







银行客户流失分析
摘要
摘要
随着互联网金融的异军突起,银行业的竞争愈加激烈,防止客户流失和挽留老客户成为各大银行关心的重要问题。本文首先根据已有数据集对各特征进行描述性统计分析,初步了解数据;之后进行数据预处理,包括数据清洗,数据变换、特征选择;再后用SVM、LR、朴素贝叶斯、决策树、RF、XGBoost、LM神经网络进行建模,通过不同性能度量,选出XGBoost为表现最好的模型并进行调参;最后,根据描述性统计和特征重要性为银行挽留客户提出建议。
关键词:客户流失;数据预处理;XGBoost;调参;建议
研究背景
银行客户流失是指银行的客户不再继续参与原业务、不再重复购买或者终止原先的产品或者服务。近年来,随着互联网金融的异军突起和传统银行业的竞争加剧,银行发展自身潜力、吸引优质顾客、防止客户流失就显得格外重要。研究表明,发展一位新客户所花费的成本要比维持一位老客户的成本多达5到6倍。所以说,在客户流失后,如果企业要去重新发展新客户所需要的成本是巨大的,且大多数新用户产生的利润不如老用户。因此,不管是哪个行业都越来越重视客户流失管理。预测潜在的流失客户、有效挽留和关怀客户是各个企业关心的重要问题之一。
研究目标
1、通过确定客户流失模型,有效预测客户的流失情况。
2、通过预测模型的建立,提出相应建议提高用户的活跃度,实现挽留关怀客户的有效性,降低开展挽留关怀工作的成本。
分析流程
数据探索与预处理
本节首先观察样本数据,初步了解属性特征,对各属性进行描述性统计分析,初步探索各属性与客户流失情况的关系;其次进行数据预处理工作,包括异常值处理,数据变换,数据规约等;之后将样本划分为训练集和测试集,观察客户流失情况样本是否均衡,不均衡时需要对训练样本进行均衡化处理;最后,对训练集和测试集进行标准化处理。
数据探索
本次所使用的数据集是某欧洲银行的数据。数据集一共包含了14个变量,10000个样本,不包含缺失值。本数据集可从superdatascience官网下载。首先先来观察数据情况。 图1 数据集变量预览
图1 数据集变量预览
在图1展示的数据集中,从左到右,数据集所具有的的变量有编号、用户ID、姓名、信用分、地区、性别、年龄、用户时长(使用银行产品时长)、存贷款情况、使用产品数量、是否有信用卡、是否为活跃用户、估计收入、是否已流失。将数据集特征进行汇总,由表1可以清楚地看出特征变量名称和属性。
表1 数据集特征汇总

我们从表1可以看到,数据集一共包含14个变量,其中第14个变量就是我们的目标变量,目标变量定义的是是否已经流失的分类变量,从而确定了本次数据挖掘的目标是分类。除了目标变量外,特征属性中有7个分类变量,其中有5个是字符类型的,这意味着在数据预处理时首先要处理这些变量才能做下一步分析。其余6个是数值变量,我们接下来要注意考虑数值变量是否存在异常值,是否需要进行数据变换。
下面对各变量首先进行描述性统计分析,观察变量分布情况,进一步了解数据。
1、定量变量初探
本小节主要是通过绘制定量变量的频数分布图来观察变量的分布情况,初步了解各变量分布。
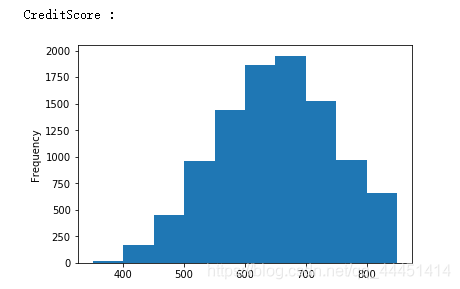 图2-1 CreditScore-信用得分频数分布 图2-1 CreditScore-信用得分频数分布
|
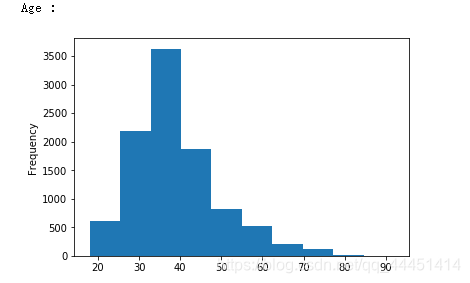 图2-2 Age-年龄频数分布 图2-2 Age-年龄频数分布
|
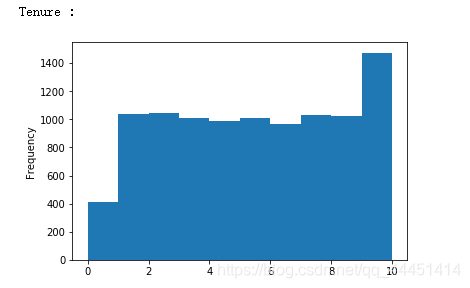 图2-3 Tenure-客户使用年数分布 图2-3 Tenure-客户使用年数分布
|
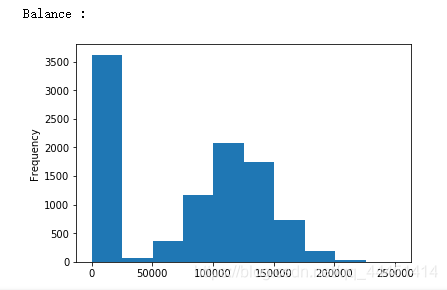 图2-4 Balance-客户存贷款情况 图2-4 Balance-客户存贷款情况
|
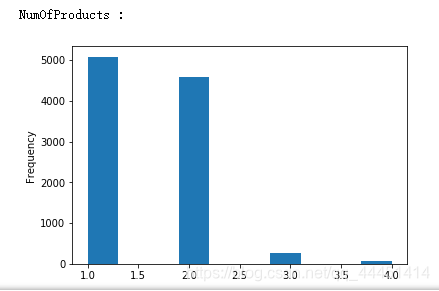 图2-5 NumOfProducts-拥有产品数量 图2-5 NumOfProducts-拥有产品数量
|
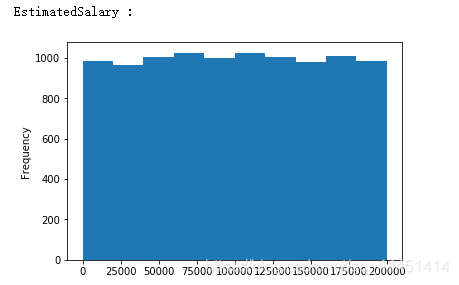 图2-6 EstimateSalary-估计收入 图2-6 EstimateSalary-估计收入
|
总体来看图2-1,对于信用分这个属性来说,流失和非流失总体呈现出一个偏正态分布,信用分在650-700之间达到峰值。由图2-2可以看出,年龄呈现出一个偏左态分布。该银行35到40岁的客户最多,在60岁以上的客户很少。且给银行的目标用户大部分年龄在25到45岁之间,比较符合多数银行客户年龄的分布情况。对于该银行,图2-3用户使用年数在1到9年的分布均匀,使用10年的人数最多,使用1年的人数较少。我们可以初步猜测该银行忠诚客户较多,但是在发展新客户方面不够重视或者策略需要调整。;对于客户存贷款情况,该样本数据显现的都是存贷款大于0的情况。从图中可以看出,存款在25000以下的占据大部分。在存款大于25000呈现正态分布。在持有产品数方面,该银行大多数用户使用银行的产品数量为1个或2个,拥有3个或4个产品的极少。说明该银行的产品只有少数具有吸引力,银行应该实施相应措施激励用户使用该银行产品。从图2-6可以看出,该银行客户估计收入在0到200000之间,且不同收入客户分布均匀,猜测该银行并没有清晰的目标客户定位,对不同收入层的客户效用没有差别。
2、分类指标分布情况
对于分类指标,这里展示了不同指标分类的频数分布情况,同时展示了在每种类别下客户流失情况。
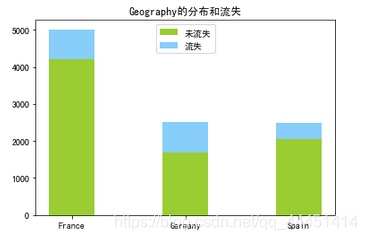 图3-1 地区分布和流失情况 图3-1 地区分布和流失情况
|
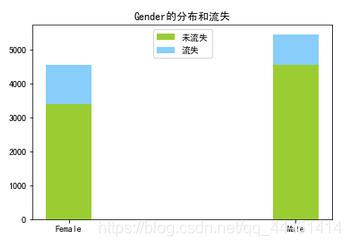 图3-2 性别分布和流失情况 图3-2 性别分布和流失情况
|
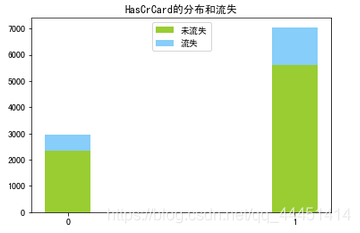 图3-3 信用卡分布和流失情况 图3-3 信用卡分布和流失情况
|
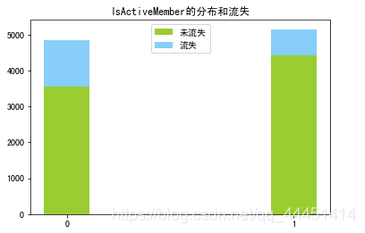 图3-4 活跃用户分布和流失情况 图3-4 活跃用户分布和流失情况
|
图3-1中,在地区这个属性可以看出,样本数据集客户来自三个国家:法国、德国、西班牙。该银行法国用户最多,德国和西班牙客户数量几乎相等,但从流失情况来看,德国用户的流失率明显高过其他两国。从性别来看,图3-2显示,银行的男性用户高于女性,但是女性的流失率要高过男性。在客户是否拥有信用卡来看(图3-3),该银行70%的客户有信用卡,没有信用卡客户的流失率在20%以上,有信用卡的流失率在16%。使用该银行信用卡的用户忠诚度更高。由图3-4知,该银行的活跃客户稍高于非活跃用户,活跃用户的流失率明显低于非活跃用户,这也说明活跃客户较非活跃客户忠诚度更高。
3、目标变量分布
 图4 客户流失情况
图4 客户流失情况
从图4我们可以很明显看到,客户流失情况样本分布很不均衡,未流失与流失用户比例接近4:1。所以接下来在划分训练集和测试集之后,需要对不均衡的测试集样本进行均衡处理。
数据预处理
数据清洗
因为样本不含缺失值,所以不用进行缺失值的处理。数据清洗在这里主要包括两步:删除无关变量和异常值处理。
1、删除不相关变量
我们将导入jupter notebook的数据集输出前5个数据观察变量,如图5。
 图5 数据集展示
图5 数据集展示
在所有变量中,RowNumber:用户编号,CustomerId:用户ID,Surname:用户姓名这三个变量明显是无关变量,我们将无关变量剔除。
2、异常值处理
首先根据变量的箱线图来判断是否存在异常值。
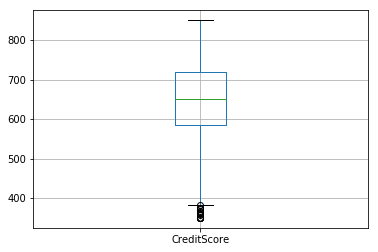 图6-1 信用分 图6-1 信用分
|
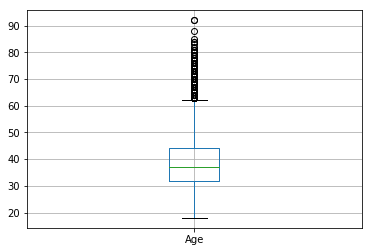 图6-2年龄 图6-2年龄
|
 图6-3 使用年数 图6-3 使用年数
|
 图6-4 存贷款 图6-4 存贷款
|
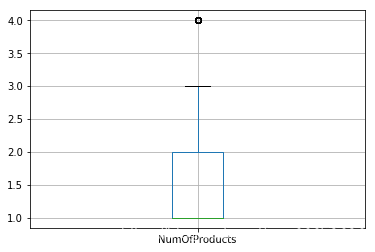 图6-5 产品数量 图6-5 产品数量
|
 图6-6 估计收入 图6-6 估计收入
|
由图6可以看出,信用分、年龄、产品数量存在异常值。信用分低于400分是异常值,年龄大于60的属于异常值,产品数为4的也属异常值。处理异常值的方法有很多,其中忽略异常值也是一种方法。由于认为信用分、年龄、产品数量属于重要变量,这里选择不剔除异常值。
数据变换
对于该数据集的数据变换处理,主要包括对字符型变量的量化、对分类变量的处理、连续属性离散化、样本不均衡处理和数据标准化。
1、字符型变量的量化
由之前样本数据的观察了解到,地区、性别是字符型变量,无法进行分析,需要将这2个属性进行量化。这里使用转换数值工具包LabelEncoder进行转换。处理后,地区包含0、1、2三个值,性别包括0、1两个值。其中地区变量0代表France,1代表Germany,2代表Spain;性别变量0代表女,1代表男。图7展示了变化后的效果。
 图7 量化后数据集
图7 量化后数据集
2、连续特征离散化。
将连续特征离散化对异常数据有很强的鲁棒性,能够增强模型的稳定性,降低了模型过拟合的风险,并且能够提高迭代速度。在之前的异常值检测中我们已知CreditScore和Age两个变量存在异常值,这里将他们进行离散化,将信用得分划分为600分以下、600-650、650-700、700-750、750以上共5个分组,年龄划分为30岁以下、30-40、40-50、50-60、60-70、70-80、80岁以上7个分组。
下面给出分组后的信用分和年龄分布。
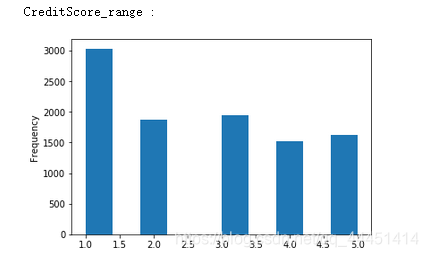 图8-1 信用分 图8-1 信用分
|
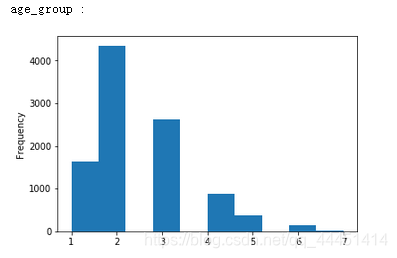 图8-2 信用分 图8-2 信用分
|
在进行完这些处理后 ,接下来的工作就是对分类变量进行独热编码以及特征矩阵的标准化。但是,考虑到类标签流失与未流失的比例接近1:4,属于不均衡数据。样本不均衡会给结果带来很大影响。在样本不均衡情况下,即使我们最终得到的模型准确度很高也是不可信的。所以,在进行分类任务时,解决样本不均衡问题很重要。解决样本不均衡的方法有很多,目前用的较多的有欠采样、过采样、加权、One-class分类。这里选择过采样的改进方法SMOTE算法来平衡样本。
3、样本不均衡处理
在对样本处理前,首先简单介绍样本不均衡的处理方法SMOTE算法。
SMOTE(Synthetic Minority Oversampling Technique),合成少数类过采样技术.它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General),SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中,具体如下图所示,算法流程如下。
(1)对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
(2)根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为xn。
(3)对于每一个随机选出的近邻xn,分别与原样本按照如下的公式构建新的样本。
x n e w = x + r a n d ( 0 , 1 ) ( x ^ − x ) x_{new}=x+rand(0,1)(\widehat{x}-x) xnew=x+rand(0,1)(x
−x)
 图9 SMOTE算法示意图
图9 SMOTE算法示意图
介绍完SMOTE原理后,我们对数据集进行处理。首先将数据集划分为训练集和样本集,这里将原始数据的80%作为训练集,20%作为样本集然后需要对训练集样本不均衡进行处理。这里随机产生的训练集正负样本比例接近1:5。我们通过SMOTE算法将正样本也就是流失样本扩展到和未流失样本一样多。我们可以看一下SMOTE处理后的效果。
 图10 均衡处理后训练样本数量
图10 均衡处理后训练样本数量
图10中我们可以看出,SMOTE已经将训练集扩展成了正负样本一致。由于SMOTE算法是基于样本到k近邻之间的距离随机生成的样本,所以过采样后流失样本的离散变量会连续化。Geography、Gender、HasCrCard、IsActiveMember这四个变量是离散变量且为分类变量,但是Smote处理后将他们连续化了,因此需要进行离散化处理。这里划分数据离散化的标准就近原则,即样本数据离哪个指标近就划分到那一类中。
4、虚拟变量变换
处理完样本不均衡问题后,我们考虑到Geography变量是三分类变量,直接编码(0,1,2)会让计算机直接将变量作为有序数组处理。所以,真正分析的时候要把他们作为虚拟变量处理,性别就是二分类引入一个虚拟变量,(即我们知道一个是0,另一个就是1)可以不变,地区是三分类,要引入两个虚拟变量,即要知道其中两个的类,才能确定另一个,比如France和Spain是0,我们才能确定Germany是1。这里可以直接用sklearn里的OneHotEncoder进行处理。OneHotEncoder是将分类变量的类别生成3列。这里当France为真时(1,0,0),Germany为真时(0,1,0),Spain为真时(0,0,1)。同时,为了避免掉入“虚拟变量陷阱”,我们删除其中一列,这里选择剔除Spain这一列。由于OneHotEncoder工具包会将独热编码后的数据放在最前面,因此此时变量顺序已经发生改变。展示效果如图11。
 图11 虚拟变量变换后的数据集
图11 虚拟变量变换后的数据集
5、特征标准化
数据的标准化处理,可以在保持列内数据多样性的同时,尽量减少不同类别之间差异的影响,可以让机器公平对待全部特征。同样用sklearn里StandardScaler包处理。这里训练集合测试集要进行相同的处理。
特征选择
在对单变量分析完之后,我们来观察下特征变量之间的相关性,当特征之间出现强相关性时,我们应该考虑剔除变量强相关性,下面给出了特征变量之间的相关系数矩阵。由于离散变量较多,因此这里采用相关系数矩阵展示。
表2 特征变量相关关系表
| Geography | Gender | Tenure | Balance | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | CreditScore_range | age_group |
|---|---|---|---|---|---|---|---|---|---|
| 1.000 | 0.005 | 0.004 | 0.069 | 0.004 | -0.009 | 0.007 | -0.001 | -0.000 | 0.018 |
| 1.000 | 0.015 | 0.012 | -0.022 | 0.006 | 0.023 | -0.008 | -0.006 | -0.022 | |
| 1.000 | -0.012 | 0.013 | 0.023 | -0.028 | 0.008 | 0.004 | -0.010 | ||
| 1.000 | -0.304 | -0.015 | -0.010 | 0.013 | 0.010 | 0.027 | |||
| 1.000 | 0.003 | 0.010 | 0.014 | 0.009253 | -0.030 | ||||
| 1.000 | -0.012 | -0.010 | -0.002 | -0.015 | |||||
| 1.000 | -0.011 | 0.020 | 0.088 | ||||||
| 1.000 | 0.005 | -0.003 | |||||||
| 1.000 | -0.003 | ||||||||
| 1.000 |
由相关系数矩阵可以看出,特征变量之间相关关系较弱,因此我们可以将全部特征纳入。
数据建模和调参
关于分类算法,目前几大主流基学习器如决策树、支持向量机、朴素贝叶斯、逻辑回归都可以实现,集成学习效果一般较基学习器好,包括随机森林、GBDT、还有比赛使用最多的XGBoost。同时,深度学习也成为数据挖掘上的重要工具,如LM神经网络、BP神经网络、RNN、CNN等。这里使用了决策树、支持向量机、朴素贝叶斯、逻辑回归、XGBoost、LM神经网络进行建模,通过对不同模型的学习能力评估选择能够预测客户流失的最优模型。
模型评价
通过不同模型对样本训练集的学习,之后用测试集来验证模型的学习能力。这里选用了分类度量指标precision、recall、F1值、准确度、ROC曲线、AUC值、Kappa值来比较各模型。
首先给出各模型的precision、recall、F1值对比,结果见下图。
表3 各模型性能度量
| measure | SVM | LR | Tree | RF | XGB | Bayes | LM |
|---|---|---|---|---|---|---|---|
| precision | 0.79 | 0.80 | 0.80 | 0.85 | 0.86 | 0.80 | 0.84 |
| recall | 0.78 | 0.70 | 0.79 | 0.86 | 0.87 | 0.73 | 0.81 |
| F1 | 0.78 | 0.73 | 0.79 | 0.85 | 0.86 | 0.75 | 0.82 |
| Accuracy | 77.90% | 70.25% | 78.70% | 85.65% | 86.55% | 73.15% | 81.20% |
从上表我们可以看出,XGBoost、随机森林、LM神经网络三种模型所有评价指标都在0.8以上,性能较好。其中XGBoost的四个指标都是最大值,随机森林次之,两者precision、recall、F1值都很接近,准确率相差接近1%,之后是LM神经网络。其余的模型较XGBoost、随机森林、LM神经网络表现差。
我们再来比较一下ROC曲线和AUC值。见图12
 图12 ROC曲线
图12 ROC曲线
从ROC曲线可以看出,XGBoost包含了其他模型的ROC曲线曲线,最靠近ROC曲线的左上角。并且比较各模型的AUC值,XGBoost也是最大的。从ROC曲线结合AUC值,认为XGBoost表现最好。
最后,再来比较一下各模型的kappa值。Kappa统计量比较的是分类器与仅仅基于随机的分类器的性能,它是根据混淆矩阵计算得出,和混淆矩阵评价保持一致。Kappa统计量的值在-1到1之间,小于0表示分类器性能不如随机分类,大于1表示比随机分类效果好,越接近于1表示分类性能越好。一般kappa值大于0.4才认为具有较好的分类性能。kappa统计量的计算公式是:
k = p 0 − p c 1 − p c k=\frac{p_0-p_c}{1-pc} k=1−pcp0−pc
其中,
p 0 = ∑ i = 1 r x i i N , p c = ∑ i = 1 2 ( x i . x . i ) N 2 p_0=\frac{\sum_{i=1}^rx_{ii}}{N},p_c=\frac{\sum_{i=1}^2(x_{i.}x_{.i})}{N^2} p0=N∑i=1rxii,pc=N2∑i=12(xi.x.i)
xij表示的是混淆矩阵对应的值。
我们用图像直观地表现各模型的kappa表现。
 图13 各模型kappa值比较
图13 各模型kappa值比较
由kappa值的条形图可以看出,XGBoost、RF、LM的值都超过了0.4,可以认为是较好的分类器。其中XGBoost最大,我们认为XGBoost的分类性能最好。
综合以上评价指标,XGBoost表现最好。下面将针对XGBoost学习器进行调参,使模型表现达到最优。
XGBoost模型介绍、调参及评估
由上一节的模型评价,确定了本次关于数据集预测银行流失客户的最优算法是XGBoost。同时,XGBoost也是目前在数据挖掘比赛中表现非常好的模型。在本节首先介绍XGBoost算法的原理以及优点,然后结合数据集对XGBoost模型进行调参,获取最优超参数,最后输出模型调参后的性能指标。
XGBoost模型介绍
XGBoost模型原理
XGBoost是boosting算法的其中一种。Boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器。因为XGBoost是一种提升树模型,所以它是将许多树模型集成在一起,形成一个很强的分类器。而所用到的树模型则是CART回归树模型。
XGBoost的算法思想就是不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数,去拟合上次预测的残差。当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数,最后只需要将每棵树对应的分数加起来就是该样本的预测值。
XGBoost的目标函数是:
O b j ( t ) = ∑ i = 1 n l ( y i , y ^ i ( t − 1 ) + f t ( x i ) ) + ∑ k = 1 k Ω ( f k ) + c o n s t a n t   Obj (t)= \sum_{i=1}^n l(y_i,\widehat{y}_i^{(t-1)}+f_t(x_i))+\sum_{k=1}^k\Omega(f_k)+constant\, Obj(t)=i=1∑nl(yi,y
i(t−1)+ft(xi))+k=1∑kΩ(fk)+consta
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7264
7264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









