







文章目录
一、PyTorch环境的配置及安装
1.官网下载最新版Anaconda,完成后打开Anaconda Prompt,显示(base)即安装成功
2.conda create -n pytorch python=3.6建立一个命名为pytorch的环境,且环境python版本为3.6
3.conda activate pytorch激活并进入pytorch这个环境;linux:source activate pytorch
4.pip list来查看环境内安装了哪些包,可以发现并没有我们需要的pytorch
5.打开PyTorch官网,直接找到最新版pytorch指令conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch(无脑最新版就完事了。。。。老版本调了半天,最后还出问题了),打开pytorch环境,输入指令下载安装
6.检验是否安装成功。输入python,import torch不报错即pytorch安装成功。输入torch.cuda.is_available(),若返回True即机器显卡是可以被pytorch使用的(如失败,建议去英伟达官网下载更新驱动程序,并删除环境,使用各种最新版重新安装)。
7.linux服务器安装时出现环境安装不到conda/envs下,而在.conda下,进行如下操作

other:conda info -e (查看所有的虚拟环境)
删除环境:
第一步:首先退出环境
conda deactivate
第二步:删除环境
conda remove -n 需要删除的环境名 --all
rm -rf + 文件名 删除文件夹
df -h查看linux系统各分区的情况
nohup 命令 > 文件 2>&1 & # 使模型在后台训练 exit退出黑窗口
1.> 会重写文件,如果文件里面有内容会覆盖,没有则创建并写入。
2.>> 将内容追加到文件中,即如果文件里面有内容会把新内容追加到文件尾,如果文件不存在,就创建文件
kill -9 PID # 关闭特定进程
tar -xvf #解压tar包
查看当前文件夹的大小:du -ah
查看当前文件夹下面各个文件夹的大小:du -ah --max-depth=1
anaconda下的pkgs怎么清理:conda clean -a
ps u pid 查询显卡谁在使用
sudo chmod -R 777 myResources 修改文件的权限为所有用户拥有最高权限
pip install *** -i https://pypi.tuna.tsinghua.edu.cn/simple 镜像加速安装
ps -f -p 26359 可以看到进程26359在跑训练
cp -r /TEST/test1 /TEST/test2 复制文件夹
Defaulting to user installation because normal site-packages is not writeable : python3 -m pip install requests
fuser -v /dev/nvidia* nvidia-smi 无进程占用GPU,但GPU显存却被占用了
二、Pycharm、jupyter的安装
1. Pycharm
1.pycharm官网下载安装
2.新建项目(lean_pytorch),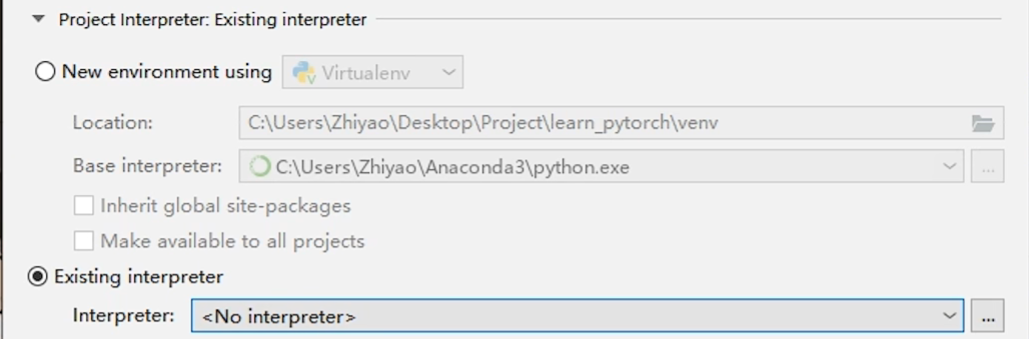
点击已存在的编译器,点进去寻找刚刚我们安装好的环境。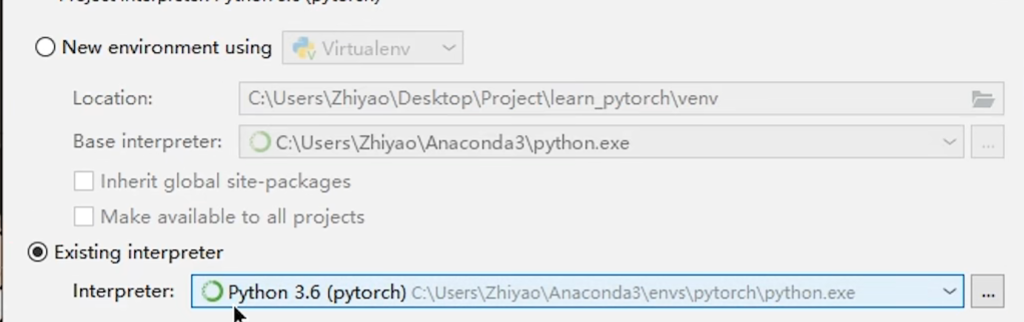
导入成功。
2.jupyter
- 安装好anaconda后无需再次安装。
- jupyter默认安装在base环境中,所以我们需要在pytorch环境中安装jupyter.
- 进入pytorch环境,输入
conda install nb_conda安装juypter - 安装完成后输入
juypter notebook即可打开。 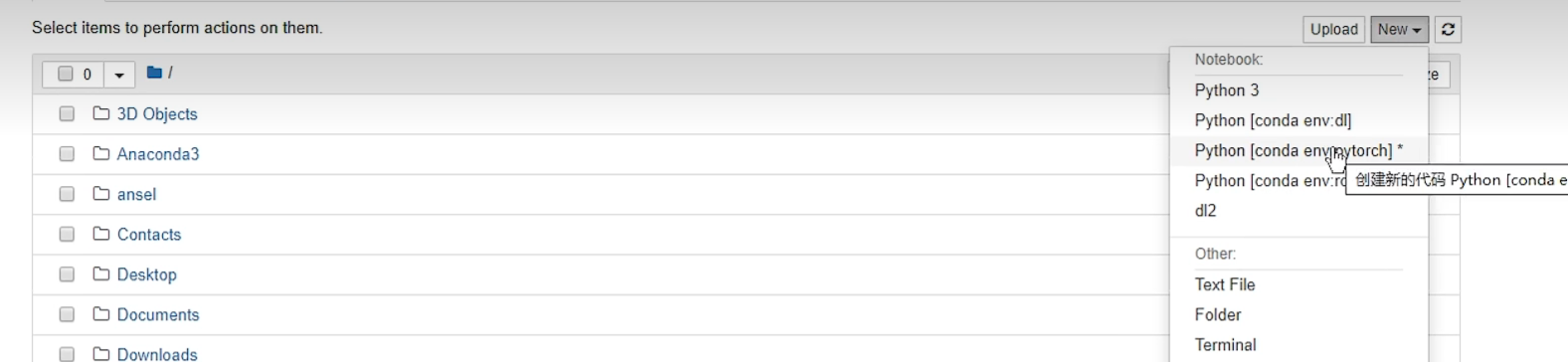
新建pytorch环境下的juypter文件。- 输入
import torch,torch.cuda.is_available(),返回TRUE即安装成功。
三、Python学习中的两大法宝函数(help、dir)
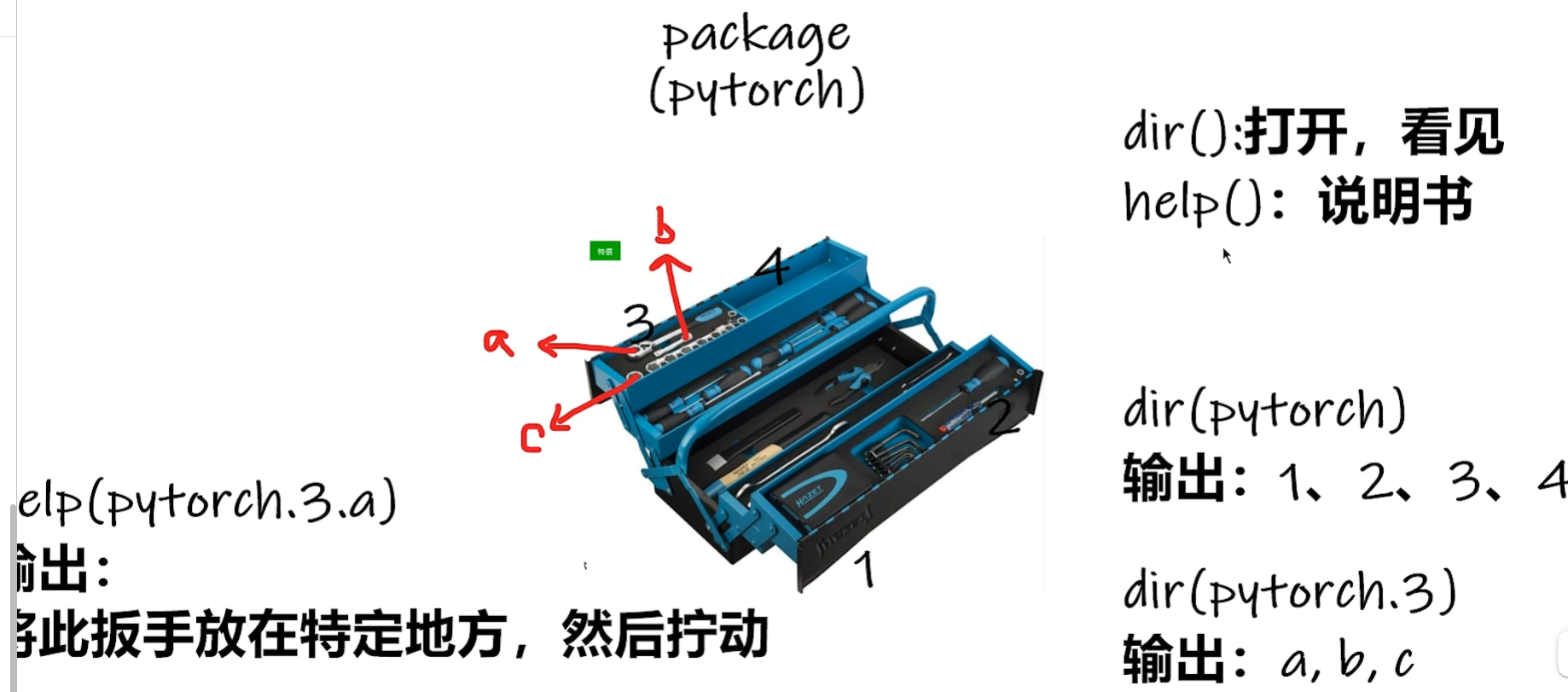
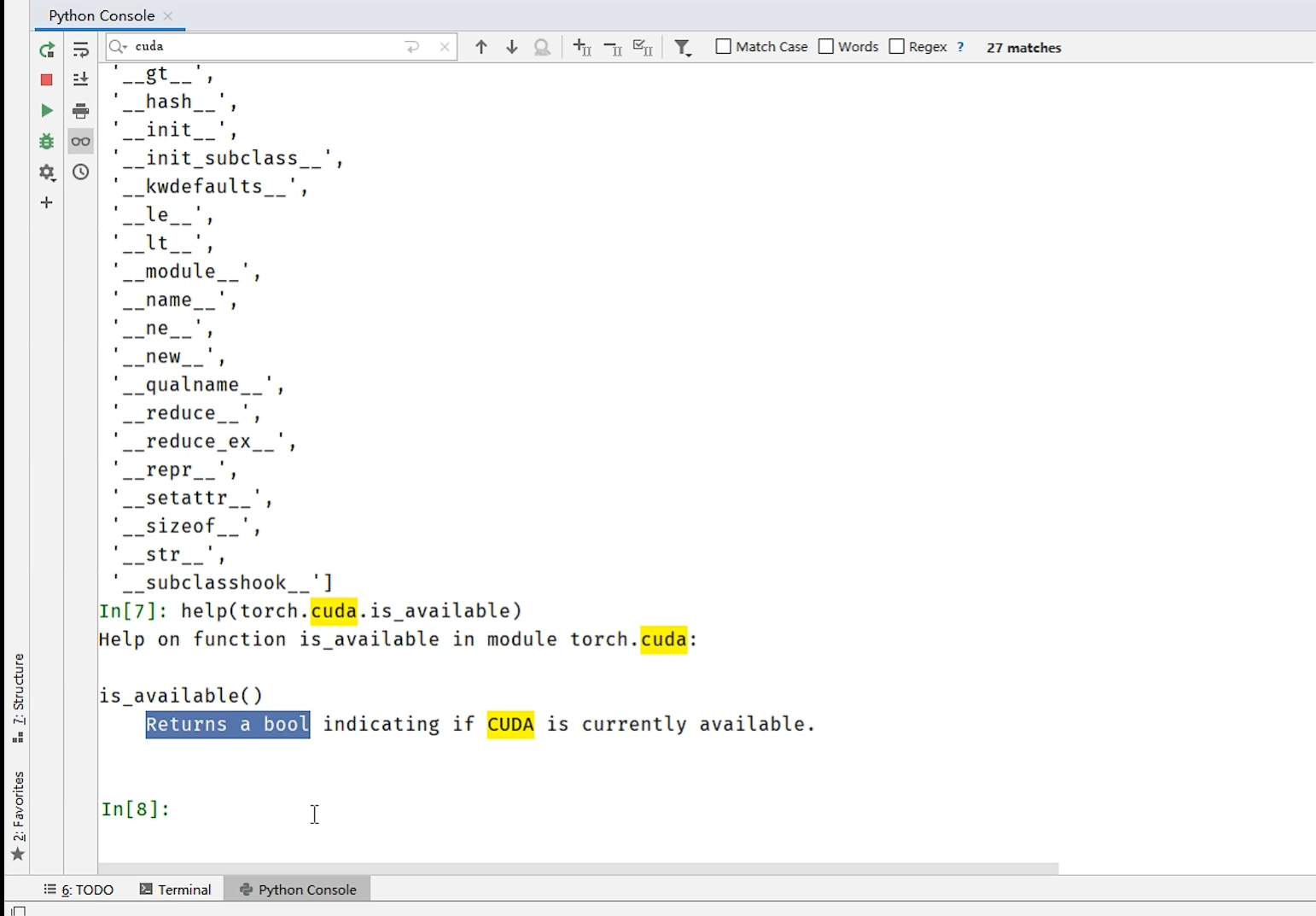
进入pycharm的python console,输入dir(torch),dir(torch.cuda),dir(torch.cuda.is_available()),help(torch.cuda.is_available)。
四、加载数据(Dataset)
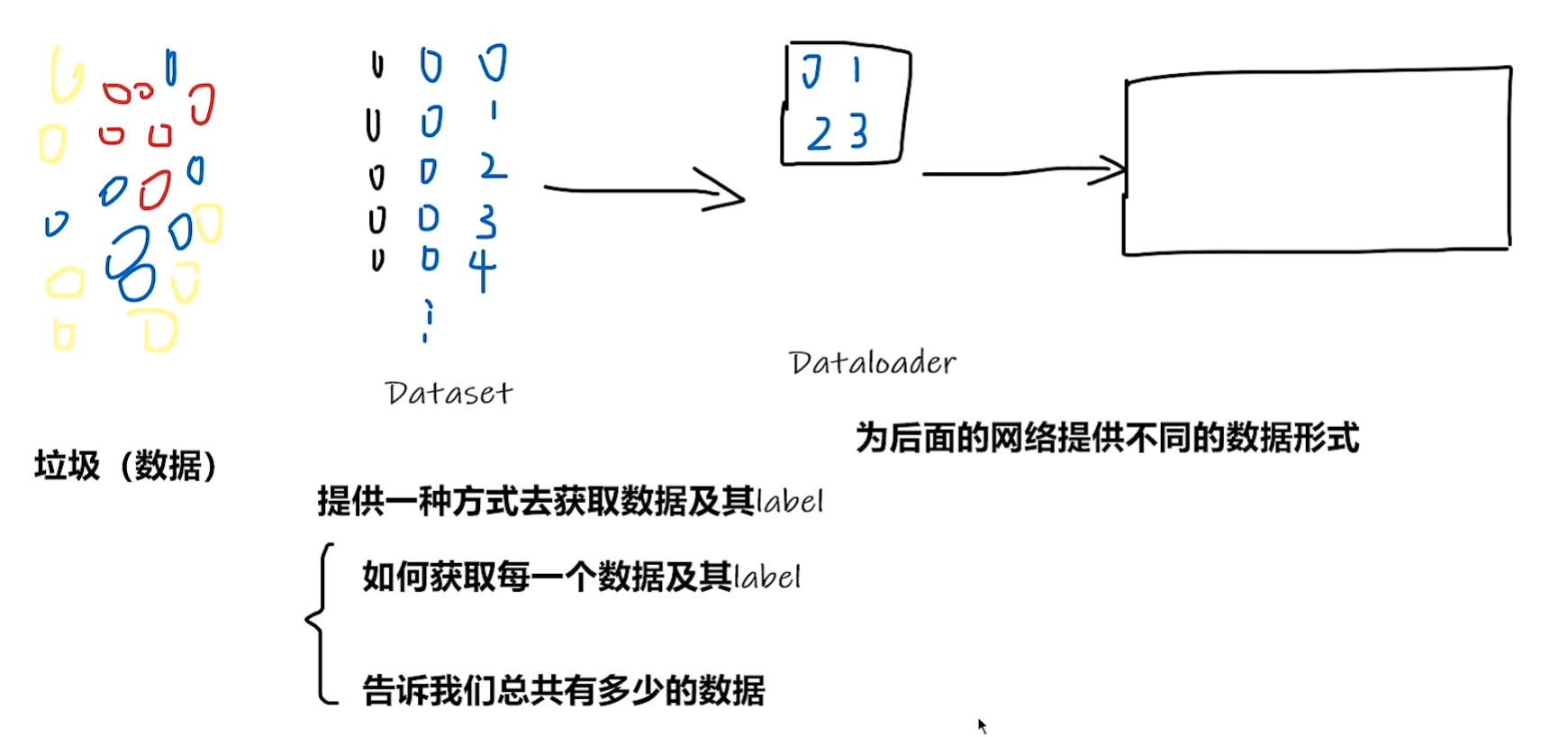

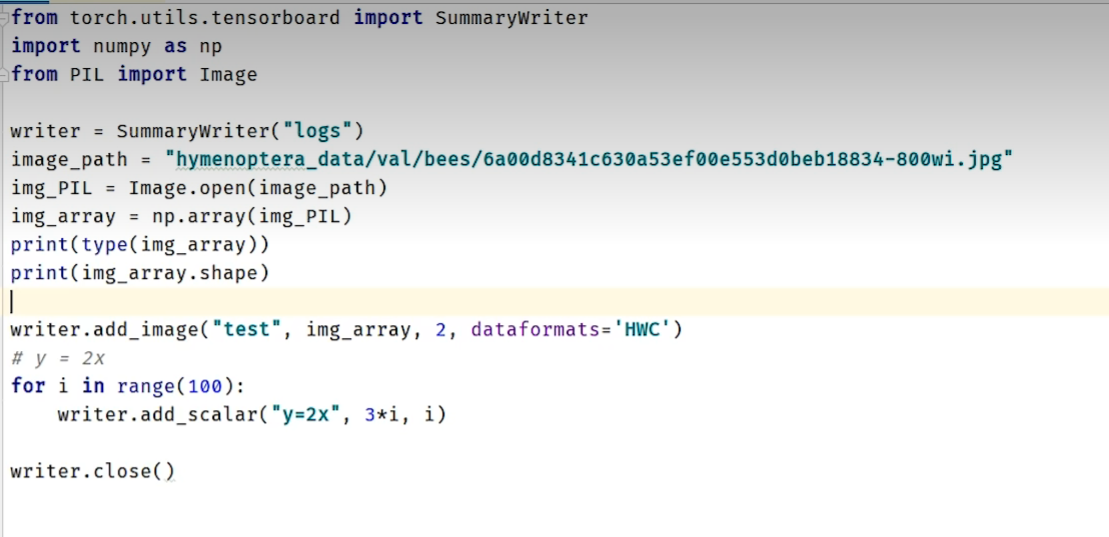
from torch.utils.data import Dataset, DataLoader
import numpy as np
from PIL import Image
import os
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
from torchvision.utils import make_grid
writer = SummaryWriter("logs")
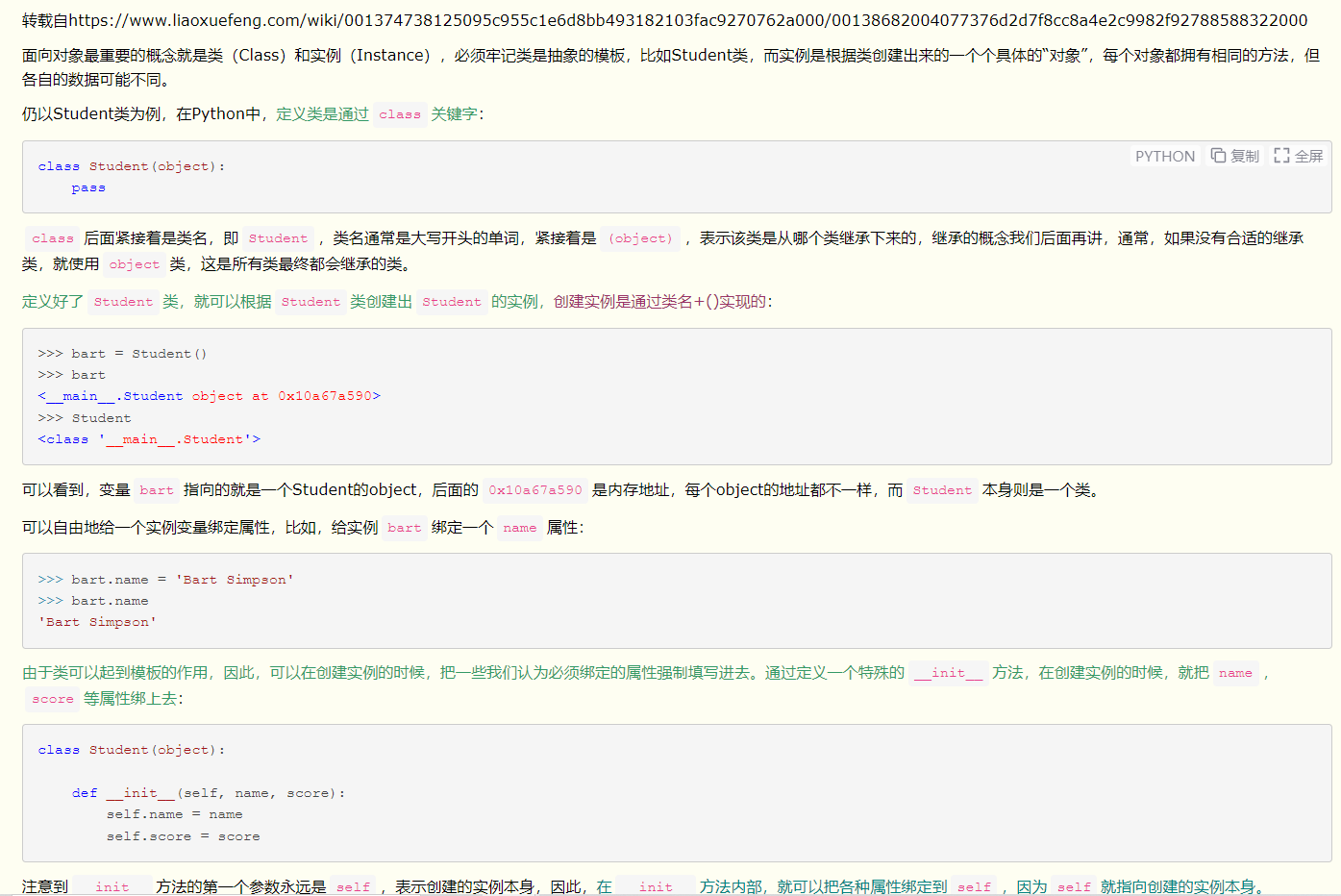
class MyData(Dataset):
def __init__(self, root_dir, image_dir, label_dir, transform):
self.root_dir = root_dir
self.image_dir = image_dir
self.label_dir = label_dir
self.label_path = os.path.join(self.root_dir, self.label_dir)
self.image_path = os.path.join(self.root_dir, self.image_dir)
self.image_list = os.listdir(self.image_path)
self.label_list = os.listdir(self.label_path)
self.transform = transform
# 因为label 和 Image文件名相同,进行一样的排序,可以保证取出的数据和label是一一对应的
self.image_list.sort()
self.label_list.sort()
def __getitem__(self, idx):
img_name = self.image_list[idx]
label_name = self.label_list[idx]
img_item_path = os.path.join(self.root_dir, self.image_dir, img_name)
label_item_path = os.path.join(self.root_dir, self.label_dir, label_name)
img = Image.open(img_item_path)
with open(label_item_path, 'r') as f:
label = f.readline()
# img = np.array(img)
img = self.transform(img)
sample = {'img': img, 'label': label}
return sample
def __len__(self):
assert len(self.image_list) == len(self.label_list)
return len(self.image_list)
if __name__ == '__main__':
transform = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor()])
root_dir = "dataset/train"
image_ants = "ants_image"
label_ants = "ants_label"
ants_dataset = MyData(root_dir, image_ants, label_ants, transform)
image_bees = "bees_image"
label_bees = "bees_label"
bees_dataset = MyData(root_dir, image_bees, label_bees, transform)
train_dataset = ants_dataset + bees_dataset
# transforms = transforms.Compose([transforms.Resize(256, 256)])
dataloader = DataLoader(train_dataset, batch_size=1, num_workers=2)
writer.add_image('error', train_dataset[119]['img'])
writer.close()
# for i, j in enumerate(dataloader):
# # imgs, labels = j
# print(type(j))
# print(i, j['img'].shape)
# # writer.add_image("train_data_b2", make_grid(j['img']), i)
#
# writer.close()
五、TensorBorad的使用
安装tensorborad:pip install tensorboard
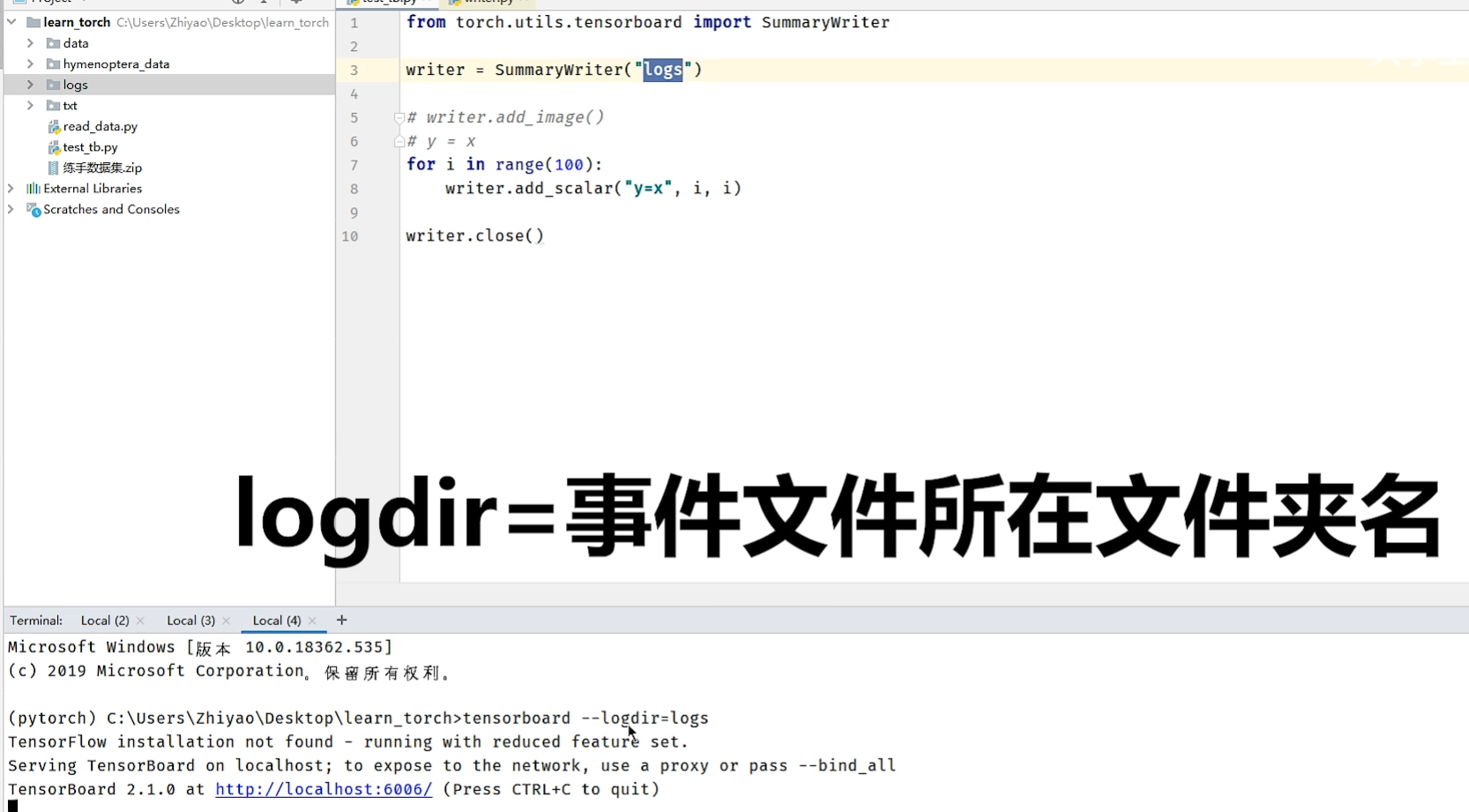
更改端口:

六、Transformer
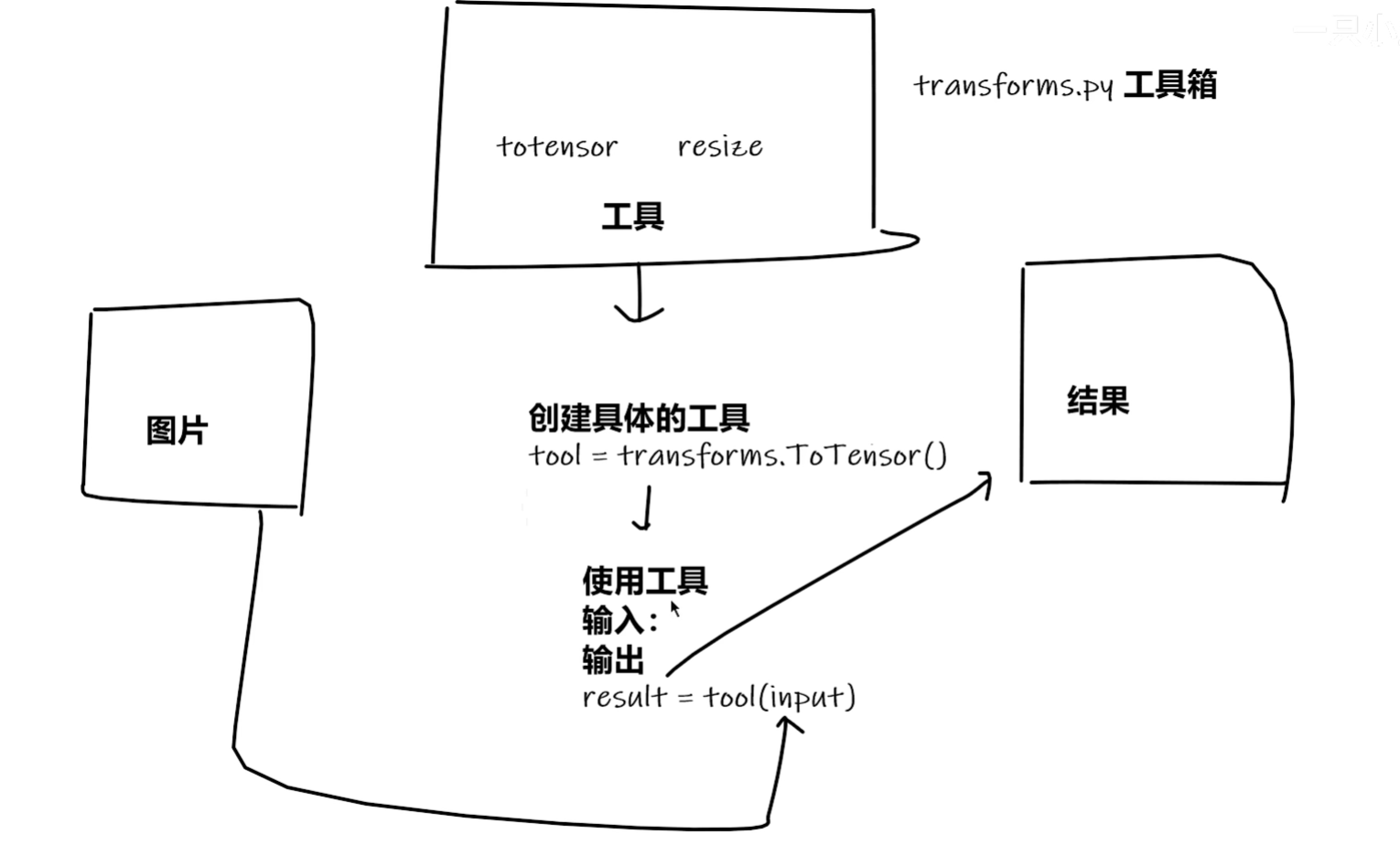
进入structure
1.compose
将几个步骤合为一个
2.toTensor
将PIL和numpy类型的图片转为Tensor(可用于训练)

__call__的使用: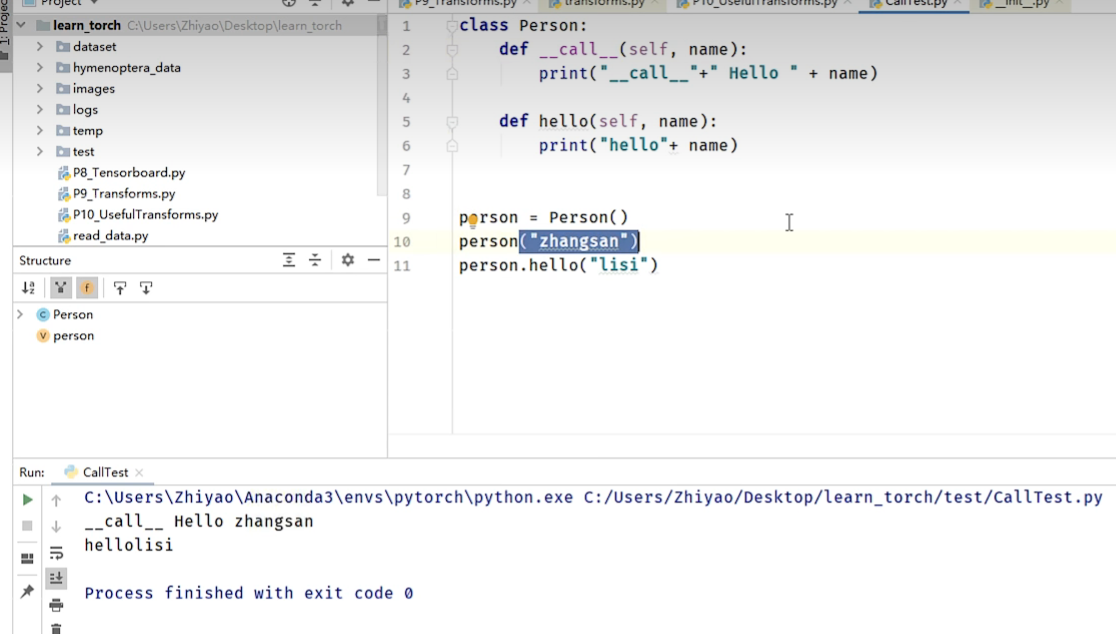
ctrl+p提示函数参数
3.Normalize
讲一个tensor类型进行归一化

4.Resize
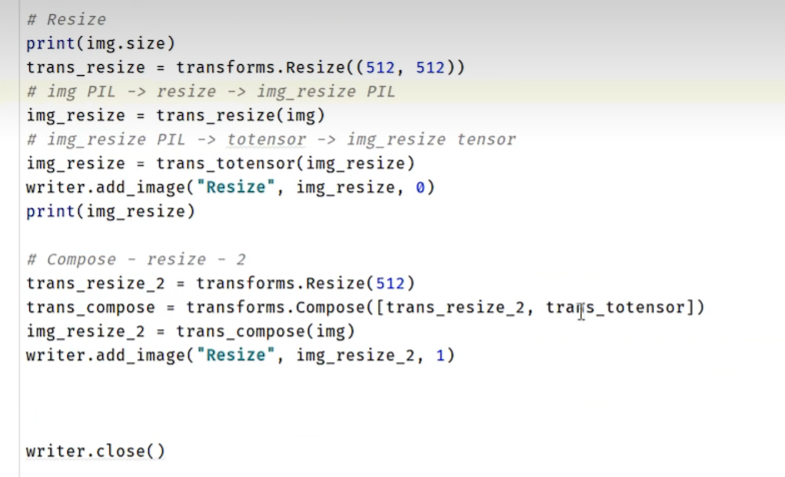
tips:
七、torchvision中数据集的使用
torchvision 是PyTorch中专门用来处理图像的库。这个包中有四个大类。
torchvision.datasets
torchvision.models
torchvision.transforms
torchvision.utils
这里主要介绍前三个。
1.torchvision.datasets
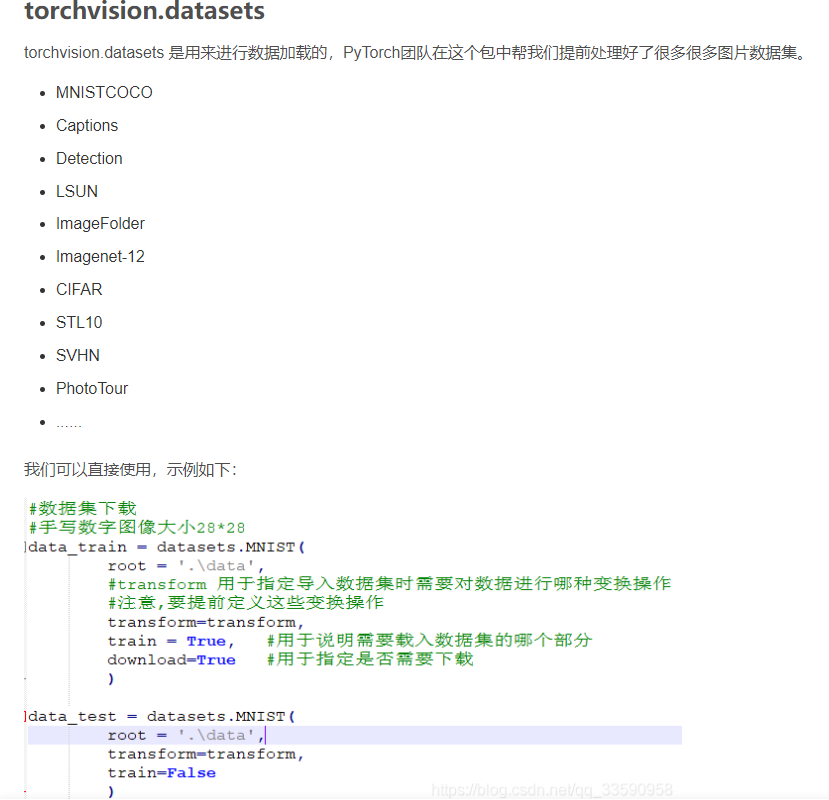
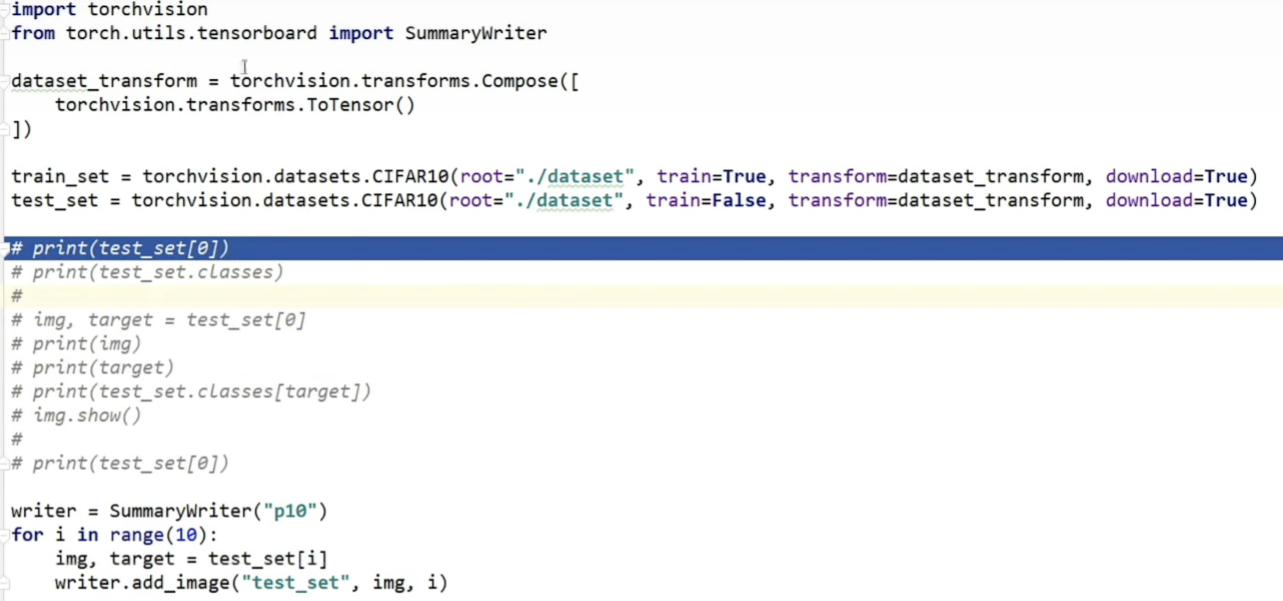
八、dataloader
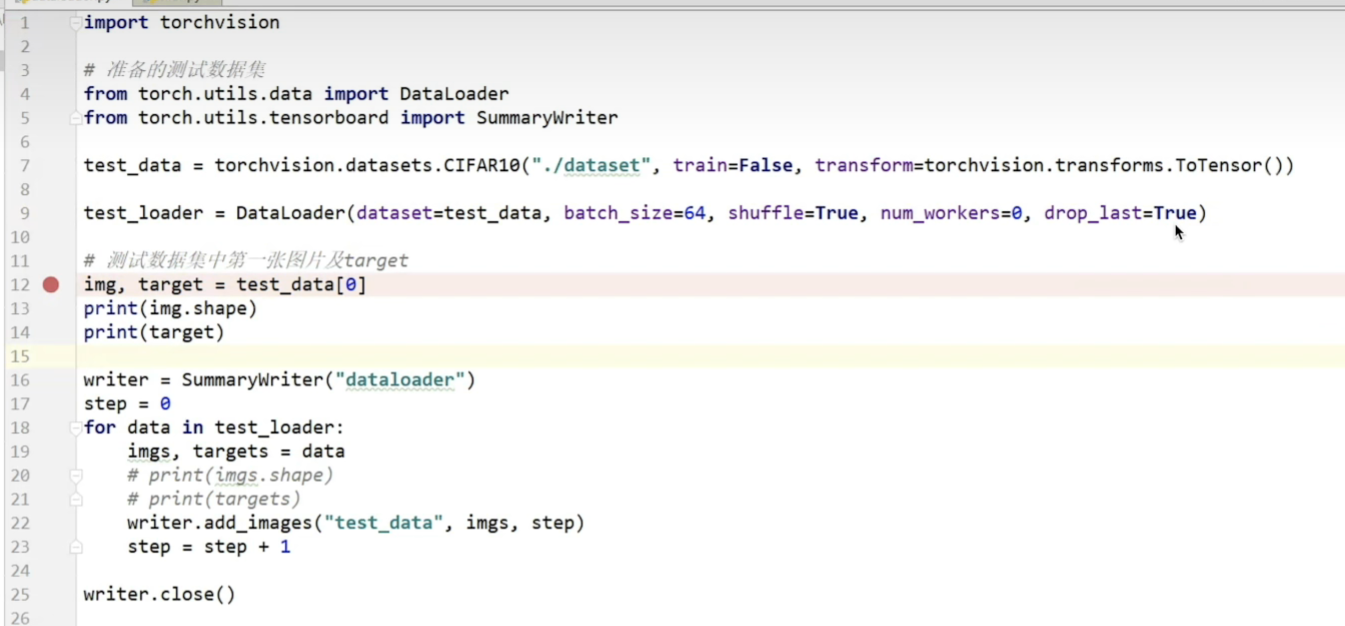
drop_last=true,舍去最后的余数图片,如上半张图片将会舍去,下半张图片为FALSE
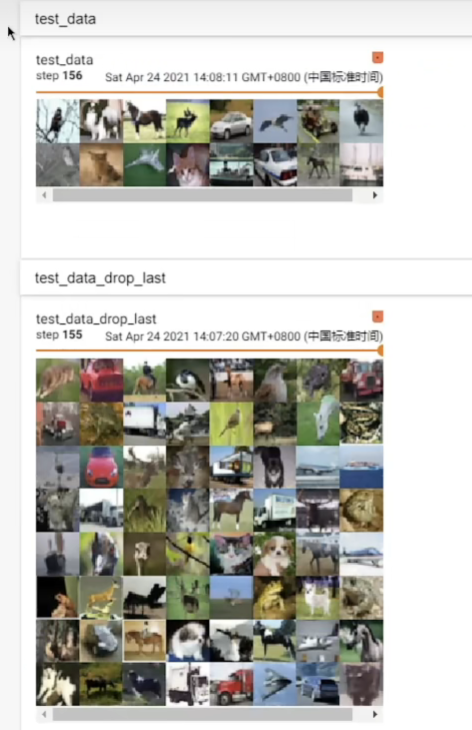
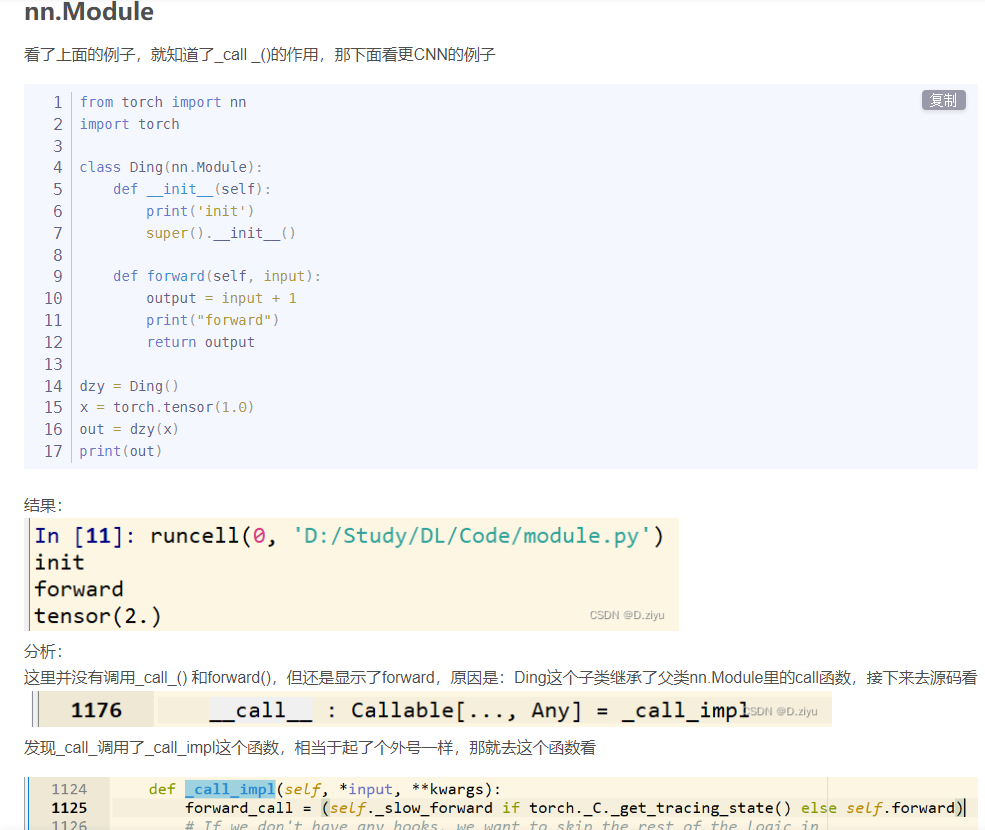
九、nn.module
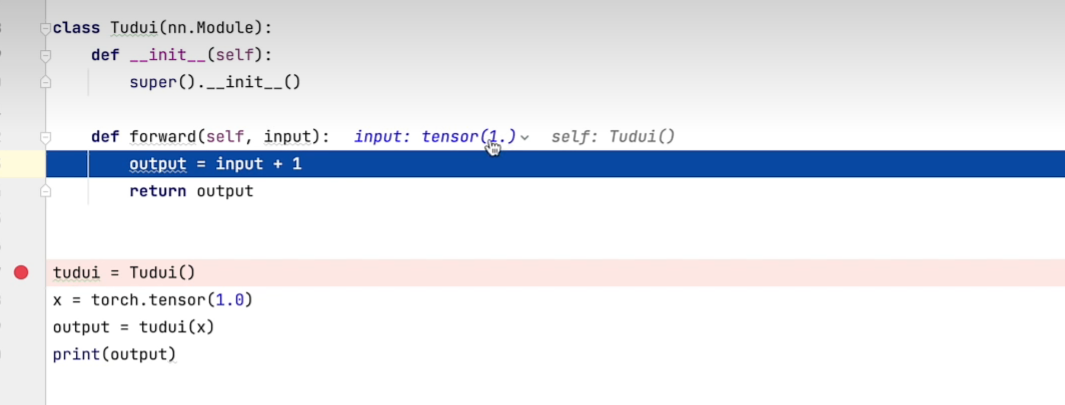
十、卷积操作


十一、卷积层
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
imgs, targets = data
output = tudui(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30]
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1
十二、池化层
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpool1(input)
return output
tudui = Tudui()
writer = SummaryWriter("../logs_maxpool")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
十三、非线性激活
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
dataset = torchvision.datasets.CIFAR10("../data", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
tudui = Tudui()
writer = SummaryWriter("../logs_relu")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, global_step=step)
output = tudui(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()
十四、线性层
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
output = torch.flatten(imgs)
print(output.shape)
output = tudui(output)
print(output.shape)
十五、Sequential
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
print(tudui)
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
writer = SummaryWriter("../logs_seq")
writer.add_graph(tudui, input)
writer.close()
十六、损失函数和反向传播
1.损失函数
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
print("ok")
2.反向传播及优化
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
scheduler = StepLR(optim, step_size=5, gamma=0.1)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
scheduler.step()
running_loss = running_loss + result_loss
print(running_loss)
十七、现有模型的使用及修改
import torchvision
# train_data = torchvision.datasets.ImageNet("../data_image_net", split='train', download=True,
# transform=torchvision.transforms.ToTensor())
from torch import nn
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
train_data = torchvision.datasets.CIFAR10('../data', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_true)
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
十八、网络模型的保存和修改
1.保存
import torch
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1,模型结构+模型参数
torch.save(vgg16, "vgg16_method1.pth")
# 保存方式2,模型参数(官方推荐)
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
# 陷阱
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
torch.save(tudui, "tudui_method1.pth")
2.读取
import torch
from model_save import *
# 方式1-》保存方式1,加载模型
import torchvision
from torch import nn
model = torch.load("vgg16_method1.pth")
# print(model)
# 方式2,加载模型
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
# model = torch.load("vgg16_method2.pth")
# print(vgg16)
# 陷阱1
# class Tudui(nn.Module):
# def __init__(self):
# super(Tudui, self).__init__()
# self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
#
# def forward(self, x):
# x = self.conv1(x)
# return x
model = torch.load('tudui_method1.pth')
print(model)
只用方式2!!!!
十九、完整的模型训练套路

import torchvision
from my_model import *
from torch.utils.tensorboard import SummaryWriter
#准备数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#创建网络模型
tudui = Tudui()
#损失函数
loss_fn = nn.CrossEntropyLoss()
#优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate)
#训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 10
#添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("-----------第{}轮训练开始-----------".format(i+1))
#训练步骤开始
tudui.train()
for data in train_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
total_test_loss += loss
accuracy = (outputs.argmax(1)==targets).sum()
total_accuracy += accuracy
print("整体集上的Loss:{}".format(total_test_loss))
print("整体数据集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1
torch.save(tudui,"tudui_{}.pth".format(i))
#torch.save(tudui.state_dict(),"tudui_{}".format(i))
print("模型已保存")
writer.close()
二十、利用GPU训练

import torchvision
from torch.utils.tensorboard import SummaryWriter
import torch
import time
#准备数据集
from torch import nn
from torch.utils.data import DataLoader
device = torch.device("cuda")
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
tudui = Tudui()
tudui=tudui.to(device)
#损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
#优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate)
#训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 10
#添加tensorboard
writer = SummaryWriter("../logs_train")
start_time=time.time()
for i in range(epoch):
print("-----------第{}轮训练开始-----------".format(i+1))
#训练步骤开始
tudui.train()
for data in train_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time-start_time)
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
total_test_loss += loss
accuracy = (outputs.argmax(1)==targets).sum()
total_accuracy += accuracy
print("整体集上的Loss:{}".format(total_test_loss))
print("整体数据集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1
torch.save(tudui,"tudui_{}.pth".format(i))
#torch.save(tudui.state_dict(),"tudui_{}".format(i))
print("模型已保存")
writer.close()
二十一、完整的模型验证套路
# -*- coding: utf-8 -*-
# 作者:小土堆
# 公众号:土堆碎念
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "../imgs/airplane.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB') # 因为png格式是四通道,除了RGB三通道外,还有一个透明度通道,
# 调用convert保留其颜色通道。当然,如果图片本来就是三个颜色通道,经此操作,不变。加上这一步可以适应png jpg各种格式的图片
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = torch.load("tudui_29_gpu.pth", map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
总结
。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









