







python数据分析与数据化运营 第二版 宋天龙
import time # 时间库
import numpy as np # numpy库
import pandas as pd # pandas库
from sklearn.ensemble import RandomForestClassifier # RF库
#读取数据
sheet_names = ['2015','2016','2017','2018','会员等级']
sheet_datas = [pd.read_excel('sales.xlsx',sheet_name=i)for i in sheet_names]
#数据审查
for each_name,each_data in zip(sheet_names,sheet_datas):
print('[data summary for {0:=^50}]'.format(each_name))
print('Overview:','\n',each_data.head(4))# 展示数据前4条
print('DESC:','\n',each_data.describe())# 数据描述性信息
print('NA records',each_data.isnull().any(axis=1).sum()) # 缺失值记录数
print('Dtypes',each_data.dtypes) # 数据类型# 去除缺失值和异常值
for ind,each_data in enumerate(sheet_datas[:-1]):
sheet_datas[ind] = each_data.dropna()# 丢弃缺失值记录
sheet_datas[ind] = each_data[each_data['订单金额'] > 1]# 丢弃订单金额<=1的记录
sheet_datas[ind]['max_year_date'] = each_data['提交日期'].max() # 增加一列最大日期值# 汇总所有数据
data_merge = pd.concat(sheet_datas[:-1],axis=0)
# 获取各自年份数据
data_merge['date_interval'] = data_merge['max_year_date']-data_merge['提交日期']
data_merge['year'] = data_merge['提交日期'].dt.year
# 转换日期间隔为数字
data_merge['date_interval'] = data_merge['date_interval'].apply(lambda x: x.days) # 转换日期间隔为数字
#data_merge.head()# 按会员ID做汇总
rfm_gb = data_merge.groupby(['year','会员ID'],as_index=False).agg({'date_interval':
'min', # 计算最近一次订单时间
'提交日期': 'count', # 计算订单频率
'订单金额': 'sum'}) # 计算订单总金额
# 重命名列名
rfm_gb.columns = ['year','会员ID','r','f','m']
rfm_gb.head() 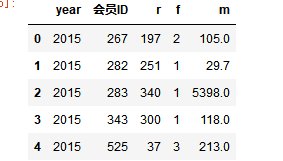
# 查看数据分布
desc_pd = rfm_gb.iloc[:,2:].describe().T
print(desc_pd)
# 定义区间边界
r_bins = [-1,79,255,365] # 注意起始边界小于最小值
f_bins = [0,2,5,130]
m_bins = [0,69,1199,206252]
count mean std min 25% 50% 75% max
r 148591.0 165.524043 101.988472 0.0 79.0 156.0 255.0 365.0
f 148591.0 1.365002 2.626953 1.0 1.0 1.0 1.0 130.0
m 148591.0 1323.741329 3753.906883 1.5 69.0 189.0 1199.0 206251.8RFM三个变量已规整完成,接下来就是进行区间划分,可以对其做分箱或离散化操作,通过对其基本数据描述概要来看R,M较为离散,F则大部分用户趋近于1,因为数据集是大件家电,所以一年一次为正常现象,所以做出如下区间划分,M,R以25%,75%的数值为分界线,F以2,5分三个区间。
#计算RFM因子权重
# 匹配会员等级和rfm得分
rfm_merge = pd.merge(rfm_gb,sheet_datas[-1],on='会员ID',how='inner')
# rf获得rfm因子得分
clf = RandomForestClassifier()
clf = clf.fit(rfm_merge[['r','f','m']],rfm_merge['会员等级'])
weights = clf.feature_importances_
print('feature importance:',weights)feature importance: [0.42950337 0.00630906 0.56418758]
RFM的权重建立的基本思路,建立一个RFM三个变量与会员等级的分类,然后通过RFM模型输出权重
# RFM分箱得分
rfm_gb['r_score'] = pd.cut(rfm_gb['r'], r_bins, labels=[i for i in range(len(r_bins)-1,0, -1)]) # 计算R得分
rfm_gb['f_score'] = pd.cut(rfm_gb['f'], f_bins, labels=[i+1 for i in range(len(f_bins)-1)]) # 计算F得分
rfm_gb['m_score'] = pd.cut(rfm_gb['m'], m_bins, labels=[i+1 for i in range(len(m_bins)-1)]) # 计算M得分# 计算RFM总得分
# 方法一:加权得分
rfm_gb = rfm_gb.apply(np.int32) # cate转数值
rfm_gb['rfm_score'] = rfm_gb['r_score'] * weights[0] + rfm_gb['f_score'] * weights[1] + rfm_gb[
'm_score'] * weights[2]# 方法二:RFM组合
rfm_gb['r_score'] = rfm_gb['r_score'].astype(np.str)
rfm_gb['f_score'] = rfm_gb['f_score'].astype(np.str)
rfm_gb['m_score'] = rfm_gb['m_score'].astype(np.str)
rfm_gb['rfm_group'] = rfm_gb['r_score'].str.cat(rfm_gb['f_score']).str.cat(
rfm_gb['m_score'])rfm_gb.to_excel('sales_rfm_score.xlsx') # 保存数据为Excel
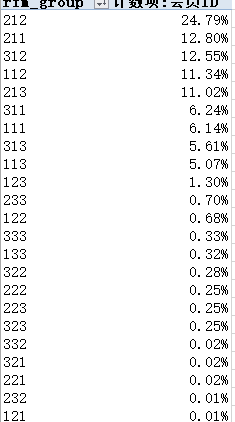
在得到RFM分级数据之后我们需要对客户的价值度进行细分了,首先通过excel的数据透视表的到RFM分组用户的占比,可以发现前9个分组用户数量总和接近整体。那所以说把分析重点放在这9组用户群体上。那又可以把这两组用户群体分为俩类一是占比超过百分之十,二是占比不到百分之十的,另还需要增加针对于大客户群体进行单独分析。















 1031
1031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









