







 文章探讨了标准卷积和因果卷积的区别,主要在于padding的位置。标准卷积在两侧填充,而因果卷积仅在前面填充,确保不会看到未来的数据。因果卷积适用于序列预测任务,防止信息泄露。通过代码示例展示了在Keras中如何实现因果卷积,并指出在Pytorch中可使用validpadding达到类似效果。
文章探讨了标准卷积和因果卷积的区别,主要在于padding的位置。标准卷积在两侧填充,而因果卷积仅在前面填充,确保不会看到未来的数据。因果卷积适用于序列预测任务,防止信息泄露。通过代码示例展示了在Keras中如何实现因果卷积,并指出在Pytorch中可使用validpadding达到类似效果。
标准(传统)卷积和因果卷积的区别(一维)
问题的起源
在TCN论文及代码解读总结中提到
因果卷积和传统的卷积神经网络的不同之处在于,因果卷积不能看到未来的数据
找了很长时间没有捋清头绪,转头把方向指向了代码,就从官方文档下手吧,在Pytorch文档里面没有找到因果卷积的相关定义,却在Keras中文文档里面找到了,当padding值为"causal"时,表示因果(膨胀)卷积,回头看Pytorch文档发现Pytorch的padding没有"causal"这个值!但它们都有{"valid", "same"}。
那么问题来了:
当padding值为
{"valid", "same"}是不是代表标准卷积?
下面就开始找文章验证自己猜想,并尝试复现相关代码
相关文章
第一篇常规卷积与因果卷积的区别详解
这篇博客有Pytorch实现TCN的代码参考,结合TCN说明了常规卷积和因果卷积的区别只是padding位置不同。标准卷积是在两边padding,而因果卷积只是在前面padding,该博客也解释了TCN为了实现因果卷积对Conv1d进行Chomp1d处理的原因。但看到下面评论有点疑惑???说大错特错???我带着疑问找到了下面这个链接,也验证了这篇博客说的没有问题,评论有问题。
第二篇Machine Learning for Finance这应该是一本书
白嫖看到了想看到的部分,解释了标准卷积和因果卷积的区别,太幸运了吧!这里只把图片放到这里,供参考哈
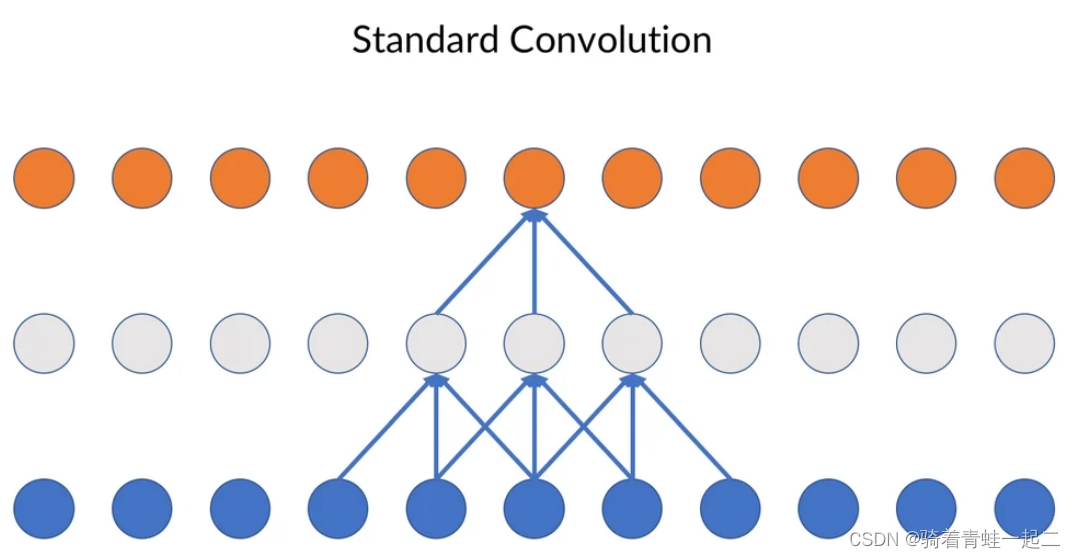 原文给出了这句解释:Standard convolution does not take the direction of convolution into account.
原文给出了这句解释:Standard convolution does not take the direction of convolution into account.(标准卷积不考虑卷积的方向)说实话我没看懂
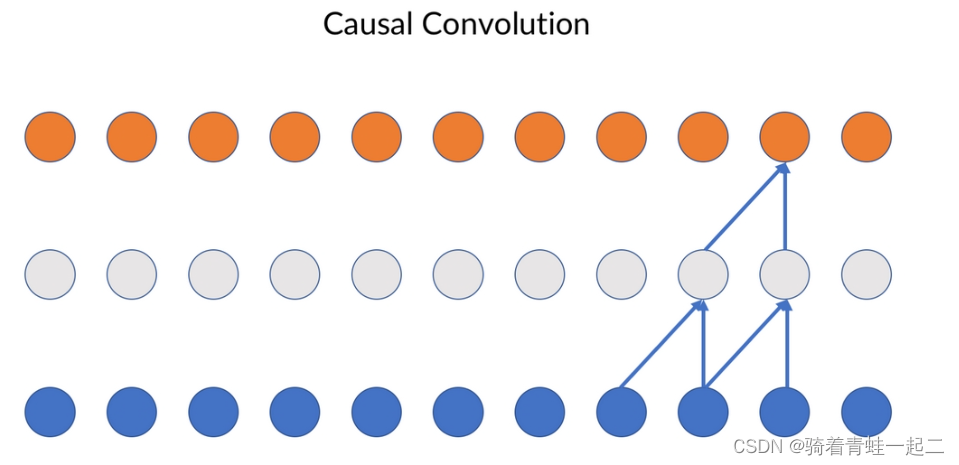
同样原文也解释了这个图片:Causal convolution shifts the filter in the right direction.(因果卷积将过滤器朝正确的方向移动)自行翻译理解吧
个人理解
因果卷积和标准卷积只是padding的位置区别。
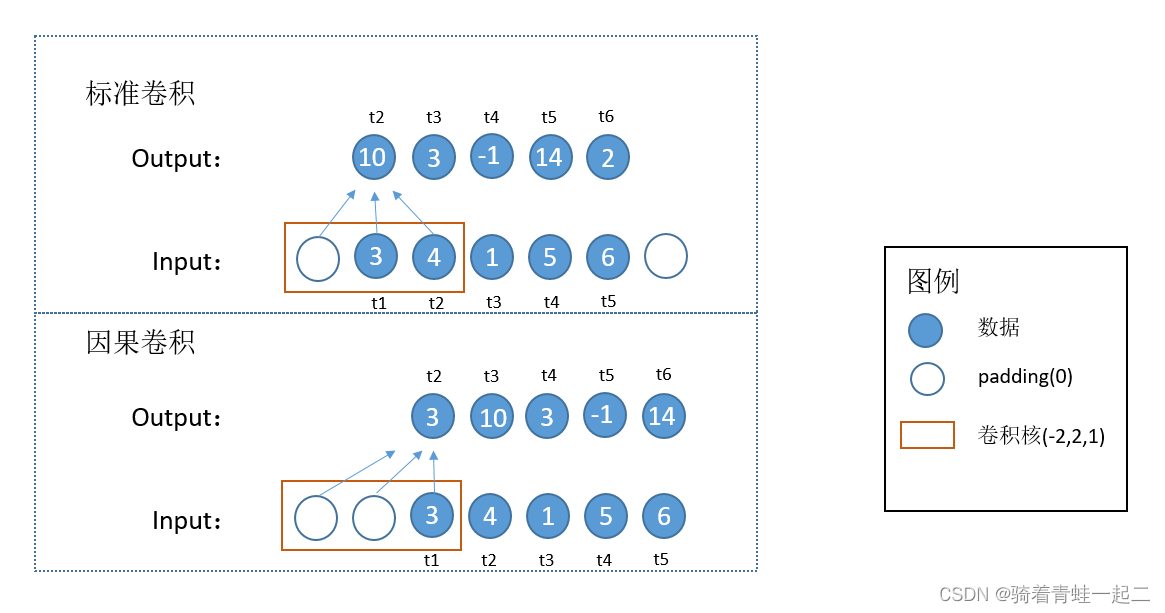
对于因果卷积不能看到未来的数据给出一下个人见解,这里涉及到一个知识点(感受野)。我们以输出的t3值为例,标准卷积输出为3,标准卷积的感受野为[3,4,1],也就是意味着它用t1、t2、t3时刻的数据去预测t3,也就造成了标准卷积看到了未来数据的问题;对于因果卷积来说,输出的t3值为10,因果卷积的感受野为[0,3,4],也就避免了上面问题。
这里有个前提:
数据和标签在一起,而不是单独分开,如果标签和数据分开,就不会导致未来数据泄露。
即当传递给模型的数据格式为[t1,t2,t3,t4,t5],用标准卷积预测t5值就会导致数据泄露,而要用标准卷积预测t6值可能会引入padding的噪声,影响模型性能。
个人部分看法:当padding值为
"same",妥妥的传统卷积。
复现相关代码
为了进一步验证猜想,尝试用代码层面去解释。对于{"valid", "same"}卷积过程,这里我们可以参考各种卷积方式的最全讲解,与下面代码进行对比验证。
- 引入相关模块
from keras.layers import Conv1D
from keras import Sequential
import numpy as np
- 自定义卷积核
def my_init(shape, dtype=None):
# 自定义必须保留 shape, dtype 两个属性
init = [[[-2]], [[2]], [[1]]]
return init
- 定义Conv1D层,将padding设置为
"causal",有兴趣的可以自行修改为其他属性{"valid", "same"}去尝试。
model = Sequential([
Conv1D(1, kernel_size=3, name='cnn1', padding='causal',
kernel_initializer=my_init, # 全部初始化为0
use_bias=False), # 不使用偏置
])
- 自定义传入的数据,并用模型进行输出
x_list = [3, 4, 1, 5, 6] # 自定义列表
# 将列表转换为np数组,并转换为(batch_size, steps, input_dim)格式
x = np.array(x_list, dtype='float64').reshape(1, -1, 1)
y = model(x)
print(y)
tf.Tensor(
[[[ 3.]
[10.]
[ 3.]
[-1.]
[14.]]], shape=(1, 5, 1), dtype=float32)
- 查看层的初始化权重值
layer = model.get_layer('cnn1') # 通过层的名字得到层
k = layer.get_weights() # 查看层的初始化权重值
print(k)
接着讨论
我们假设这样一个场景,给出了t1-t5时刻的数据,我们要预测t6时刻的数据,为了关联更多的数据,那我们是不是要增加感受野,让卷积输出的t6时刻数据包含较大范围的信息,让我们完善一下因果卷积流程吧,同时对比一下当padding值为 "valid"的情况。
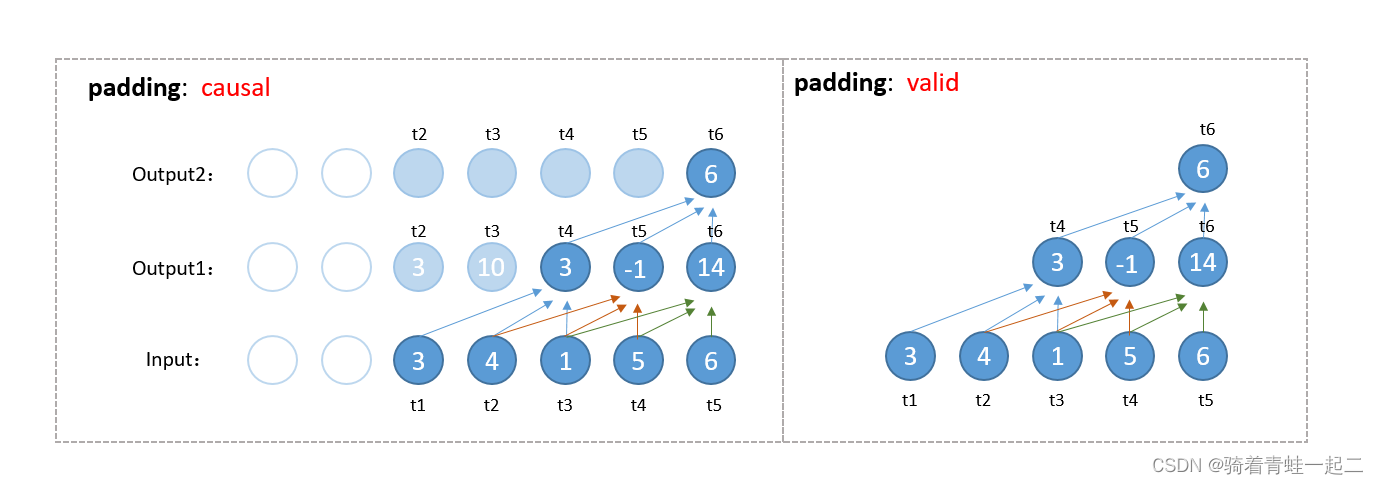
个人部分看法:
当落脚到代码实现上,抛开其他输出时刻数据,只关注t6时刻的数据,会发现我们可以定义padding值为"valid"会实现相同的效果!!!
那是不是意味着padding值为"valid"定义的卷积是因果卷积???我个人看法是认同的。
但当模型复杂度上升之后,要保证输入前后维度保持不变,那就不能选择"valid"这个属性值,而应该参照TCN中的方法。
最后用Pytorch代码去实现两层padding值为"valid"运行后的结果
import torch.nn as nn
import torch
import numpy as np
cnn1 = nn.Conv1d(1, 1, kernel_size=3, padding='valid', bias=False)
cnn1.weight.data = torch.Tensor([[[-2, 2, 1]]])
cnn2 = nn.Conv1d(1, 1, kernel_size=3, padding='valid', bias=False)
cnn2.weight.data = torch.Tensor([[[-2, 2, 1]]])
x_list = [3, 4, 1, 5, 6] # 自定义列表
# 将列表转换为np数组,并转换为(batch_size, steps, input_dim)格式
x = torch.Tensor(np.array(x_list, dtype='float64').reshape(1, 1, -1))
y = cnn1(x)
y = cnn2(y)
print(y)
tensor([[[6.]]], grad_fn=< ConvolutionBackward1 >)

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









