







前言
之前咱们三个同学做了个Simple-SCM,我负责那个Merge模块,也就是对两个不同分支的代码进行合并。当时为了简便起见,遇到文件冲突的时候,就直接按照文件的更改日期来存储,直接把更改日期较新的那个文件认为是我们要保留的文件版本。但是这样子做是存在很多问题的,因为这样做就无法对不同分支的代码他们各自的特性进行整合,最终保留的只是其中一个分支的代码。因此,加入按行进行比较的diff算法是非常必要的。
然后,本着自力更生的理念,我希望能够自己写出这个代码,然后把它应用到Simple-SCM之中。今年五月份的时候就看到了Google开源的diff-match-patch库,这里面提供了完善的diff功能。一看代码量,三千多行,就把这事往后推了。这个开源库里面讲到了,用的就是Myers的论文,我就想,我能不能自己阅读论文,把它复现出来呢?但是由于时间的缘故,就没去搞。毕竟当时是实训大作业要赶ddl嘛,先把软件做出来再说。
到了最近,我又找到了这个库,然后想起了还没有完成的Merge模块,就想着去把它做出来。于是,我说干就干,还深夜发了一条朋友圈,来立一个Flag。
然后我就,真的,抽空把这个论文给看了。并且把它的基础版本给复现了出来!(论文原文请转到文末)
什么是diff?
diff在软件开发过程中非常常见,最直观的就是在git里面,可以查看两个不同版本的代码的区别。得出的数据包括了:新增的、删除的、修改的、没有改变的。
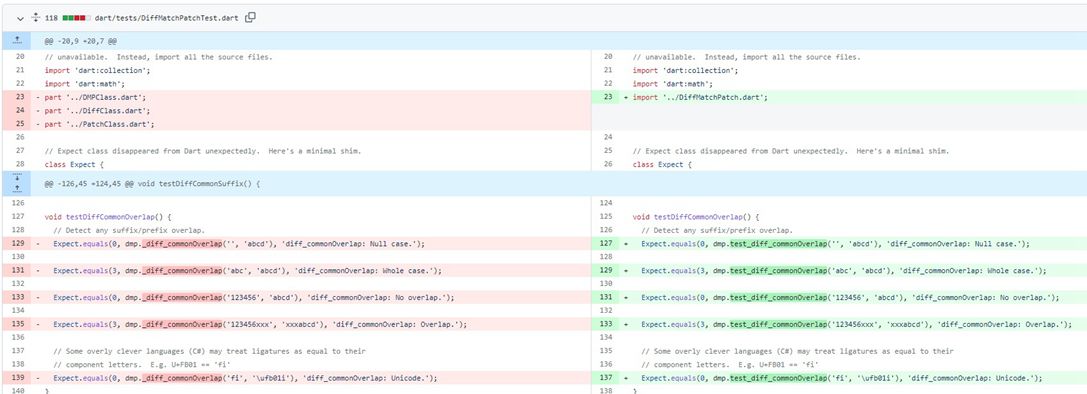
在Github上查看代码版本之间的差异
上面这张图展现的就是在Github上看到的,展现了两个版本的代码之间的差异。红色的表示这段代码在新版中已经被删除了,绿色的表示是新增的,其中,颜色加深部分则是发生改变的。
并且,左边的旧版本代码有很多种方式来变成右边的新版代码。找到一个最符合人类直观反应的diff,也是一个复杂的问题。
Myers的Diff算法的原理
我们如何判断两份代码文件的差异呢?首先我们要认识到它是字符串,换行只是加了换行符而已。因此,从本质上来说,我们要能够判断两个字符串的差异。
这就回归到了我们熟知的最长公共子序列(LCS)问题了,对于LCS问题,在之前我也学过LCS的算法。之前学的基于DP的算法的时间复杂度是O(MN),也就是我们所说的N平方复杂度。对于大量的数据而言,之前的算法速度是很慢的。
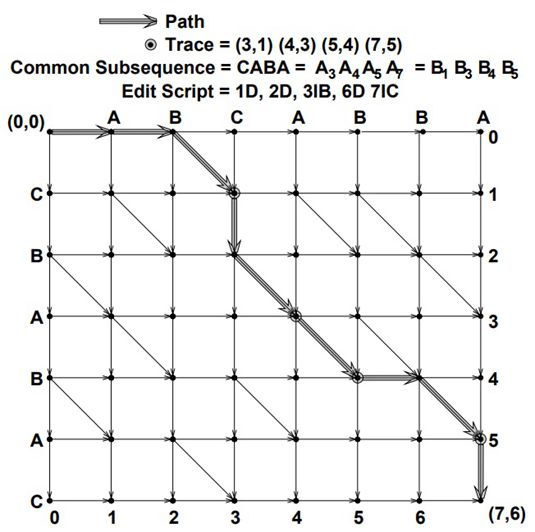
编辑图
因此,Myers在论文中引入了编辑图(Edit Graph)的概念。也就是将旧字符串放在x轴,新字符串放在y轴。起点是(0,0),终点是(M,N)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









