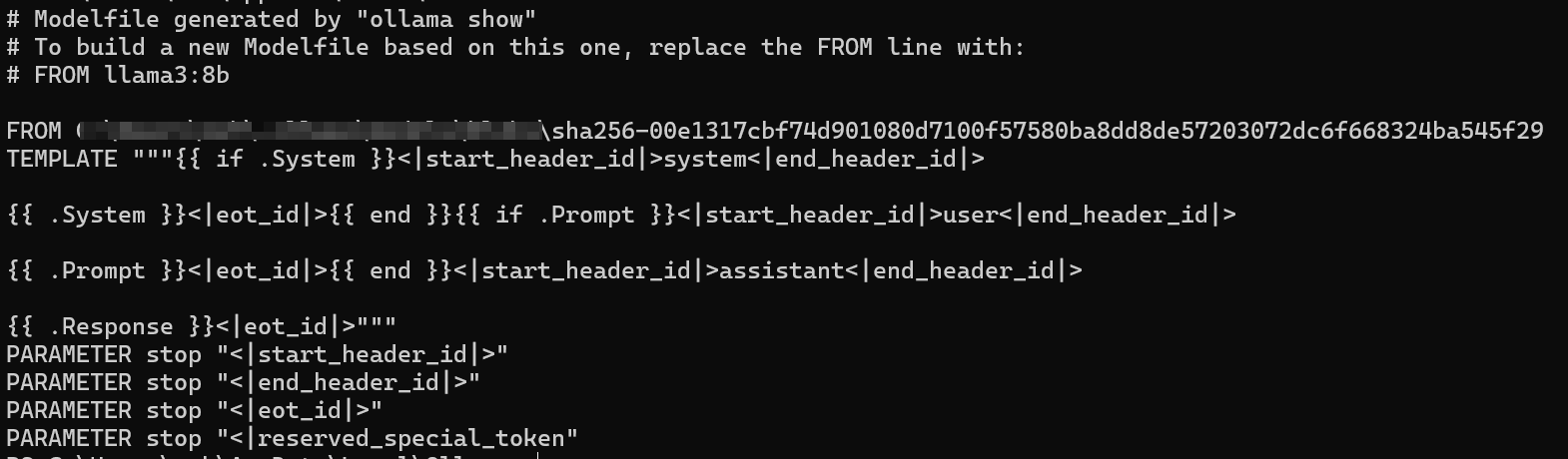
从模型文件信息里得知 /xxx/xxx/xxx/xxx/xxx/sha256-00e1317cbf74d901080d7100f57580ba8dd8de57203072dc6f668324ba545f29 即为我们想要的llama3:8b (格式为gguf),导出代码如下:
Linux系统中
cp /xxx/xxx/xxx/xxx/xxx/sha256-00e1317cbf74d901080d7100f57580ba8dd8de57203072dc6f668324ba545f29
Windows系统中
copy /xxx/xxx/xxx/xxx/xxx/sha256-00e1317cbf74d901080d7100f57580ba8dd8de57203072dc6f668324ba545f29
导入某个模型
比如我们选择个链接 https://hf-mirror.com/brittlewis12/Octopus-v2-GGUF/tree/main 下载octopus-v2.Q8_0.gguf
准备Modelfile文件
From /path/to/qwen_7b.gguf
是最简单的办法 当然可以从上面模型信息生成完成版本的Modelfile
# Modelfile generated by "ollama show"
# To build a new Modelfile based on this one, replace the FROM line with:
# FROM qwen:7b
FROM /path/to/qwen_7b.gguf
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>{{ end }}<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""
PARAMETER stop "<|im_start|>"
PARAMETER stop "\"<|im_end|>\""
记得替换你的模型的完整路径 另外不同模型的template 和 stop parameter不同,这个不知道就不写,或者网上搜索 然后执行:
ollama create qwen:7b -f Modelfile
导入模型的时候,至少确保硬盘可用空间在模型大小的2倍以上。
小结
通过以上实际部署及使用操作体验情况来看,我只能说无怪Ollama最近爆火,它是真正击中了众多开发者的心(包括我),轻松点击几下鼠标就可以完成本地模型的部署,这种“即插即用”的模式,彻底改变了以往需要深厚技术背景才能涉足的大型语言模型应用领域,让更多创意和项目得以孵化。除此之外,它也提供了丰富的模型选择,Ollama里支持的模型库达到了92种,涵盖了从基础研究到行业应用的广泛需求,甚至最新的qwen2也在其中。
而在使用上,Ollama虽然没有直接提供可视化一键拉取模型的方式,但是由于其命令简明,手册清晰,所以我觉得这点也是可以接受的。
总的来概括一下,Ollama确确实实是一个部署模型便捷、模型资源丰富、可扩展性强的大模型侧的工具,截止至2024年6月8日,我仍然认为它是部署本地大模型的不二之选。
LM Studio部署
Windows部署LM Studio
进入LM Studio官网,需要加载一分钟左右,点击【Download LM Studio for Windows】:
这个下载速度属实给我干沉默了:
好不容易下载完了,这边我也给出百度云的资源,避免小伙伴们走弯路:
链接:https://pan.baidu.com/s/1UZvxkmHuCSWBpnQ2EYje0A
提取码:nigo

点击可以直接启动,界面如下:
-
Home:主屏幕区,后面推荐各类大模型
-
Search:搜索下载各类大模型。
-
AI Chat:模型对话区
-
Multi Model:多模型对话,显存要大24G+。
-
Local Server:创建web服务
-
My Models:已下载模型和文档设置
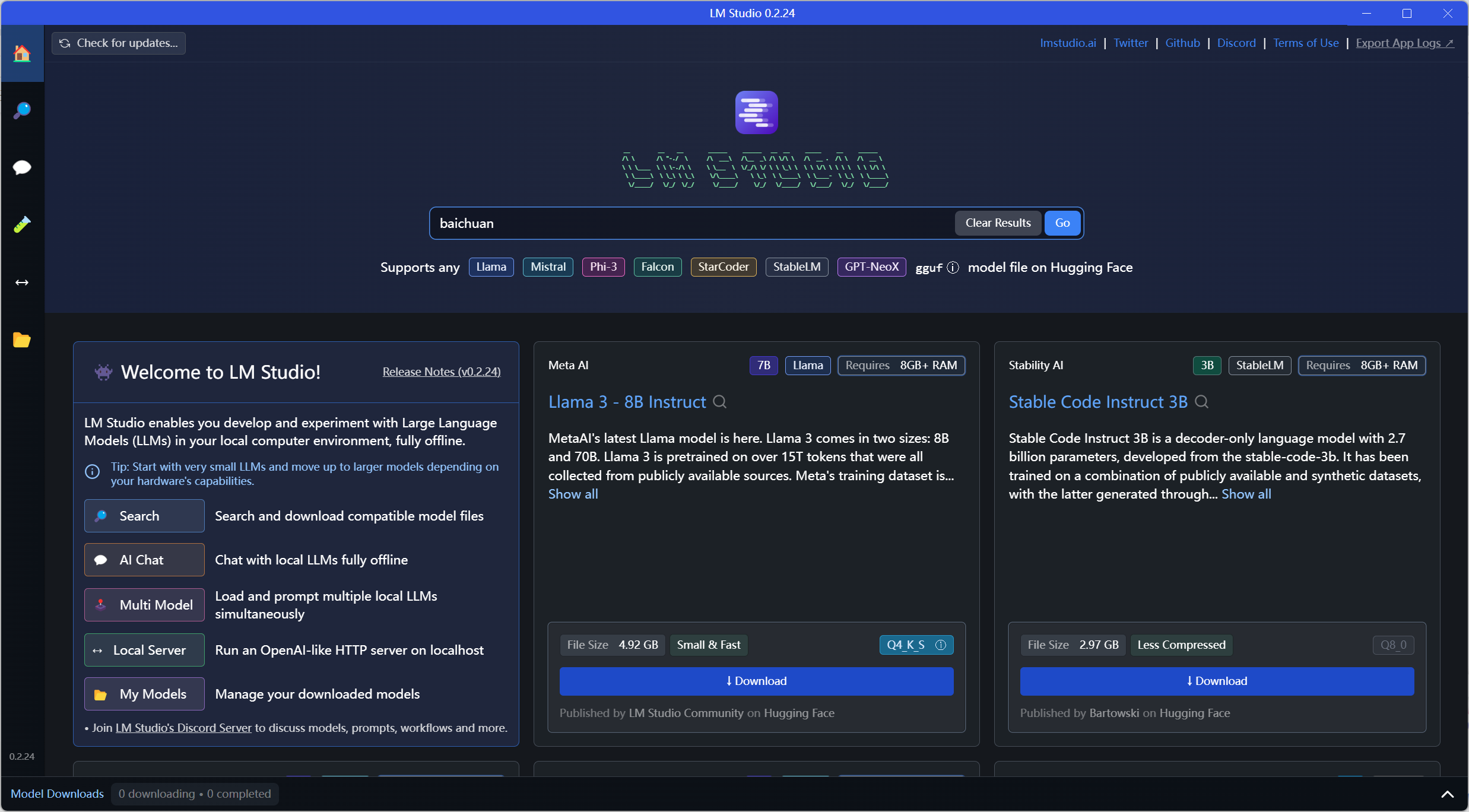
先来到文件夹这里,把模型的下载路径换到D盘下面:
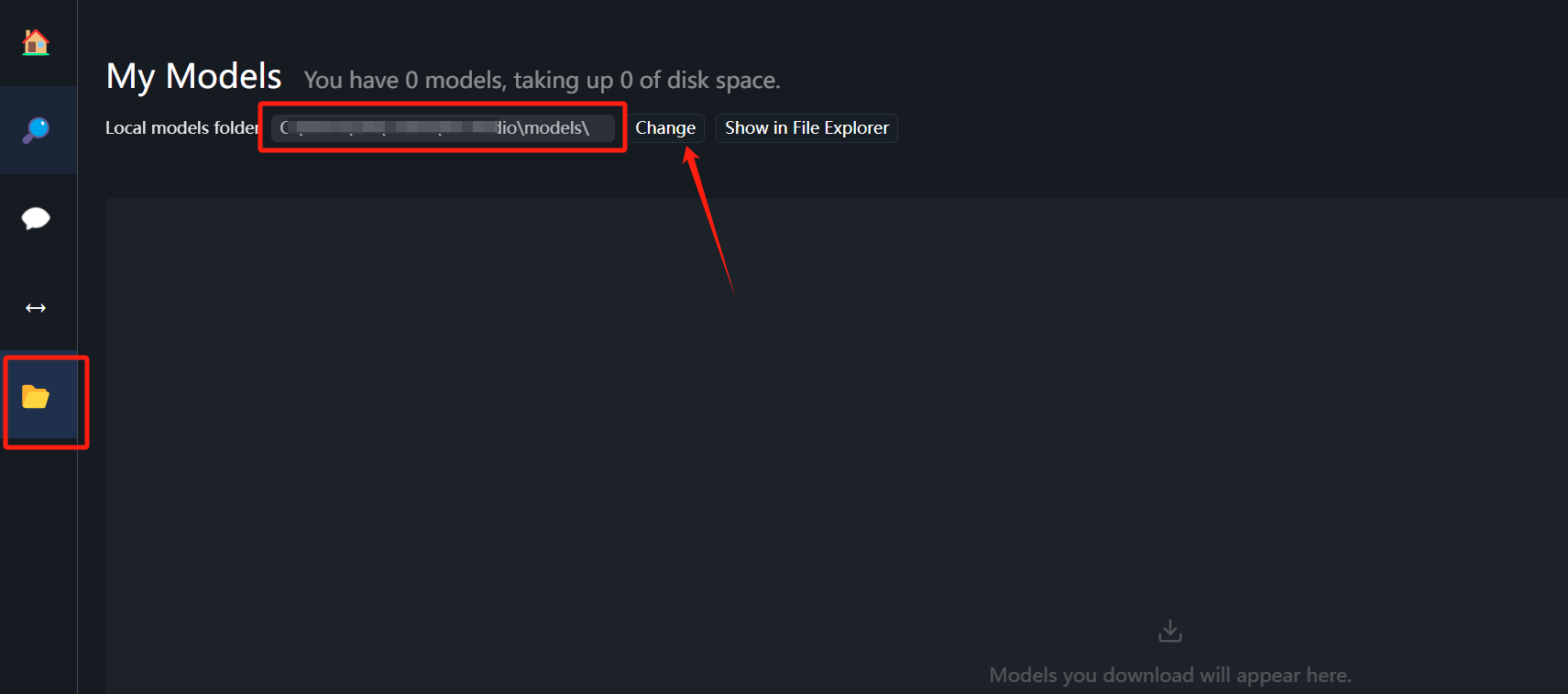
这里必须在D盘下创建该目录结构:
D:\models\Publisher\Repository
但在点击 Change 时,自定义路径选择到 /models 层即可。

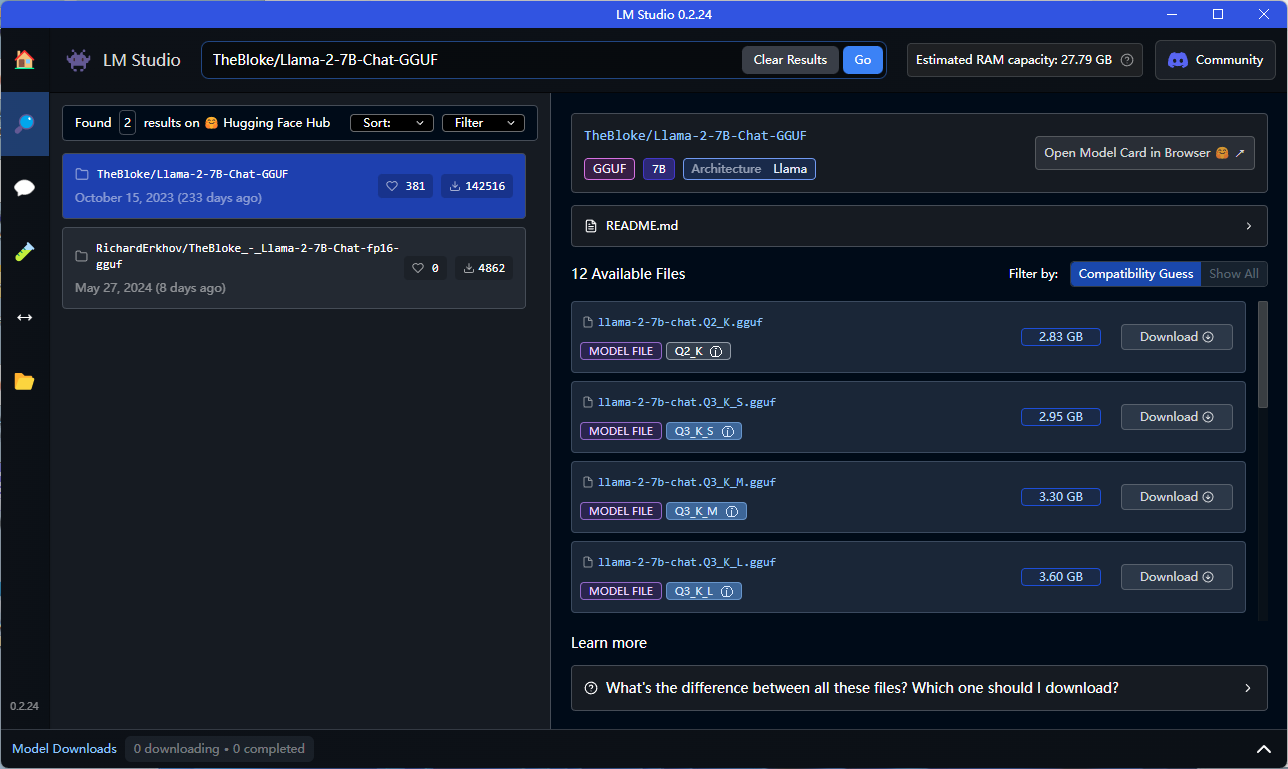
在主界面中直接下拉,可浏览各种大语言模型,选择download 按钮可直接下载,但是部分模型可能需要科学上网才能下载:
同时,在搜索栏中也可以直接搜索想要下载的模型:
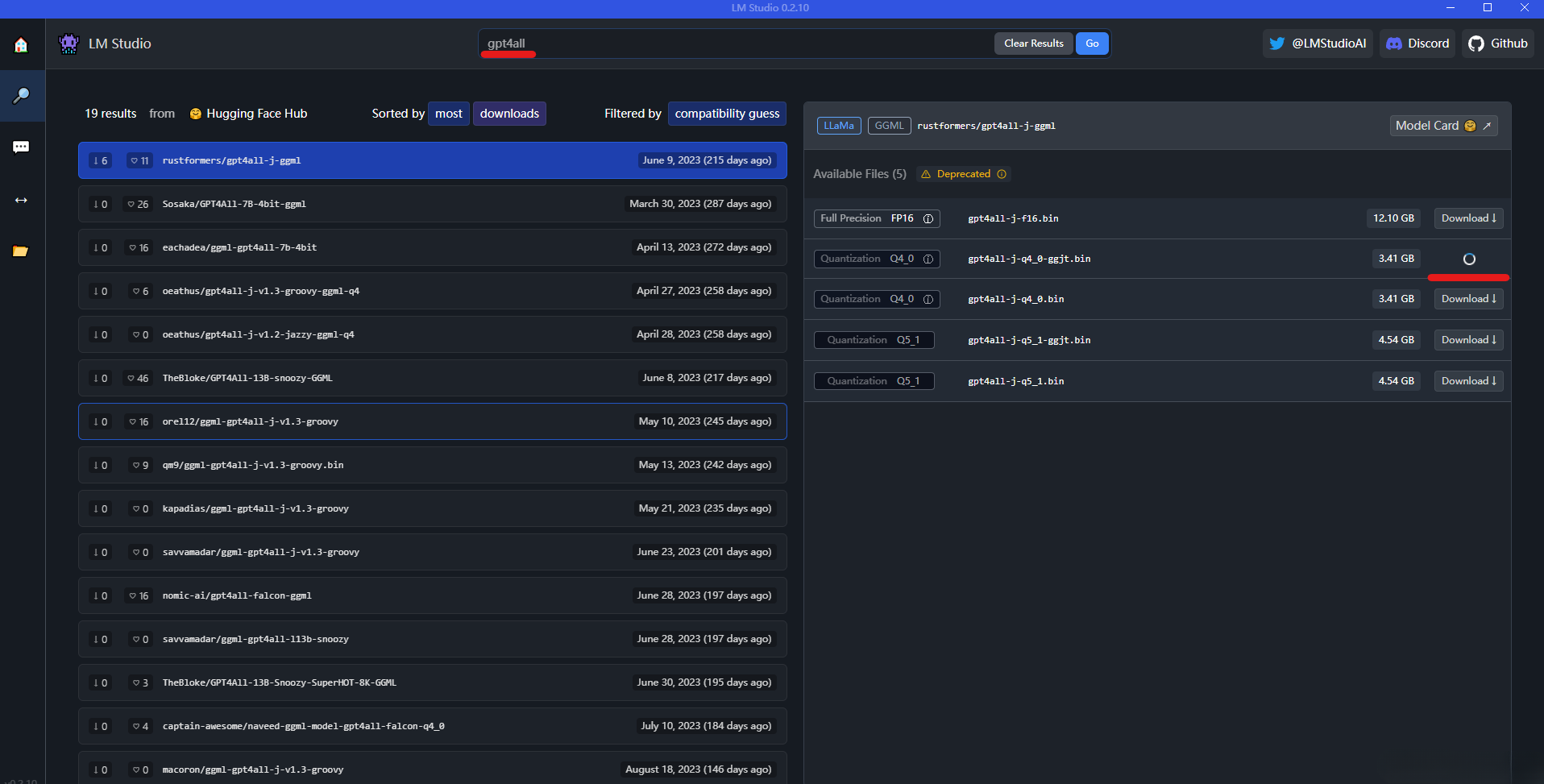
当模型下载完后,可以在左边菜单栏选择chat图标,然后选择模型(下载之后的模型会在下拉列表中),如下图:
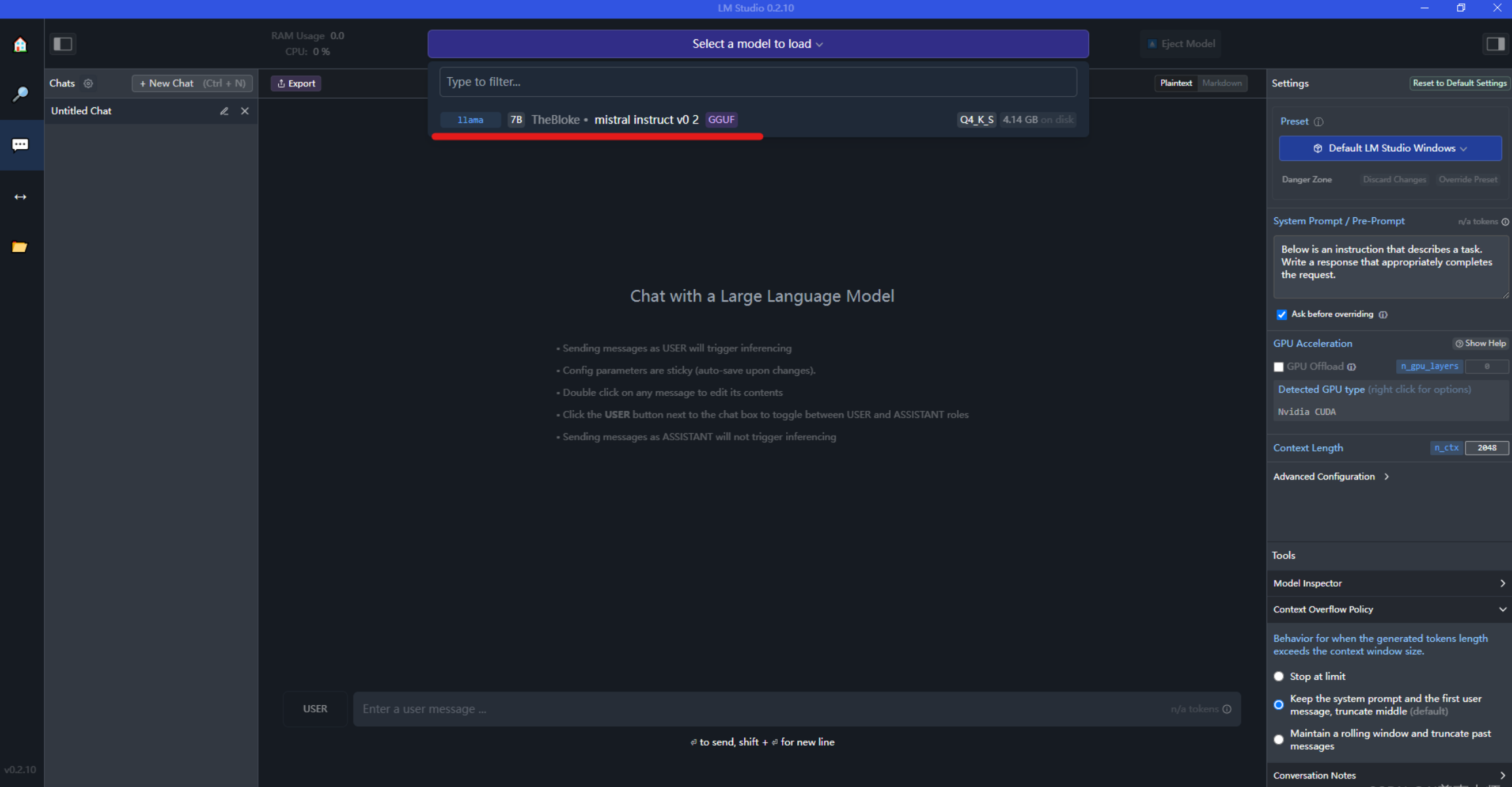
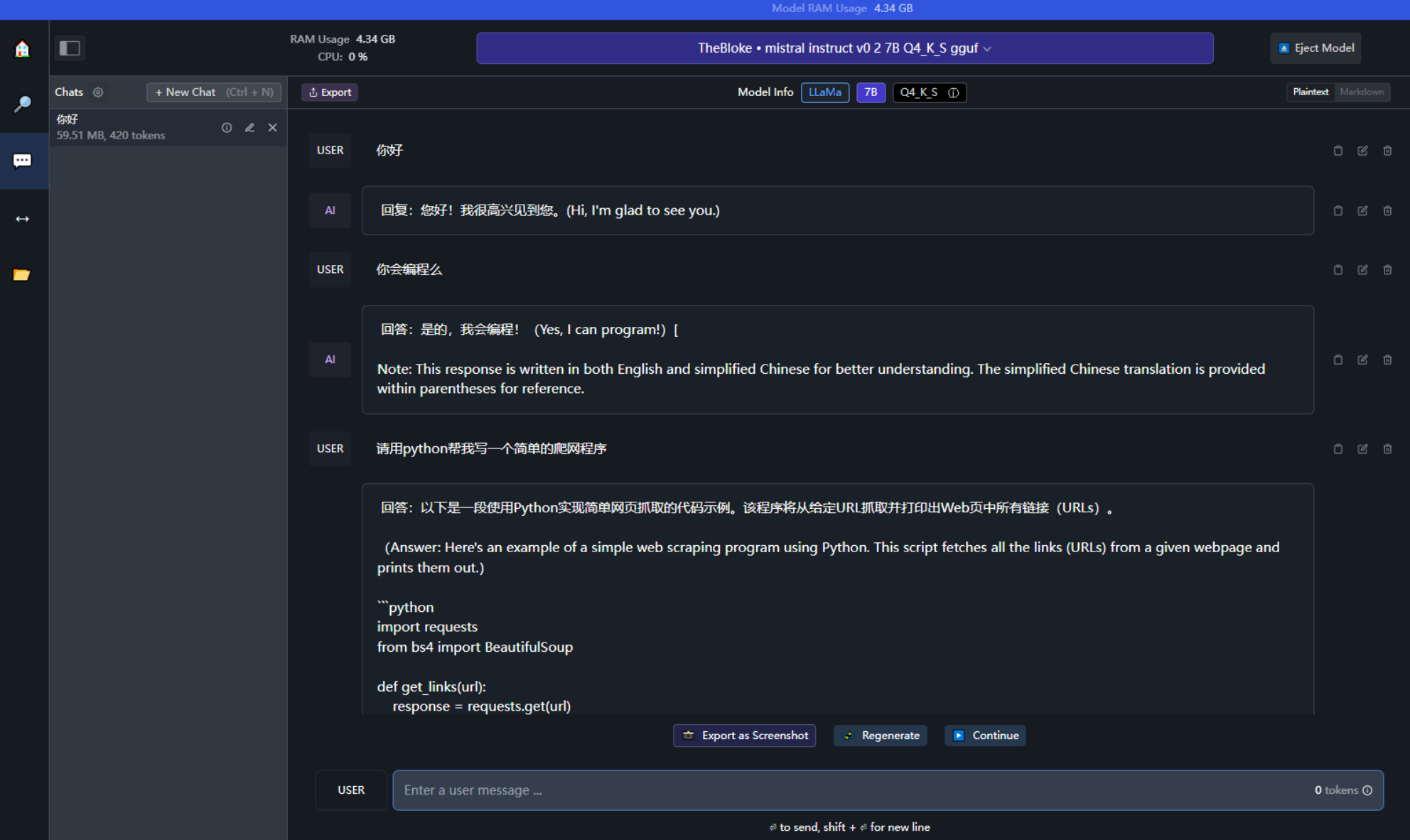
直接输入你想要提问的问题,和模型进行对话
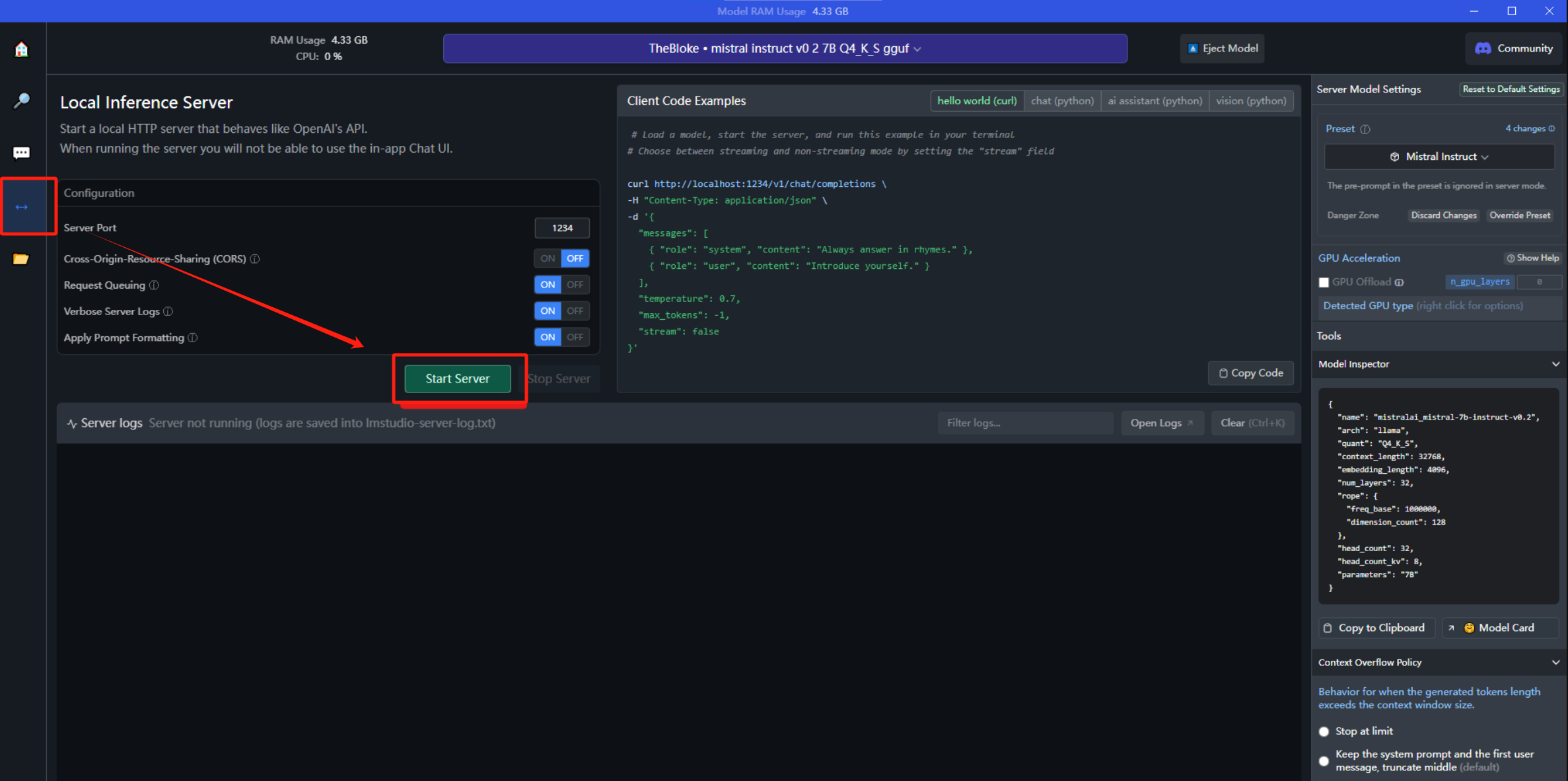
当然,LM 同样也支持在本地以Server的形式提供API接口服务,这意味着可以把大语言模型做为一个后端服务来进行调用,前端可以包装任意面向业务的功能。
Linux部署LM Studio
进入LM Studio官网,点击【Download LM Studio for Linux】,不过这里似乎只支持Beta版本的,查了一下文档,只适配Linux (x86, Ubuntu 22.04, AVX2),其他Linux系统可能会出现兼容性问题:
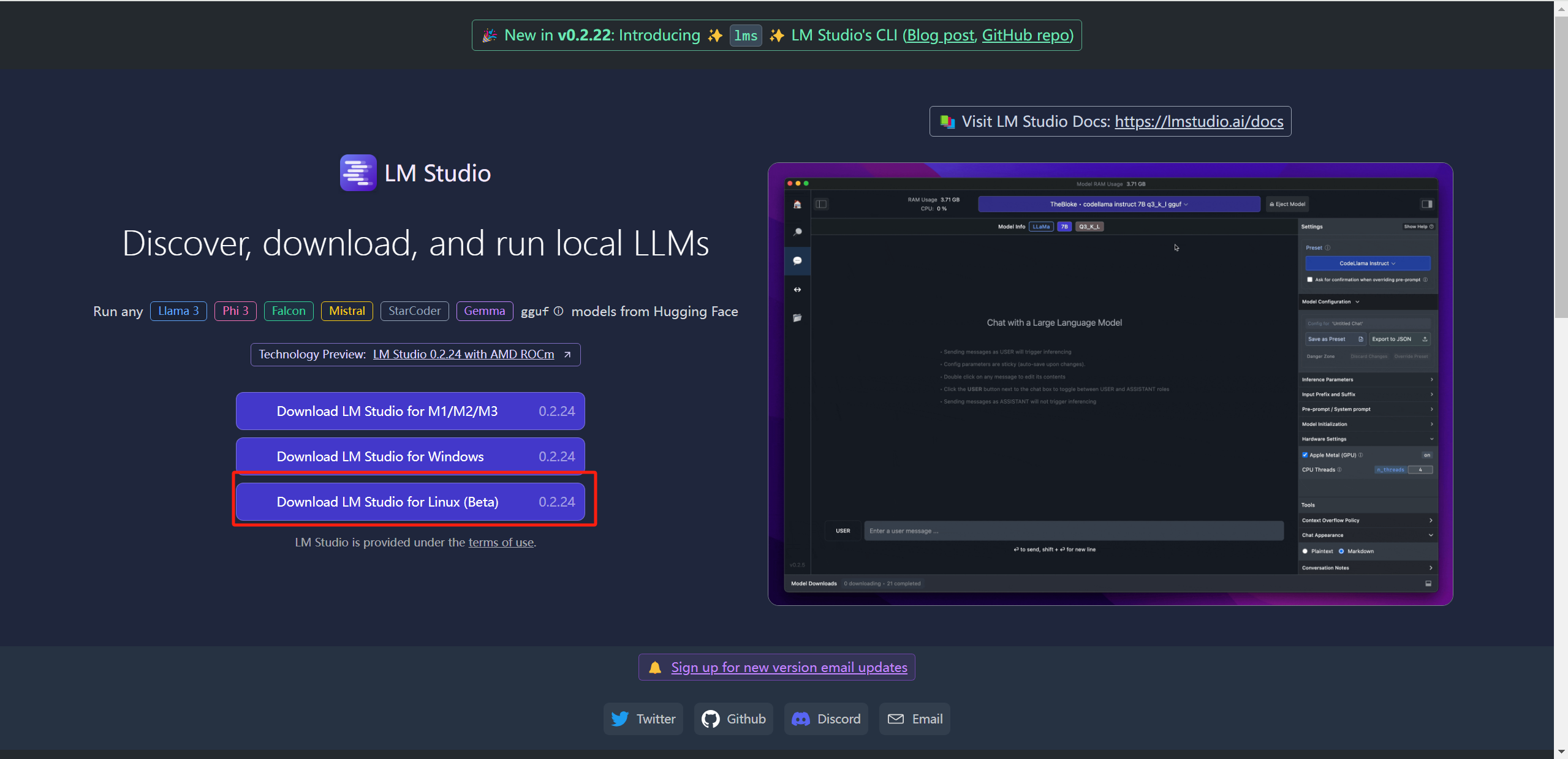
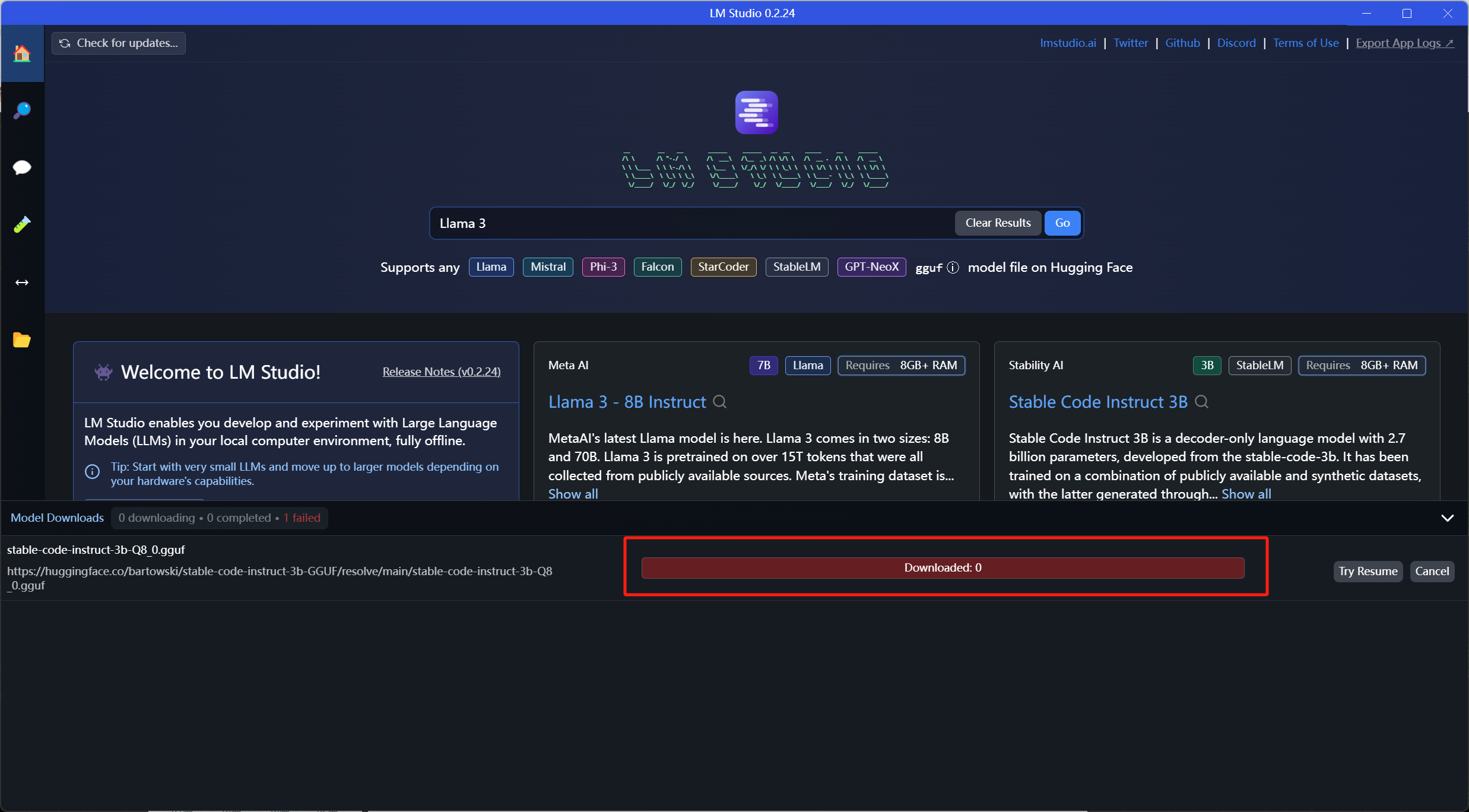
又是漫长的等待。。。结果下了一多个小时还是没有下完。。。中途还提示一次Failed,晕。。
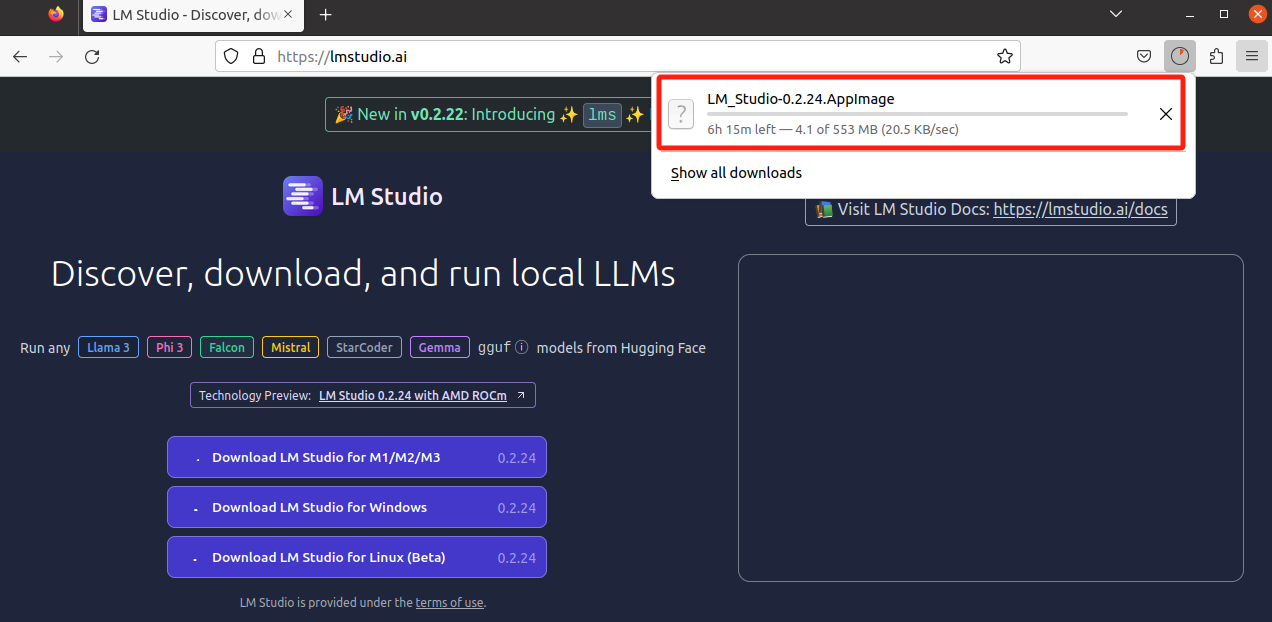
本来还是想秉持着探索精神去尝试的,但是无奈真的被科学上网劝退了,至于Linux下的安装和启动方式,在Ubuntu里也是可以通过可视化的方式去操作的,所以与上述Windows差别不大,这里暂且略过吧,如有兴趣的小伙伴可以挂梯子去尝试下载安装部署。
LM Studio本地大模型下载设置
通过上述实践我们也可以看到,不管是LM Studio工具本身的下载还是内置大模型的下载,其实都是需要翻墙的,没有办法在日常网络环境中直接快速使用,但是,我们仍然可以通过其他的方式来下载大模型并导入到LM Studio中使用。
下面提供两种方案:
-
从国内的模型站下载,魔塔社区:ModelScope魔搭社区 。
-
使用VScode修改 huggingface.co链接替换为国内镜像 hf-mirror.com就可以查找下载大模型镜像。
从魔塔社区下载
进入魔塔社区:ModelScope魔搭社区。
模型下载好之后,复制到目录所在位置即可在下方识别出来:
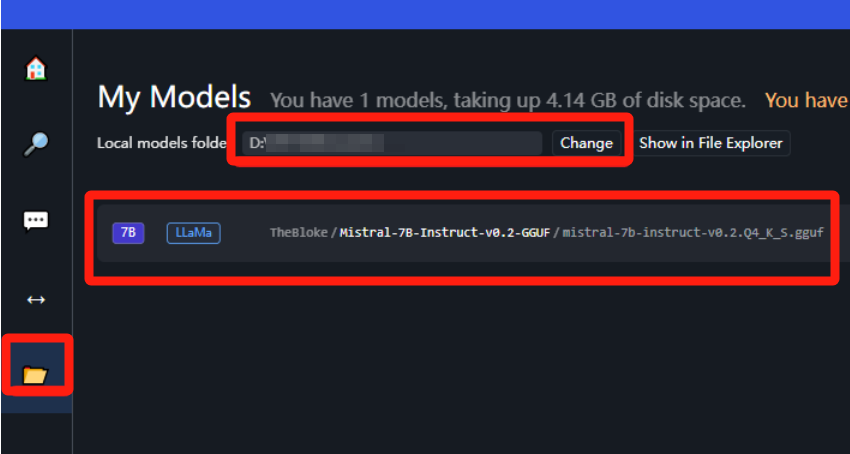
修改js文件中的默认下载路径
进入目录,如下所示:
右键app-0.2.23,使用VS Code打开,然后把里面的huggingface.co链接替换为hf-mirror.com:
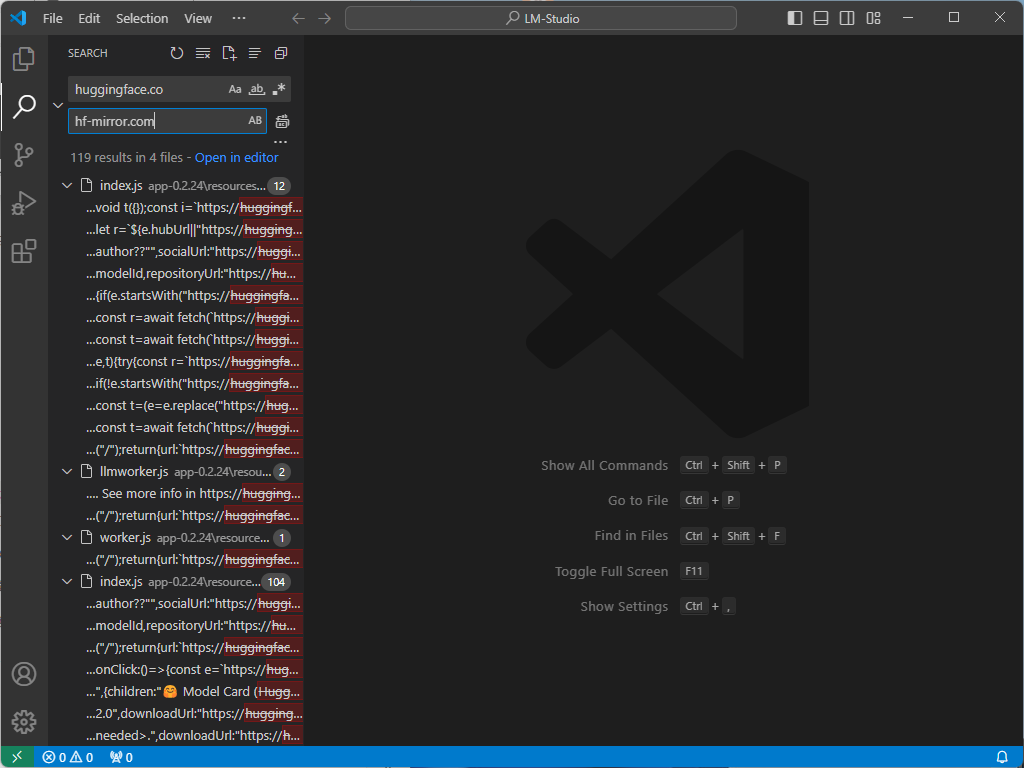
再次重启LM Studio,就可以搜索下载LLM大模型了。

小结
如果从工具本身的能力出发,我认为这款工具是强于Ollama的。首先说一下模型数量,LM Studio内部模型下载的主要来源是Hugging Face Hub,模型数量非常多,即便是对比Ollama的话整体数量也是偏多的。
第二点就是我个人非常喜欢的可视化界面以及模型对话时的负载设置。
相比于Ollama,LM Studio提供了更直观易用的界面,点击下载按钮即可一键进行模型的安装部署。
同时在模型负载设置这一块,LM Studio也做的更好,比如:正常来说默认是计算机的CPU完成所有工作,但如果安装了GPU,将在这里看到它。如果GPU显存不够,就可以将GPU想要处理多少层(从10-20开始)进行设置,然后这一部分层就会使用GPU处理了,这与llama.cpp的参数是一样的。还可以选择增加LLM使用的CPU线程数。默认值是4。这个也是需要根据本地计算机进行设置。
唯一美中不足的,就是需要科学上网才能下载该工具和工具内模型,不过通过上述换源的方式,这一问题也算得以解决。
整体对比,LM Studio和Ollama是各有千秋:
-
从功能丰富度和性能优化的角度综合评估,LM Studio明显更胜一筹。
-
从工具本身使用及模型部署效率来看,Ollama的上手速度会更快,使用会更便捷,效率也会更高。
所以我这里也斗胆得出如下结论:
-
LM Studio更适合那些寻求快速原型设计、多样化实验以及需要高效模型管理的开发者和研究人员。
-
Ollama更适合那些偏好轻量级解决方案、重视快速启动和执行效率的用户,适合小型项目或对环境要求不复杂的应用场景。
Xinference
Xinference 支持两种方式的安装,一种是使用 Docker 镜像安装,另外一种是直接本地源码进行安装。个人建议,如果在windows环境中最好采用源码安装,Linux环境中可以采用Docker来安装。
Windows 安装 Xinference
首先我们需要准备一个 3.9 以上的 Python 环境运行来 Xinference,建议先根据 conda 官网文档安装 conda。 然后使用以下命令来创建 3.11 的 Python 环境:
conda create --name xinference python=3.10
conda activate xinference
安装 pytorch
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
安装 llama_cpp_python
pip install https://github.com/abetlen/llama-cpp-python/releases/download/v0.2.55/llama_cpp_python-0.2.55-cp310-cp310-win_amd64.whl
安装 chatglm-cpp
pip install https://github.com/li-plus/chatglm.cpp/releases/download/v0.3.1/chatglm_cpp-0.3.1-cp310-cp310-win_amd64.whl
安装 Xinference
pip install "xinference[all]"
如有需要,也可以安装 Transformers 和 vLLM 作为 Xinference 的推理引擎后端(可选):
pip install "xinference[transformers]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "xinference[vllm]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "xinference[transformers,vllm]" # 同时安装
#或者一次安装所有的推理后端引擎
pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simple
设置 model 路径
在电脑上设置环境变量,路径请根据各自环境修改。
XINFERENCE_HOME=D:\XinferenceCache
不过同样,这里也面临着科学上网的问题,Xinference 模型下载缺省是从Huggingface官方网站下载 https://huggingface.co/models 。在国内因为网络原因,可以通过下面的环境变量设计为其它镜像网站:
HF_ENDPOINT=https://hf-mirror.com.
或者直接设置为:ModelScope:
通过环境变量"XINFERENCE_MODEL_SRC"设置。
XINFERENCE_MODEL_SRC=modelscope.
另外,可以通过环境变量XINFERENCE_HOME设置运行时缓存文件主目录。
export HF_ENDPOINT=https://hf-mirror.com
export XINFERENCE_MODEL_SRC=modelscope
export XINFERENCE_HOME=/jppeng/app/xinference
可以设置环境变量,临时启作用,或者设置在用户环境变量中,登陆即自动生效。
启动 Xinference
xinference-local -H 0.0.0.0或<your_ip>
Xinference 默认会在本地启动服务,端口默认为 9997。因为这里配置了-H 0.0.0.0参数,非本地客户端也可以通过机器的 IP 地址来访问 Xinference 服务。
启动成功后,我们可以通过地址 http://localhost:9777 来访问 Xinference 的 WebGUI 界面了。
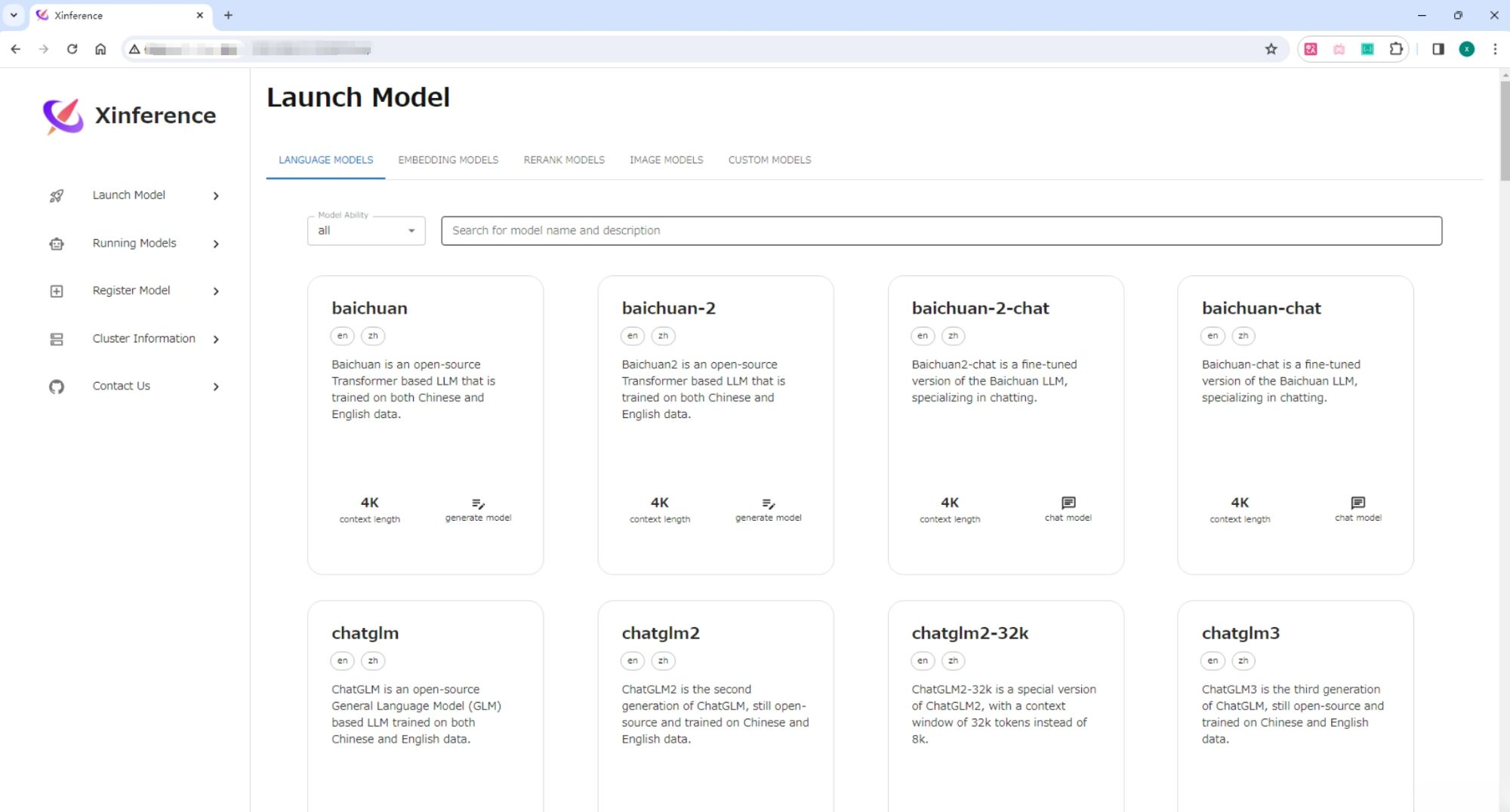
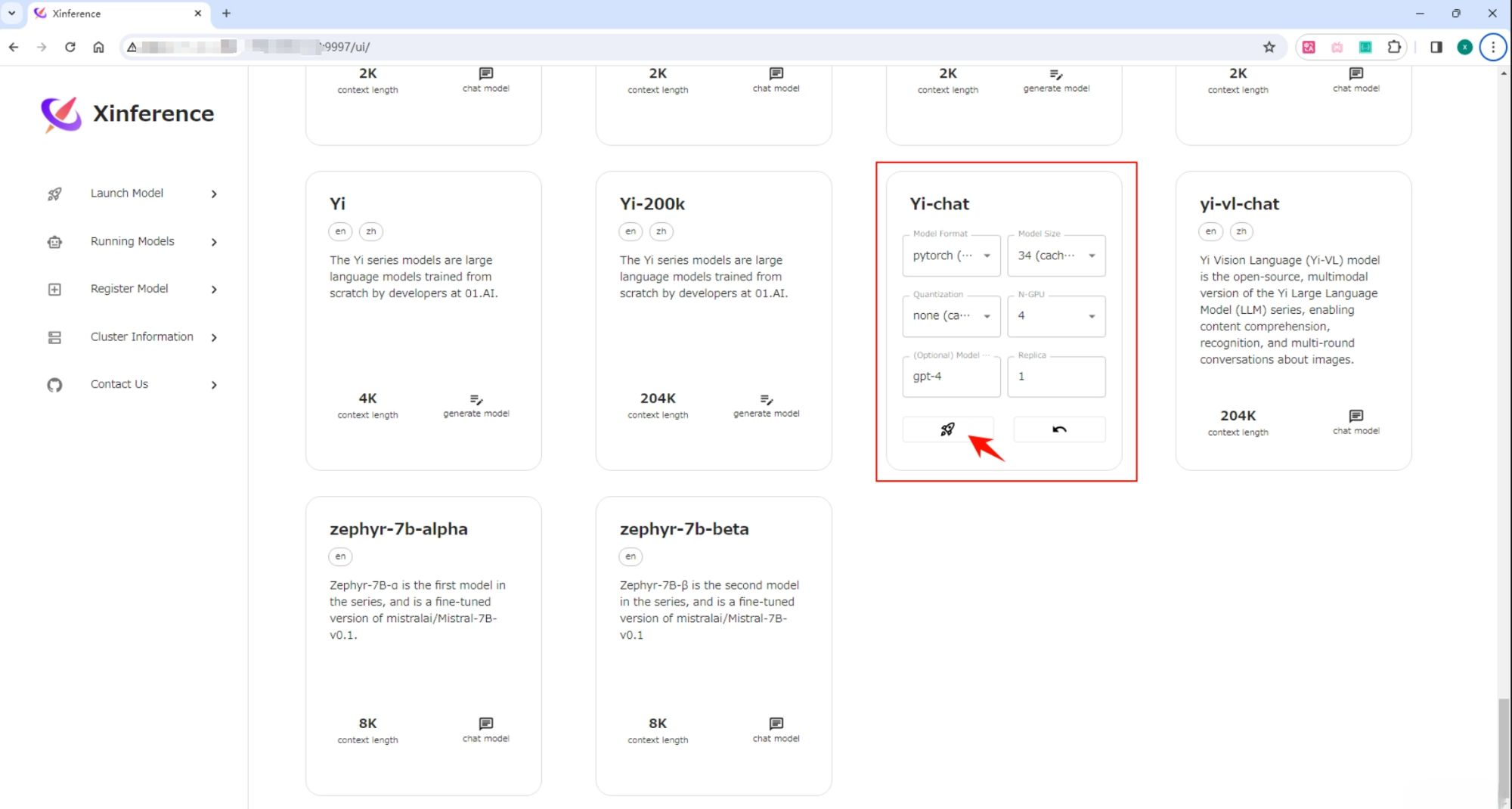
打开“Launch Model”标签,搜索到 Yi-chat,选择模型启动的相关参数,然后点击模型卡片左下方的小火箭 按钮,就可以部署该模型到 Xinference。 默认 Model UID 是 Yi-chat(后续通过将通过这个 ID 来访问模型)。

当第一次启动 Yi-chat 模型时,Xinference 会从 HuggingFace 下载模型参数,大概需要几分钟的时间。Xinference 将模型文件缓存在本地,这样之后启动时就不需要重新下载了。

点击该下载好的模型。
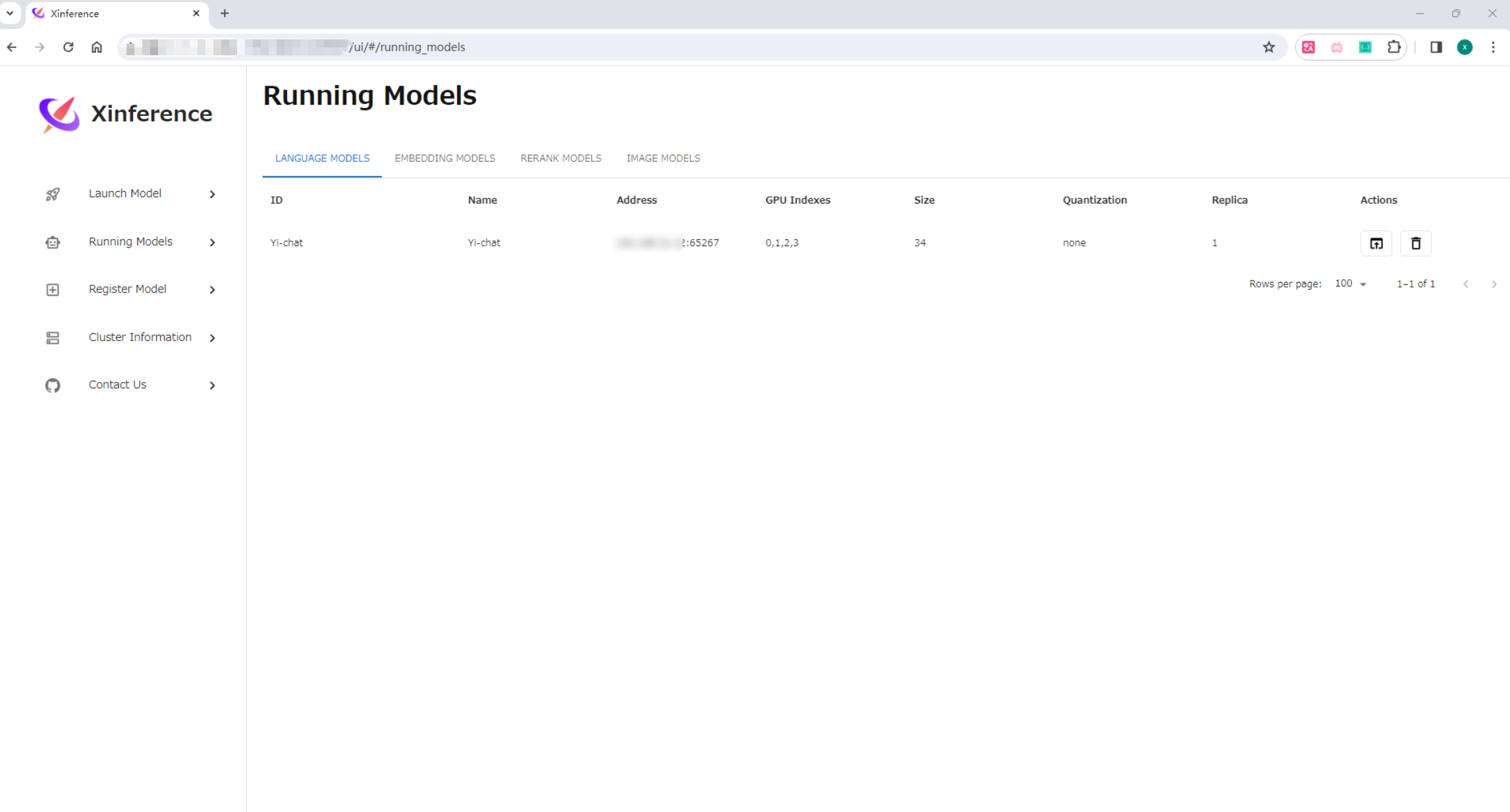
运行成功后,在 “Running Models” 页面可以查看。
Linux 安装 Xinference
在Linux下个人更推荐docker安装,这里需要准备两个前提,确保机器上已经安装了 Docker 和 CUDA。
docker一键安装 Xinference 服务。
docker pull xprobe/xinference:latest
docker启动 Xinference 服务
docker run -it --name xinference -d -p 9997:9997 -e XINFERENCE_MODEL_SRC=modelscope -e XINFERENCE_HOME=/workspace -v /yourworkspace/Xinference:/workspace --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0
-
-e XINFERENCE_MODEL_SRC=modelscope:指定模型源为modelscope,默认为hf
-
-e XINFERENCE_HOME=/workspace:指定docker容器内部xinference的根目录
-
-v /yourworkspace/Xinference:/workspace:指定本地目录与docker容器内xinference根目录进行映射
-
–gpus all:开放宿主机全部GPU给container使用
-
xprobe/xinference:latest:拉取dockerhub内xprobe发行商xinference项目的最新版本
-
xinference-local -H 0.0.0.0:container部署完成后执行该命令
部署完成后访问IP:9997即可。
Xinference使用
Xinference接口
在 Xinference 服务部署好的时候,WebGUI 界面和 API 接口已经同时准备好了,在浏览器中访问http://localhost:9997/docs/就可以看到 API 接口列表。
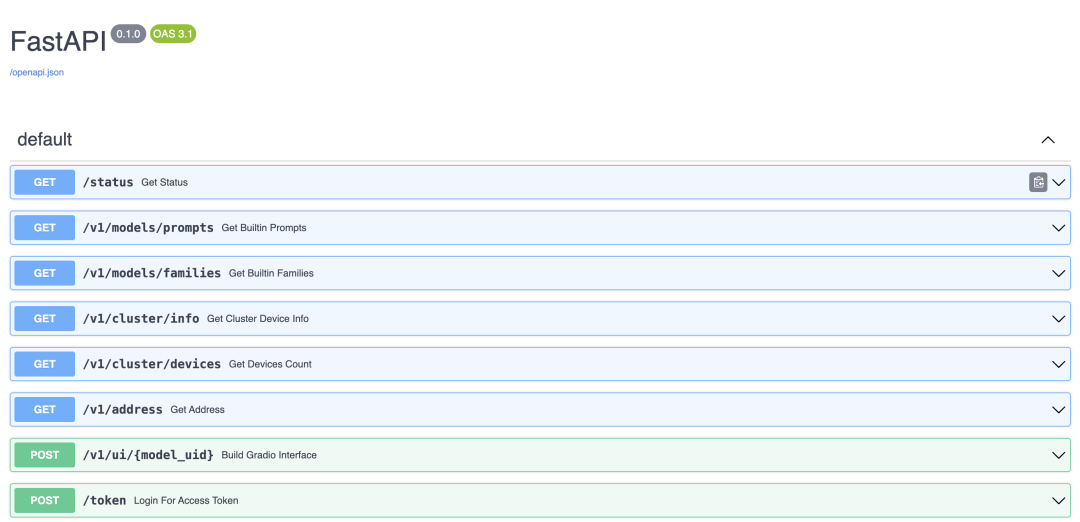
接口列表中包含了大量的接口,不仅有 LLM 模型的接口,还有其他模型(比如 Embedding 或 Rerank )的接口,而且这些都是兼容 OpenAI API 的接口。以 LLM 的聊天功能为例,我们使用 Curl 工具来调用其接口,示例如下:
curl -X 'POST' \
'http://localhost:9997/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "chatglm3",
"messages": [
{
"role": "user",
"content": "hello"
}
]
}'
# 返回结果
{
"model": "chatglm3",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I help you today?",
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 8,
"total_tokens": 29,
"completion_tokens": 37
}
}
Xinference多模态模型
多模态模型是指可以识别图片的 LLM 模型,部署方式与 LLM 模型类似。
首先选择Launch Model菜单,在LANGUAGE MODELS标签下的模型过滤器Model Ability中选择vl-chat,可以看到目前支持的 2 个多模态模型:
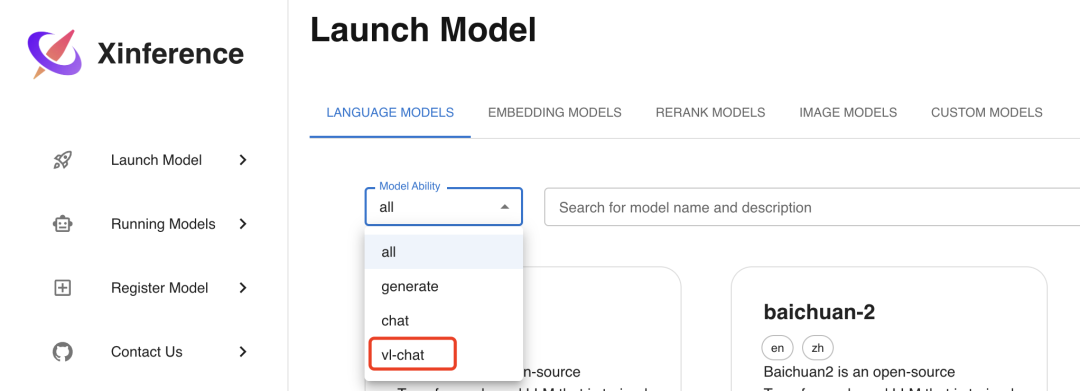
选择qwen-vl-chat这个模型进行部署,部署参数的选择和之前的 LLM 模型类似,选择好参数后,同样点击左边的火箭图标按钮进行部署,部署完成后会自动进入Running Models菜单,显示如下:
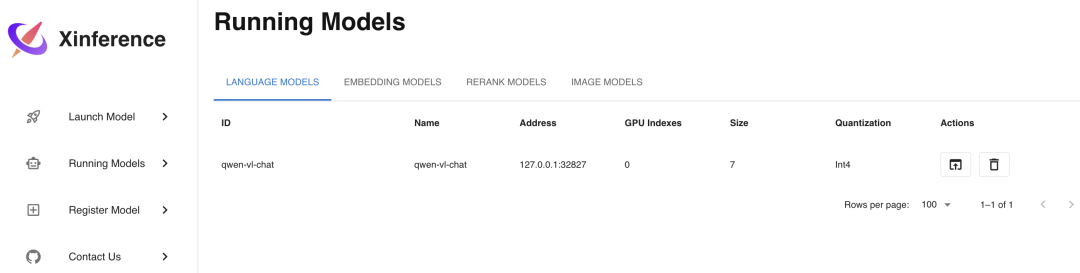
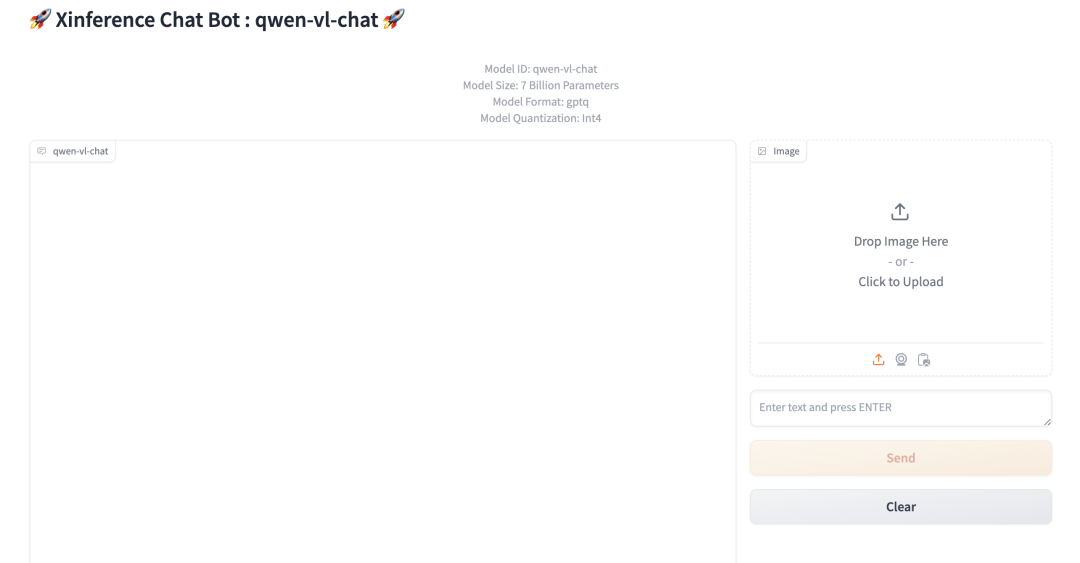
点击图中Launch Web UI的按钮,浏览器会弹出多模态模型的 Web 界面,在这个界面中,你可以使用图片和文字与多模态模型进行对话,界面如下:
XinferenceEmbedding 模型
Embedding 模型是用来将文本转换为向量的模型,使用 Xinference 部署的话更加简单,只需要在Launch Model菜单中选择Embedding标签,然后选择相应模型,不像 LLM 模型一样需要选择参数,只需直接部署模型即可,这里我们选择部署bge-base-en-v1.5这个 Embedding 模型。
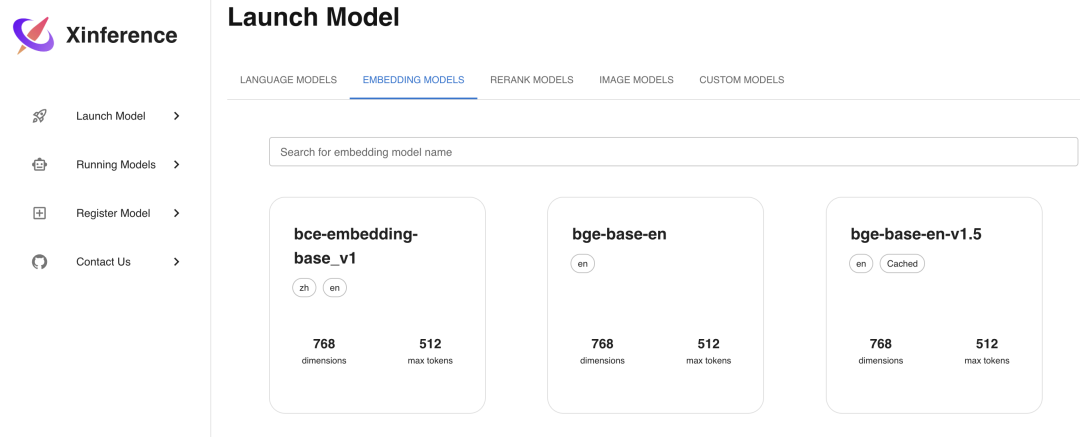
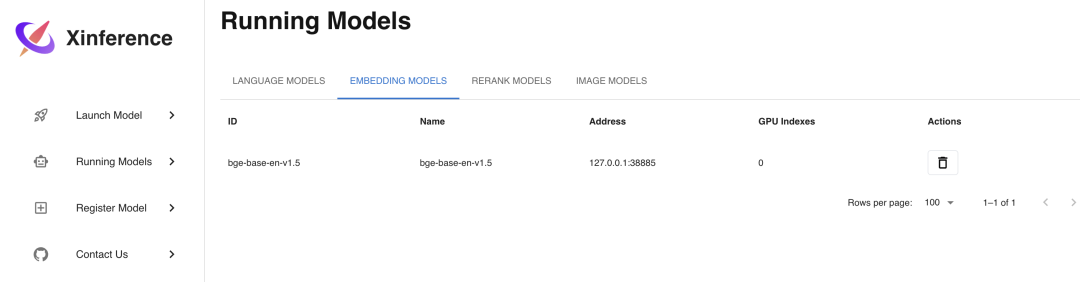
我们通过 Curl 命令调用 API 接口来验证部署好的 Embedding 模型:
curl -X 'POST' \
'http://localhost:9997/v1/embeddings' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "bge-base-en-v1.5",
"input": "hello"
}'
# 显示结果
{
"object": "list",
"model": "bge-base-en-v1.5-1-0",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [0.0007792398682795465, …]
}
],
"usage": {
"prompt_tokens": 37,
"total_tokens": 37
}
}
Xinference Rerank 模型
Rerank 模型是用来对文本进行排序的模型,使用 Xinference 部署的话也很简单,方法和 Embedding 模型类似,部署步骤如下图所示,这里我们选择部署bge-reranker-base这个 Rerank 模型:
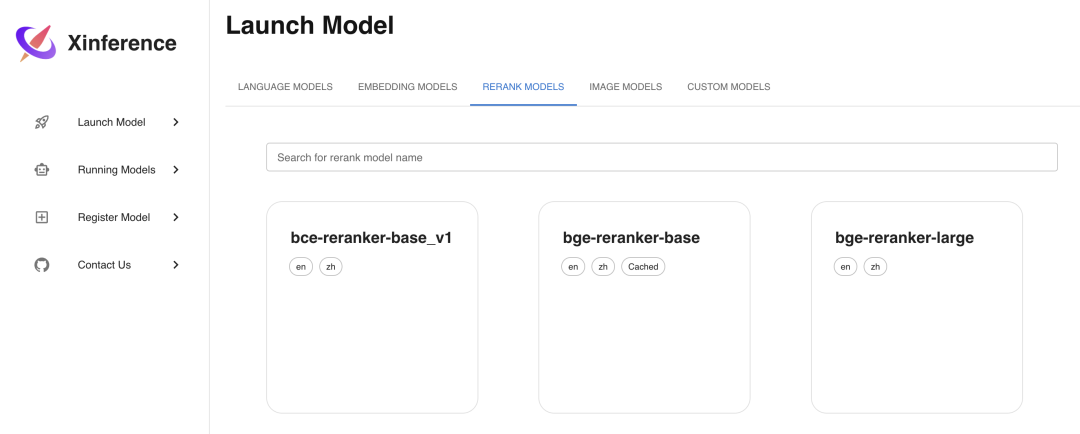
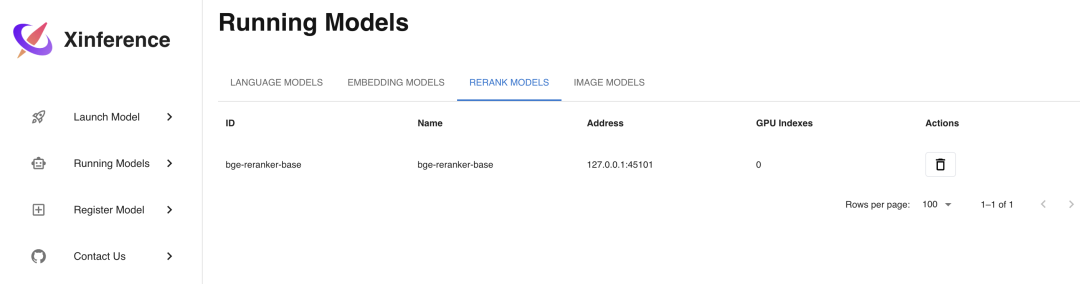
curl -X 'POST' \
'http://localhost:9997/v1/rerank' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "bge-reranker-base",
"query": "What is Deep Learning?",
"documents": [
"Deep Learning is ...",
"hello"
]
}'
# 显示结果
{
"id": "88177e80-cbeb-11ee-bfe5-0242ac110007",
"results": [
{
"index": 0,
"relevance_score": 0.9165927171707153,
"document": null
},
{
"index": 1,
"relevance_score": 0.00003880404983647168,
"document": null
}
]
}
Xinference 注意事项
Xinference 默认是从 HuggingFace 上下载模型,如果需要使用其他网站下载模型,可以通过设置环境变量XINFERENCE_MODEL_SRC来实现,使用以下代码启动 Xinference 服务后,部署模型时会从Modelscope上下载模型:
XINFERENCE_MODEL_SRC=modelscope xinference-local
在 Xinference 部署模型的过程中,如果你的服务器只有一个 GPU,那么你只能部署一个 LLM 模型或多模态模型或图像模型或语音模型,因为目前 Xinference 在部署这几种模型时只实现了一个模型独占一个 GPU 的方式,如果你想在一个 GPU 上同时部署多个以上模型,就会遇到这个错误:No available slot found for the model。
但如果是 Embedding 或者 Rerank 模型的话则没有这个限制,可以在同一个 GPU 上部署多个模型。
小结
Xinference在基础配置功能上也是毫不含糊,相比于LM studio的界面更加简洁清爽,在模型库方面同样也是下载自Hugging Face Hub,同样也是需要科学上网或者修改下载源。
但有两个比较大的优势就是:Xinference的显存管理能力还比较好,服务挂掉可以自动重启,具有较高的稳定性。其次是支持集群模式部署,可以保证大模型的高可用。
大模型侧工具安装部署总结
由于作者的眼界、精力和能力也有限,并且确实也不是专业的AI研究员,仅仅是一位兴趣使然的爱好者,这里列出的几款也单纯只是作者平常关注到的,所以可能也不全,请各位见谅!
文章从起笔写到这里已经过了三天了,这三天也基本把上文提到的大模型侧工具全部体验了一遍,下面说一下主要结论吧。
就这三个工具而言,确实也是各有千秋:
-
从功能丰富度和性能优化的角度综合评估,LM Studio明显更胜一筹。
-
从工具本身使用及模型部署效率来看,Ollama的上手速度会更快,使用会更便捷,效率也会更高。
-
从企业级稳定性和高可用来看,Xinference支持分布式部署,并且可以故障自动拉起。
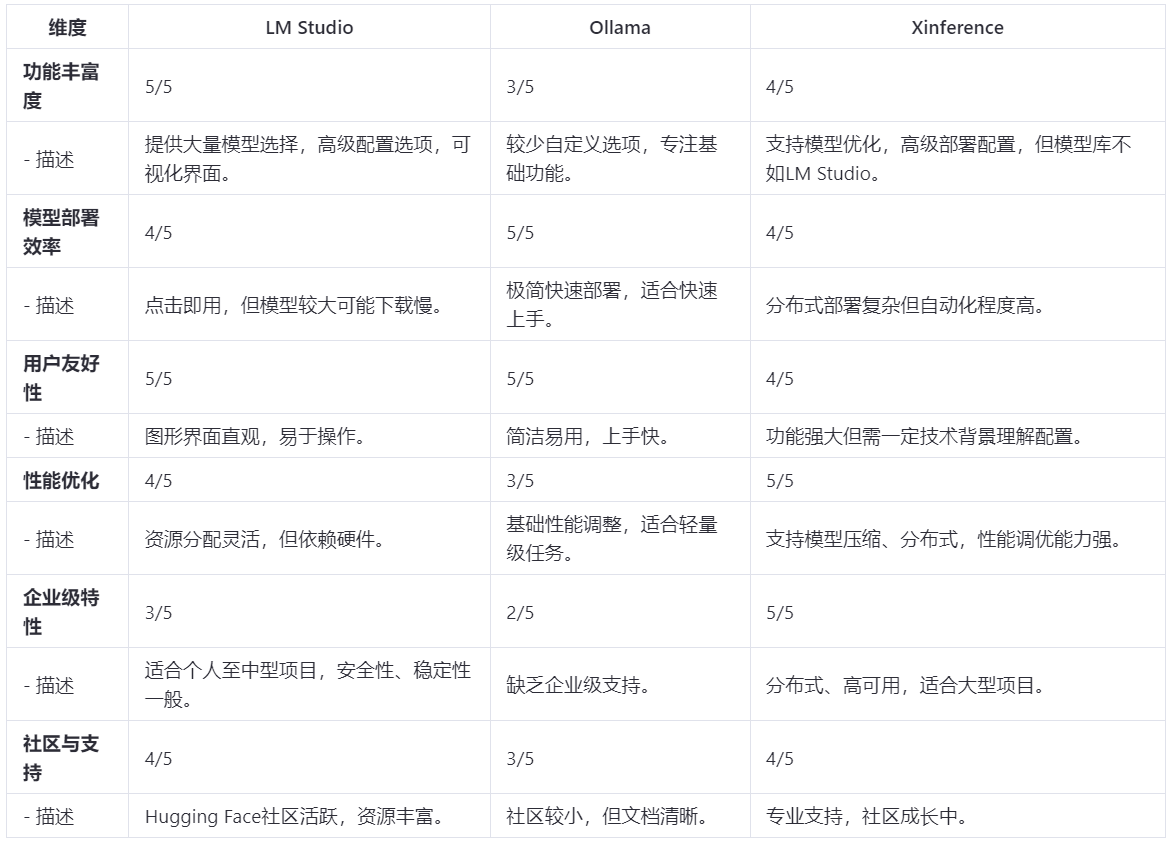
【注】:评分标准为1-5分,5分为最高。
对于AI小白来说(完全不懂AI,不知道大模型是什么具体含义,完全不知道怎么下载模型),选择Ollama来管理和下载模型是保证没有问题的,体验感确实拉满了。
对于一些开发者和研究员而言,我觉得可以在LM Studio和Xinference中任选其一,如果是个人实验的话,我倾向于推荐LM Studio;如果是企业级内部或者中大型项目需要的话,我建议还是采用Xinference。
除了上述提到的之外可能也还有一些比较好用的大模型管理工具是周周没有接触过的,也请小伙伴们积极指出~
随着AI技术的飞速发展,新的工具和服务也会不断涌现,本文截止至2024年6月9日,请各位选择最适合自己需求的工具,这将有助于提升工作效率,推动项目的成功。
记住,没有绝对最好,只有最适合当前情境的工具。















 3121
3121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









