







文章目录
一、四种初始化
1.直接生成,原始结构类型决定张量类型
import torch
data=[[1,2],[3,4]]
x_data=torch.tensor(data)
2.通过numpy转化生成张量(可以相互转化)
import numpy as np
np_array=np.array(data)
x_np=torch.from_numpy(np.array)
3.通过已有张量来生成新的张量
(同时新的张量将会继承已有张量的数据属性,包括结构、类型,也可以指定新的数据类型)
x_zeros=torch.zeros_like(x_data)
x_ones=torch.ones_like(x_data)
x_rand=torch.rand_like(x_data,dtype=torch.float)#生成一个元素服从[0,1]均匀分布的张量,形状和给定张量x_data相同
x_randn=torch.randn_like(x_data)#生成一个元素服从标准正态分布的张量,形状和给定张量x_data相同
x_randint=torch.randint_like(x_data,0,100)#生成0~100均包含的张量,形状和x_data相同
x_full=torch.full_like(x_data,1.7,dtype=torch.float)
4.通过指定数据维度来生成张量(用的比较少)
shape=(2,3)
one_tensor=torch.ones(shape)
full_tensor=torch.full((shape),fill_value=5,dtype=torch.long)
二、属性
张量可以查询张量的维度、数据类型和存储设备(CPU或GPU)
tensor_sa=torch.rand(3,4)
print(tensor_sa)
print(tensor_sa.shape)
print(tensor_sa.dtype)
print(tensor_sa.device)
三、加减乘除
叶子结点不可以原地运算,正常使用+、-、*、/
#加减乘除
a+b=torch.add(a,b)
a-b=torch.sub(a,b)
a*b=torch.mul(a,b)
a/b=torch.div(a,b)
#实操
import torch
a=torch.rand(3,4)
b=torch.rand(4)
a+b#b会被广播 变成最后的维度进行加减乘除
torch.add(a,b)#等价上面相加
torch.all(torch.eq(a+b,torch.add(a,b)))#输出:tensor(True) 测试all里面的所有元素是否评估为True
矩阵相乘
torch.mm(a,b)#此方法只适用于2维
torch.matmul(a,b)
a@b=torch.matmul(a,b)#推荐使用此方法
# 实操
a=torch.full((2,3),3)
b=torch.ones(2,2)
print(torch.mm(a,b))
print(torch.matmul(a,b))
幂次计算
pow,sqrt,rqrt
a=torch.full([2,2],3)
a.pow(2)
aa=a**2
aa.sqrt()
aa**(0.5)
aa.pow(0.5)
aa.rsqrt()#平方根的倒数
四、近似值
a.floor()#向下取整,floor
a.ceil()#向上取整,ceil
a.trunc()#保留整数部分,truncate,截断
a.frac()#保留小数部分,fraction,小数
a.round()#四舍五入:round,大约
五、限幅
a.max()#最大值
a.min()#最小值
a.median()#中位数
a.clamp(10)#将最小值限定为10
a.clamp(0,10)#将数据限定在[0,10],两边都是闭区间
a.max()
a.min()
a.clamp(0.51)
a.clamp(0.2,0.51)
六、所有元素求和、均值
torch.sum(a)
torch.mean(a)
torch.mean(axis=0)#对每一列求平均
七、极值
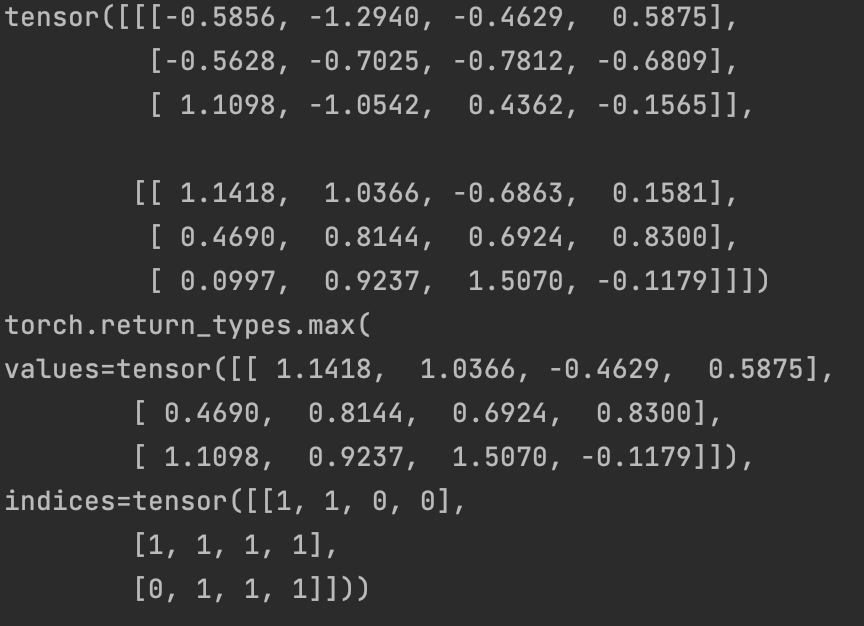
如果只需要最大值或最小值的位置,可以使用argmax和argmin.如果既要获得最大值和最小值的位置,又要获得具体的值,就需要使用max和min
t=torch.randn(2,3,4)
print(torch.argmax(t,0))

t=torch.randn(2,3,4)
print(torch.max(t,0))
八、排序
torch.sort(t,-1)
t.sort(-1)

九、索引和切片
ten=torch.ones(4,4)
ten[:,1]=0
#一维切片
start:stop:step
#二维切片
a[:,0:3]#取前三列的二维数组
import copy
list1 = [[123, 456], [789, 213]]
list2 = list1#浅拷贝
list3 = list1[:]#浅拷贝
list4 = copy.deepcopy(list1)#深拷贝
list1[0][0] = 111
print(list2) # [[111, 456], [789, 213]]
print(list3) # [[111, 456], [789, 213]]
print(list4) # [[123, 456], [789, 213]]
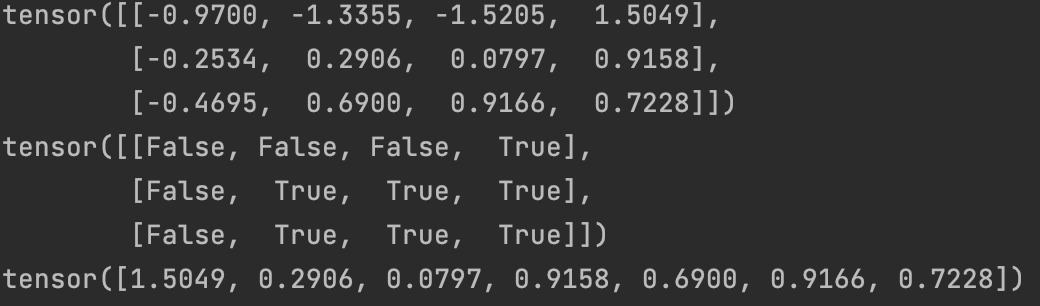
十、掩码
t=torch.randn(3,4)
t>0
t[t>0]
十一、拼接
torch.cat仅仅是张量的连接,不会增加维度
torch.stack是堆叠,会增加维度
t1=torch.randn(2,4)
t2=torch.randn(2,4)
t3=torch.randn(2,4)
t4=torch.randn(2,2)
torch.stack([t1,t2,t3],-1).shape#torch.Size([2,4,3])
torch.stack([t1,t2,t3],0).shape#torch.Size([3,2,4])
torch.stack([t1,t2,t3],1).shape#torch.Size([2,3,4])
torch.stack([t1,t2,t3],2).shape#torch.Size([2,4,3])
torch.cat([t1,t2,t3],-1).shape#torch.Size([2,12])
torch.cat([t1,t2,t3],0).shape#torch.Size([6,4])
torch.cat([t1,t2,t3],1).shape#torch.Size([2,12])
torch.cat([t1,t2,t3,t4],-1).shape#torch.Size([2,14])
#torch.cat([t1,t2,t3,t4],0).shape#报错
torch.cat([t1,t2,t3,t4],1).shape#torch.Size([2,14])
十二、切割
torch.split 、torch.chunk
t=torch.randn(3,6)
t.split([1,2,3],-1)#3*1、3*2、3*3
t.split(3,-1)#3*3 每组3份进行分组
t.chunk(3,-1)#3*2 分成3组进行分组
十三、张量的广播
如果两个数组的后缘维度(从末尾开始算起的维度)的轴长度相符或其中一方的长度为一,则认为它们是广播兼容的。广播会在缺失维度和(或)轴长度为1的维度上进行。
换种说法就是,按从右往左顺序看两个张量的每一个维度,x和y每个对应着的两个维度都需要能够匹配上。满足下面的条件就可以:
a.这两个维度的大小相等
b.某个维度 一个张量有,一个张量没有
c.某个维度 一个张量有,一个张量也有但大小为1
x=torch.empty(5,3,4,1)
y=torch.empty(3,1,1)
从右往左看,两个张量的第四维相等,都为1,满足a;第三维度4、1,满足b;第二维相同都为3;第一位5和没有,b。随意可以进行广播。
所以两个张量维度从右往左看,如果出现两个张量在某个维度位置上面,维度大小不相等,且两个维度大小没有一个是1,那么这两个张量一定不能进行广播。
那两个张量满足可广播条件后,具体怎么进行广播?
统一前:
x=torch.empty(5,3,4,1)
y=torch.empty(3,1,1)
统一后:
x=torch.empty(5,3,4,1)
y=torch.empty(1,3,1,1)
统一前:
x=torch.empty(5,3,4,1)
y=torch.empty(1,3,1,1)
统一后:
x=torch.empty(5,3,4,1)
y=torch.empty(5,3,4,1)
利用unsqueeze扩增进行广播
t1=torch.randn(3,4,5)
t2=torch.randn(3,5)
t2=t2.unsqueeze(1)
#t2.unsqueeze(-1).shape
#t2.unsqueeze(-1).squeeze().shape
t2.shape()#torch.Size([3,1,5])
t3=t1+t2
t3.shape#torch.Size([3,4,5])
十四、反向传播
1.反向传播的基本过程
x=torch.tensor(1.0,requires_grad=True)
y=x**2
z=y+1
z # tensor(2., grad_fn=<AddBackward0>)
z.grad_fn # <AddBackward0 at 0x7fe81279b048>
z.backward() #反向传播结束后,即可查看叶节点的导数值。张量的grad属性存储了该点处的导数值。
x # tensor(1., requires_grad=True)
x.grad # tensor(2.)
# z.backward()# RuntimeError:Traceback (most recent call last) 在默认情况下,在一张计算图上执行反向传播只能计算一次,再次调用backward方法将报错。
2.中间节点的梯度保存
在默认情况下,我们只能计算叶节点的导数值。
x=torch.tensor(1,requires_grad=True)
y=x**2
z=y**2
z.backward()
#y.grad#中间节点的梯度值不会被保存,会报错
x.grad#tensor(4.)
若想保存中间节点的梯度,我们可以使用retain_grad方法:
x=torch.tensor(1.0,requires_gard=True)
y=x**2
y.retain_grad()
z=y**2
z.backward()
y# tensor(1., grad_fn=<PowBackward0>)
y.grad# tensor(2.)
3.阻止计算图追踪
在默认情况下,只要初始张量是可微分向量,系统就会自动追踪其相关运算,并保存在动态图计算图关系中,我们也可以通过grad_fn来查看记录的函数关系。
x=torch.tensor(1.,requires_grad=True)
y=x**2
y.grad_fn## <PowBackward0 at 0x7fe8103ba160>
with torch.no_grad():
z=y**2
z# tensor(1.)
z.requires_grad# False
y# tensor(1., grad_fn=<PowBackward0>)
detach()此方法的原理是创建一个不可导的相同张量来阻止计算图的追踪
x=torch.tensor(1.,requires_grad=True)
y=x**2
y1=y.detach()
z=y1**2
y#tensor(1., grad_fn=<PowBackward0>)
y1# tensor(1.)
z# tensor(1.)
4.识别叶节点
由于叶节点较为特殊,在默认情况只能计算叶节点的导数值,我们可以用is_leaf属性查看张量是否是叶节点。
x=torch.tensor(1.,requires_grad=True)
y=x**2
y1=y.detach()
x.is_lead#True
y.is_leaf#False
注意,任何一个新创建的张量,无论是否可导、是否加入计算图,都是可以是叶节点。
y1.is_leaf#True
torch.tensor([1]).is_leaf#True
叶节点一定是新的张量,但是不一定可以导















 2679
2679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









