










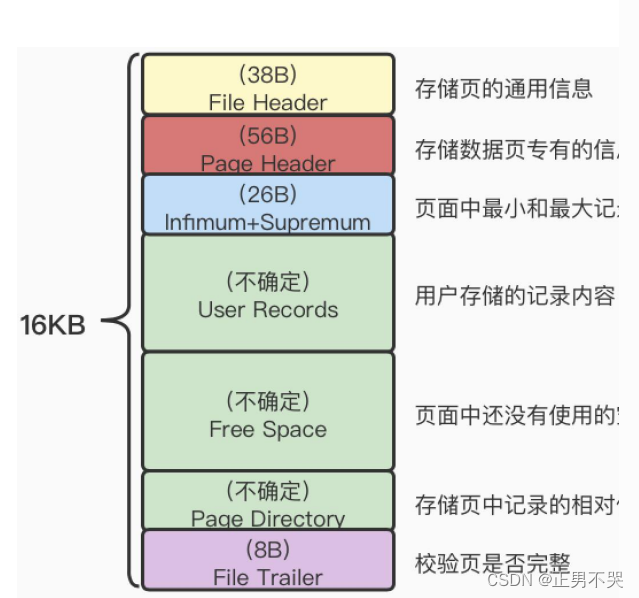
Pag–页
InnoDB采取页的方式作为磁盘和内存之间交互的基本单位。一个页的大小一般是16KB。
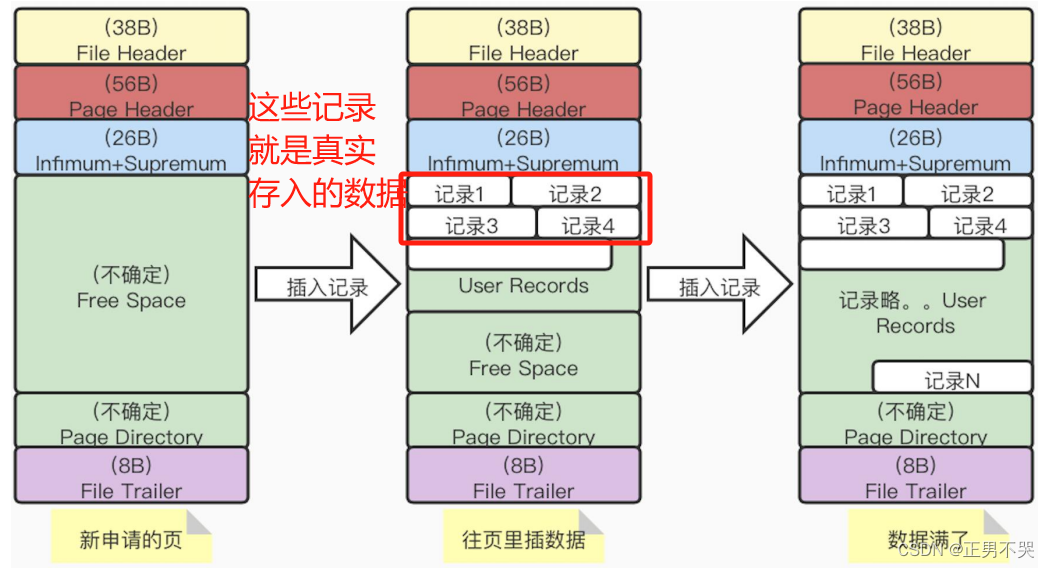
我们把存放表中数据记录的页,称为索引页or数据页。

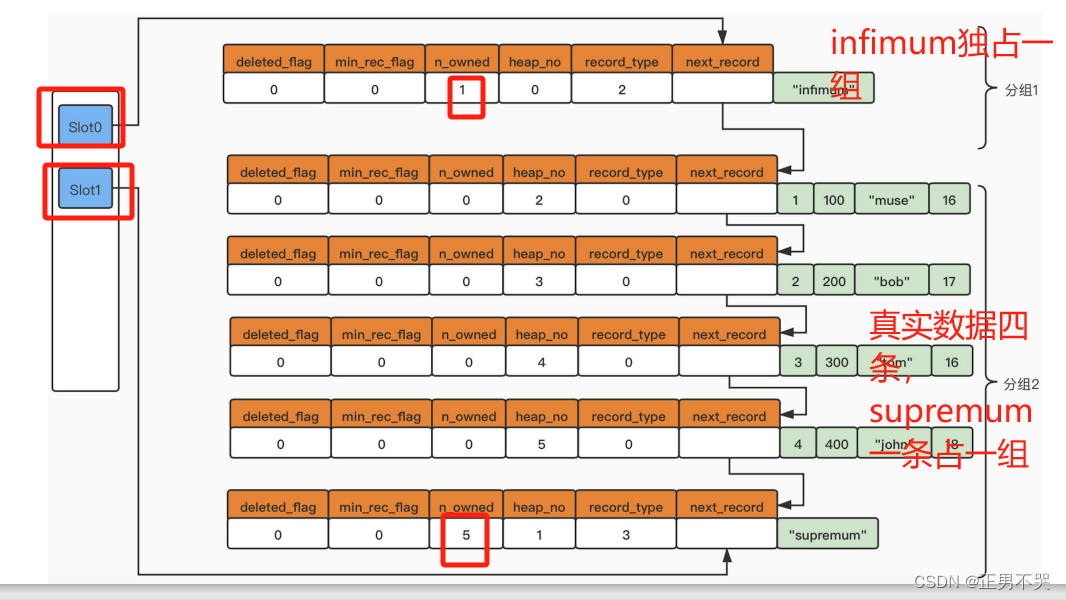
deleted_flag:逻辑删除标记(0:未删除 1:已删除 )
min_rec_flag:B+树中每层非叶子节点中的最小的目录项记录,都会添加该标记。
n_owned:一个页面被分若干组后,“带头大哥”用于保存组中所有的记录条数。
heap_no:表示当前记录在页面堆中的相对位置。
record_type:表示当前的记录类型。
① 0:普通记录
② 1: B+树非叶子节点的目录项记录
③ 2:表示Infimum记录
④ 3:表示Supremum记录
next_record:表示下一条记录的相对位置,也就是链表。这个属性非常重要。它表示从
当前记录的真实数据到下一条记录的真实数据的距离。
Page Directory概 述
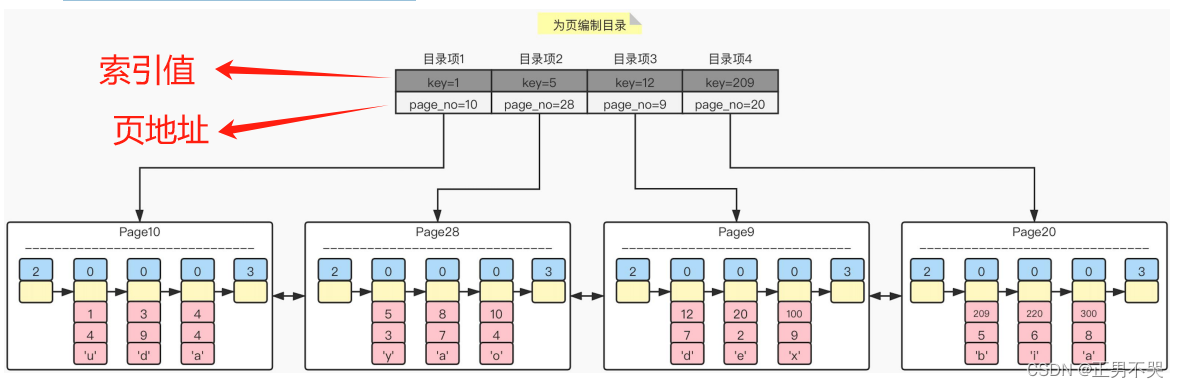
记录在页中是按照主键值从小到大的顺序串联成为一个单向链表,因此查询也只能以头节点开始逐一向后查询,但是如果数据量很大,那么性能就无法保证了。针对这个问题,InnoDB采取了图书目录的解决方案,即:PageDirectory。
分组规则如下所示:
① 对于Infimum记录所在的分组只能有1条记录。
② 对于Supremum记录所在的分组只能在1~8条记录之间。
③ 剩下的其他记录所在的分组只能在4~8条记录之间。
分组步骤如下:
① 初始情况下,一个数据页中只有Infimum记录和Supremum记录这两条,所以分为两个组。
② 之后每当插入一条记录时,都会从页目录中找到对应记录的主键值比待插入记录的主键值大,并且差值最小的槽,然后把该槽对应的n_owned加1。
③ 当一个组中的记录数等于8时,当再插入一条记录的时候,会将组中的记录拆分成两个组(一个组中4条记录,另一个组中5条记录)。并在拆分过程中,会在Page Directory中新增一个槽,并记录这个新增分组中最大的那条记录的偏移量。
对于在页中查询过程总结一下:
如果我们要查询某一条记录,需要通过索引(主键索引/二级索引)确认记录是在哪一页,然后通过page directory页目录去查找所在的组slot。采用二分法确定记录所在的组,因为组中记录的是当前组的最大id值(主键值)并且页是一个是按照id值(主键值)从小到大的顺序串联成的一个单向链表,所以需要找到当前组的前一个组(组类似一个集合,不是单向链表),然后通过next_record去遍历记录所在组的所有记录就可以找到目标记录。
B树&B+树
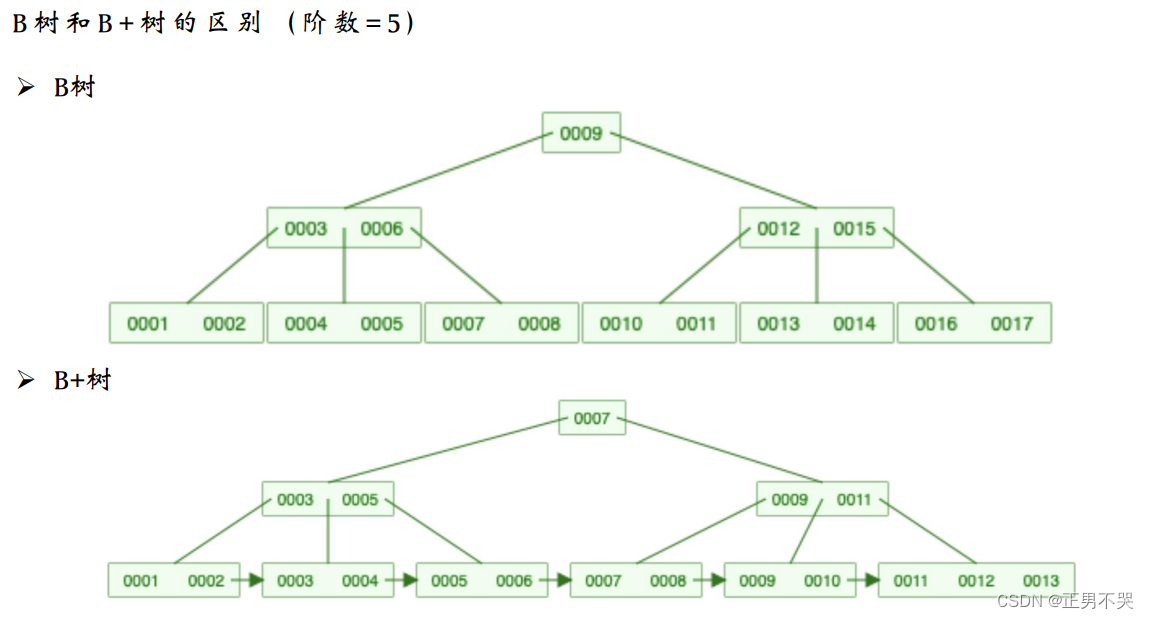
B+树的特点
【与B树相同点】
一个节点可以存储多个元素。
与B树一样,叶子节点是有序的。
每个节点中的元素,也都按照从小到大的顺序排列,即:左小右大。
所有叶子节点都位于同一层,或者说根节点到每个叶子节点的高度都相同。
【与B树不同点】
B+树的叶子节点是有单向指针的,其中:MySQL中采用的是双向指针。
B+树的非叶子节点的元素是与叶子节点有冗余的(叶子节点是全量元素)
Index–索引
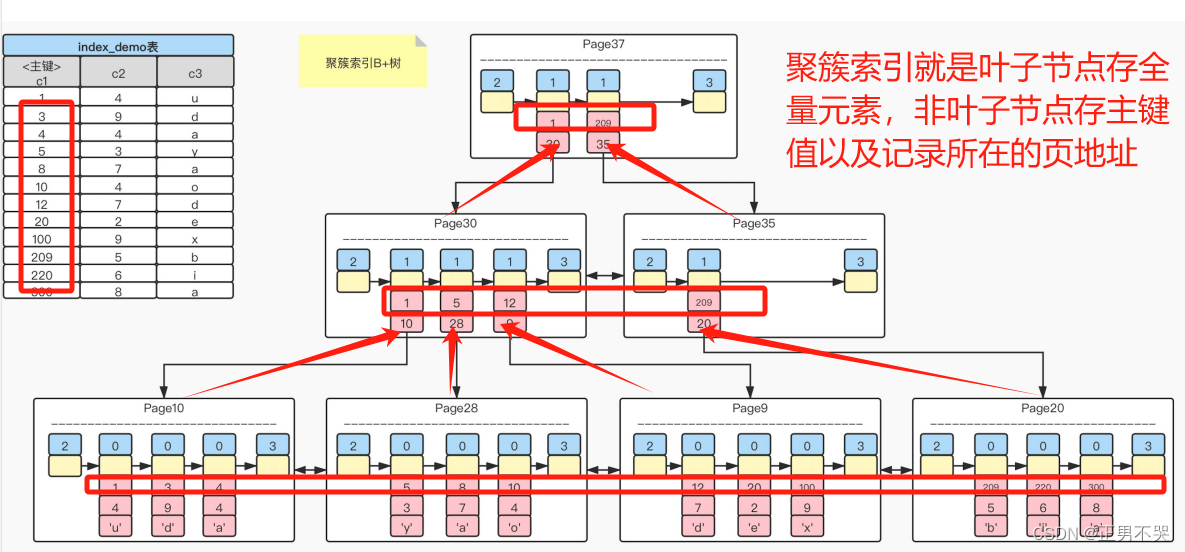
当记录越来越多,创建的页也会越来越多,如果仅通过链表方式遍历查询,性能会出现很大问题。如何解决呢? 采用B+树结构,即:叶子节点里存储完整的数据(数据页),非叶子节点存储主键索引(索引页)
聚簇索引
主键就是聚簇索引,修改聚簇索引其实就是修改主键。
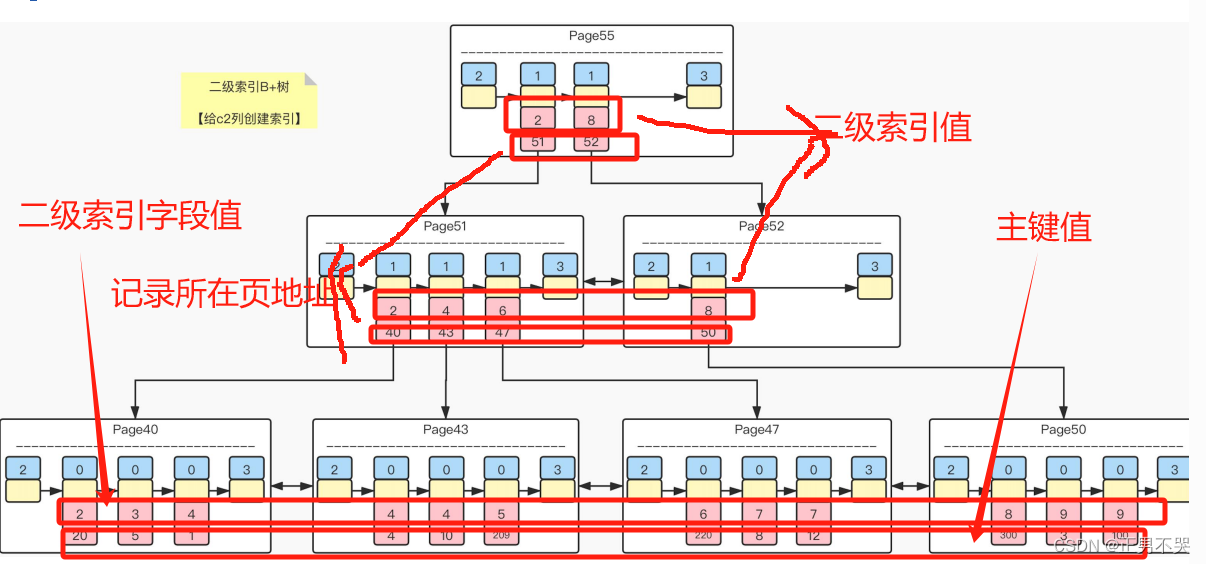
非聚簇索引/二级索引–非主键
除主键外字段作为索引就是二级索引,二级索引在叶子节点上不是全量元素而是存索引值以及对应的主键值。当通过二级索引字段查询全量字段时,先通过二级索引找到记录对应的主键值,然后通过主键值聚簇索引查询到全量元素。
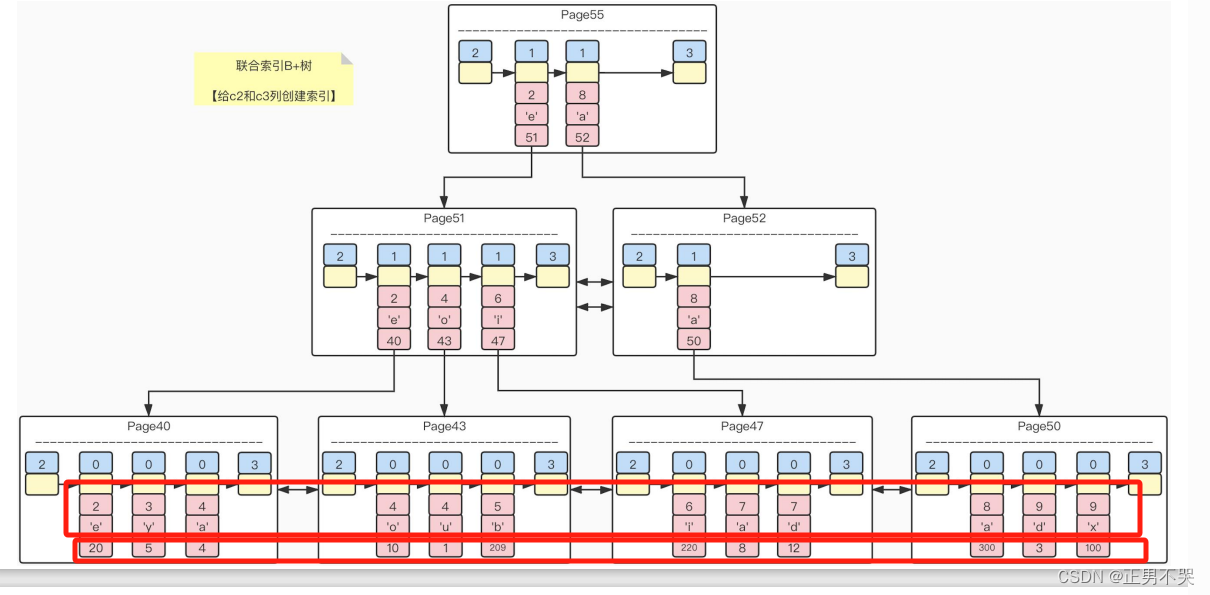
联合索引
联合索引就是多个字段同时作为索引–多列,叶子节点存作为索引的多个字段元素以及主键。会自动根据索引值按照顺序排列。当根据联合索引的字段去查询时,比如c1,c2字段作为联合索引。先查询c1索引值,再查询c2索引值,如果都没有就不存在数据。页内的记录是单向链表只能查找下一个,但是页与页之间是一个双向链表,可以查询到当前页的上一页记录。
Buffer pool–缓冲池
缓冲池概念
为了缓存磁盘中的页,MySQL服务器启动时就向操作系统申请了一片连续的内存空间,他们给这片内存起名为Buffer Pool(缓冲池)。默认Buffer Pool只有128M,可以在启动服务器的时候配置innodb_buffer_pool_size(单位为字节)启动项来设置自定义缓冲池大小。Buffer Pool对应的一片连续的内存被划分为若干个页面,默认也是16KB,该页面称为缓冲页。为了更好的管理Buffer Pool中的这些缓冲页,InnoDB为每个缓冲页都创建了控制块,它与缓冲页是一一对应的。
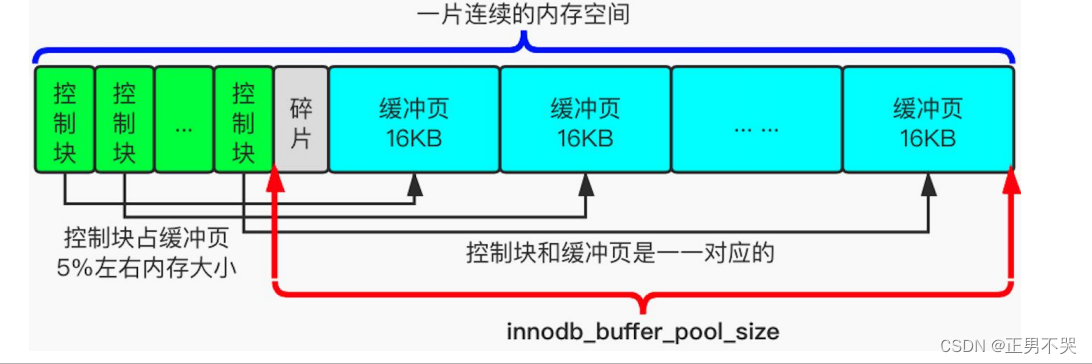
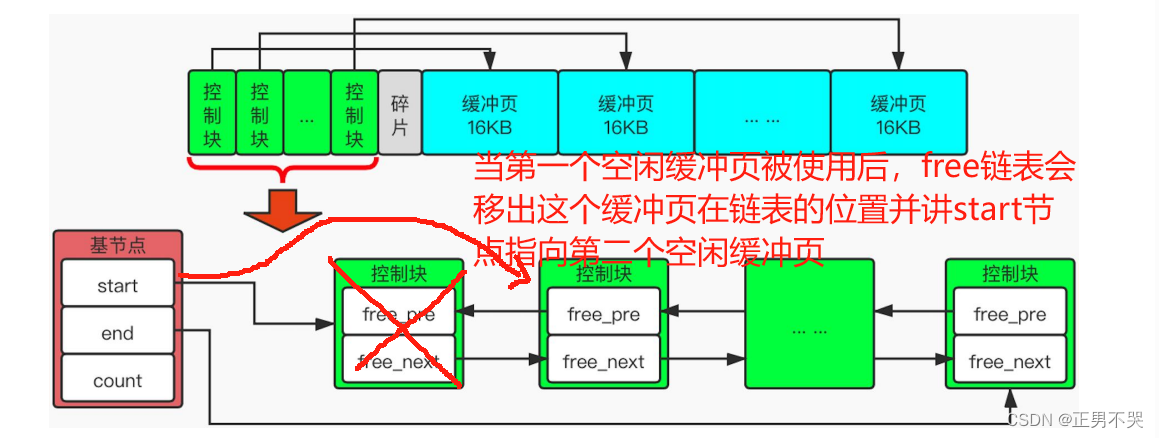
free链表
free链表又叫空闲链表,通过它可以知道缓冲池内有哪些缓冲页是空白的可用可分配的。
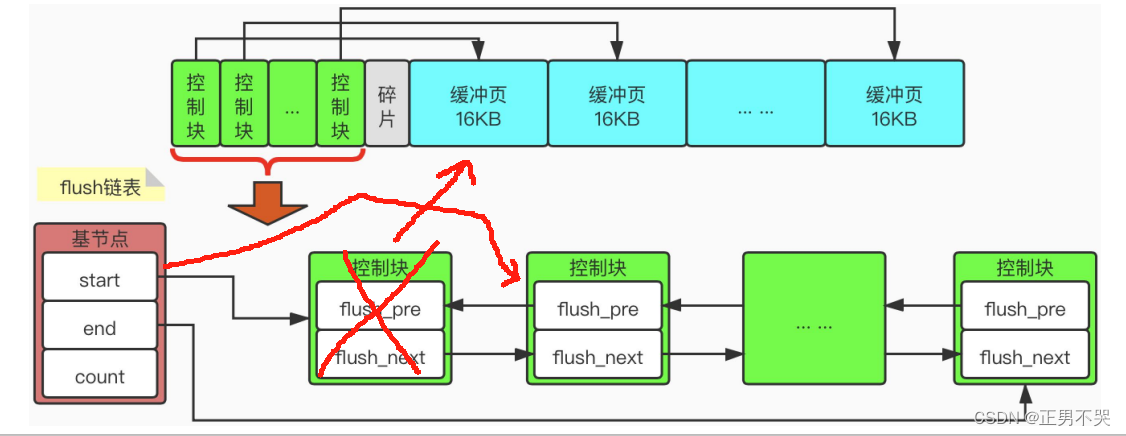
flush链表
flush链表存放的是脏页,如果我们修改了Buffer Pool中某个缓冲页的数据,那么它就与磁盘上的页不一致了,这样的缓冲页也被称之为脏页(dirty page)。为了性能问题,我们每次修改缓冲页后,并不着急立刻把修改刷新到磁盘上,而是将被修改过的缓冲页对应的控制块作为节点加入到这个链表中,该链表也被称为flush链表。
Flush链表刷新方式有两种:
【1】从flush链表中刷新一部分页面到磁盘
后台线程会根据当时系统的繁忙程度确定刷新速率,定时从flush链表中刷新一部分页面到
磁盘。——即:BUF_FLUSH_LIST
有时后台线程刷新脏页的进度比较慢,导致用户准备加载一个磁盘页到Buffer Pool中时没
有可用的缓冲页。此时,就会尝试查看LRU链表尾部,看是否存在可以直接释放掉的未修
改缓冲页。如果没有,则不得不将LRU链表尾部的一个脏页同步刷新到磁盘(与磁盘交互
是很慢的,这会降低处理用户请求的速度)。——即:BUF_FLUSH_SINGLE_PAGE
【2】从LRU链表的冷数据中刷新一部分页面到磁盘
后台线程会定时从LRU链表的尾部开始扫描一些页面,扫描的页面数量可以通过系统变量
innodb_lru_scan_depth来指定,如果在LRU链表中发现脏页,则把它们刷新到磁盘。——
即:BUF_FLUSH_LRU
控制块里会存储该缓冲页是否被修改的信息,所以在扫描LRU链表时,可以很轻松地获取
到某个缓冲页是否是脏页的信息。















 183
183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









