







基于RFM的精细化用户管理
用户价值细分是了解用户价值度的重要途径,销售型公司对于订单交易尤为关注,因此基于订单交易的价值度模型将更适合运营需求。针对交易数据分析的常用模型是RFM模型,该模型简单,容易理解,且业务落地能力强。
本文原始数据来源于《Python数据分析与数据化运营》。
一、背景和目标
在制定运营策略,营销策略时,我们希望针对不同的客户类型推行不同的策略,实现精准化运营,从而获得最大的转化率。而要实现精准化运营就离不开客户分类。通过客户分类,将客户分为重要保持客户,重要发展客户,重要挽留客户,一般客户,低价值客户。对不同的客户群体开展不同的个性化服务,将有限的资源合理分配给不同价值度客户,从而实现效益最大化。
RFM模型是常见的价值度模型,根据会员最近一次购买时间R(Recency),购买频率F(Frequency),购买金额M(Monetary)计算RFM得分,通过这3个维度来评估客户的订单活跃价值,常用来做客户分群或价值分群。
本实例通过某企业2018年的用户订单抽样数据,利用kmeans对客户群体进行细分,并利用RFM模型对客户价值进行分析,对不同价值的用户制定相应的运营策略。
二、案例过程
采用jupyter notebook(Python3.7)
1)导入相应的库
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import os
os.chdir('H:\python_book_v2\chapter5')
2)读取数据
import os
os.chdir('H:\python_book_v2\chapter5')
data=pd.read_excel('sales.xlsx',sheet_name='2018') #选取2018年数据进行分析
3)数据审查
- 查看前5条数据并且查看不同数据列的数据格式,看是否符合源数据文件的格式或得到目标转换要求。
data.head()

data.dtypes

explore=data.describe(percentiles=[],include='all').T
explore['null']=len(data)-explore['count']

从上述结果可以得到
- 共有81349条,缺失值仅有一条,因此可以选择丢弃而带来的影响较小;
- 每个sheet表中的数据都能正常读取和识别,无任何错误;
- 日期列被自动识别为日期格式,省去后期做转化的过程;
- 数据分布十分的不均匀,订单金额的最小值为0而最大值为174900,而订单金额存在0显然没有实际意义,为异常值,在后续处理中应该去掉。
4)数据预处理
data=data.dropna() #去掉含有缺失值的行记录
data=data[data['订单金额']>1] #去掉订单金额小于等于1的行记录
data['max_year_data']=data['提交日期'].max() #获取一年中日期的最大值
data['data_interval']=data['max_year_data']-data['提交日期']
data['data_interval']=data['data_interval'].apply(lambda x:x.days) #将时间间隔转化为数值型计算对象
#通过agg聚合函数来求R,F,M三列的值
rfm_gb=data.groupby('会员ID',as_index=False).agg({'data_interval':'min','订单号':'count','订单金额':'sum'})
rfm_gb.columns=['会员ID','R','F','M'] #rR表示最近一次下订单时间,M表示2018年下单频率,M表示订单金额总和
5)使用KMeans聚类
- 数据标准化处理
聚类之前为了消除不同量纲带来的影响,还要对R,F,M三列数据进行标准化处理。数据的标准化处理方法有最大化最小化处理,标准差标准化处理,这里采用标准差标准化处理。
先建立StandardScaler对象,然后使用fit_transform转化。
numeric_feature=rfm_gb.iloc[:,1:] #获取数值型特征
scaler=StandardScaler()
scaled_numeric_feature=scaler.fit_transform(numeric_feature)
print(scaled_numeric_feature)
转化后数据如下:
- 训练聚类模型
先建立聚类模型对象,设置random_state=0可以避免由于初始值的不同导致聚类差异,然后通过fit方法训练模型。
model_kmeans=KMeans(n_clusters=5,random_state=0) #建立聚类模型对象
model_kmeans.fit(scaled_numeric_feature) #训练聚类模型
- 合并数据和特征
kmeans_labels=pd.DataFrame(model_kmeans.labels_+1,columns=['labels'])
rfm=pd.DataFrame(scaled_numeric_feature)
ID=pd.DataFrame(rfm_gb.index.values)
kmeans_data=pd.concat([ID,rfm,kmeans_labels],axis=1)
kmeans_data.columns=['会员ID','ZR','ZF','ZM','labels']
kmeans_data.head()
现将labels构造为pandas数据框,然后和rfm合并,输出top结构如下:
- 保存聚类结果到Excel
kmeans_data.to_excel('sales_kmeans_data.xlsx')
结果如图所示

- 计算不同聚类类别的样本量和占比
对每个label进行汇总,统计指标可以是任意一列,这里选取“会员ID”,得到频数和占比,然后合并为一个数据框
label_count=kmeans_data.groupby('labels')['ZR'].count() #计算频数
label_count_rate=label_count/kmeans_data.shape[0] #计算占比
label_records_count=pd.concat([label_count,label_count_rate],axis=1) #将两列数据合并
label_records_count.columns=['count','rate'] #重命名
print(label_records_count)
输出结果如下:
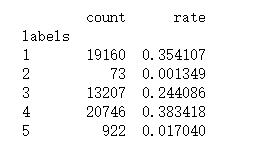
- 计算不同聚类类别数值型特征
在不同类别中,我们需要知道每个特征的突出性与其他类别下该特征的对比,从K-Means以均值项为基础指标做参考,因此均值是更为合理的选择。
kmeans_numeric_feature=kmeans_data.groupby('labels')['ZR','ZF','ZM'].mean()
kmeans_numeric_feature=pd.DataFrame(kmeans_numeric_feature)
kmeans_numeric_feature
输出结果如下

6)图形展示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False #使得中文正常显示
x=label_records_count.index
height=label_records_count.values[:,0]
labels=['群体1','群体2','群体3','群体4','群体5']
plt.bar(height=height,x=x,width=0.5)
plt.xticks(label_records_count.index,labels)
plt.xlabel('群体')
plt.ylabel('频数')
plt.title('五类群体数量分布')
for a,b in zip(x,height): #设置数字标签
plt.text(a,b,'%.0f'%b,ha='center',va='bottom')
plt.show()

生成雷达图的数据名为cluster_data
x1=pd.DataFrame(labels)
x2=pd.DataFrame(label_count.values)
x3=pd.DataFrame(kmeans_numeric_feature.values)
cluster_data=pd.concat([x1,x2,x3],axis=1)
cluster_data.columns=['cluster_names','cluster_num','ZR','ZF','ZM']
数据展示如图:

定义生成雷达图的函数
def plot_radar(data):
'''
the first column of the data is the cluster name;
the second column is the number of each cluster;
the last are those to describe the center of each cluster.
'''
kinds = data.iloc[:, 0]
labels = data.iloc[:, 2:].columns
centers = pd.concat([data.iloc[:, 2:], data.iloc[:,2]], axis=1)
centers = np.array(centers)
n = len(labels)
angles = np.linspace(0, 2*np.pi, n, endpoint=False)
angles = np.concatenate((angles, [angles[0]]))
fig = plt.figure()
ax = fig.add_subplot(111, polar=True) # 设置坐标为极坐标
# 画若干个三角形
floor = np.floor(centers.min()) # 大于最小值的最大整数
ceil = np.ceil(centers.max()) # 小于最大值的最小整数
for i in np.arange(floor, ceil + 0.5, 0.5):
ax.plot(angles, [i] * (n + 1), '--', lw=0.5 , color='black')
# 画不同客户群的分割线
for i in range(n):
ax.plot([angles[i], angles[i]], [floor, ceil], '--', lw=0.5, color='black')
# 画不同的客户群所占的大小
for i in range(len(kinds)):
ax.plot(angles, centers[i], lw=2, label=kinds[i])
#ax.fill(angles, centers[i])
ax.set_thetagrids(angles * 180 / np.pi, labels) # 设置显示的角度,将弧度转换为角度
plt.legend(loc='lower right', bbox_to_anchor=(1.5, 0.0)) # 设置图例的位置,在画布外
ax.set_theta_zero_location('N') # 设置极坐标的起点(即0°)在正北方向,即相当于坐标轴逆时针旋转90°
ax.spines['polar'].set_visible(False) # 不显示极坐标最外圈的圆
ax.grid(False) # 不显示默认的分割线
ax.set_yticks([]) # 不显示坐标间隔
plt.show()
plot_radar(cluster_data)
生成雷达图展示如下:

分析:
- 群体1的三个属性相当,均比较小
- 群体2在F,M属性上最大,R属性上最小
- 群体3的R属性最大
- 群体4的三个属性相当,均比较小
- 群体5的F,M属性较大,R属性较小
其中每项指标的实际意义:
- R:最近一次购买时间
- F:购买频数,频数越大表示购买越多
- M:购买总金额,越大表示购买总金额越多
对应实际业务进行分值离散转化,对应1-5分,属性值越大,分值越高
同时定义五个等级的客户类别
(1)重要保持客户
最近有购买记录,购买次数高且购买总金额高,这类客户购买金额大,经常购买,是最理想的客户类型,公司应优先将资源投放到他们身上,维持这类客户的忠诚度。
(2)重要发展客户
最近有购买记录,购买次数高或购买总金额高,这类客户最近有购买记录,但购买频数低或总购买金额低,具有很大的发展潜力,公司应加强这类客户的满意度,使他们逐渐成为忠诚客户。
(3)重要挽留客户
购买次数高或购买总金额高,最近无购买记录,这类客户总购买金额高,但较长时间没有购买,可能处于流失状态公司应加强与这类客户的互动,召回用户,延长客户的生命周期。
(4)一般客户
最近有购买记录,购买次数高但总购买金额低,这类客户购买金额低,可能经常买折扣商品,最近无购买记录,可能是趁着折扣而选择购买,对品牌无忠诚度公司需要在资源支持的情况下强化对这类客户的联系
(5)低价值客户
最近无购买记录,购买次数低或购买总金额低,这类客户与一般客户类似,购买金额低,可能经常买折扣商品,最近无购买记录,可能是趁着折扣而选择购买,对品牌无忠诚度
根据聚类结果,对应上述五类客户类型,进行匹配,得到客户群体的价值排名:

现在已经将所有客户分群同时客户群体也对应了客户价值,建模完成。
三、分析结果
根据建模结果,发现该公司五类不同价值数量对应如下
根据二八法则:一般而言企业的80%收入由20%的用户贡献。从图中也能看出,忠诚的重要保留客户,重要发展客户必然贡献了企业的绝大部分,企业也需要投入资源服务好这部分客户。
同时,重要发展客户,重要保持客户,重要挽留客户也对应客户生命周期的发展期,稳定期,衰退期,企业也应重点投入资源挽留衰退期的客户。
针对不同的群体提出不同策略:
- 群体1(低价值客户):在这类群体的最近接触渠道上可以增加营销或广告资源投入,通过这些渠道再次吸引客户完成消费;
- 群体2(重要保持客户):这是绝对忠诚的高价值用户,虽然数量只有73,但由于各方面突出,因此可以亲些更多的资源,比如设计VIP服务,专项服务,绿色通道等;
- 群体3(一般客户):这类客户占比较大,且最近有购买记录但购买金额较低,可以增加订单相关的刺激措施,例如组合商品优惠券发放,,积分购买商品等;
- 群体4(重要挽留客户):对于这部分客户重点是提升新近购买度,即促进最近一次消费,可以通过电话,电子邮件,发放优惠券等方式挽回这部分高价值客户;
- 群体5(重要发展客户);这类群体的消费新进度高消费金额大但购买频数低,所以对这部分群体主要是提升购买频数,除了可以在最近一次的购买渠道上增加曝光,与最近一次相关的其他关联访问渠道增加营销资源外,还可以指定不同活动或事件来触达用户,增加用户的回访,促进购买。















 292
292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









