







 本文深入探讨了一种1986年的O(ND)算法,用于计算两个序列的最短编辑距离。该算法在处理长DNA序列时表现出优越的时间效率,优于传统的动态规划方法。文章详细介绍了算法原理、Python实现、存在的问题及优化,包括如何输出编辑脚本,并给出了实际运行时间测试。通过对常规算法的改进,实现了兼容替换操作并优化了输出编辑脚本的代码。
本文深入探讨了一种1986年的O(ND)算法,用于计算两个序列的最短编辑距离。该算法在处理长DNA序列时表现出优越的时间效率,优于传统的动态规划方法。文章详细介绍了算法原理、Python实现、存在的问题及优化,包括如何输出编辑脚本,并给出了实际运行时间测试。通过对常规算法的改进,实现了兼容替换操作并优化了输出编辑脚本的代码。
论文阅读:An O ND Difference Algorithm and Its Variations
最近阅读了O(ND)这篇论文( 论文链接),虽然是一篇很老的论文(1986),但是其算法思想及其效果很好。
摘要
这篇博客讲述了O(ND)论文的算法的原理,python的具体实现,论文算法存在的问题,计算两条相似序列的最短编辑距离,并且与常规DP算法进行时间比较。发现O(ND)算法在序列相似时,时间消耗明显优于DP算法。所以O(ND)算法在计算长片段相似DNA的两条序列时有着极大优势。
对于论文算法存在的问题,对其进行改进,兼容了sub的功能,并能够输出编辑脚本。
理论
该部分讲述leetcode原题,常规算法,论文中各种概念的定义,以及论文的算法
最长公共子串与最短编辑脚本
最长公共子串问题(LCS)和最短编辑脚本(SES)(链接为leetcode原题)
SES问题描述如下:
给定两个字符串A、B,我们可以对任意一个字符串做三种操作:
- 插入一个字符(insertion)
- 删除一个字符(deletion)
- 替换一个字符(substitution)
求:将A变成B的最少操作次数(最短编辑距离)和操作方法(最短编辑脚本)
LCS问题描述如下:
给定两个字符串A、B,
定义
子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串**
求这两个字符串的最长公共子序列的长度
常规算法
这两道题常规的解法就是动态规划(dp),常规解法leetcode中已经描述的很详细了,这里就不再赘述。
常规算法存在的问题
动态规划算法的时间复杂度为O(MN)空间复杂度也为O(MN)复杂度太高,如果对于两个很长的字符串,CPU和内存消耗是很大的。
常规算法中可以优化的点如下:
- 常规算法的字符集可以是任意的、无限的,而实际应用中遇到的字符集往往是有限的
例如:
大写英文字母字符集大小为26(A~Z)
阿拉伯数字字符集大小为10(0~9)
DNA碱基字符集大小为4(A、G、C、T)- 常规算法的两个字符串差异可以特别大,而实际应用中两个字符串的差异可能很小
编辑图及相关定义
为了与论文中的字母对应,在这里进行定义:
N=len(A)
M=len(B)
D=len(最短编辑脚本)
L=len(最长公共字串)
其中M,N为已知,D,L为待求。
下图是论文中的edit graph图
其中
字符串A=abcabba,N=7
字符串B=cbabac,M=6
如果字符串A中的某一字符Ai与字符串B的Bj相同,那么在这个编辑图中会多一条点(Ai-1,Bj-1)到(Ai,Bj)的对角线

现在问题演变成了:
如何在编辑图上找到一条(0,0)到(n,m)的最短路径
路径中如果包含
- 水平边,则表示字符串A删除一个字母
- 垂直边,则表示字符串A插入一个字母
- 对角线,则表示不做任何操作
注意这里的操作只有插入和删除,没有替换。
论文算法
diagonal k,D-path,snake的定义
这三个论文中关键概念的定义如下图所示:

diagonal k:即为对角线k,在图中用蓝色虚线标出,对于图中任意一点(x,y)而言,有x-y=k。
D-path:是一个递归定义,根据编辑图的定义,这里的D可以认为是path中经过水平或垂直边的次数
0-path,表示这个路径没有任何水平或垂直边,即0-path是一条对角线。
1-path,表示这个路径先经过0-path,在经过一个水平或垂直边,再经过一条snake
snake:指经过水平或垂直边后,再经过能走到最远的对角线。
推论1

这个推论1很好理解
首先,D=0
0-path的endpoints肯定只会落在d0,因为0-path表示没有经过任何水平垂直边,也就是字符串A、B完全相同的开头部分,只要A、B开始出现差异,就会有indel(插入、删除)
当D=1
1-path的endpoints只会落在d-1或者d1上,如果竖着走(代表A插入一个字符),无论再经过多长的snake,endpoint都会落在d-1上,同理横着走(代表A删除一个字符)。
当D=2
2-path的endpoints可能落在d-2(竖着走两次)d0(竖着横着各一次)d2(横着两次)上
推论2

其实这里的推论2和D-path,snake的定义有点重复。
主要是想表示每次计算D-path的endpoint是可以由上一次计算(D-1)-path的endpoint结果推导出来的,然后阐述了递归出口:0-path的endpoint在(x,x)上。
简略版算法
其实经过上面的定义和推论已经可以看出来该算法的主要思想:
我们对于两条差别不大的字符串A、B,转换成编辑图后,总是存在几段snake(即字符串A、B中完全相同的部分),能加快我们的算法速度,而不用对这段snake进行O(N2)的遍历。
简要算法如下图:

每轮循环找到D-path在diagonal k上的endpoint,如果该endpoint是(N,M)则退出循环,得到D值,即为最短编辑距离。
详细算法

实现
python实现及测试
论文算法的python实现如下
def ond_algo(A:str,B:str)->int:
n=len(A)
m=len(B)
max_value=m+n
v=[-1]*(max_value+1)
x,y=0,0
while x < n and y < m and A[x] == B[y]:
x, y = x + 1, y + 1
v[m] = x
for d in range(1,max_value):
for k in range(-d,d+2,2):
if k==-d or k!=d and v[k-1+m]<v[k+1+m]:
x=v[k+1+m]#竖着走
else:
x=v[k-1+m]+1#横着走
y=x-k
while x<n and y<m and A[x]==B[y]:
x,y=x+1,y+1
v[k+m]=x
if x>=n and y>=m:
return d
运行时间测试
这个是测试了两条差异较大的10k序列,D值是10912(因为替换算2权值,所以大于10k),可以认为有将近一半的序列差异,ond比dp算法快一倍

这个是用两条差异较小的21k序列,D值是30
ond算法秒杀dp算法

论文算法存在的问题
论文中是将求解LCS、SES问题转化成了求编辑图中最短路径的问题,最短路径中的水平垂直边代表插入和删除(indel),但没有替换(sub)。
这样实质上是将sub视为了insert+del,这样会给三种操作赋予不同的权重:
insertion:1
deletion:1
substitution:2
所以论文给出的D值会与leetcode编辑距离(SES)有出入
但我们将状态转移方程(图源官方题解)中的替换的权值改为2,给出的答案和论文算法就一致了。

O(ND)算法改进
如何输出编辑脚本
论文中提到输出编辑脚本只需要保存每一轮的V数组即可。V数组保存的是每轮D-path的endpoint
在详细版算法中,为了节省空间,保存的是每轮endpoint的横坐标,因为有y=x-k的关系存在,所以只需要保存x就可以保存endpoint的位置。
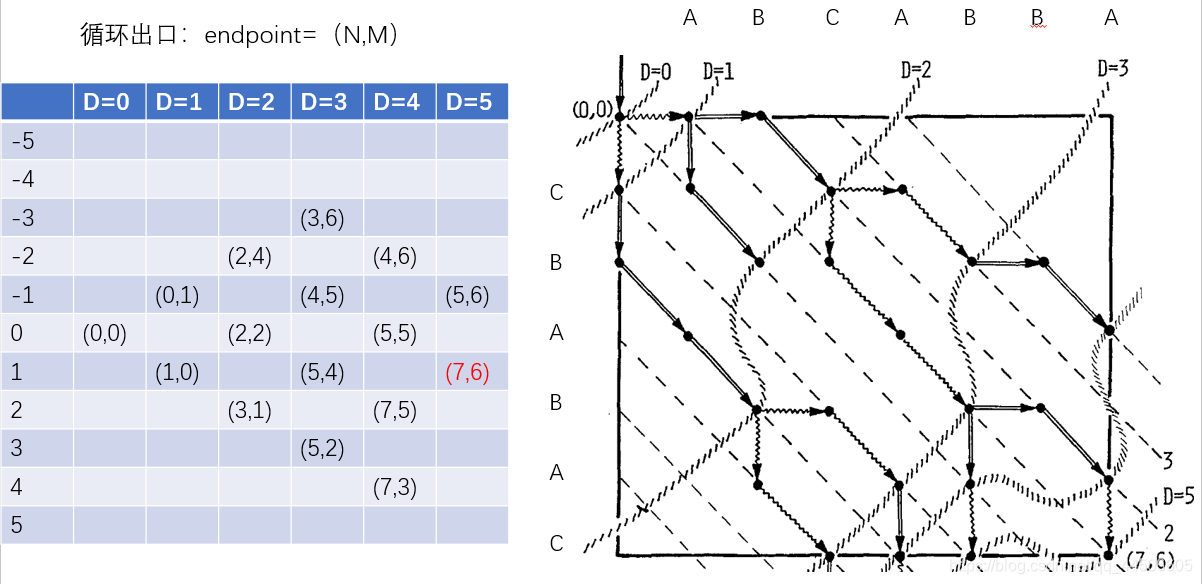
对于一个endpoint,只需要比较上一轮(D-1)-path的两个endpoint,dk-1的x、dk+1的x+1大小(dk+1到dk是竖着走,所以x不变,dk-1到dk是横着走,所以x+1),就可以得知本轮路径。
例如上图中,(7,6)上一轮的endpoint可以是d0的(5,5)和d2的(7,5),7>5+1,所以(7,6)是从(7,5)过来的。
如果dk-1的x、dk+1的x+1相等,表明两个endpoint都可以走,我们可以随机选一条,或者设置优先级。
添加sub
从上个图的V数组中可以看到endpoint中间会空出一个位置,其实这个点就是sub的位置,dk上的一个endpoint经过一个sub之后还是会留在dk上,这样我们计算每轮D-path时就会考虑sub,所以权值更新为:
insertion:1
deletion:1
substitution:1
就和我们一般认为的SES和LCS问题一样了。
改进代码
算法部分这次不再返回一个int值,而是返回整个v数组,因为v数组记录了整个计算过程
输出编辑脚本时,不同的I、D、S优先级会导致编辑脚本有多种,但v数组是一致的
def list_get(index:int, list:[], default=None):
return list[index] if 0<= index < len(list) else default
def my_ond_algo_version1(A:str, B:str)->[[]]:
n=len(A)
m=len(B)
max_value=m+n
v=[]
x,y=0,0
while x < n and y < m and A[x] == B[y]:
x, y = x + 1, y + 1
v.append([x])
for d in range(1,max_value):
tmp_v=[-1]*(2*d+1)
for k in range(-d,d+1,1):
x1=list_get(list=v[d-1],index=k+d-2,default=-1)
x2=list_get(list=v[d-1],index=k+d-1,default=-1)
x3=list_get(list=v[d-1],index=k+d,default=-1)
p1 = Point(x=x1, k=k-1)#横着走的点
p2= Point(x=x2,k=k)#substitution
p3 = Point(x=x3, k=k+1)#竖着走的点
x=max([p1.x+1,p2.x+1,p3.x])
y=x-k
while x<n and y<m and A[x]==B[y]:
x,y=x+1,y+1
tmp_v[k+d]=x
if x>=n and y>=m:
v.append(tmp_v)
return v
v.append(tmp_v)
获取编辑距离
def get_edit_distance(v:[[]]):
return len(v)-1
获取编辑脚本,这里只是其中一种优先级
def get_edit_script(v:[[]])->[]:
script=[]
d=len(v)-1
k=v[-1].index(-1)-d-1 if -1 in v[-1] else d
for d in range(len(v)-1,0,-1):
x1 = list_get(list=v[d - 1], index=k + d - 2, default=-1)
x2 = list_get(list=v[d - 1], index=k + d - 1, default=-1)
x3 = list_get(list=v[d - 1], index=k + d, default=-1)
p1 = Point(x=x1, k=k - 1) # 横着走的点
p2 = Point(x=x2, k=k) # substitution
p3 = Point(x=x3, k=k + 1) # 竖着走的点
p_list=[(p1.x+1,p1),(p2.x+1,p2),(p3.x,p3)]
p_list.sort(key=lambda p:p[0])
if p_list[-1][1]==p1:
script.insert(0,(p_list[-1][1].x,'D'))
elif p_list[-1][1]==p2:
script.insert(0,(p_list[-1][1].x,'S'+str(p_list[-1][1].y)))
elif p_list[-1][1]==p3:
script.insert(0,(p_list[-1][1].x,'I'+str(p_list[-1][1].y)))
k=p_list[-1][1].k
return script
测试代码
def test_my_ond_algo(self):
A = 'ABCABBA'
B = 'CBABAC'
ans = 4
ond_v = algo.my_ond_algo_version1(A, B)
ond_ans=algo.get_edit_distance(ond_v)
script=algo.get_edit_script(ond_v)
print(script)#[(0, 'S0'), (2, 'D'), (5, 'D'), (7, 'I5')]
self.assertEqual(ond_ans, ans, 'ond_ans is %d but ans is ' % ond_ans + str(ans))
输出的编辑脚本[(0, ‘S0’), (2, ‘D’), (5, ‘D’), (7, ‘I5’)]表示:将A变成B:
A[0]subB[0]
A[2]del
A[5]del
A[7]insertB[5]

















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









